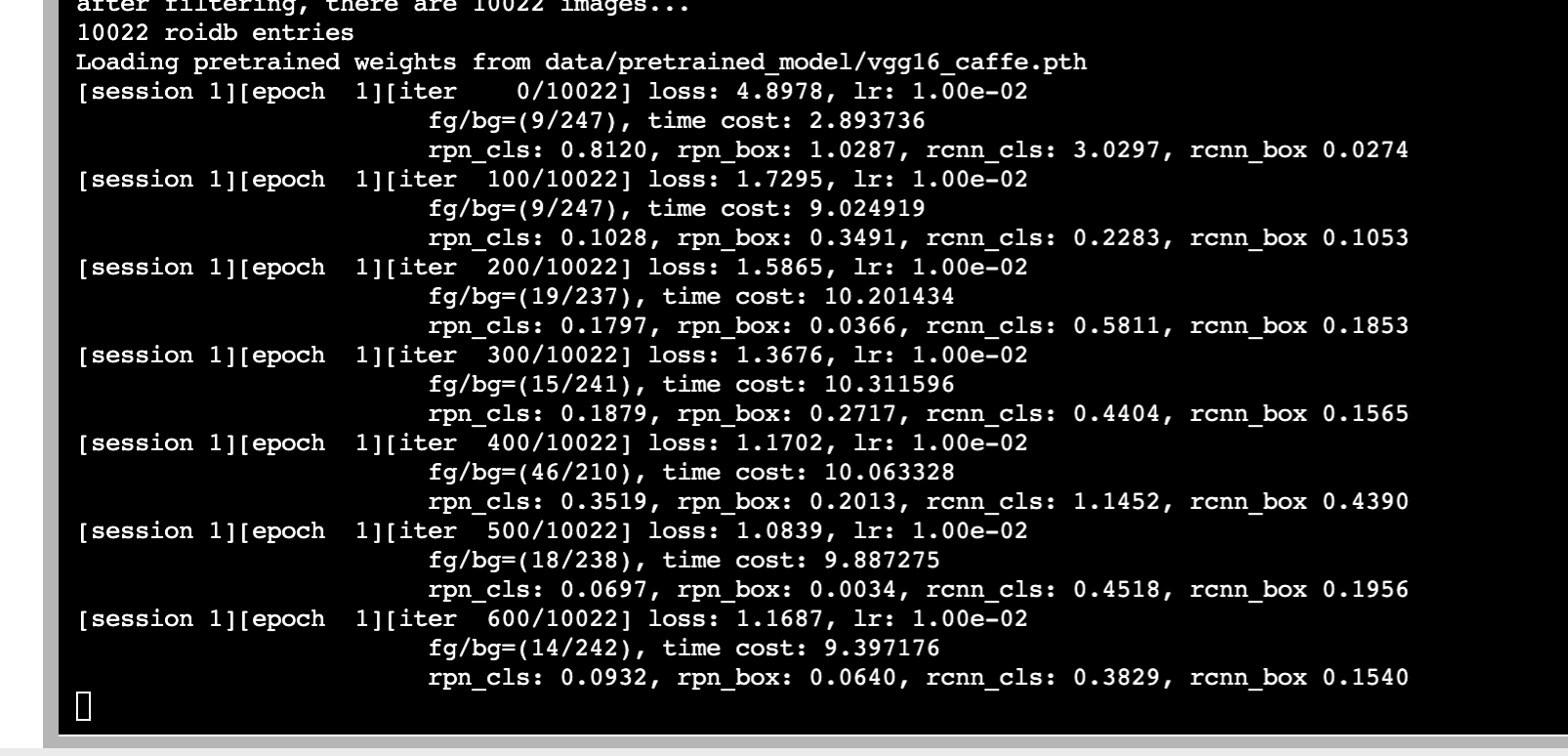
最近在做一个分割数据集,训练数据时由于图像数据太大一直爆显存,然后就找了找同时resize图像和json的脚本,然后转换为YOLO格式一直出问题,标签和目标位置对不上,也是困扰了好久,终于解决,记录一下。
首先是resize图像和json,下面是找到的一个脚本,他可以自定义宽高其中一个,另一个根据比例改变,参考的这个链接对labelme已经标注的图片和json文件做resize操作_Yee_Ko的博客-CSDN博客
这个src_dir和 dst_dir是处理前后的路径,src_dir里要同时放图像和json,w_new = “”这里改你想要的大小
import cv2
import os
import glob
import json
import collections
import numpy as np
from labelme import utils
#这个文件可以更改图像和json文件的分辨率,但是是宽高改一个,另一个比例改,改后的json文件图像的宽高有问题
#需要用到json_hw更改
if __name__ == "__main__":
src_dir = r'E:\seg_resize\before'
dst_dir = r'E:\seg_resize\after'
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
# 先收集一下文件夹中图片的格式列表,例如 ['.jpg', '.JPG']
exts = dict()
filesnames = os.listdir(src_dir)
for filename in filesnames:
name, ext = filename.split('.')
