GitHub是一个基于Web的代码托管平台和开发者社区。它允许开发者存储、管理和分享他们的代码,并进行版本控制。开发者可以在GitHub上创建仓库来存储项目代码,并使用Git来跟踪和管理代码的变更历史。GitHub提供了一系列协作工具,如问题追踪、Pull请求(合并请求)、代码审查等,使开发团队能够更好地协同工作、交流和合作开发。此外,GitHub还是一个活跃的开源社区,开发者可以在上面找到各种开源项目、学习新技术、贡献代码或参与讨论。GitHub的用户可以通过浏览其他开发者的项目、关注感兴趣的人、收藏喜欢的仓库等方式来互动和分享。总之,GitHub为开发者提供了一个集代码托管、版本控制和社交互动于一体的平台。
相信所有从事开发的人员来说,github都是一个必不可少的网站,官方地址在这里,如下所示:
当然了有时候因为各种客观存在的网络因素问题,会出现以下访问不到的情况,如下所示:

不过没有关系,多刷新几次等等就好了。
我们自己平时在开发过程中经常也会需要到gihub中去查资料,很多项目甚至是已经不错的模板了可以直击拿来使用了,而且github里面也开源了很多底层基础框架类的项目,对于整体技术的推动和发展还是很友好的了,对于新手入门学习也是非常不错的资源库了。
平时我们查询自己想要的项目大都是手动进行下载的,这里本文的主要目的就是开发构建项目自动下载模块,来实现项目资源数据的自动化下载存储。
这里我们以清华大学开源的chatGLM-6B项目为例,官方项目地址在这里,如下所示:

常用的手动下载的方式有两种:
【第一种】
使用git命令行来进行下载,如下所示:
执行下述命令:
git clone https://github.com/THUDM/ChatGLM-6B静静等待就可以了,不过经常因为网络等问题会导致下载失败,需要多尝试几次。
【第二种】
直接在项目页面端手动点击操作下载即可,如下所示:
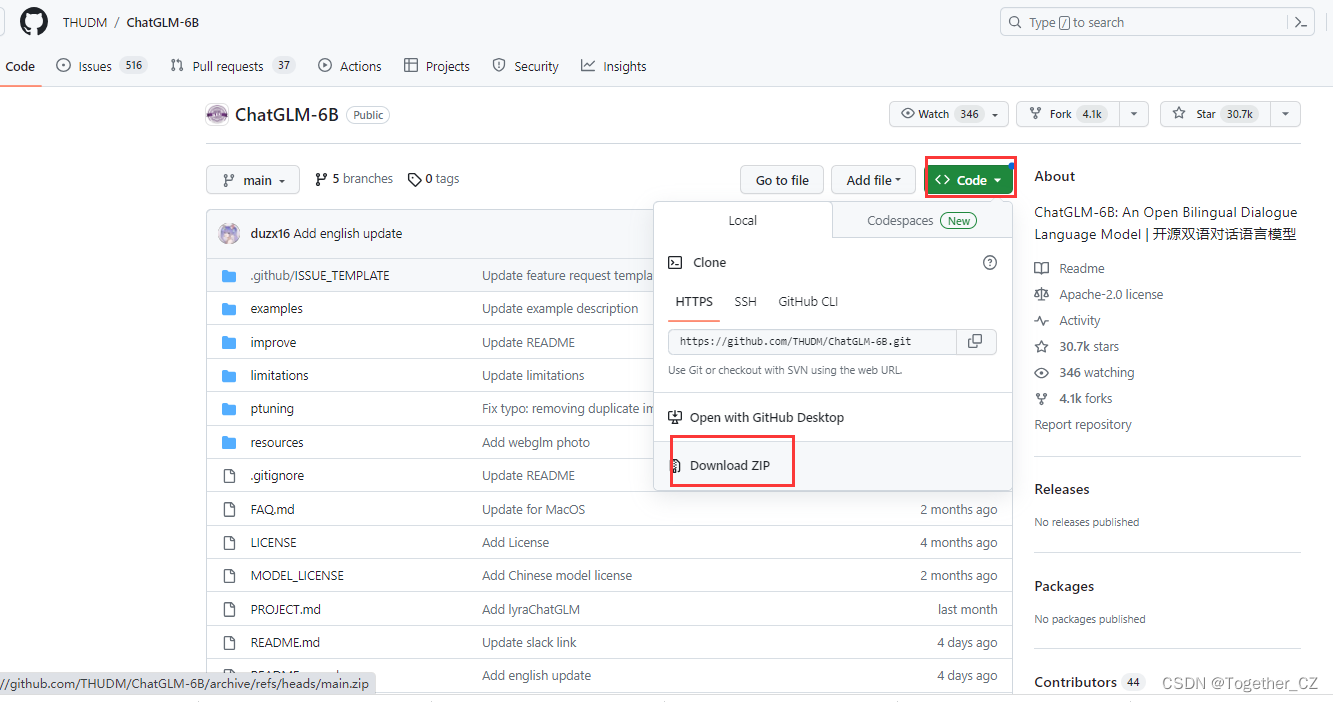
实测,这种方式下载更便捷一点,且成功率更高一点。
这两种方式本质上来讲都是基于手动点击操作实现的项目数据下载。
接下来我们来看下如何实现自动项目数据下载与本地存储。最简单的实现方式就是借助于第三方目标git就可以直接实现了,代码实现如下所示:
#!usr/bin/env python
# encoding:utf-8
from __future__ import division
"""
功能: GitHub项目资源数据自动化下载存储
"""
import os
from git import Repo
def download_github_project(repository_url, local_directory):
# 克隆GitHub项目到本地目录
Repo.clone_from(repository_url, local_directory)
# 项目链接
github_url = "https://github.com/THUDM/ChatGLM-6B"
repository = github_url.split("/")[-1].strip()
# 本地目录
localDir = "projects/"
saveDir = localDir + repository + "/"
if not os.path.exists(saveDir):
os.makedirs(saveDir)
# 下载GitHub项目到本地目录
download_github_project(github_url, saveDir)
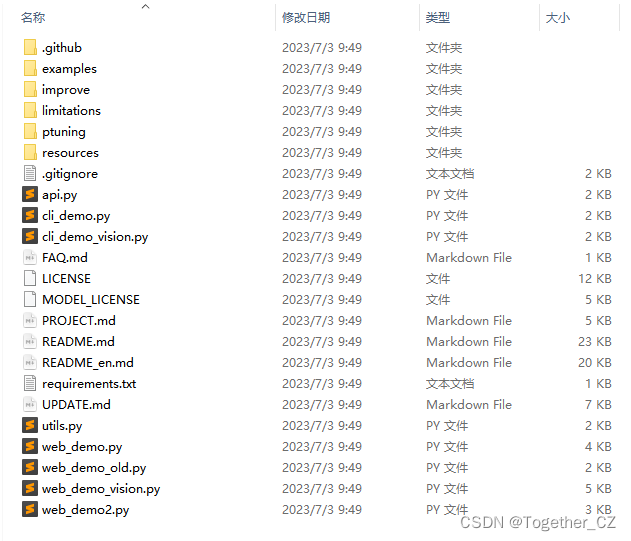
接下来我们看下对应的项目资源数据,如下所示:
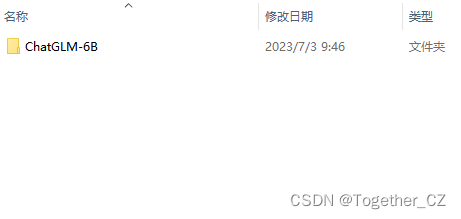

