嵌入已经渗透到数据科学家的工具包中,并极大地改变了 NLP、计算机视觉和推荐系统的工作方式。然而,许多数据科学家发现它们过时且令人困惑。更多的人在不了解它们是什么的情况下盲目地使用它们。在本文中,我们将深入探讨嵌入是什么、它们如何工作以及它们在现实系统中通常如何运作。
文章目录
- 什么是Embeddings?
- 一次性编码
- 嵌入解决编码问题
- 嵌入是如何创建的?
- 常见的嵌入模型
- 主成分分析(PCA)
- 奇异值分解
- 词向量
- BERT
- 现实世界中的嵌入
- 推荐系统
- 语义搜索
- 计算机视觉
- 嵌入操作
- 平均
- 减法/加法
- 最近邻
- 结论
什么是Embeddings?
要理解嵌入,我们必须首先了解机器学习模型的基本要求。具体来说,大多数机器学习算法只能将低维数值数据作为输入。
在下面的神经网络中,每个输入特征都必须是数字。这意味着在推荐系统等领域,我们必须将非数字变量(例如项目和用户)转换为数字和向量。我们可以尝试用产品 ID 来表示商品;然而,神经网络将数字输入视为连续变量。这意味着较高的数字“大于”较低的数字。它还将相似的数字视为相似的项目。这对于“年龄”这样的字段来说非常有意义,但当数字代表分类变量时就毫无意义了。在嵌入之前,最常用的方法之一是 one-hot 编码。
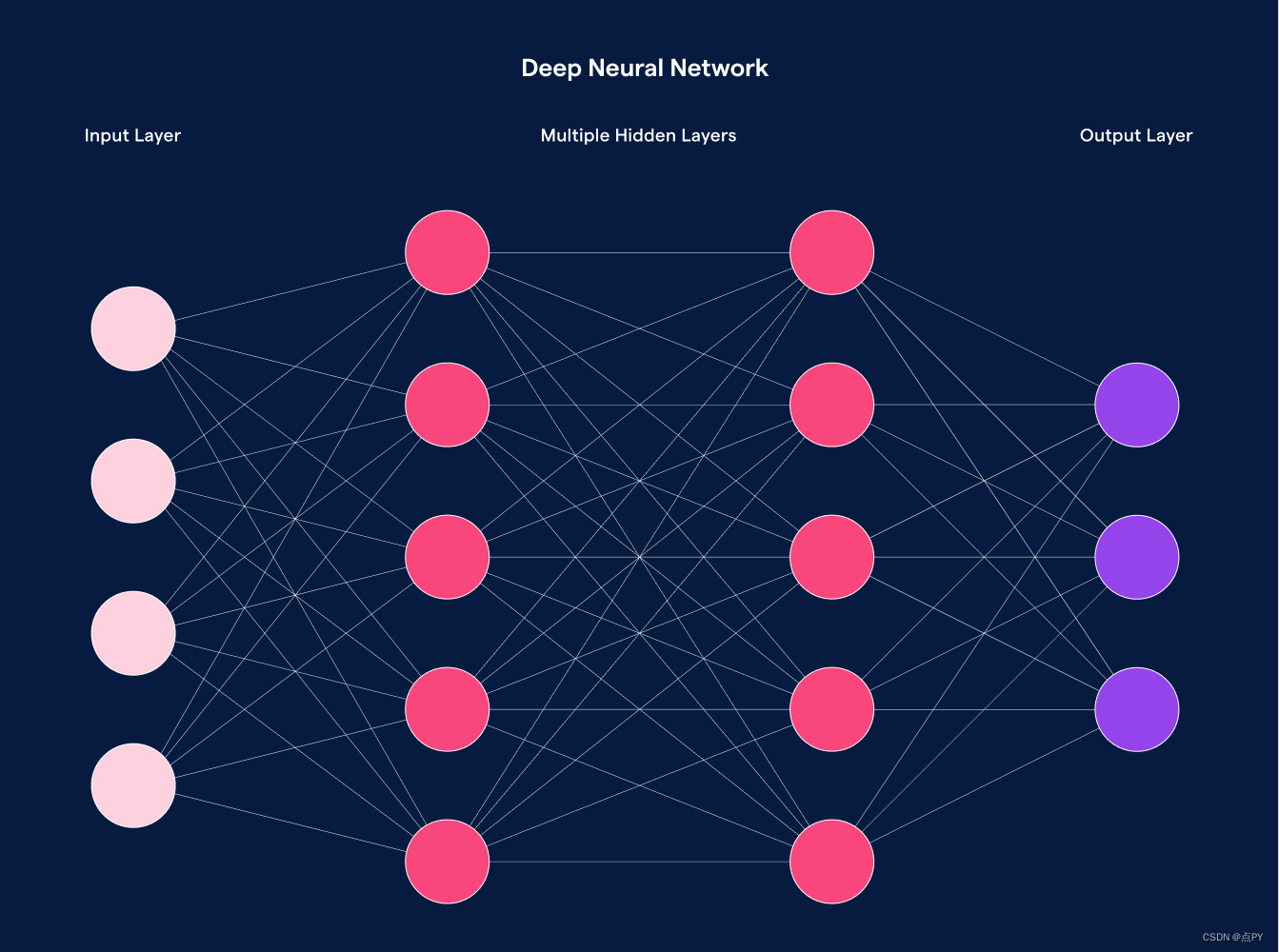
