使用OpenCV工具包实现人脸检测与人脸识别(吐血整理!)
- OpenCV实现人脸检测
- OpenCV人脸检测方法
- 基于Haar特征的人脸检测
- Haar级联检测器预训练模型下载
- Haar 级联分类器
- OpenCV-Python实现
- 基于深度学习的人脸检测
- 传统视觉方法与深度学习方法对比
- OpenCV实现人脸识别
- 制作数据集
- 加载数据集
- 训练数据集
- 单张图片测试
OpenCV实现人脸检测
要实现人脸识别功能,首先要进行人脸检测,判断出图片中人脸的位置,才能进行下一步的操作。
参考链接:
1、OpenCV人脸检测
2、【OpenCV-Python】32.OpenCV的人脸检测和识别——人脸检测
3、【youcans 的图像处理学习课】23. 人脸检测:Haar 级联检测器
4、OpenCV实战5:LBP级联分类器实现人脸检测
5、计算机视觉OpenCv学习系列:第十部分、实时人脸检测
OpenCV人脸检测方法
在OpenCV中主要使用了两种特征(即两种方法)进行人脸检测,Haar特征和LBP特征。用的最多的是Haar特征人脸检测,此外OpenCV中还集成了深度学习方法来实现人脸检测。
基于Haar特征的人脸检测
Haar级联检测器预训练模型下载
在OpenCV中,使用已经训练好的XML格式的分类器进行人脸检测。在OpenCV的安装目录下的sources文件夹里的data文件夹里或者在github上下载opencv源代码,在源代码的data文件夹里都可以找到模型文件:
https://github.com/opencv/opencv/tree/4.x/data


haarcascade_eye.xml, 眼睛
haarcascade_eye_tree_eyeglasses.xml, 戴眼镜的眼睛
haarcascade_frontalcatface.xml, 正面猫脸
haarcascade_frontalcatface_extended.xml, 正面猫脸
haarcascade_frontalface_alt.xml, 正面人脸
haarcascade_frontalface_alt2.xml, 正面人脸
haarcascade_frontalface_alt_tree.xml, 正面人脸
haarcascade_frontalface_default.xml, 正面人脸
haarcascade_fullbody.xml, 人体
haarcascade_lefteye_2splits.xml, 左眼
haarcascade_license_plate_rus_16stages.xml,
haarcascade_lowerbody.xml,
haarcascade_profileface.xml,
haarcascade_righteye_2splits.xml, 右眼
haarcascade_russian_plate_number.xml,
haarcascade_smile.xml, 笑脸
haarcascade_upperbody.xml, 上身
Haar 级联分类器
基于 Haar 特征的级联分类器是 Paul Viola 在论文”Rapid Object Detection using a Boosted Cascade of Simple Features”中提出的一种目标检测方法。
Haar 级联分类器在每一级的节点中,使用 AdaBoost 算法学习一个高检测率低拒绝率的多层分类器。其特点是:
- 使用 Haar-like 输入特征,对矩形图像区域的和或者差进行阈值化。
- 使用积分图像计算 45°旋转区域的像素和,加速 Haar-like 输入特征的计算。
- 使用统计 Boosting 来创建二分类(人脸/非人脸)的分类器节点(高通过率,低拒绝率)。
- 将弱分类器并联组合起来,构成筛选式级联分类器。
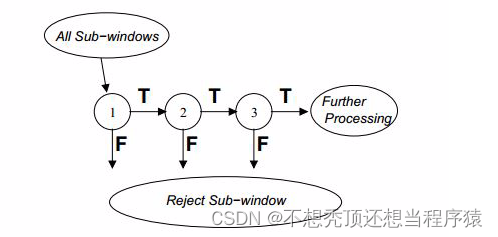
各级的 Boosting 分类器对于有人脸的检测窗口都能通过,同时拒绝一小部分非人脸的检测窗口,并将通过的检测窗口传给下一个分类器。依次类推,最后一个分类器将几乎所有非人脸的检测窗口都拒绝掉,只剩下有人脸的检测窗口。因此,只要检测窗口区域通过了所有各级 Boosting 分类器,则认为检测窗口中有人脸。
在实际应用中输入图片的尺寸较大,需要进行多区域、多尺度的检测。多区域是要遍历图片的不同位置,多尺度是为了检测图片中不同大小的人脸。
在 Haar 级联分类人脸检测器中,主要利用了人脸的结构化特征:
1)与脸颊相比,眼部颜色较深
2)与眼睛相比,鼻梁区域较为明亮
3)眼睛、嘴巴、鼻子的位置较为固定
