文章目录
- 一、ForkJoinPool简介
- 二、ForkJoinPool的基本原理
- 1. 分治法
- 2. 工作窃取
- 三、ForkJoinPool的使用场景
- 1. 递归式的任务分解:
- 2. 数据并行处理:
- 3. 合并结果:
- 4. 并行递归算法:
- 5. 小结:
- 四、ForkJoinPool的基本使用
- 1. 计算1到1亿累加和:
- 2. 运行结果:
- 3. 案例分析:
一、ForkJoinPool简介
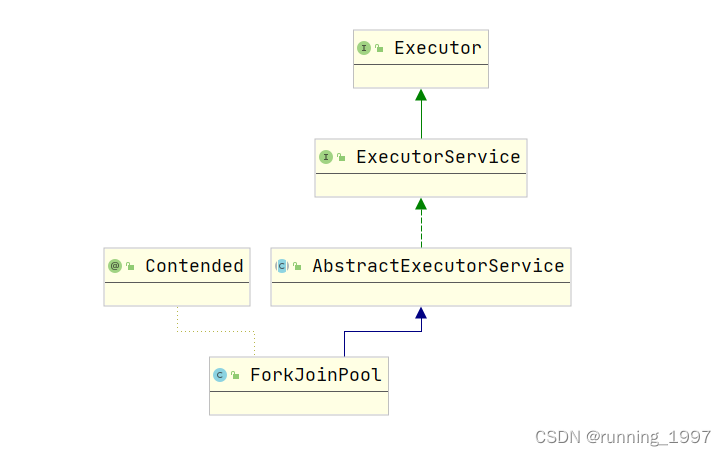
- Fork/Join框架是Java7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
- 使用Fork/Join框架可以简化并发任务的编写和调度,提高并行任务的执行效率。它适用于那些可以被划分成多个独立子任务并且子任务之间没有依赖关系的情况。通过将大任务分割成小任务并使用Fork/Join框架执行,可以充分利用多核处理器的性能,提高程序的并发能力。
二、ForkJoinPool的基本原理
- ForkJoinPool是Java并发编程中的一个线程池实现,它特别适用于任务分解与合并的场景。
- ForkJoinPool的基本原理是基于“工作窃取”(work-stealing)算法。它维护着一个工作队列(WorkQueue)的数组,每个工作队列对应一个工作线程(WorkerThread)。当一个线程需要执行一个任务时,它会将任务添加到自己的工作队列中。当一个线程的工作队列为空时,它会从其他线程的工作队列中“窃取”一个任务来执行。这个“窃取”操作可以在不同的线程间实现任务的负载均衡。
- ForkJoinPool的任务是通过ForkJoinTask来表示的,ForkJoinTask是一个抽象类,它提供了两个子类:RecursiveAction和RecursiveTask。
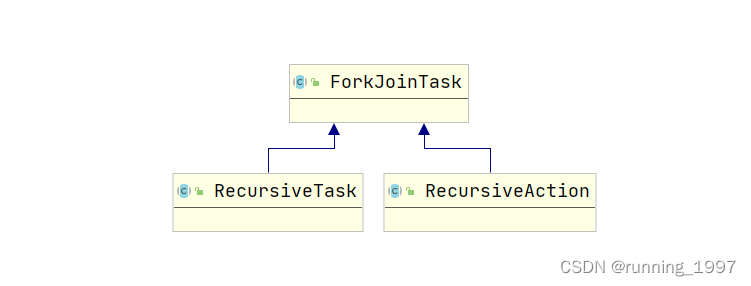
RecursiveAction表示没有返回值的任务,而RecursiveTask表示有返回值的任务。 - 当一个任务被提交到ForkJoinPool时,它会被划分成更小的子任务,然后分配给不同的工作线程执行。如果一个任务的划分后的子任务数超过了一个阈值(通常是系统的处理器数量),那么这个任务就会被分割成更小的子任务,并通过递归的方式继续划分和执行。当一个工作线程执行完自己的任务后,它会从自己的工作队列中获取一个待执行的任务,或者从其他工作线程的工作队列中“窃取”一个任务来执行。这样,ForkJoinPool就实现了任务的自动划分、负载均衡和并行执行。