if ext != 'json':
if exts.__contains__(ext):
exts[ext] += 1
else:
exts[ext] = 1
anno = collections.OrderedDict() # 这个可以保证保存的字典顺序和读取出来的是一样的,直接使用dict()的话顺序会很乱(小细节哦)
for key in exts.keys():
for img_file in glob.glob(os.path.join(src_dir, '*.' + key)):
file_name = os.path.basename(img_file)
print(f"Processing {file_name}")
img = cv2.imread(img_file)
(h, w, c) = img.shape # 统计了一下,所有图片的宽度里面,1344是占比较多的宽度中最小的那个,因此
# 都等比例地将宽resize为1344(这里可以自己修改)
w_new = 1440
h_new = int(h / w * w_new) # 高度等比例缩放
ratio = w_new / w # 标注文件里的坐标乘以这个比例便可以得到新的坐标值
img_resize = cv2.resize(img, (w_new, h_new)) # resize中的目标尺寸参数为(width, height)
cv2.imwrite(os.path.join(dst_dir, file_name), img_resize)
# 接下来处理标注文件json中的标注点的resize
json_file = os.path.join(src_dir, file_name.split('.')[0] + '.json')
save_to = open(os.path.join(dst_dir, file_name.split('.')[0] + '.json'), 'w')
with open(json_file, 'rb') as f:
anno = json.load(f)
for shape in anno["shapes"]:
points = shape["points"]
points = (np.array(points) * ratio).astype(int).tolist()
shape["points"] = points
# 注意下面的img_resize编码加密之前要记得将通道顺序由BGR变回RGB
anno['imageData'] = str(utils.img_arr_to_b64(img_resize[..., (2, 1, 0)]), encoding='utf-8')
json.dump(anno, save_to, indent=4)
print("Done")
但是用这个脚本处理后,我想使用YOLOv8做实例分割,后来发现怎么也转换不对,经过别人提醒,原因是json转txt的代码中获取的是json中的图像长宽计算的,这个脚本并没有改变json中记录的原图像长宽,所以写了一个文件根据resize后的图像长宽去改json中的值,命名为json_hw.py,下边代码中的json_dir和image_dir要放你的json和resize后图像的路径,到这步就改完了json文件了。
import json
import os
from PIL import Image
#这是一个调整图像分辨率后,但是json文件记录的高宽没有改变,使用这个脚本可以将json文件中的图像高宽改为实际图像高宽
def update_image_resolution(json_dir, image_dir):
json_files = os.listdir(json_dir)
for json_file in json_files:
json_path = os.path.join(json_dir, json_file)
image_path = os.path.join(image_dir, os.path.splitext(json_file)[0] + '.jpg')
# 读取JSON文件
with open(json_path, 'r') as f:
data = json.load(f)
# 获取图像的实际大小
image = Image.open(image_path)
width, height = image.size
# 更新JSON文件中的分辨率字段
data['imageHeight'] = height
data['imageWidth'] = width
# 保存更新后的JSON文件
with open(json_path, 'w') as f:
json.dump(data, f, indent=4)
if __name__ == "__main__":
json_dir = r'E:\yolov5-master\mydata\json'
image_dir = r'E:\yolov5-master\mydata\images'
update_image_resolution(json_dir, image_dir)
然后随便找了一个json转YOLO的txt格式的脚本,这个一搜很多,我这里随便放一个,json-dir是你json文件的保存路径,save-dir是txt文件的保存路径,classes是你的数据集中的类别,我这代码中写了三类,分别是bud,inflorescence,branch,这三类的顺序和你YOLOv5或者v8的数据集的yaml文件对应好顺序就行,v5和v8都适用,我是用的下面这位博主提供的脚本,这个就是获取json中的图像长宽,也是resize后一直出问题的原因:h, w = json_dict['imageHeight'], json_dict['imageWidth']
YOLOv8实例分割训练自己的数据集保姆级教程_dg68668的博客-CSDN博客
# -*- coding: utf-8 -*-
import json
import os
import argparse
from tqdm import tqdm
from PIL import Image
#这是一个将json文件转换为YOLO格式的txt文件的脚本
def convert_label_json(json_dir, save_dir, classes):
json_paths = os.listdir(json_dir)
classes = classes.split(',')
for json_path in tqdm(json_paths):
# for json_path in json_paths:
path = os.path.join(json_dir, json_path)
with open(path, 'r') as load_f:
json_dict = json.load(load_f)
h, w = json_dict['imageHeight'], json_dict['imageWidth']
# save txt path
txt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))
txt_file = open(txt_path, 'w')
for shape_dict in json_dict['shapes']:
label = shape_dict['label']
label_index = classes.index(label)
points = shape_dict['points']
points_nor_list = []
for point in points:
points_nor_list.append(point[0] / w)
points_nor_list.append(point[1] / h)
points_nor_list = list(map(lambda x: str(x), points_nor_list))
points_nor_str = ' '.join(points_nor_list)
label_str = str(label_index) + ' ' + points_nor_str + '\n'
txt_file.writelines(label_str)
if __name__ == "__main__":
"""
python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_rings/txts --classes "cat,dogs"
"""
parser = argparse.ArgumentParser(description='json convert to txt params')
parser.add_argument('--json-dir', type=str, default=r'E:\ultralytics-main\ultralytics\mydata\json', help='json path dir')
parser.add_argument('--save-dir', type=str, default=r'E:\ultralytics-main\ultralytics\mydata\txt', help='txt save dir')
parser.add_argument('--classes', type=str, default='bud,inflorescence,branch', help='classes')
args = parser.parse_args()
json_dir = args.json_dir
save_dir = args.save_dir
classes = args.classes
convert_label_json(json_dir, save_dir, classes)这个一整套下来就很轻松地将labelme的标签转换成YOLOv5(v5要7.0版本)或者v8需要的分割数据集了,各位加油,如果有帮助就给点个赞吧!!!






![[pyqt5]动态加载ui文件并给菜单的一个子菜单添加触发事件](https://img-blog.csdnimg.cn/ad24761c821144809db7882259ffc067.jpeg)