目录
1. unordered系列关联式容器
1.1 unordered_map
1.1.1 unordered_map的文档介绍
1.1.2 unordered_map的接口说明
1.2 unordered_set
1.3 在线OJ
2. 底层结构
2.1 哈希概念
2.2 哈希冲突
2.3 哈希函数
2.4 哈希冲突解决
2.4.1 闭散列
2.4.2 开散列
3. 模拟实现
3.1 哈希表的改造
3.2 unordered_map
4. 哈希的应用
4.1 位图
4.1.1 位图概念
4.1.2 位图的实现
4.1.3 位图的应用
4.2 布隆过滤器
4.2.1 布隆过滤器提出
4.2.2布隆过滤器概念
4.2.3 布隆过滤器的插入
4.2.4 布隆过滤器的查找
4.2.5 布隆过滤器删除
4.2.6 布隆过滤器优点
5. 海量数据面试题
5.1 哈希切割
5.2 位图应用
5.3 布隆过滤器
1. unordered系列关联式容器
1.1 unordered_map
1.1.1 unordered_map的文档介绍
https://cplusplus.com/reference/unordered_map/unordered_map/?kw=unordered_map
1.1.2 unordered_map的接口说明
1. unordered_map的构造

2. unordered_map的容量

3. unordered_map的迭代器

4. unordered_map的元素访问

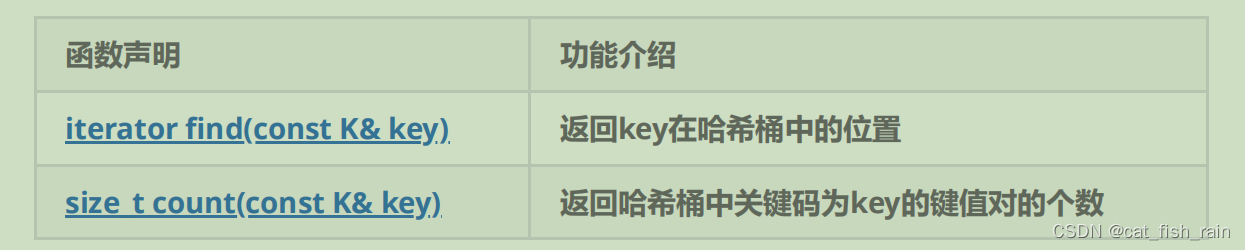
6. unordered_map的修改操作

7. unordered_map的桶操作

1.2 unordered_set
https://cplusplus.com/reference/unordered_set/unordered_set/?kw=unordered_set
1.3 在线OJ
力扣
class Solution {
public:
int repeatedNTimes(vector<int>& nums) {
int n=nums.size();
int N=n/2;
unordered_map<int,int> mp;
// map<int,int> mp;
// vector<int,int> mp;
for(int i=0;i<nums.size();i++){
mp[nums[i]]++;
// if(mp[nums[i]]==N)
// return nums[i];
}
for(auto e:mp){
if(e.second==N)
return e.first;
}
return -1;
}
};https://leetcode.cn/problems/intersection-of-two-arrays/submissions/
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> s1;
//使用unordered_set 比set 更快在时间上
set<int> s2;
vector<int> ans;
for(int i=0;i<nums1.size();i++){
s1.insert(nums1[i]);
}
for(int i=0;i<nums2.size();i++){
s2.insert(nums2[i]);
}
for(auto e:s1){
auto it=s2.find(e);
if(it!=s2.end())
ans.push_back(e);
}
return ans;
}
};力扣
力扣
力扣
2. 底层结构
2.1 哈希概念
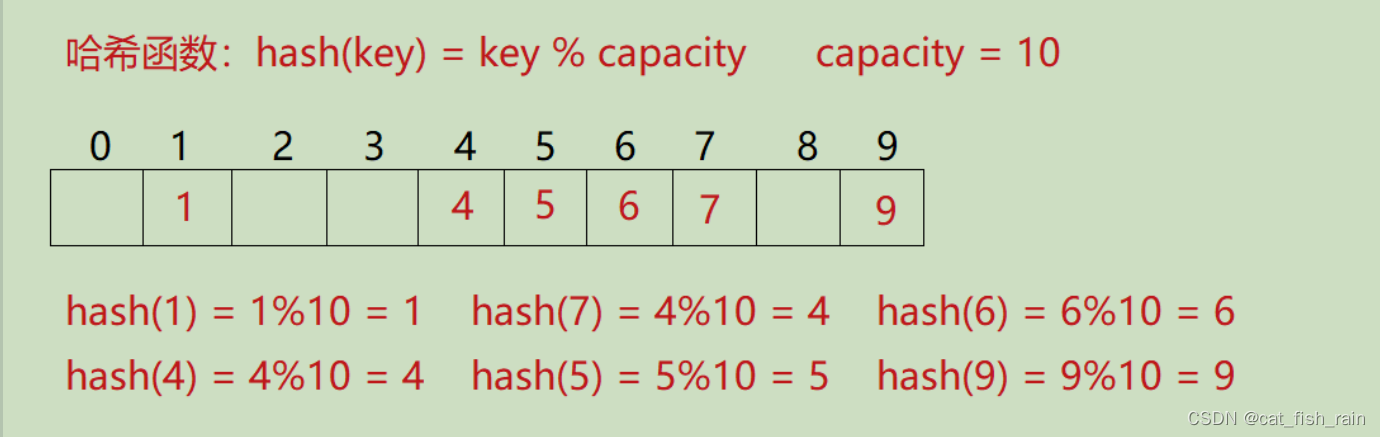
2.2 哈希冲突
2.3 哈希函数

2.4 哈希冲突解决
2.4.1 闭散列
- 通过哈希函数获取待插入元素在哈希表中的位置
- 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素

// 哈希表每个空间给个标记
// EMPTY此位置空, EXIST此位置已经有元素, DELETE元素已经删除
enum State{EMPTY, EXIST, DELETE};#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
enum State
{
EMPTY,
EXIST,
DELETE
};
template <class K, class V>
class HashTable
{
struct Elem
{
pair<K, V> _val;
State _state;