一次性编码
One-hot 编码是表示分类变量的常用方法。这种无监督技术将单个类别映射到向量并生成二进制表示。实际过程很简单。我们创建一个大小等于类别数的向量,并将所有值设置为 0。然后将与给定 ID 或多个 ID 关联的行设置为 1。
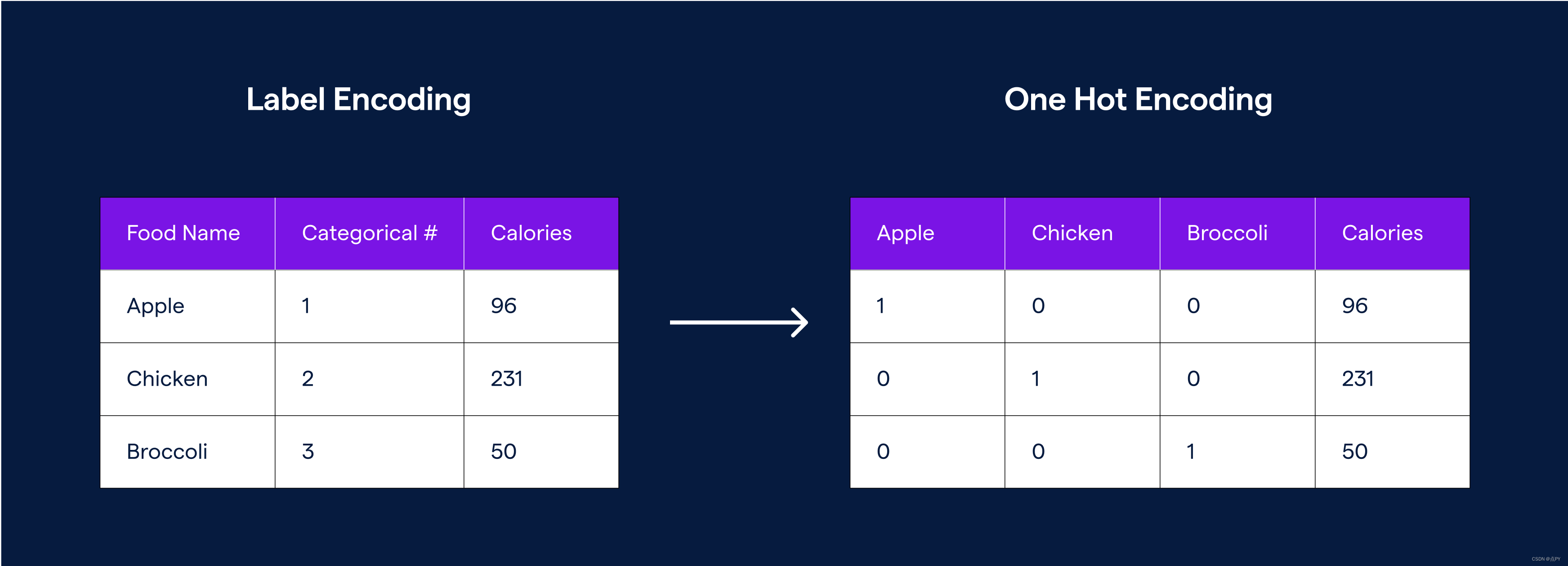
从技术上讲,这可以将一个类别转换为一组连续变量,但实际上我们最终得到的是一个巨大的 0 向量,其中有一个或几个 1。这种简单性也有缺点。对于具有许多独特类别的变量,它会创建难以管理的维数。由于每个项目在向量空间中技术上是等距的,因此它忽略了围绕相似性的上下文。在向量空间中,方差较小的类别并不比方差较大的类别更接近。
这意味着“热狗”和“汉堡”这两个术语并不比“热狗”和“百事可乐”更接近。因此,我们无法评估两个实体之间的关系。我们可以生成更多一对一的映射,或者尝试将它们分组并寻找相似之处。这需要大量的工作和手动标记,这通常是不可行的。
直观上,我们希望能够创建更密集的类别表示并维护项目之间的一些隐式关系信息。我们需要一种方法来减少分类变量的数量,以便我们可以将相似类别的项目更紧密地放置在一起。这正是嵌入的含义。
嵌入解决编码问题
