本专栏是网易云课堂人工智能课程《神经网络与深度学习》的学习笔记,视频由网易云课堂与 deeplearning.ai 联合出品,主讲人是吴恩达 Andrew Ng 教授。感兴趣的网友可以观看网易云课堂的视频进行深入学习,视频的链接如下:
https://mooc.study.163.com/course/2001281002
也欢迎对神经网络与深度学习感兴趣的网友一起交流 ~
目录
1 神经网络的结构
2 激活函数
3 随机初始化
1 神经网络的结构

你可以把很多 sigmoid 单元堆叠起来,构建一个神经网络。神经网络的每个节点对应两个计算步骤:前一层输出的线性组合(z 值),以及非线性激活(a 值)。
对于包含 2 层 sigmoid 单元的神经网络,用 表示输入特征,第一层参数
,第二层参数
,有

神经网络可以分成输入层(Input Layer)、隐藏层(Hidden Layer)和输出层(Output Layer)。上图中的神经网络被称为双层神经网络(2 Layer Neural Network),输入层不被计算,原因是输入层不包含参数和非线性激活过程。
在使用监督学习的神经网络中,训练集包含了输入 x 和输出 y,隐藏层的含义是,在训练集中,你无法看到中间节点的数值。
2 激活函数

当构建神经网络时,你可以选择隐藏层用哪一个激活函数,以及输出单元用什么激活函数。
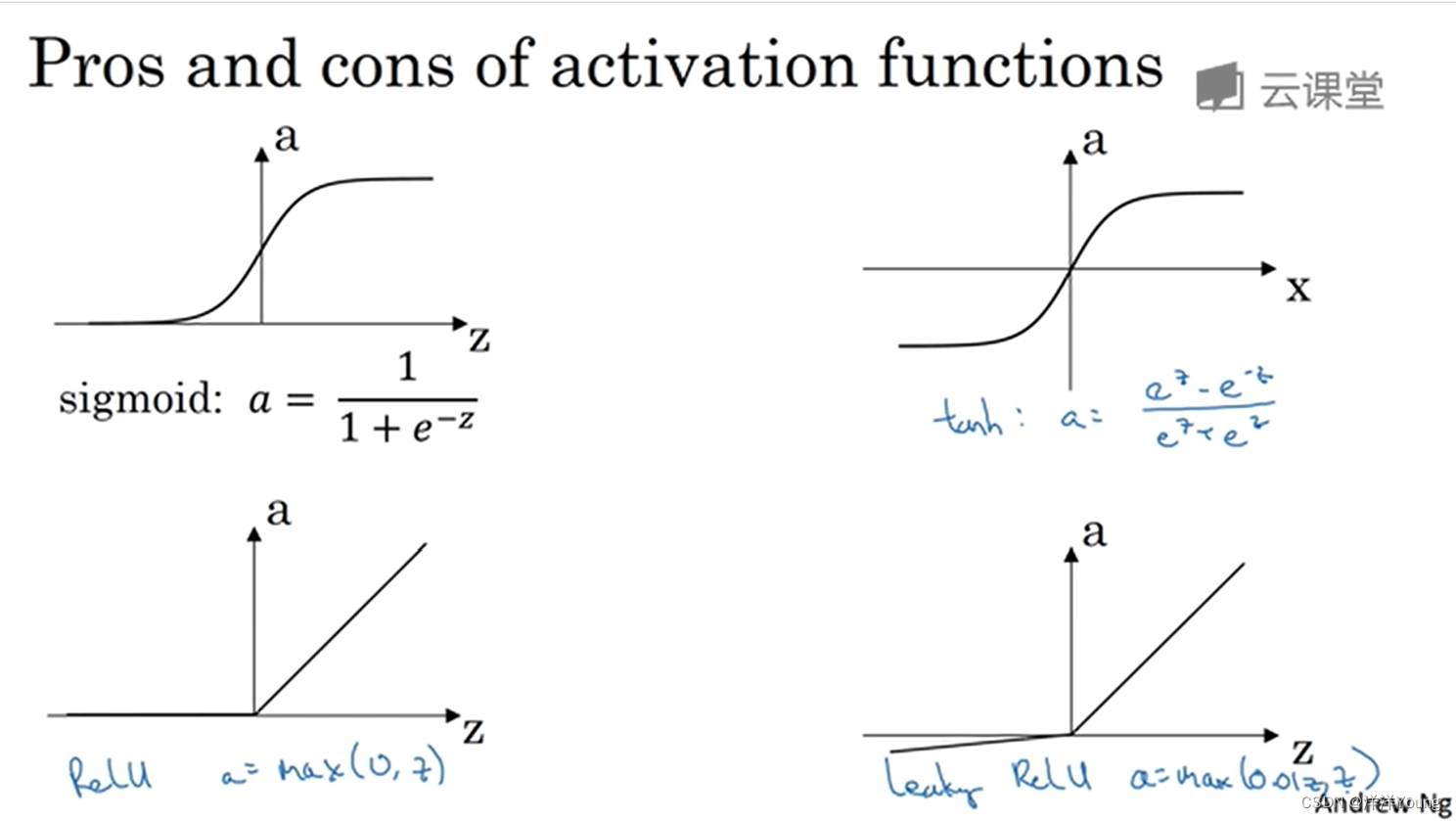
tanh 函数是 sigmoid 函数的平移版本。通常情况下,tanh 函数比 sigmoid 函数更好。但是这两个函数有一个·缺点:当 z 很大或很小时,函数的梯度值接近 0,这个问题被称为”梯度消失问题”。
另外两个常用的激活函数是 ReLU 函数和带泄露的 ReLU 函数。
3 随机初始化

当训练神经网络时,初始化权重的选取非常重要。对于 Logistic 回归,你可以将初始权重设为 0。但是对于神经网络,在初始值全 0 的情况下,神经网络中的隐藏单元都在进行完全相同的计算,这时隐藏单元的数量将失去意义。

问题的解决方案是随机初始化权重 ,通常的做法是使用 random 函数随机生成数值,为了避免初始权值太大导致梯度下降法变慢,可以乘上一个小的系数,比如 0.01,不过偏置值
是可以初始化为 0 的。