通过这 5 个矩形区域的明暗关系,就可以形成对人脸的各个部分的判别特征。例如在下图中,第一个特征检测眼部和上脸颊之间的强度差异,第二个特征检测双眼的间距。

Haar 人脸检测正脸检测识别率很高,但对侧脸的检测性能较差。
OpenCV-Python实现
使用 Haar 级联检测器检测图片中的人脸的步骤:
(1)创建一个 CascadeClassifier 级联分类器对象,从 .xml 文件加载级联分类器模型。
(2)读取待检测的图片。
(3)使用 detectMultiScale() 方法检测图片,返回检测到的面部或眼睛的边界矩形。
(4)将检测到的边界矩形绘制到检测图片上。
OpenCV 中定义了级联分类器类 cv::CascadeClassifier。在 Python 语言中,使用接口函数 cv2.CascadeClassifier() 从文件创建分类器。成员函数 cv.CascadeClassifier.detectMultiScale() 用于执行对图像进行目标检测。
import cv2
cv2.CascadeClassifier.detectMultiScale(image[, scaleFactor=1.1, minNeighbors=3, flags=0, minSize=Size(), maxSize=Size()]) → objects
参数说明:
- filename:加载分类器模型的文件路径和名称,字符串。加载的级联分类器模型文件,扩展名为 .xml。
- image:待检测的输入图像,CV_8U 格式。
- scaleFactor:搜索窗口的缩放比例,默认值为1.1。
- minNeighbors:表示构成检测目标的相邻矩形的最小个数,默认值为 3。
- flags:版本兼容标志,默认值为 0。
- minSize:检测目标的最小尺寸,元组 (h,w)。
- maxSize:检测目标的最大尺寸,元组 (h,w)。
返回值
- objects:返回值,检测目标的矩形边界框 ,是形如 (N,4) 的Numpy数组。每行有 4个元素 (x, y, width, height) 表示矩形框的左上顶点坐标 (x,y) 和宽度 width、高度 height。
使用Haar 级联检测器检测图片中的人脸:
import numpy as np
import cv2 as cv
if __name__ == '__main__':
# (6) 使用 Haar 级联分类器 预训练模型 检测人脸
# 读取待检测的图片
img = cv.imread("../data/single.jpg")
print(img.shape)
# 加载 Haar 级联分类器 预训练模型
model_path = "../data/haarcascade_frontalface_alt2.xml"
face_detector = cv.CascadeClassifier(model_path) # <class 'cv2.CascadeClassifier'>
# 使用级联分类器检测人脸
faces = face_detector.detectMultiScale(img, scaleFactor=1.1, minNeighbors=1,
minSize=(30, 30), maxSize=(300, 300))
print(faces.shape) # (17, 4)
print(faces[0]) # (x, y, width, height)
# 绘制人脸检测框
for x, y, width, height in faces:
cv.rectangle(img, (x, y), (x + width, y + height), (0, 0, 255), 2, cv.LINE_8, 0)
# 显示图片
cv.imshow("faces", img)
cv.waitKey(0)
cv.destroyAllWindows()

使用Haar 级联检测器检测图片中的人眼:
人眼检测的方法与人脸检测方法相同,只是使用了不同的预训练模型,例如 haarcascade_eye.xml。
由于眼睛比人脸的尺寸小,因此减小了检测函数 detectMultiScale() 的参数 minSize=(20, 20)。
此外scaleFactor和minNeighbors也会影响到检测出的人眼个数。
import cv2 as cv
if __name__ == '__main__':
# (7) 使用 Haar 级联分类器 预训练模型 检测人眼
# 读取待检测的图片
img = cv.imread("./data/single.jpg")
print(img.shape)