嵌入是现实世界对象和关系的密集数字表示,以向量表示。向量空间量化类别之间的语义相似性。彼此接近的嵌入向量被认为是相似的。有时,它们直接用于电子商务商店中的“与此类似的商品”部分。其他时候,嵌入会传递给其他模型。在这些情况下,模型可以共享相似项目的学习成果,而不是将它们视为两个完全独特的类别,就像 one-hot 编码的情况一样。因此,嵌入可用于准确地将稀疏数据(例如点击流、文本和电子商务购买)表示为下游模型的特征。另一方面,嵌入的计算成本比单热编码高得多,而且可解释性也差得多。
嵌入是如何创建的?
创建嵌入的常见方法要求我们首先设置一个监督机器学习问题。作为副作用,训练该模型会将类别编码为嵌入向量。例如,我们可以建立一个模型,根据用户现在正在观看的内容来预测用户将观看的下一部电影。嵌入模型会将输入分解为向量,该向量将用于预测下一部电影。这意味着相似向量是在相似电影之后经常观看的电影。这为个性化提供了很好的表现。因此,即使我们正在解决一个有监督的问题(通常称为代理问题),嵌入的实际创建是一个无监督的过程。
定义代理问题是一门艺术,并且会极大地影响嵌入的行为。例如,YouTube 的推荐团队意识到,使用“预测用户将要点击的下一个视频”会导致点击诱饵被广泛推荐。他们将“预测下一个视频以及他们将观看多长时间”作为替代问题,并取得了更好的结果。
常见的嵌入模型
主成分分析(PCA)