- 总结起来,ForkJoinPool的原理可以概括为以下几个步骤:
- 将任务划分成更小的子任务;
- 将子任务分配给不同的工作线程执行;
- 工作线程执行自己的任务,并从工作队列中获取待执行的任务;
- 如果工作队列为空,工作线程可以从其他工作线程的工作队列中“窃取”一个任务来执行;
- 重复执行步骤3和步骤4,直到所有的任务都执行完毕。
1. 分治法
-
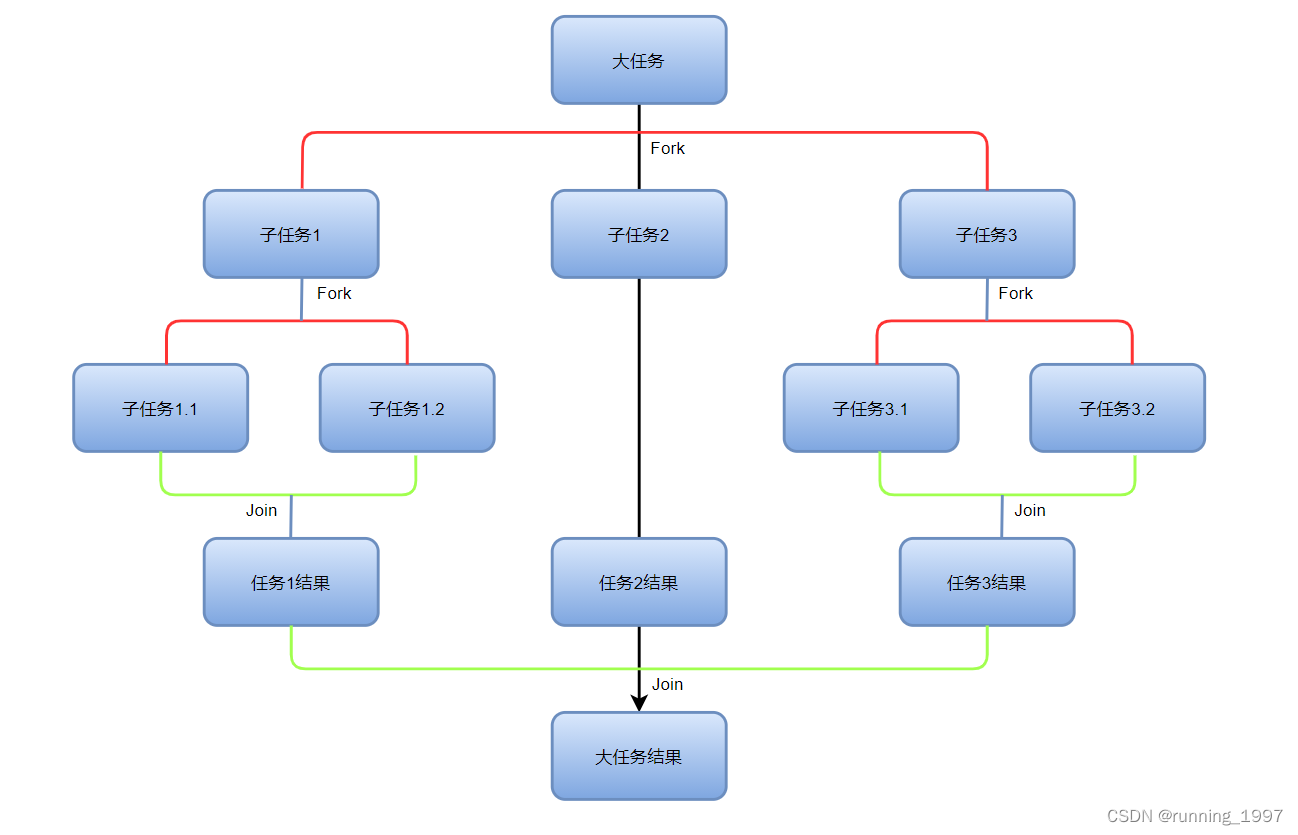
ForkJoinPool是Fork/Join框架中的核心组件,它使用分治法来实现任务的并行执行。分治法是一种将大问题划分成小问题,并通过递归地解决小问题来解决大问题的方法。
-
在Fork/Join框架中,使用ForkJoinPool来管理工作线程和任务的执行。当一个任务被提交给ForkJoinPool时,ForkJoinPool会将任务划分成更小的子任务,每个子任务都是一个ForkJoinTask。如果一个任务的划分后的子任务数超过了一个阈值(通常是系统的处理器数量),那么这个任务就会被继续划分成更小的子任务,直到满足划分条件。
-
ForkJoinPool的分治法可以通过以下步骤来实现:
- 判断任务是否足够小,如果足够小,则直接执行任务并返回结果。
- 如果任务太大,将任务划分成更小的子任务。
- 将子任务提交给ForkJoinPool进行执行。
- 等待子任务执行完成,并获取子任务的结果。
- 合并子任务的结果,得到最终的结果。
-
通过不断地划分和执行子任务,最终可以将大任务分解成多个小任务,并行地执行这些小任务,最后再将小任务的结果合并得到最终结果。这种分治的思想能够提高任务的并行性和执行效率。
-
总结起来,ForkJoinPool使用分治法来实现任务的并行执行。它通过将大任务划分成小任务,并使用递归的方式执行和合并这些小任务,能够充分利用多核处理器的性能,提高程序的并发能力。
2. 工作窃取
ForkJoinPool是Java并发包中用于支持任务并行执行的线程池,它采用了工作窃取机制来提高任务的执行效率。
工作窃取机制是指当某个线程完成了自己的任务后,它可以从其他线程的任务队列中窃取任务来执行。这种机制可以使得线程的负载均衡,提高整体的并发性能。
在ForkJoinPool中,每个线程都有一个自己的任务队列,用于存放待执行的任务。当一个线程没有任务可执行时,它可以从其他线程的任务队列中窃取任务来执行。
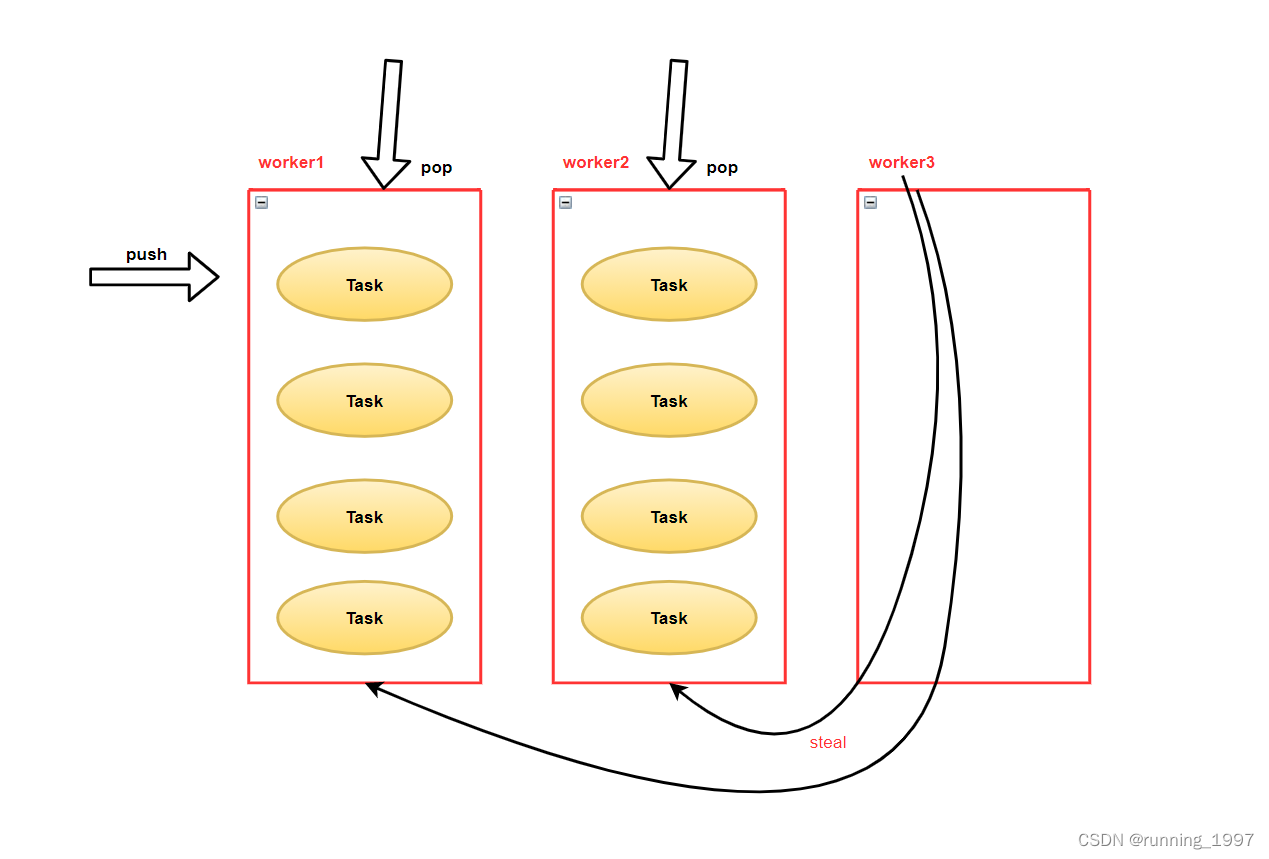
具体的工作窃取过程如下:
1、当一个线程完成了自己的任务后,它会尝试从其他线程的任务队列中窃取任务。为了避免线程之间争夺任务队列的同步问题,ForkJoinPool采用了双端队列,即每个线程都有一个自己的任务队列和一个用于窃取任务的双端队列。
2、窃取任务时,线程会从其他线程的双端队列的尾部窃取任务。这是因为尾部的任务是最新加入的任务,可能是最热门的任务,窃取这些任务可以提高执行效率。
3、当一个线程窃取到了任务后,它会将任务添加到自己的任务队列中,并开始执行该任务。
通过工作窃取机制,ForkJoinPool可以实现任务的自动负载均衡。当某个线程的任务队列较长时,其他线程可以窃取其中的任务来执行,从而使得线程的负载更均衡,提高整体的并发性能。
需要注意的是,工作窃取机制适用于任务之间的计算密集型操作,如果任务之间存在IO等阻塞操作,可能会导致线程的工作窃取效果不明显。此外,工作窃取机制也可能会引发一些问题,如线程间的竞争和任务的执行顺序问题,需要注意处理。
三、ForkJoinPool的使用场景
1. 递归式的任务分解:
当需要处理一个大型任务,并且这个任务可以被递归地分解成更小的子任务时,ForkJoinPool是一个很好的选择。它能够高效地将任务分解成更小的部分,并且可以并行地执行这些子任务。
2. 数据并行处理:
如果需要对一个数据集合进行并行处理,ForkJoinPool可以将数据分割成更小的部分,并且允许多个线程并行地处理这些部分。这对于一些需要对大量数据进行计算或处理的场景非常有用。
3. 合并结果:
当任务的执行结果需要合并到一个最终结果时,ForkJoinPool可以方便地实现这个功能。它能够将子任务的结果合并到父任务中,从而得到最终的结果。
4. 并行递归算法:
某些算法的实现需要使用递归方式进行计算,并且可以通过并行化来提高性能。ForkJoinPool提供了适合这种场景的框架和工具,可以简化并行递归算法的实现。
5. 小结:
需要注意的是,ForkJoinPool适用于处理计算密集型的任务,而不是I/O密集型的任务。因为ForkJoinPool的工作窃取算法需要多个线程共享一个任务队列,如果任务涉及到大量的I/O操作,可能会导致线程长时间等待,从而降低性能。对于I/O密集型的任务,建议使用其他适合的并发框架或技术。
四、ForkJoinPool的基本使用
1. 计算1到1亿累加和:
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class SumCalculator extends RecursiveTask<Long> {