# 加载 Haar 级联分类器 预训练模型
model_path = "./data/haarcascade_eye.xml"
eye_detector = cv.CascadeClassifier(model_path) # <class 'cv2.CascadeClassifier'>
# 使用级联分类器检测人脸
eyes = eye_detector.detectMultiScale(img, scaleFactor=1.1, minNeighbors=10,
minSize=(10, 10), maxSize=(80, 80))
# 绘制人脸检测框
for x, y, width, height in eyes:
cv.rectangle(img, (x, y), (x + width, y + height), (0, 0, 255), 2, cv.LINE_8, 0)
# 显示图片
cv.imshow("Haar_Cascade", img)
# cv.imwrite("../images/imgSave3.png", img)
cv.waitKey(0)
cv.destroyAllWindows()

scaleFactor=1.1, minNeighbors=10
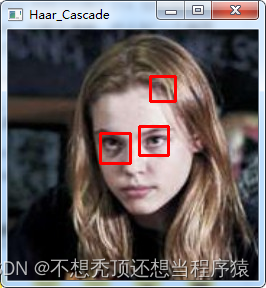
scaleFactor=1.1, minNeighbors=5
使用 Haar 级联检测器同时检测人脸和人眼
为了提高检测效率,可以先检测人脸,再在人类窗口内检测人眼,不仅可以提高检测效率,而且可以提高检测精度。
import cv2 as cv
if __name__ == '__main__':
# (8) 使用 Haar 级联分类器 预训练模型 检测人脸和人眼
# 读取待检测的图片
img = cv.imread("./data/multiface1.jpeg")
print(img.shape)
# 加载 Haar 级联分类器 预训练模型
face_path = "./data/haarcascade_frontalface_alt2.xml" # 人脸检测器
face_detector = cv.CascadeClassifier(face_path) # <class 'cv2.CascadeClassifier'>
eye_path = "./data/haarcascade_eye.xml" # 人眼检测器
eye_detector = cv.CascadeClassifier(eye_path) # <class 'cv2.CascadeClassifier'>
# 使用级联分类器检测人脸
faces = face_detector.detectMultiScale(img, scaleFactor=1.1, minNeighbors=5,
minSize=(30, 30), maxSize=(300, 300))
print(faces.shape) # (15, 4)
# 绘制人脸检测框
for x, y, width, height in faces:
cv.rectangle(img, (x, y), (x + width, y + height), (0, 0, 255), 2, cv.LINE_8, 0)
# 在人脸区域内检测人眼
roi = img[y:y + height, x:x + width] # 提取人脸
# 检测人眼
eyes = eye_detector.detectMultiScale(roi, scaleFactor=1.1, minNeighbors=1,
minSize=(2, 2), maxSize=(80, 80))
# 绘制人眼
for ex, ey, ew, eh in eyes:
cv.rectangle(img, (x+ex, y+ey), (x+ex+ew, y+ey+eh), (255, 0, 0), 2)
# 显示图片
cv.imshow("Haar_Cascade", img)
# cv.imwrite("../images/imgSave4.png", img)
cv.waitKey(0)
cv.destroyAllWindows()

可以看到对于比较正常的人脸检测效果还是不错的(需要手动调整detectMultiScale()方法的参数),但是对于侧脸、歪脸、小脸的检测效果就不太理想了,而且对于眼睛的检测只能画框,不能实现关键点检测,现在在考虑利用这个人眼检测转换成关键点来做人脸对齐,后面再看看效果。
基于深度学习的人脸检测