生成嵌入的一种方法称为主成分分析(PCA)。PCA 通过将变量压缩成更小的子集来降低实体的维度。这使得模型能够更有效地运行,但使变量更难以解释,并且通常会导致信息丢失。PCA 的一种流行实现是一种称为 SVD 的技术。
奇异值分解
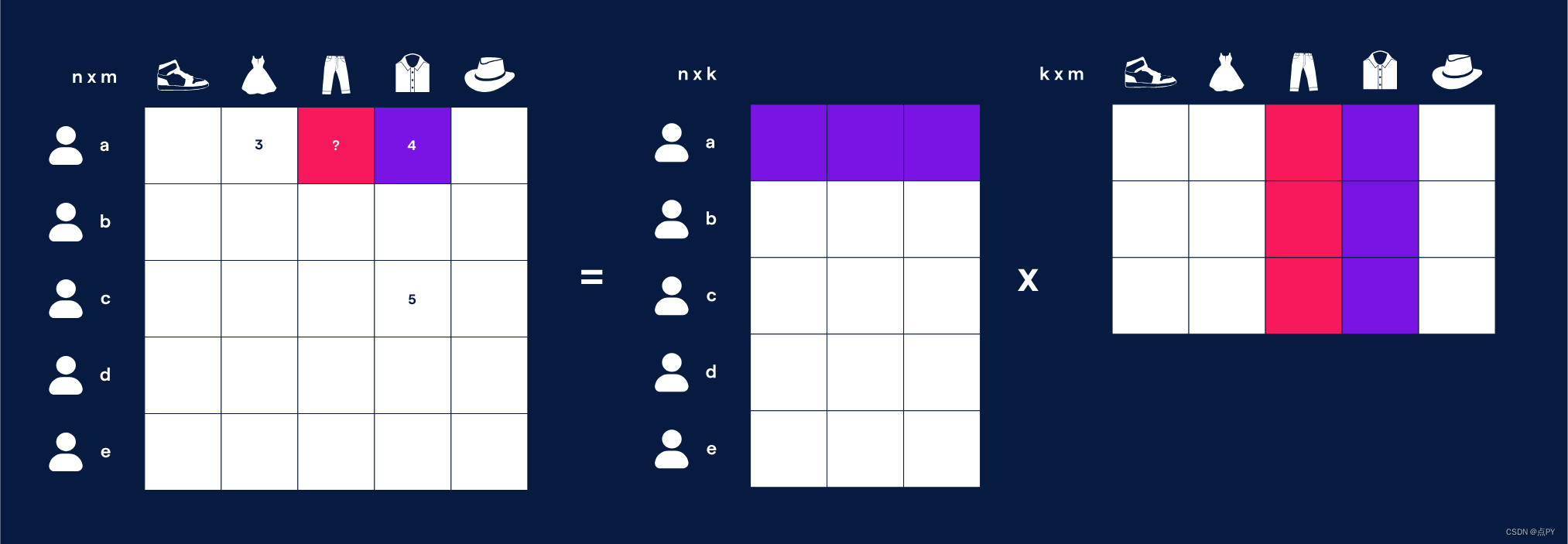
奇异值分解,也称为 SVD,是一种降维技术。SVD 通过矩阵分解将数据集特征的数量从 N 维减少到 K 维。例如,我们将用户的视频评分表示为大小(用户数)x(项目数)的矩阵,其中每个单元格的值是用户对该项目的评分。我们首先选择一个数字 k,它是我们的嵌入向量大小,然后使用 SVD 将其转换为两个矩阵。一个是(用户数量)xk,另一个是 kx(项目数量)。
在得到的矩阵中,如果我们将用户向量乘以项目向量,我们应该得到预测的用户评分。如果我们将两个矩阵相乘,我们最终会得到原始矩阵,但密集地填充了我们所有的预测评分。由此可见,具有相似向量的两个项目将导致同一用户产生相似的评分。通过这种方式,我们最终创建了用户和项目嵌入。
词向量
Word2vec 从单词生成嵌入。单词被编码为 one-hot 向量,并输入到生成隐藏权重的隐藏层。然后使用这些隐藏的权重来预测其他附近的单词。尽管这些隐藏权重用于训练,但 word2vec 不会将它们用于训练的任务。相反,隐藏权重作为嵌入返回,并且模型被丢弃。
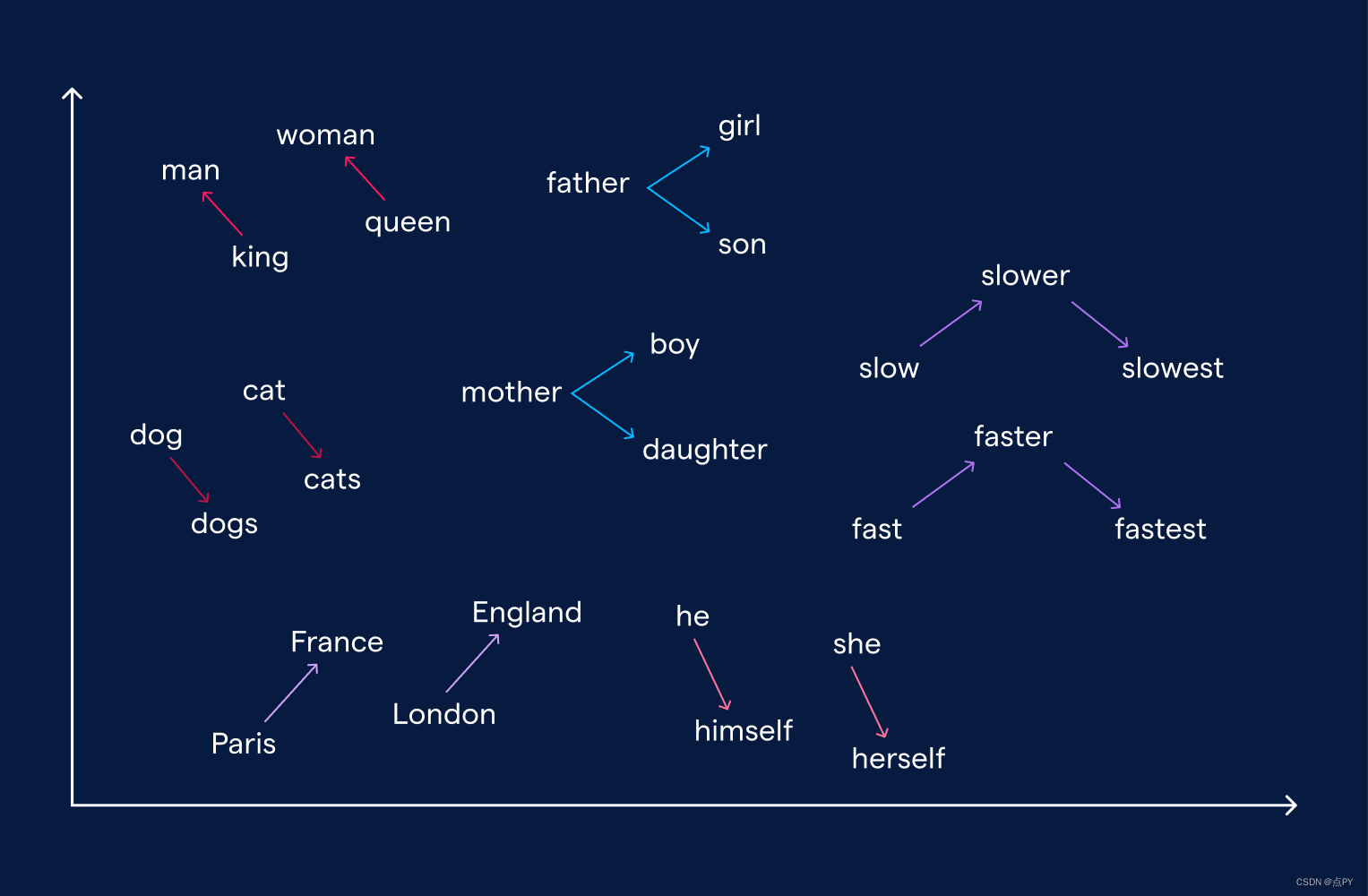
