大家好,Pandas DataFrame是具有标记行和列的二维数据结构。
有时我们需要对两个DataFrame进行逐个元素的比较。例如:
-
使用另一个DataFrame的值来更新其中的值。
-
比较数值,并选择较大或较小的值。
本文将介绍四个不同的Pandas函数,可以用于完成这些任务,并将通过实例来更好地理解它们之间的区别和相似之处。
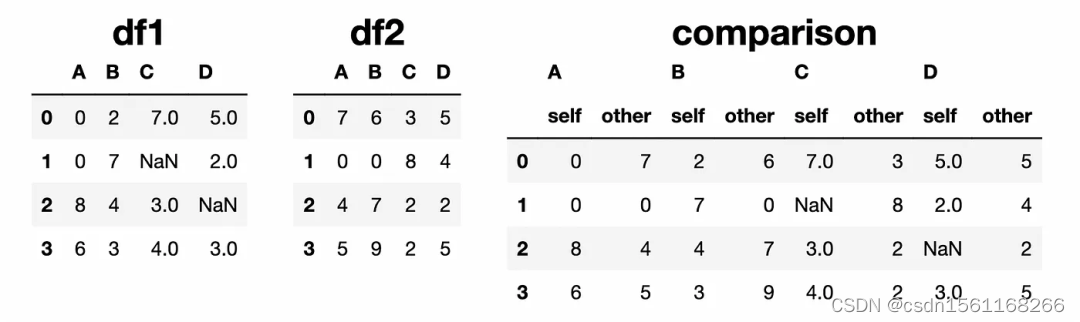
首先,让我们创建两个DataFrame,用于在示例中使用。
import numpy as np
import pandas as pd
# 使用随机整数创建DataFrame
df1 = pd.DataFrame(np.random.randint(0, 10, size=(4, 4)), columns=list("ABCD"))
df2 = pd.DataFrame(np.random.randint(0, 10, size=(4, 4)), columns=list("ABCD"))
# 添加一些缺失值
df1.iloc[2, 3] = np.nan
df1.iloc[1, 2] = np.nan1.combine函数
combine函数基于给定的函数进行逐元素的比较。例如,我们可以选择每个位置的两个值中的最大值。当我们执行示例时,它会更清晰。
combined_df = df1.combine(df2, np.maximum)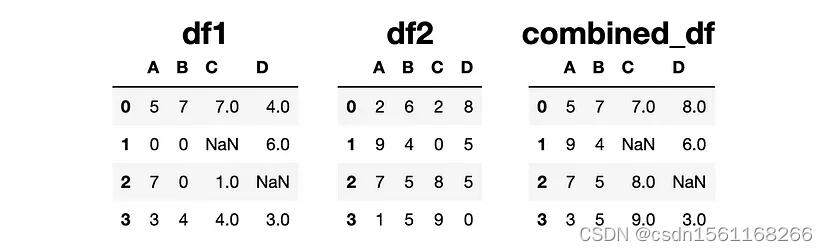
看一下第一行和第一列中的数值。组合的DataFrame具有5和2中较大的一个。
如果其中一个值为NaN(即缺失值),那么组合的DataFrame在此位置也有NaN,因为Pandas无法将值与缺失值进行比较。
我们可以通过使用fill_value参数来选择一个常量值,在缺失值的情况下使用该值,然后将其与另一个DataFrame中的值进行比较。
combined_df = df1.combine(df2, np.maximum, fill_value=0)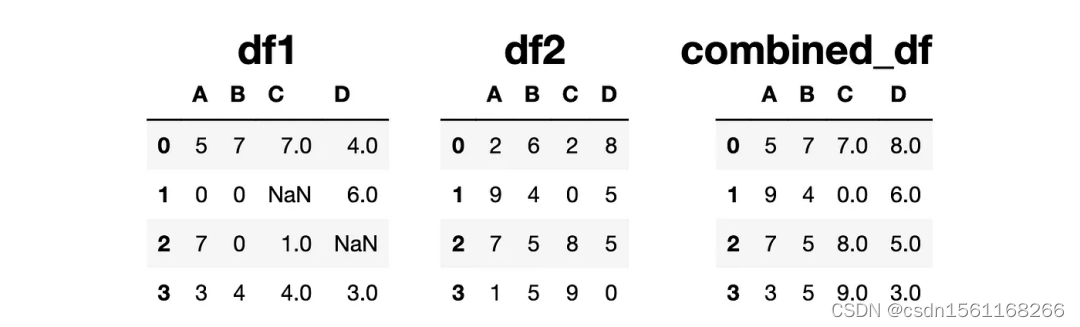