OpenCV的深度神经网络(Deep Neural Network,DNN)模块提供了基于深度学习的人脸检测器。DNN模块中使用了广受欢迎的深度学习框架,包括Caffe、TensorFlow、Torch和Darknet等。
OpenCV提供了两个预训练的人脸检测模型:Caffe和TensorFlow模型。
Caffe模型需要加载以下两个文件:
- deploy.prototxt:定义模型结构的配置文件
- res10_300x300_ssd_iter_140000_fp16.caffemodel:包含实际层权重的训练模型文件
TensorFlow模型需要加载以下两个文件:
- opencv_face_detector_uint8.pb:定义模型结构的配置文件
- opencv_face_detector.pbtxt:包含实际层权重的训练模型文件
在OpenCV源代码的“\samples\dnn\face_detector”的文件夹中提供了模型配置文件,但未提供模型训练文件。可运行该文件夹中的download_models.py文件下载上述两个训练模型文件。或直接在官方链接https://github.com/spmallick/learnopencv/find/master(这个链接太难下了)下载,在这个链接下载:OpenCV学堂/OpenCV课程资料https://gitee.com/opencv_ai/opencv_tutorial_data(关键时刻靠Gitee)
(在搜索框中输入Age进行搜索,不然找不到) 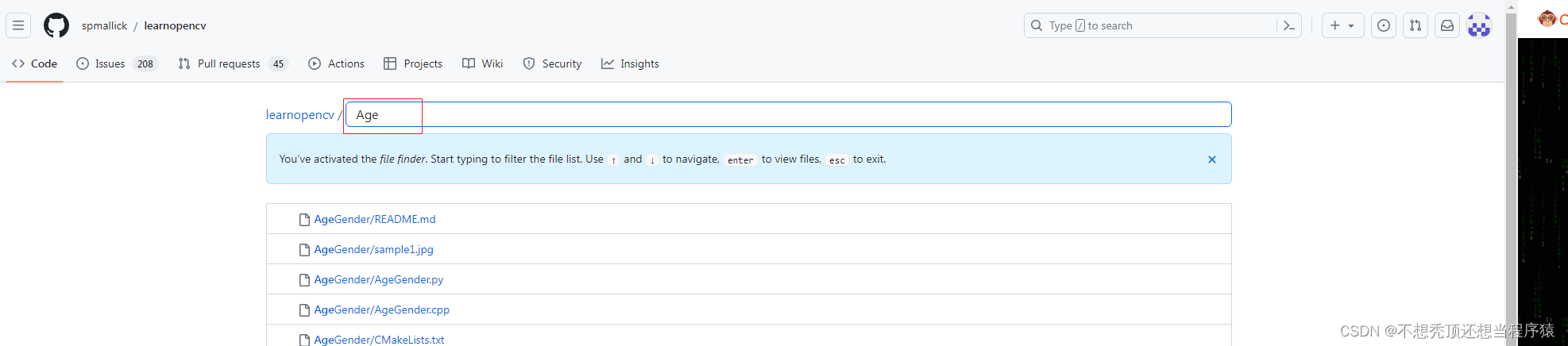

使用预训练的模型执行人脸检测时主要包含下列步骤:
(1) 调用cv2.dnn.readNetFromCaffe()或cv2.dnn.readNetFromTensorflow()函数加载模型,创建检测器。
(2) 调用cv2.dnn.blobFromImage()函数将待检测图像转换为图像块数据。
(3) 调用检测器的setInput()方法将图像块数据设置为模型的输入数据。
(4) 调用检测器的forward()方法执行计算,获得预测结果。
(5) 将可信度高于指定值的预测结果作为检测结果,在原图中标注人脸,同时输出可信度作为参考。
单张图片检测
# 基于深度学习的人脸检测(脸-眼_视频)
import cv2
import numpy as np
# dnnnet = cv2.dnn.readNetFromCaffe("deploy.prototxt", "res10_300x300_ssd_iter_140000_fp16.caffemodel")
dnnnet = cv2.dnn.readNetFromTensorflow("./data/opencv_face_detector_uint8.pb", "./data/opencv_face_detector.pbtxt")
img = cv2.imread("./data/multiface1.jpeg")
h, w = img.shape[:2]
blobs = cv2.dnn.blobFromImage(img, 1.0, (300, 300), [104., 117., 123.], False, False)
dnnnet.setInput(blobs)
detections = dnnnet.forward()
faces = 0
for i in range(0, detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.6:
faces += 1
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
x1,y1,x2,y2 = box.astype("int")
y = y1 - 10 if y1 - 10 > 10 else y1 + 10
text = "%.3f"%(confidence * 100)+'%'
cv2.rectangle(img, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.putText(img,text, (x1, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)
cv2.imshow('faces',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
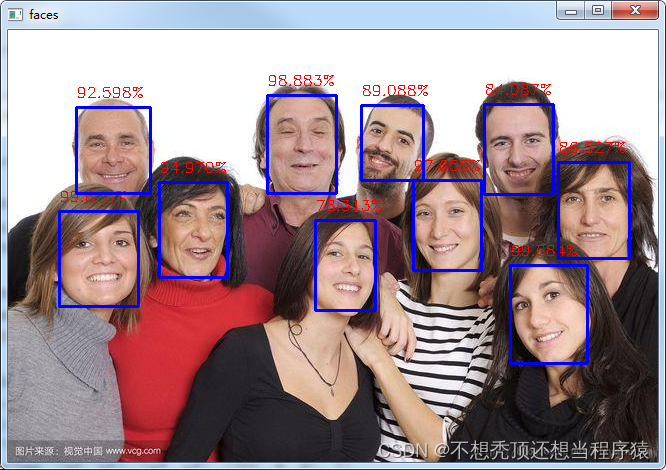
相比之下,还是深度学习模型的效果更胜一筹。
视频检测
import cv2
import numpy as np