在相似上下文中找到的单词将具有相似的嵌入。除此之外,嵌入还可以用来形成类比。例如,从国王到男人的向量与从女王到女人的向量非常相似。
Word2Vec 的一个问题是单个单词具有一个向量映射。这意味着一个单词的所有语义用途都被组合成一种表示形式。例如,“我要看一场戏”和“我想玩”中的“玩”一词将具有相同的嵌入,但无法区分上下文。

BERT
Bi Direction Encoder Representations of Transformers,也称为 BERT,是一个解决 Word2Vec 上下文问题的预训练模型。BERT 的训练分两步进行。首先,它在维基百科等庞大的数据集上进行训练,以生成与 Word2Vec 类似的嵌入。最终用户执行第二个训练步骤。他们使用非常适合其背景的数据集进行训练,例如医学文献。BERT 将针对特定用例进行微调。此外,为了创建单词嵌入,BERT 会考虑单词的上下文。这意味着“我要看一场戏”和“我想玩”中的“玩”一词将正确地具有不同的嵌入。BERT 已成为生成文本嵌入的首选转换器模型。
现实世界中的嵌入
嵌入的使用始于研究实验室,并很快成为最先进的技术。从那时起,嵌入已经出现在各个不同领域的生产机器学习系统中,包括 NLP、推荐系统和计算机视觉。
推荐系统
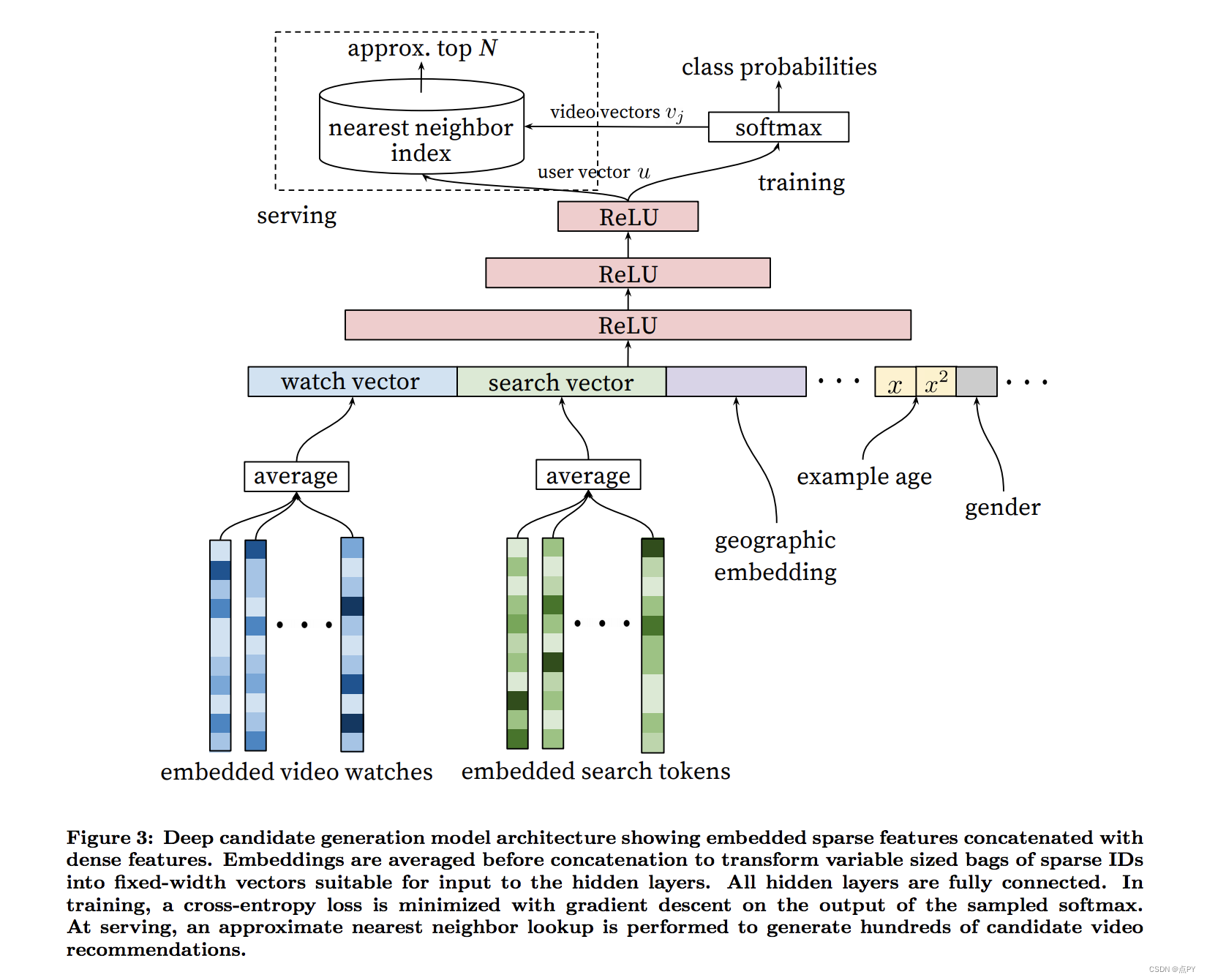