private static final long THRESHOLD = 10000; // 阈值,当任务大小小于等于阈值时,直接计算结果
private long start;
private long end;
public SumCalculator(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
if (end - start <= THRESHOLD) {
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
long mid = (start + end) / 2;
SumCalculator leftTask = new SumCalculator(start, mid);
SumCalculator rightTask = new SumCalculator(mid + 1, end);
leftTask.fork(); // 分解左边任务,异步执行
rightTask.fork(); // 分解右边任务,异步执行
long leftSum = leftTask.join(); // 等待左边任务执行完成并获取结果
long rightSum = rightTask.join(); // 等待右边任务执行完成并获取结果
return leftSum + rightSum; // 合并子任务的结果
}
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
SumCalculator calculator = new SumCalculator(1, 100000000);
long sum = forkJoinPool.invoke(calculator); // 启动任务并获取结果
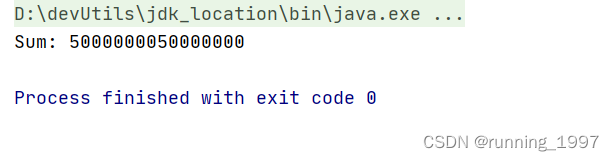
System.out.println("Sum: " + sum);
}
}
2. 运行结果:
3. 案例分析:
-
在上面的代码中,我们定义了一个继承自RecursiveTask的SumCalculator类,用于计算给定范围内的数子累加和。在compute()方法中,我们通过判断任务的大小是否小于等于阈值来决定是直接计算结果还是继续分解任务。如果任务大小小于等于阈值,直接计算结果;否则,将任务分解成两个子任务并异步执行,并通过join()方法等待子任务执行完成并获取结果,最后将子任务的结果合并返回。
-
在main()方法中,我们创建了一个ForkJoinPool实例,并通过invoke()方法启动任务并获取结果,最后打印出累加和的结果。