};
public:
HashTable(size_t capacity = 3) : _ht(capacity), _size(0)
{
for (size_t i = 0; i < capacity; i++)
{
_ht[i]._state = EMPTY;
}
}
bool Insert(const pair<K, V> &val)
{
//检测哈希表底层空间是否充足
// _CheckCapacity();
size_t hashAddr = HashFunc(key);
while (_ht[hashAddr]._state != EMPTY)
{
if (_ht[hashAddr]._state == EXIST && _ht[hashAddr]._val.first == key)
{
return false;
}
hashAddr++;
if (hashAddr == _ht.capacity())
hashAddr = 0;
//转一圈也没有找到,注意:动态哈希表,该种情况下不用考虑,哈希表元素合数到达一定数量,哈希冲突概率会增大,,需要
//扩容来降低哈希冲突,依次哈希表中元素不会存满
//插入元素
_ht[hashAddr]._state = EXIST;
_ht[hashAddr]._val = val;
return true;
}
}
int Find(const K &key)
{
size_t hashAddr = HashFunc(key);
while (_ht[hashAddr]._state != EMPTY)
{
if (_ht[hashAddr]._state == EXIST && _ht[hashAddr]._val.first == key)
{
return hashAddr;
}
hashAddr++;
}
return hashAddr;
}
bool Erase(const K &key)
{
int index = Find(key);
if (-1 != index)
{
_ht[index]._state = DELETE;
_size++;
return true;
}
return false;
}
size_t Size() const;
bool Empty() const;
void Swap(HashTable<K, V> &ht);
private:
size_t HashFunc(const K &key)
{
return key % _ht.capacity();
}
private:
vector<Elem> _ht;
size_t _size;
};
int main()
{
system("pause");
return 0;
}
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
enum State
{
EMPTY,
EXIST,
DELETE
};
template <class K, class V>
class HashTable
{
struct Elem
{
pair<K, V> _val;
State _state;
};
public:
HashTable(size_t capacity = 3) : _ht(capacity), _size(0)
{
for (size_t i = 0; i < capacity; i++)
{
_ht[i]._state = EMPTY;
}
}
bool Insert(const pair<K, V> &val)
{
//检测哈希表底层空间是否充足
// _CheckCapacity();
size_t hashAddr = HashFunc(key);
while (_ht[hashAddr]._state != EMPTY)
{
if (_ht[hashAddr]._state == EXIST && _ht[hashAddr]._val.first == key)
{
return false;
}
hashAddr++;
if (hashAddr == _ht.capacity())
hashAddr = 0;
//转一圈也没有找到,注意:动态哈希表,该种情况下不用考虑,哈希表元素合数到达一定数量,哈希冲突概率会增大,,需要
//扩容来降低哈希冲突,依次哈希表中元素不会存满
//插入元素
_ht[hashAddr]._state = EXIST;
_ht[hashAddr]._val = val;
return true;
}
}
int Find(const K &key)
{
size_t hashAddr = HashFunc(key);