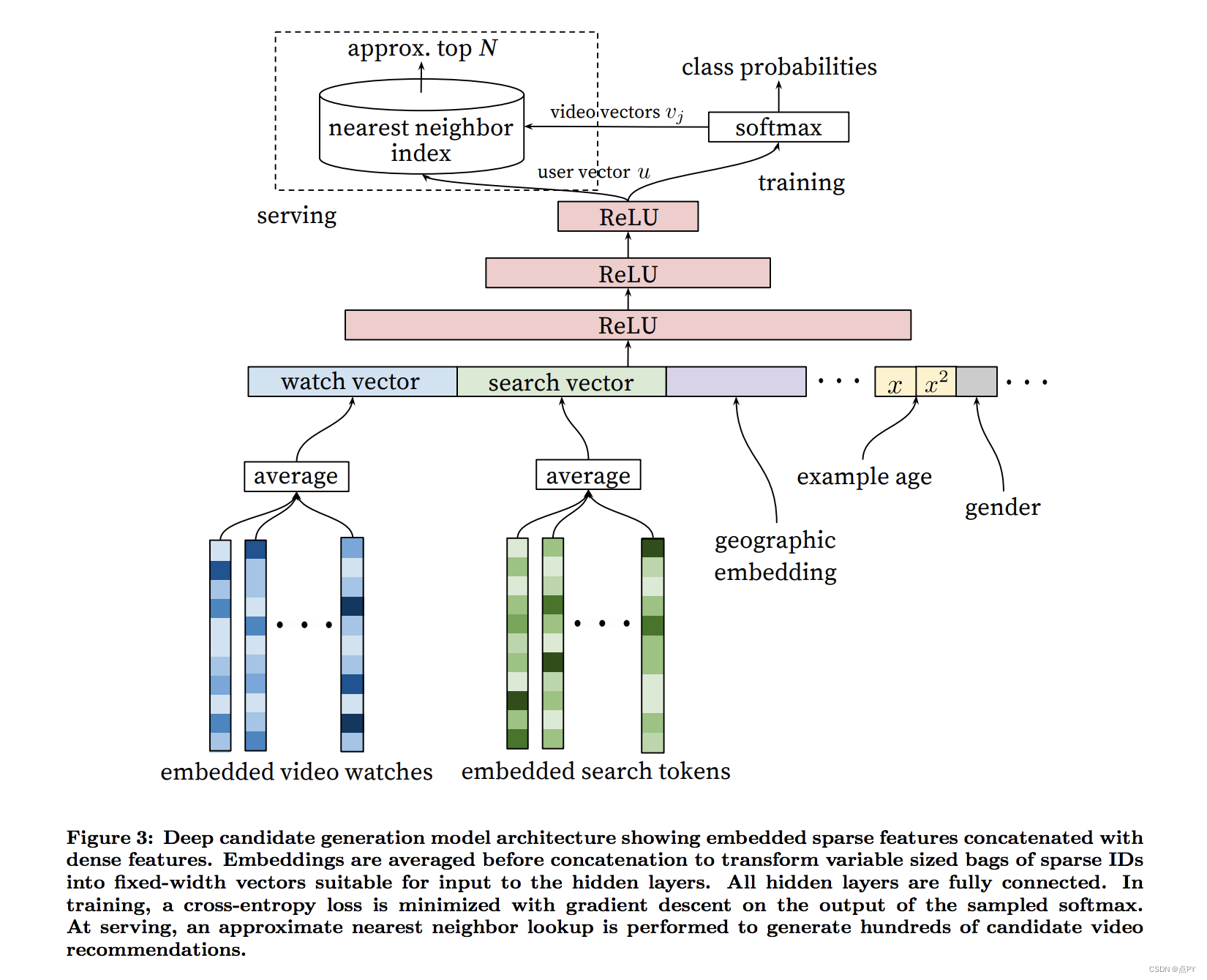
推荐系统预测用户对各种实体/产品的偏好和评级。两种最常见的方法是协作过滤和基于内容。协同过滤使用操作来训练和形成建议。现代协同过滤系统几乎都使用嵌入。例如,我们可以使用上面定义的 SVD 方法来构建推荐系统。在该系统中,将用户嵌入乘以项目嵌入生成评分预测。这提供了用户和产品之间的清晰关系。相似的项目会得到相似用户的相似评分。该属性也可用于下游模型。例如,Youtube 的推荐器使用嵌入作为预测观看时间的神经网络的输入。
语义搜索
用户期望搜索栏比正则表达式更智能。无论是客户支持页面、博客还是 Google,搜索栏都应该理解查询的意图和上下文,而不仅仅是查看单词。搜索引擎过去是围绕 TF-IDF 构建的,它也从文本创建嵌入。这种语义搜索的工作原理是使用最近邻居查找最接近查询嵌入的文档嵌入。
如今,语义搜索利用了更复杂的嵌入(例如 BERT),并可能在下游模型中使用它们。
计算机视觉
在计算机视觉中,嵌入通常被用作在不同上下文之间进行转换的方式。例如,如果训练自动驾驶汽车,我们可以将汽车图像转换为嵌入,然后根据嵌入的上下文决定要做什么。通过这样做,我们可以进行迁移学习。我们可以从《侠盗猎车手》等游戏中获取生成的图像,将其嵌入到同一向量空间中,然后训练驾驶模型,而无需向其提供大量昂贵的真实世界图像。特斯拉今天正在实践这一点。