在df1中有两个NaN值,这些值被填充为0,然后与df2中相同位置的值进行比较。
2.combine_first函数
combine_first函数使用另一个DataFrame中相同位置的值更新NaN值。
combined_df = df1.combine_first(df2)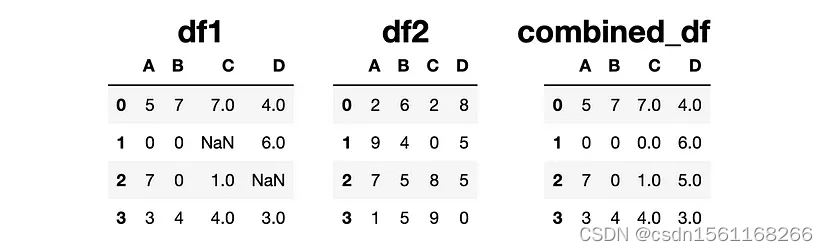
如上图所示,combined_df与df1具有相同的值,除了NaN值,这些值被填充为df2的值。
需要注意的是,combine_first函数不会更新df1和df2中的值。它只返回第一个DataFrame的更新版本。
3.update函数
update函数使用另一个DataFrame中相同位置的值更新DataFrame中的缺失值。
它听起来与combine_first函数所做的作用相同。但是,有一个重要的区别。
update函数不返回任何内容,而是会在原地更新。因此,原始DataFrame被修改(或更新)。使用示例将更清楚地理解。
我们有两个DataFrame,如下图所示:
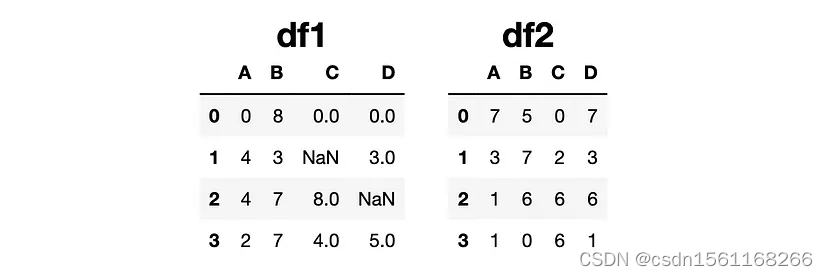
让我们在df1上使用update函数。
df1.update(df2)这行代码不返回任何内容,但会更新df1。更新版本如下:
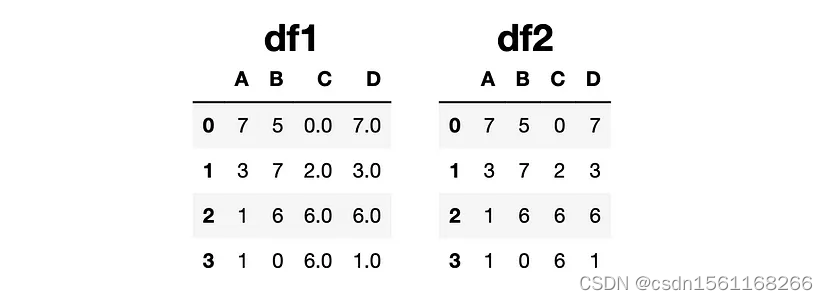
df1不再包含缺失值,这些值已使用df2中的值进行了更新。
4.compare函数
compare函数比较同一位置的值,并返回一个显示它们并排的DataFrame。
comparison = df1.compare(df2)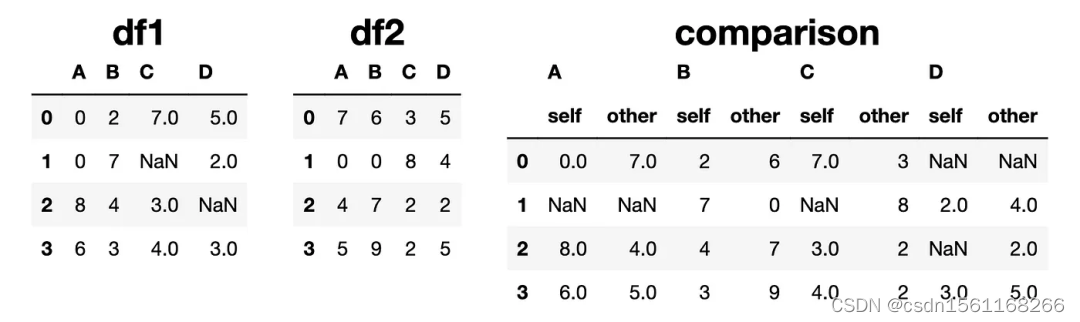
如果特定位置的数值相同,则比较结果显示它们为NaN(例如,第二行第一列)。我们可以通过使用keep_equal参数更改此行为。
comparison = df1.compare(df2, keep_equal=True)