while (_ht[hashAddr]._state != EMPTY)
{
if (_ht[hashAddr]._state == EXIST && _ht[hashAddr]._val.first == key)
{
return hashAddr;
}
hashAddr++;
}
return hashAddr;
}
bool Erase(const K &key)
{
int index = Find(key);
if (-1 != index)
{
_ht[index]._state = DELETE;
_size++;
return true;
}
return false;
}
size_t Size() const;
bool Empty() const;
void Swap(HashTable<K, V> &ht);
void CheckCapacity(){
if(_size*10/_ht.capacity()>=7){
HashTable<K,V,HF> newHt(GetNextPrime(ht.capacity));
for(size_t i=0;i<_ht.capacity();i++){
if(_ht[i]._state==EXIST){
newHT.Insert(_ht[i]._val);
}
}
Swap(newHt);
}
}
private:
size_t HashFunc(const K &key)
{
return key % _ht.capacity();
}
private:
vector<Elem> _ht;
size_t _size;
};
int main()
{
system("pause");
return 0;
}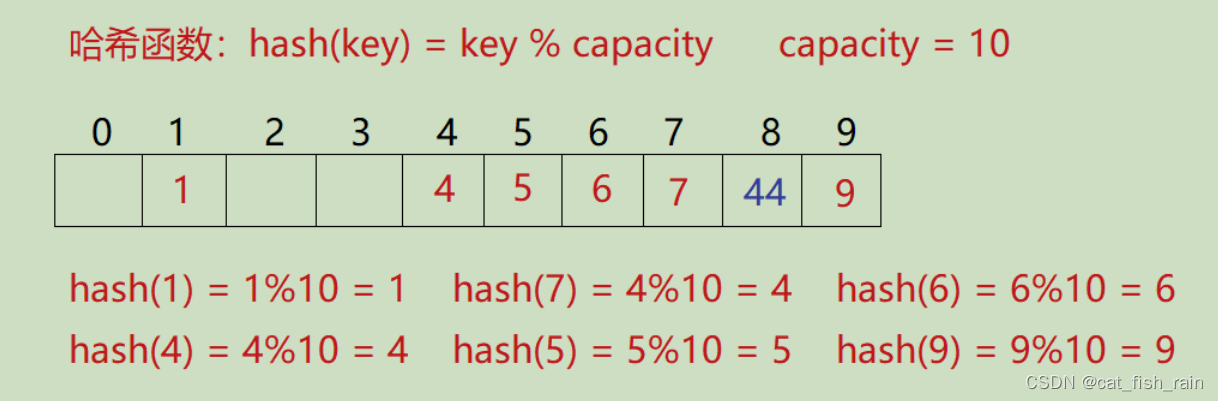
因此:闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
2.4.2 开散列
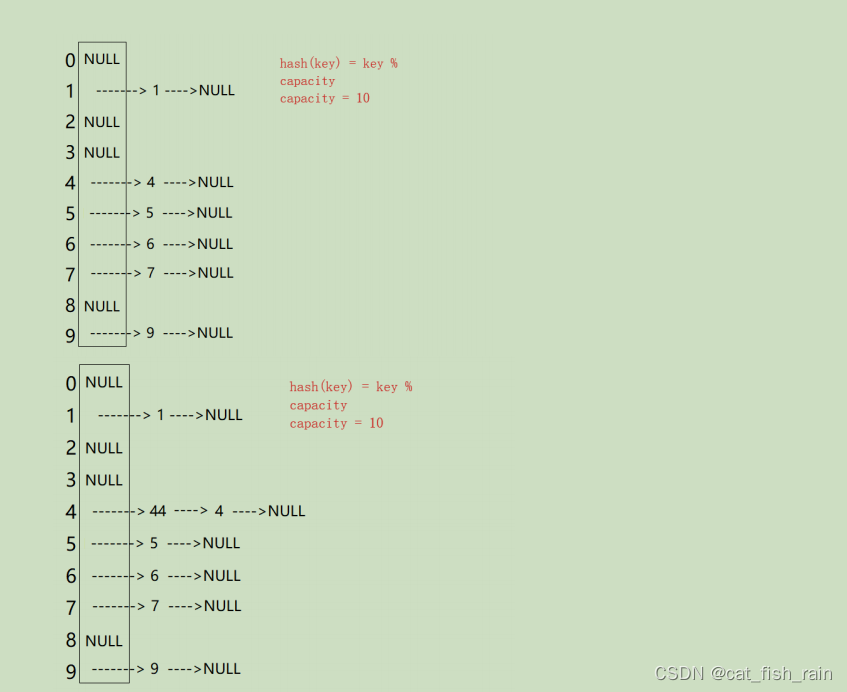
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
template<class V>
struct HashBucketNode{
HashBucketNode(const v & data):_pNext(nullptr),_data(data){
}
HashBucketNode<V> *_pNext;
V _data;
};
template<class V>
class HashBucket{
typedef HashBucketNode<V> Node;
typedef Node *PNode;
public:
HashBucket(size_t capacity=3):_size(0){
_ht.resize(GETNextPrime(capacity),nullptr);
}
//哈希桶中的元素不能重复
PNode *Insert(const v&data){
//缺人是否需要扩容
//_CheckCapacity();
//1.计算元素所在的桶号
size_t bucketNo=HashFunc(data);
//检测元素是否在桶中
PNode pCur=_ht[bucketNo];
while(pCur){
if(pCur->_data==data)
return pCur;
pCur=pCur->_pNext;
}
//插入新元素
pCur=new Node(data);
pCur->_pNext=_ht[bucketNo];
_ht[bucketNo]=pCur;
_size++;
return pCur;
}
//删除哈希桶中位data的元素(data) 不会重复
PNode* Erase(const V&data){
size_t bucketNo=HashFunc(data);
PNode pCur=_ht[bucketNo];
PNode pPrev=nullptr,pRet=nullptr;
while (pCur)
{
if(pCur->_data==data){
if(pCur==_ht[bucketNo])
_ht[bucketNo]=pCur->_pNext;
else
pPrev->_pNext=pCur->_pNext;
pRet=pCur->_pNext;
delete pCur;
_size--;
return pRet;
}
}
return nullptr;
}
PNode *Find(const v& data);
size_t Size() const;
bool Empty() const;
void Clear();