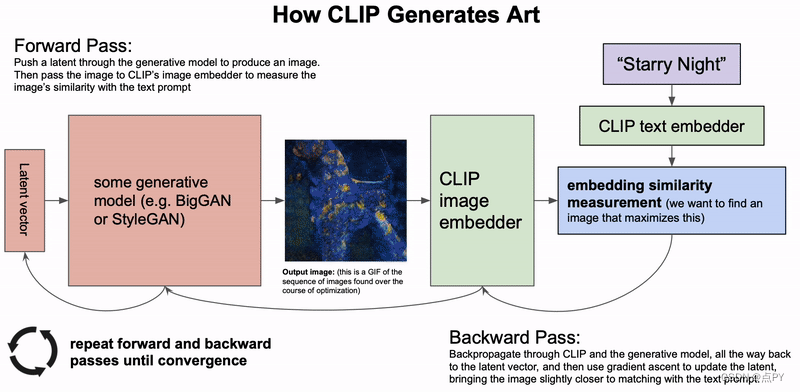
另一个有趣的例子是人工智能艺术机器:https://colab.research.google.com/drive/1n_xrgKDlGQcCF6O-eL3NOd_x4NSqAUjK#scrollTo=TnMw4FrN6JeB。它将根据用户输入的文本生成图像。例如,如果我们输入“Nostalgia”,我们会得到以下图像。

它的工作原理是将用户的文本和图像转换为同一潜在空间中的嵌入。它由四个转换器组成:图像 -> 嵌入、文本 -> 嵌入、嵌入 -> 文本、图像 -> 文本。通过所有这些转换,我们可以使用嵌入作为中间表示将文本转换为图像,反之亦然。
嵌入操作
在上面的示例中,我们看到有一些应用于嵌入的常见操作。任何使用嵌入的生产系统都应该能够实现以下部分或全部功能。
平均
使用像 word2vec 这样的东西,我们最终可以得到每个单词的嵌入,但我们通常需要一个完整句子的嵌入。类似地,在推荐系统中,我们可能知道用户最近点击的项目,但他们的用户嵌入可能在几天内没有被重新训练。在这些情况下,我们可以对嵌入进行平均以创建更高级别的嵌入。在句子示例中,我们可以通过平均每个单词嵌入来创建句子嵌入。在推荐系统中,我们可以通过对用户最后点击的 N 个项目进行平均来创建用户嵌入。