可以看到:这是基于自动化下载代码实现的项目下载截图。
前面都说了这是最简单的实现方式,那么自然还会有其他的实现方式,一般网络数据请求下载相关的我们都会经常使用到requests模块, 这里同样也是可以基于requests模块来实现项目资源数据下载的。
核心代码实现如下所示:
def downloadGithubProject(repository_url, local_directory):
"""
自动化实现GitHub项目资源的下载与本地存储
repository_url:GitHub项目链接
local_directory:本地存储目录
"""
url_parts = repository_url.split("/")
username = url_parts[-2]
repository = url_parts[-1].split(".")[0]
print("repository: ", repository)
# 构建API请求URL来获取zip文件
api_url = f"https://api.github.com/repos/{username}/{repository}/zipball"
# 发送GET请求以获取zip文件内容
response = requests.get(api_url)
# 检查响应状态码是否为200 (成功)
if response.status_code == 200:
# 保存zip文件到本地
zip_path = f"{local_directory}/{repository}.zip"
print("zip_path: ", zip_path)
with open(zip_path, "wb") as file:
file.write(response.content)
# 解压缩zip文件到指定的本地目录
with zipfile.ZipFile(zip_path, "r") as zip_ref:
zip_ref.extractall(local_directory)
# extractZip(zip_path, local_dir+"/"+repository)
# 删除下载的zip文件
os.remove(zip_path)
# 重命名
dir_name = None
dir_list = os.listdir(local_directory)
for one_dir in dir_list:
if repository in one_dir:
dir_name = one_dir
break
renameDirectory(
local_dir + "/" + dir_name, local_dir + "/" + repository_url.split("/")[-1]
)
print("项目下载完成!")
else:
print("无法下载项目。请检查链接或网络连接。")同样看下结果数据,如下所示:

还是很方便地了,后面如果配置web服务接口的形式开发一个后端服务模块的话就可以通过简单的请求数据发送的形式就可以实现自动项目数据的下载处理了。


![[软件工具]左键连发工具左键连点工具使用教程](https://i2.hdslb.com/bfs/archive/76f62ad9a68a4478e71c06c13cf1a6997bc4c0f1.jpg@100w_100h_1c.png@57w_57h_1c.png)







![[解决方案] 在linux运行python代码报错(Illegal instruction (core dumped))](https://img-blog.csdnimg.cn/dd8fa1a217f446308c3e8a334306e9aa.png)