bool BucketCount() const;
void Swap(HashBucket<v,HF> & ht);
~HashBucket();
private:
size_t HashFun(const v&data){
return data%_ht.capacity();
}
private:
vector<PNode*> _ht;
size_t _size;
}
int main()
{
system("pause");
return 0;
}void _CheckCapacity()
{
size_t bucketCount = BucketCount();
if(_size == bucketCount)
{
HashBucket<V, HF> newHt(bucketCount);
for(size_t bucketIdx = 0; bucketIdx < bucketCount; ++bucketIdx)
{
PNode pCur = _ht[bucketIdx];
while(pCur)
{
// 将该节点从原哈希表中拆出来
_ht[bucketIdx] = pCur->_pNext;
// 将该节点插入到新哈希表中
size_t bucketNo = newHt.HashFunc(pCur->_data);
pCur->_pNext = newHt._ht[bucketNo];
newHt._ht[bucketNo] = pCur;
pCur = _ht[bucketIdx];
}
}
newHt._size = _size;
this->Swap(newHt);
}
}// 哈希函数采用处理余数法,被模的key必须要为整形才可以处理,此处提供将key转化为
整形的方法
// 整形数据不需要转化
template<class T>
class DefHashF
{
public:
size_t operator()(const T& val)
{
return val;
}
};
// key为字符串类型,需要将其转化为整形
class Str2Int
{
public:
size_t operator()(const string& s)
{
const char* str = s.c_str();
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
};
// 为了实现简单,此哈希表中我们将比较直接与元素绑定在一起
template<class V, class HF>
class HashBucket
{
// ……
private:
size_t HashFunc(const V& data)
{
return HF()(data.first)%_ht.capacity();
}
};size_t GetNextPrime(size_t prime)
{
const int PRIMECOUNT = 28;
static const size_t primeList[PRIMECOUNT] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
size_t i = 0;
for (; i < PRIMECOUNT; ++i)
{
if (primeList[i] > prime)
return primeList[i];
}return primeList[i];
}https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html
3. 模拟实现
3.1 哈希表的改造
1. 模板参数列表的改造
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
// K:关键码类型
// V: 不同容器V的类型不同,如果是unordered_map,V代表一个键值对,如果是
// unordered_set,V 为 K
// KeyOfValue: 因为V的类型不同,通过value取key的方式就不同,详细见
// unordered_map/set的实现
// HF: 哈希函数仿函数对象类型,哈希函数使用除留余数法,需要将Key转换为整形数字才能
// 取模
template<class K, class V, class KeyOfValue, class HF = DefHashF<T> >
class HashBucket;
int main()
{
system("pause");
return 0;
}#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// K:关键码类型