减法/加法
我们之前提到过词嵌入如何通过向量差异对类比进行编码。向量加法和减法可用于多种任务。例如,我们可以找到廉价品牌和奢侈品牌外套之间的平均差异。我们可以存储该增量,并在每当我们想要推荐与用户当前正在查看的商品相似的奢侈品时使用它。我们可以找到可乐和减肥可乐之间的区别,并将其应用于其他饮料,甚至是那些没有减肥可乐的饮料,以找到最接近减肥版本的东西。

最近邻
最近邻(NN)通常是最有用的嵌入操作。它找到与当前嵌入相似的东西。在推荐系统中,我们可以创建用户嵌入并查找与他们最相关的项目。在搜索引擎中,我们可以找到与搜索查询最相似的文档。然而,最近邻是一项计算成本较高的操作。简单地执行它是 O(N*K),其中 N 是项目数,K 是每个嵌入的大小。然而,在大多数情况下,当我们需要最近邻居时,近似就足够了。如果我们向用户推荐五个项目,其中一个在技术上是第六个最接近的项目,那么用户可能不会关心。近似最近邻 (ANN) 算法通常会将查找的复杂性降低至 O(log(n))。
结论
嵌入是数据科学工具包的重要组成部分,并且不断受到欢迎。嵌入使团队能够打破从 NLP 到推荐系统等多个学科的最新技术。随着它们越来越受欢迎,人们将更加关注它们在现实系统中的运作。我们认为嵌入存储将成为机器学习基础设施的关键部分,这就是我们开源的原因。尝试一下,如果这听起来像是一个很棒的全职项目,我们正在招聘!