# win7系统在代码中所有的cv2.VideoCapture要加cv2.CAP_DSHOW,不然会报错
capture = cv2.VideoCapture(0, cv2.CAP_DSHOW)
frame_width = capture.get(cv2.CAP_PROP_FRAME_WIDTH)
frame_height = capture.get(cv2.CAP_PROP_FRAME_HEIGHT)
fps = capture.get(cv2.CAP_PROP_FPS)
dnnnet = cv2.dnn.readNetFromTensorflow("./data/opencv_face_detector_uint8.pb", "./data/opencv_face_detector.pbtxt")
if capture.isOpened() is False:
print('CAMERA ERROR !')
exit(0)
while capture.isOpened():
ret, frame = capture.read()
if ret is True:
# cv2.imshow('FRAME', frame) # 显示捕获的帧
h, w = frame.shape[:2]
blobs = cv2.dnn.blobFromImage(frame, 1.0, (300, 300), [104., 117., 123.], False, False)
dnnnet.setInput(blobs)
detections = dnnnet.forward()
faces = 0
for i in range(0, detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.6:
faces += 1
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
x1, y1, x2, y2 = box.astype("int")
y = y1 - 10 if y1 - 10 > 10 else y1 + 10
text = "%.3f" % (confidence * 100) + '%'
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.putText(frame, text, (x1, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)
cv2.imshow('faces', frame)
k = cv2.waitKey(1)
if k == ord('q'):
break
else:
break
capture.release()
cv2.destroyAllWindows()
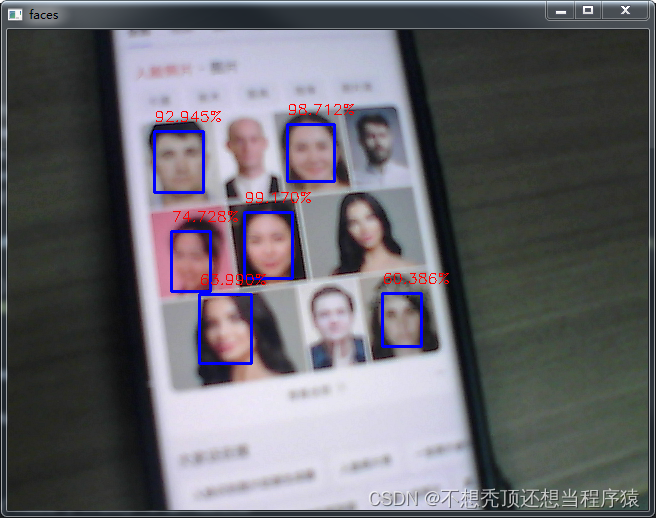
把手机放在摄像头前进行检测,可以看到有些人脸还是检测不出来,后面可以考虑加入活体检测。
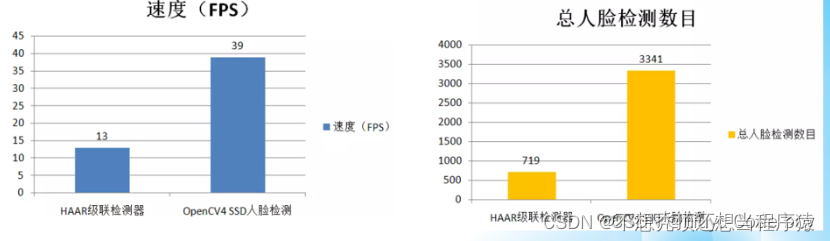
传统视觉方法与深度学习方法对比
针对同一段视频文件,速度与检测总数统计比较
OpenCV实现人脸识别
参考链接:
1、opencv的人脸面部识别(主要代码参考)
2、【OpenCV-Python】33.OpenCV的人脸检测和识别——人脸识别
自己根据博主的代码做了适当的修改,符合自己项目的要求
OpenCV 有三种人脸识别的算法:
特征脸(Eigenfaces)人脸识别 是通过 PCA(主成分分析)实现的,它识别人脸数据集的主成分,并计算出待识别图像区域相对于数据集的发散程度(0-20k),该值越小,表示差别越小,0值代表完全匹配。低于4k-5k都是相当可靠的识别。
EigenFaces人脸识别的基本步骤如下:
(1) 调用cv2.face.EigenFaceRecognizer_create()方法创建EigenFace识别器。
(2) 调用识别器的train()方法以便使用已知图像训练模型。
(3) 调用识别器的predict()方法以便使用未知图像进行识别,确认其身份。
cv2.face.EigenFaceRecognizer_create()函数的基本格式如下:
recognizer = cv2.face.EigenFaceRecognizer_create([num_components[, threshold]])
# recognizer为返回的EigenFaces识别器对象
# num_components为分析时的分量数量, 默认为0, 表示根据实际输入决定
# threshold为人脸识别时采用的阈值
EigenFaces识别器的train()方法的基本格式如下:
recognizer.train(src, label)
# src为用于训练的已知图像数组, 所有图像必须为灰度图且大小要相同
# label为标签数组, 与已知图像数组中的人脸一一对应, 同一个人的人脸标签应设置为相同值
EigenFaces识别器的predict()方法的基本格式如下:
label, confidence = recoginer.predict(testimg)
# label为返回的标签值
# confidence为返回的可信度, 表示未知人脸和模型中已知人脸之间的距离, 0表示完全匹配, 低于5000可认为是可靠的匹配结果
# test_img为未知人脸图像, 图像必须为灰度图且大小要与训练图像相同
人鱼脸(FisherFaces)人脸识别 是从 PCA发展而来,使用线性判别分析(Linear Discriminant Analysis,LDA)方法实现人脸识别,采用更复杂的计算,容易得到更准确的结果。低于4k~5k都是相当可靠的识别。
FisherFaces人脸识别的基本步骤如下:
(1) 调用cv2.face.FisherFaceRecognizer_create()方法创建FisherFaces识别器。
(2) 调用识别器的train()方法以便使用已知图像训练模型。
(3) 调用识别器的predict()方法以便使用未知图像进行识别,确认其身份。
在OpenCV中,cv2.face.EigenFaceRecognizer类和cv2.face.FisherFaceRecognizer类同属于cv2.face.BasicFaceRecognizer类、cv2.face.FaceRecognizer类和cv2.Algorithm类的子类,对应的xxx_create()、train()和predict()等方法的基本格式与用法相同。
局部二进制编码直方图(Local Binary Patterns Histograms,LBPH)人脸识别 将人脸分成小单元,并将其与模型中的对应单元进行比较,对每个区域的匹配值产生一个直方图。它允许待检测人脸区域可以和数据集中图像的形状、大小不同,更方便灵活。参考值低于50则算是好的识别,高于80则认为比较差。
LBPH算法处理图像的基本原理如下:
(1) 取像素x周围(领域)的8个像素与其比较,像素值比像素x大的取0,否则取1。将8个像素对应的0、1连接得到一个8位二进制数,将其转换为十进制,作为像素x的LBP值。
(2) 对像素的所有像素按相同的方法进行处理,得到整个图像的LBP值,该图像的直方图就是图像的LBPH。
LBPH人脸识别的基本步骤如下;
(1) 调用cv2.face.LBPHFaceRecognizer_create()方法创建LBPH识别器。
(2) 调用识别器的train()方法以便使用已知图像训练模型。
(3) 调用识别器的predict()方法以便使用未知图像进行识别,确认其身份。
cv2.face.LBPHFaceRecognizer_create()函数的基本格式如下:
recognizer = cv2.face.LBPHFaceRecognizer_create([radius[, neighbors[, grid_x[, grid_y[, threshold]]]]])
# recognizer为返回的LBPH识别器对象
# radius为邻域的半径大小
# neighbors为邻域内像素点的数量, 默认为8
# grid_x为将LBP图像划分为多个单元格时, 水平方向上的单元格数量, 默认为8
# grid_y为将LBP图像划分为多个单元格时, 垂直方向上的单元格数量, 默认为8
# threshold为人脸识别时采用的阈值
LBPH识别器的train()方法的基本格式如下:
recognizer.train(src, label)
# src为用于训练的已知图像数组, 所有图像必须为灰度图且大小要相同
# label为标签数组, 与已知图像数组中的人脸一一对应, 同一个人的人脸标签应设置为相同值
LBPH识别器的predict()方法的基本格式如下:
label, confidence = recoginer.predict(testimg)
# label为返回的标签值
# confidence为返回的可信度, 表示未知人脸和模型中已知人脸之间的距离, 0表示完全匹配, 低于50可认为是非常可靠的匹配结果
# test_img为未知人脸图像, 图像必须为灰度图且大小要与训练图像相同
制作数据集
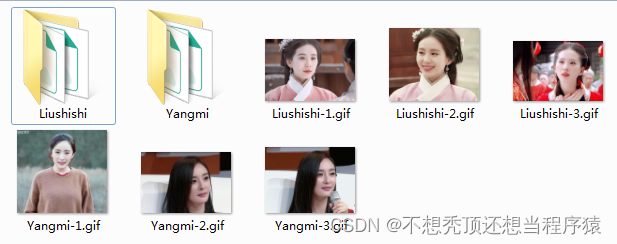