// V: 不同容器V的类型不同,如果是unordered_map,V代表一个键值对,如果是
// unordered_set,V 为 K
// KeyOfValue: 因为V的类型不同,通过value取key的方式就不同,详细见
// unordered_map/set的实现
// HF: 哈希函数仿函数对象类型,哈希函数使用除留余数法,需要将Key转换为整形数字才能
// 取模
template <class K, class V, class KeyOfValue, class HF = DefHashF<T>>
class HashBucket;
// 注意:因为哈希桶在底层是单链表结构,所以哈希桶的迭代器不需要--操作
template <class K, class V, class KeyOfValue, class HF>
struct HBIterator
{
typedef HashBucket<K, V, KeyOfValue, HF> HashBucket;
typedef HashBucketNode<V> *PNode;
typedef HBIterator<K, V, KeyOfValue, HF> Self;
HBIterator(PNode pNode = nullptr, HashBucket *pHt = nullptr);
Self &operator++()
{
// 当前迭代器所指节点后还有节点时直接取其下一个节点
if (_pNode->_pNext)
_pNode = _pNode->_pNext;
else
{
// 找下一个不空的桶,返回该桶中第一个节点
size_t bucketNo = _pHt->HashFunc(KeyOfValue()(_pNode -
> _data)) +
1;
for (; bucketNo < _pHt->BucketCount(); ++bucketNo)
{
if (_pNode = _pHt->_ht[bucketNo])
break;
}
}
return *this;
}
Self operator++(int);
V &operator*();
V *operator->();
bool operator==(const Self &it) const;
bool operator!=(const Self &it) const;
PNode _pNode;
// 当前迭代器关联的节点
HashBucket *_pHt;
// 哈希桶--主要是为了找下一个空桶时候方便
};
int main()
{
system("pause");
return 0;
}template<class K, class V, class KeyOfValue, class HF = DefHashF<T> >
class HashBucket
{
friend HBIterator<K, V, KeyOfValue, HF>;
// ......
public:
typedef HBIterator<K, V, KeyOfValue, HF> Iterator;
//
// ...
// 迭代器
Iterator Begin()
{
size_t bucketNo = 0;
for (; bucketNo < _ht.capacity(); ++bucketNo)
{
if (_ht[bucketNo])
break;
}
if (bucketNo < _ht.capacity())
return Iterator(_ht[bucketNo], this);
else
return Iterator(nullptr, this);
}
Iterator End(){ return Iterator(nullptr, this);}
Iterator Find(const K& key);
Iterator Insert(const V& data);
Iterator Erase(const K& key);
// 为key的元素在桶中的个数
size_t Count(const K& key)
{
if(Find(key) != End())
return 1;
return 0;
}
size_t BucketCount()const{ return _ht.capacity();}
size_t BucketSize(size_t bucketNo)
{
size_t count = 0;
PNode pCur = _ht[bucketNo];
while(pCur)
{
count++;
pCur = pCur->_pNext;
}
return count;
}
// ......
