前言
在上篇文章中,我们探讨了如何创造一个能够进行Connect4的对弈大脑。简单的介绍了几种对弈算法,例如极小化极大算法,Alpha-Beta剪枝算法等,最关键的是目前最流行的神经网络算法和深度学习。神经网络算法,让计算机也有一个想人类一样能够思考的大脑,设置独特的场景来进行学习下棋。在本篇文章中,我们将进一步探讨如何让机械臂来实现下棋动作,将想法给实现出来。(换句话说就是,AI机械臂下棋)
如果感兴趣欢迎观看上篇文章。
Introduction
下面的内容主要分为四个部分来进行介绍。
● 获取信息:用摄像头获取到棋盘上的信息,进行对弈
● 处理信息:处理获取到的信息识别出棋子的位置,通过对弈算法,计算出下一步棋子应该在哪里下
● 机械臂的轨迹:设计机械臂如何抓取棋子,设计放置棋子的路径
● 功能的整合:将上面三个功能结合在一起,实现AI机械臂下棋。复制

让我们一起来看看吧~
项目
获取信息
环境:python,最新版的opencv,numpy
首先需要获取棋盘的信息,信息包括棋盘,棋盘上的棋子。我们用到的是OpenCV当中cv2.aruco.ArucoDetector(dictionary, parameters)
该方法用来检测Aruco二维码,从图片当中标记出Aruco的位置,并且计算出标记的位置和姿态信息。这样就能够确定整个棋盘的位置了,确定四个角的位置。

Code:代码是用cv2.aruco.ArucoDetector(dictionary, parameters)方法来确定我们棋盘的位置。
dictionary = cv2.aruco.getPredefinedDictionary(cv2.aruco.DICT_6X6_250)
parameters = cv2.aruco.DetectorParameters()
detector = cv2.aruco.ArucoDetector(dictionary, parameters)
corners, ids, rejectedCandidates = detector.detectMarkers(bgr_data)
rvec, tvec, _ = cv2.aruco.estimatePoseSingleMarkers(corners, 0.05, self.mtx, self.dist)
if rvec is None or len(corners) != 4:
return None
# debug
if DEBUG:
debug_img = bgr_data.copy()
for i in range(rvec.shape[0]):
cv2.drawFrameAxes(debug_img, self.mtx, self.dist, rvec[i, :, :, ], tvec[i, :, :, ],
0.03)
# Draw a square around the marker.
cv2.aruco.drawDetectedMarkers(debug_img, corners)
cv2.imshow("debug1", debug_img)
# Sort the detected QR code corner points in the following order: top left, top right, bottom left, bottom right.
corners = np.mean(corners, axis=2)
corners = (np.ceil(corners)).astype(int)
corners = corners.reshape((4, 2))
cx, cy = (np.mean(corners[:, 0]), np.mean(corners[:, 1]))
res: list = [None for _ in range(4)]
for x, y in corners:
if x < cx and y < cy:
res[0] = (x, y)
elif x > cx and y < cy:
res[1] = (x, y)
elif x < cx and y > cy:
res[2] = (x, y)
else:
res[3] = (x, y)
res = np.array(res)
## debug code
if DEBUG:
debug_img = bgr_data.copy()
for p in res:
cv2.circle(debug_img, p, 3, BGR_GREEN, -1)
cv2.imshow("aruco", debug_img)
return res复制
确定完棋盘之后,我们用不同的颜色来当棋子,这里就用两种区分度比较大的颜色,红色和黄色,并且标注出来。
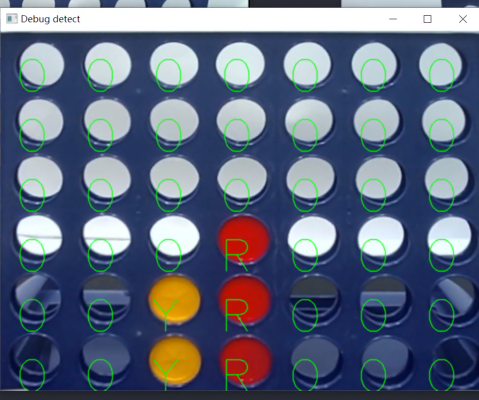
设置一个逻辑,当棋面每多一枚棋子的时候,将当前棋盘的数据返回给到对弈算法,进行判断下一步棋应该如何走。
处理信息
接下来需要处理棋盘的信息。
从上边可以看到我们获取到了棋盘的数据,接下来我们需要把数据,传递给对弈算法,让对弈算法将下一步棋子的位置预测出来。
下面是处理的伪代码:
functionmodel_predict(state, available_actions):
# 将available_actions转换为numpy数组
available_actions = np.array(available_actions)