不管使用哪种算法都需要有训练集。从视频或者动图创建训练集的效率比较高。可以从网上下载或者自己写一个摄像头捕获程序进行采集。本次实验直接从网上下载了一些明星的动图,然后将动图按帧分解,使用OpenCV中的Haar级联器检测人脸区域,然后将人脸区域全部存为200X200的灰度图,存入对应的文件夹中,创建训练集。
from PIL import Image
import os
import cv2
import numpy as np
# GIF动图转图片
def gifSplit2Array(gif_path):
import numpy as np
img = Image.open(os.path.join(path, gif_path))
for i in range(img.n_frames):
img.seek(i)
new = Image.new("RGBA", img.size)
new.paste(img)
arr = np.array(new).astype(np.uint8) # image: img (PIL Image):
yield arr[:, :, 2::-1] # 逆序(RGB 转BGR), 舍弃alpha通道, 输出数组供openCV使用
# 人脸检测
def face_generate(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
front_face_cascade = cv2.CascadeClassifier('./data/haarcascade_frontalface_alt2.xml') # 检测正脸
faces0 = front_face_cascade.detectMultiScale(gray, 1.02, 5)
eye_cascade = cv2.CascadeClassifier('./data/haarcascade_eye_tree_eyeglasses.xml') # 检测眼睛
if faces0 is not None:
for (x, y, w, h) in faces0:
face_area = gray[y: y + h, x: x + w] # (疑似)人脸区域
quasi_eyes = eye_cascade.detectMultiScale(face_area, 1.03, 5, 0) # 在人脸区域检测眼睛
if len(quasi_eyes) == 0: continue
quasi_eyes = tuple(
filter(lambda x: x[2] / w > 0.18 and x[1] < 0.5 * h, quasi_eyes)) # ex,ey,ew,eh; ew/w>0.18,尺寸过滤 ,且眼睛在脸的上半部
if len(quasi_eyes) <= 1: continue
yield cv2.resize(face_area, (200, 200))
# 制作数据集
def get_dataset(path, gif_list):
i = 0
all_items = os.listdir(path)
print(all_items)
for item in all_items:
name = item.split('-')[0]
name_path = os.path.join(path, name)
if not os.path.exists(name_path):
os.mkdir(name_path)
for gif in gif_list:
print(gif)
for img in gifSplit2Array(gif):
for face in face_generate(img):
cv2.imwrite("./dataset/%s/%s.pgm" % (gif.split('-')[0], i), face)
# print(i)
i += 1
if __name__ == '__main__':
path = './dataset'
gif_list = ["Yangmi-1.gif", "Yangmi-2.gif", "Yangmi-3.gif", "Liushishi-1.gif", "Liushishi-2.gif", "Liushishi-3.gif"]
get_dataset(path, gif_list)
加载数据集
将所有数据放在一个ndarray数组中
def load_dataset(datasetPath):
names = []
X = []
y = []
ID = 0
for name in os.listdir(datasetPath):
subpath = os.path.join(datasetPath, name)