};3.2 unordered_map
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// K:关键码类型
// V: 不同容器V的类型不同,如果是unordered_map,V代表一个键值对,如果是
// unordered_set,V 为 K
// KeyOfValue: 因为V的类型不同,通过value取key的方式就不同,详细见
// unordered_map/set的实现
// HF: 哈希函数仿函数对象类型,哈希函数使用除留余数法,需要将Key转换为整形数字才能
// 取模
template <class K, class V, class KeyOfValue, class HF = DefHashF<T>>
class HashBucket;
// 注意:因为哈希桶在底层是单链表结构,所以哈希桶的迭代器不需要--操作
template <class K, class V, class KeyOfValue, class HF>
struct HBIterator
{
typedef HashBucket<K, V, KeyOfValue, HF> HashBucket;
typedef HashBucketNode<V> *PNode;
typedef HBIterator<K, V, KeyOfValue, HF> Self;
HBIterator(PNode pNode = nullptr, HashBucket *pHt = nullptr);
Self &operator++()
{
// 当前迭代器所指节点后还有节点时直接取其下一个节点
if (_pNode->_pNext)
_pNode = _pNode->_pNext;
else
{
// 找下一个不空的桶,返回该桶中第一个节点
size_t bucketNo = _pHt->HashFunc(KeyOfValue()(_pNode -
> _data)) +
1;
for (; bucketNo < _pHt->BucketCount(); ++bucketNo)
{
if (_pNode = _pHt->_ht[bucketNo])
break;
}
}
return *this;
}
Self operator++(int);
V &operator*();
V *operator->();
bool operator==(const Self &it) const;
bool operator!=(const Self &it) const;
PNode _pNode;
// 当前迭代器关联的节点
HashBucket *_pHt;
// 哈希桶--主要是为了找下一个空桶时候方便
};
// unordered_map中存储的是pair<K, V>的键值对,K为key的类型,V为value的类型,HF哈希
函数类型
// unordered_map在实现时,只需将hashbucket中的接口重新封装即可
template <class K, class V, class HF = DefHashF<K>>
class unordered_map
{
typedef pair<K, V> ValueType;
typedef HashBucket<K, ValueType, KeyOfValue, HF> HT;
// 通过key获取value的操作
struct KeyOfValue
{
const K &operator()(const ValueType &data)
{
return data.first;
}
};
public:
typename typedef HT::Iterator iterator;
public:
unordered_map() : _ht()
{
}
iterator begin() { return _ht.Begin(); }
iterator end() { return _ht.End(); }
// capacity
size_t size() const { return _ht.Size(); }
bool empty() const { return _ht.Empty(); }
///
// Acess
V &operator[](const K &key)
{
return (*(_ht.InsertUnique(ValueType(key, V())).first)).second;
}
const V &operator[](const K &key) const;
//
// lookup
iterator find(const K &key) { return _ht.Find(key); }
size_t count(const K &key) { return _ht.Count(key); }
/
// modify
pair<iterator, bool> insert(const ValueType &valye)
{
return _ht.Insert(valye);
}
iterator erase(iterator position)
{
return _ht.Erase(position);
}
// bucket
size_t bucket_count() { return _ht.BucketCount(); }
size_t bucket_size(const K &key) { return _ht.BucketSize(key); }
private:
HT _ht;
};
int main()
{
system("pause");
return 0;
}4. 哈希的应用
4.1 位图
4.1.1 位图概念

4.1.2 位图的实现
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class bitset
{
public:
bitset(size_t bitCount)
: _bit((bitCount >> 5) + 1), _bitCount(bitCount)
{
}
// 将which比特位置1
void set(size_t which)
{
if (which > _bitCount)
return;
size_t index = (which >> 5);
size_t pos = which % 32;
int main()
{
system("pause");
return 0;
}
_bit[index] |= (1 << pos);
}