# 对state进行扩展,以适应ONNX模型的输入要求
state = np.expand_dims(np.expand_dims(np.array(state, dtype=np.float32), axis=0), axis=0)
# 构建ONNX模型的输入
ort_inputs ={self.policy_net.get_inputs()[0].name: state}
# 进行模型预测,获取每个可用位置的预测值
r_actions =self.policy_net.run(None, ort_inputs)[0][0,:]
# 根据预测值选择最优的落子位置
state_action_values = np.array(
[r_actions[action]for action in available_actions])
argmax_action = np.argmax(state_action_values)
greedy_action = available_actions[argmax_action]
return greedy_action复制
该方法中的主要逻辑是使用ONNX模型来进行模型预测,并根据预测结果选择最优的落子位置。首先,将可用位置available_actions转换为numpy数组,并将当前游戏状态state进行扩展,以适应ONNX模型的输入要求。然后,将扩展后的state传递给ONNX模型进行预测,并将预测结果保存在r_actions变量中。接着,根据预测结果以及可用的落子位置,计算出每个可用位置的预测值,选取其中最大的一个对应的落子位置作为最优的落子位置,并将其返回。
机械臂的轨迹
大脑(对弈算法),眼睛(识别算法)都有了,现在就差一个手去执行动作。我们使用python库pymycobot来对机械臂进行控制。因为棋盘的原因,棋子只能从棋盘的上方投下,我们给每一条数列的棋个上设置一个坐标点位,就可以完成机械臂的路径规划了。因为棋面比较干净没有遮挡物,所以不用考虑过多的路径因素。
下面是机械臂运行轨迹位置的伪代码:
# 初始化定义几个坐标点
# 设定一个长度为7的列表
self.chess_table = [None for _ in range(7)]
self.chess_table[0]-[6] = [J1,J2,J3,J4,J5,J6] # 七个棋格的位置
self.angle_table = {
"recovery": [0, 0, 0, 0, 0, 0], #初始位置
"observe": [-2.54, 135.0, -122.95, -32.34, 2.46, -90.35],#观察位置
"stack-hover-1": [-47.19, -37.96, -58.53, 1.05, -1.93, -1.84],#吸取棋子的位置
}复制
接下来介绍一下pymycobot当中控制机械臂的一些方法:
#Sending the angle to the robotic arm.
self.send_angles(self.chess_table[n], ARM_SPEED)
#Sending the Cartesian coordinates to the robotic arm.
self.send_coords(coord_list,ARM_SPEED)复制
功能的整合
将功能点整合之前我们得整理它们之间的逻辑。
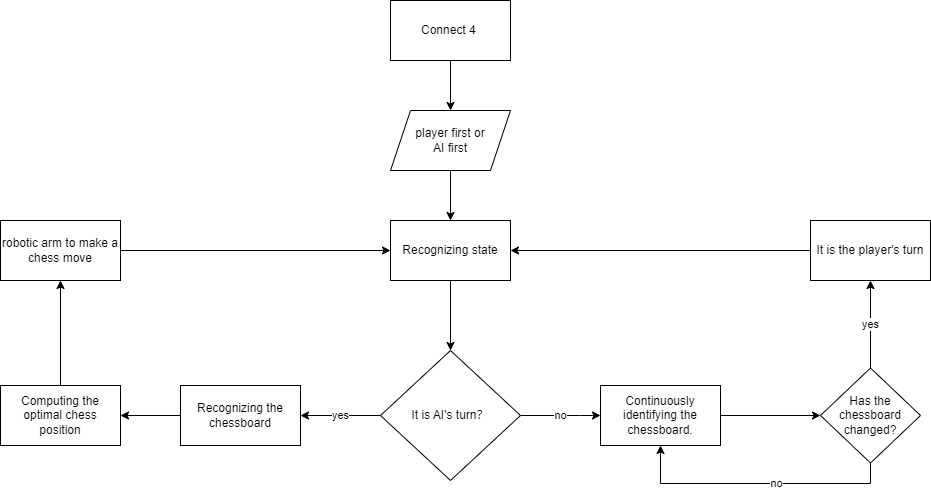
下棋的流程图有了接下来就是,将功能点结合在一起.
这是程序的结构文件。
├── Agent.py The logic of the robotic arm's gameplay.
├── ArmCamera.pyCamera control.
├── ArmInterface.py Robotics Arm control
├── Board.py Data structure of the chessboard and related judgments.
├── CameraDemo.py Small program for testing camera performance.
├── config.pyUtilized to define specific configuration details.
├── Detection.py Machine vision recognition.
├── dqn.ptNeural network model file, used to implement gameplay logic.
├── main.pymain program.
├── StateMachine.pyA state machine.
总结
从理论上来说的话,几乎没有人能够在赢得胜利。因为机器的算法可以预测到后面将要下在几步棋甚至更多,而对于普通人来说,一般能够预测的也就两三步棋。但是从视频上来看,AI只赢了一场比赛,输掉的那一场是因为结构因素的影响,本来该下的棋盘的位置,被迫换了一个地方。
你觉得这个项目有意思吗?我们会在后续将Connect4 这个套装进行完善后,上架在我们的网站,有兴趣的朋友可以关注我们,后续会进行更新。
你是否会尝试用机械臂来实现其他的棋艺呢?例如国际象棋,中国象棋等,不同的棋艺所使用的算法也会大大不同,欢迎大家在地下跟我们留言进行分享你们的想法。