if os.path.isdir(subpath):
names.append(name)
for file in os.listdir(subpath):
im = cv2.imread(os.path.join(subpath, file), cv2.IMREAD_GRAYSCALE)
X.append(np.asarray(im, dtype=np.uint8))
y.append(ID)
ID += 1
X = np.asarray(X)
y = np.asarray(y, dtype=np.int32)
return X, y, names
训练数据集
X, y, names = load_dataset(path)
# 报错找不到face模块是因为只安装了主模块
# pip uninstall opencv-python, pip install opencv0-contrib-python
# 创建人脸识别模型(三种识别模式)
# model = cv2.face.EigenFaceRecognizer_create() #createEigenFaceRecognizer()函数已被舍弃
# model = cv2.face.FisherFaceRecognizer_create()
model = cv2.face.LBPHFaceRecognizer_create()
model.train(X, y)
单张图片测试
注意:将face_generate()函数最后一行改为
yield cv2.resize(face_area, (200, 200)), x, y, w, h
开始进行测试
path = './dataset'
infer_path = './data/Yangmi.jpeg'
# gif_list = ["Yangmi-1.gif", "Yangmi-2.gif", "Yangmi-3.gif", "Liushishi-1.gif", "Liushishi-2.gif", "Liushishi-3.gif"]
# get_dataset(path, gif_list)
X, y, names = load_dataset(path)
# 报错找不到face模块是因为只安装了主模块
# pip uninstall opencv-python, pip install opencv0-contrib-python
# 创建人脸识别模型(三种识别模式)
# model = cv2.face.EigenFaceRecognizer_create() #createEigenFaceRecognizer()函数已被舍弃
# model = cv2.face.FisherFaceRecognizer_create()
model = cv2.face.LBPHFaceRecognizer_create()
model.train(X, y)
img = cv2.imread(infer_path)
for roi, x, y, w, h in face_generate(img):
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2) # 画红色矩形框标记正脸
ID_predict, confidence = model.predict(roi) # 预测!!!
name = names[ID_predict]
print("name:%s, confidence:%.2f" % (name, confidence))
text = name if confidence < 70 else "unknow" # 10000 for EigenFaces #70 for LBPH
cv2.putText(img, text, (x, y - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2) # 绘制绿色文字
cv2.imshow('', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
测试效果:

补充: 这个实现方法完全使用opencv中的自带方法,目前只是进行了单张图片的识别,并且数据集比较小,在实际的环境中识别效果有待验证,并且没有加入自己写的人脸对齐程序,后面希望能结合进去,提高识别效果










![[pyqt5]动态加载ui文件并给菜单的一个子菜单添加触发事件](https://img-blog.csdnimg.cn/ad24761c821144809db7882259ffc067.jpeg)