// 将which比特位置0
void reset(size_t which)
{
if (which > _bitCount)
return;
size_t index = (which >> 5);
size_t pos = which % 32;
_bit[index] &= ~(1 << pos);
}
// 检测位图中which是否为1
bool test(size_t which)
{
if (which > _bitCount)
return false;
size_t index = (which >> 5);
size_t pos = which % 32;
return _bit[index] & (1 << pos);
}
// 获取位图中比特位的总个数
size_t size() const { return _bitCount; }
// 位图中比特为1的个数
size_t Count() const
{
int bitCnttable[256] = {
0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4, 1, 2, 2, 3, 2, 3, 3, 4, 2,
3, 3, 4, 3, 4, 4, 5, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3,
3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3,
4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4,
3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5,
6, 6, 7, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4,
4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5,
6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 2, 3, 3, 4, 3, 4, 4, 5,
3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 3,
4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 4, 5, 5, 6, 5, 6, 6, 7, 5, 6,
6, 7, 6, 7, 7, 8};
size_t size = _bit.size();
size_t count = 0;
for (size_t i = 0; i < size; ++i)
{
int value = _bit[i];
int j = 0;
while (j < sizeof(_bit[0]))
{
unsigned char c = value;
count += bitCntTable[c];
++j;
value >>= 8;
}
}
return count;
}
private:
vector<int> _bit;
size_t _bitCount;
};4.1.3 位图的应用
4.2 布隆过滤器
4.2.1 布隆过滤器提出
4.2.2布隆过滤器概念
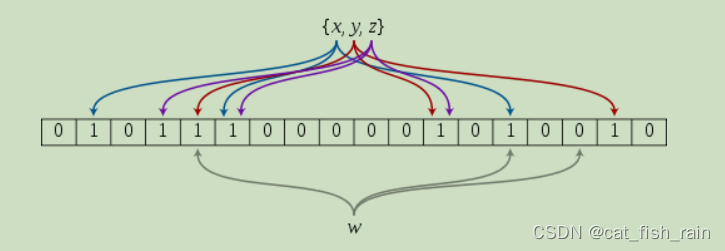
详解布隆过滤器的原理,使用场景和注意事项 - 知乎
4.2.3 布隆过滤器的插入

向布隆过滤器中插入:"baidu"
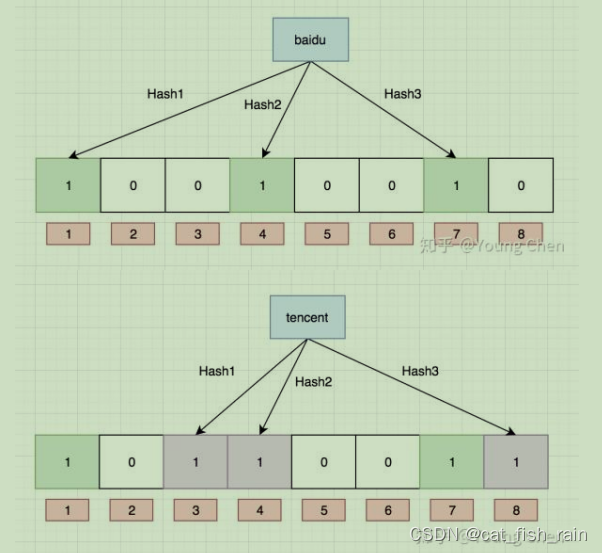
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
struct BKDRHash
{
size_t operator()(const string &s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
struct APHash
{
size_t operator()(const string &s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string &s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template <size_t N,
size_t X = 5,
class K = string,
class HashFunc1 = BKDRHash,
class HashFunc2 = APHash,
class HashFunc3 = DJBHash>
class BloomFilter
{
public:
void Set(const K &key)
{
size_t len = X * N;
size_t index1 = HashFunc1()(key) % len;
size_t index2 = HashFunc2()(key) % len;
size_t index3 = HashFunc3()(key) % len;
/* cout << index1 << endl;
cout << index2 << endl;
cout << index3 << endl<<endl;*/
_bs.set(index1);
_bs.set(index2);
_bs.set(index3);
}
bool Test(const K &key)
{
size_t len = X * N;
size_t index1 = HashFunc1()(key) % len;
if (_bs.test(index1) == false)
return false;
size_t index2 = HashFunc2()(key) % len;
if (_bs.test(index2) == false)
return false;
size_t index3 = HashFunc3()(key) % len;
if (_bs.test(index3) == false)
return false;
return true;
// 存在误判的
}
// 不支持删除,删除可能会影响其他值。
void Reset(const K &key);
private:
bitset<X * N> _bs;
};
int main()
{
system("pause");
return 0;
}