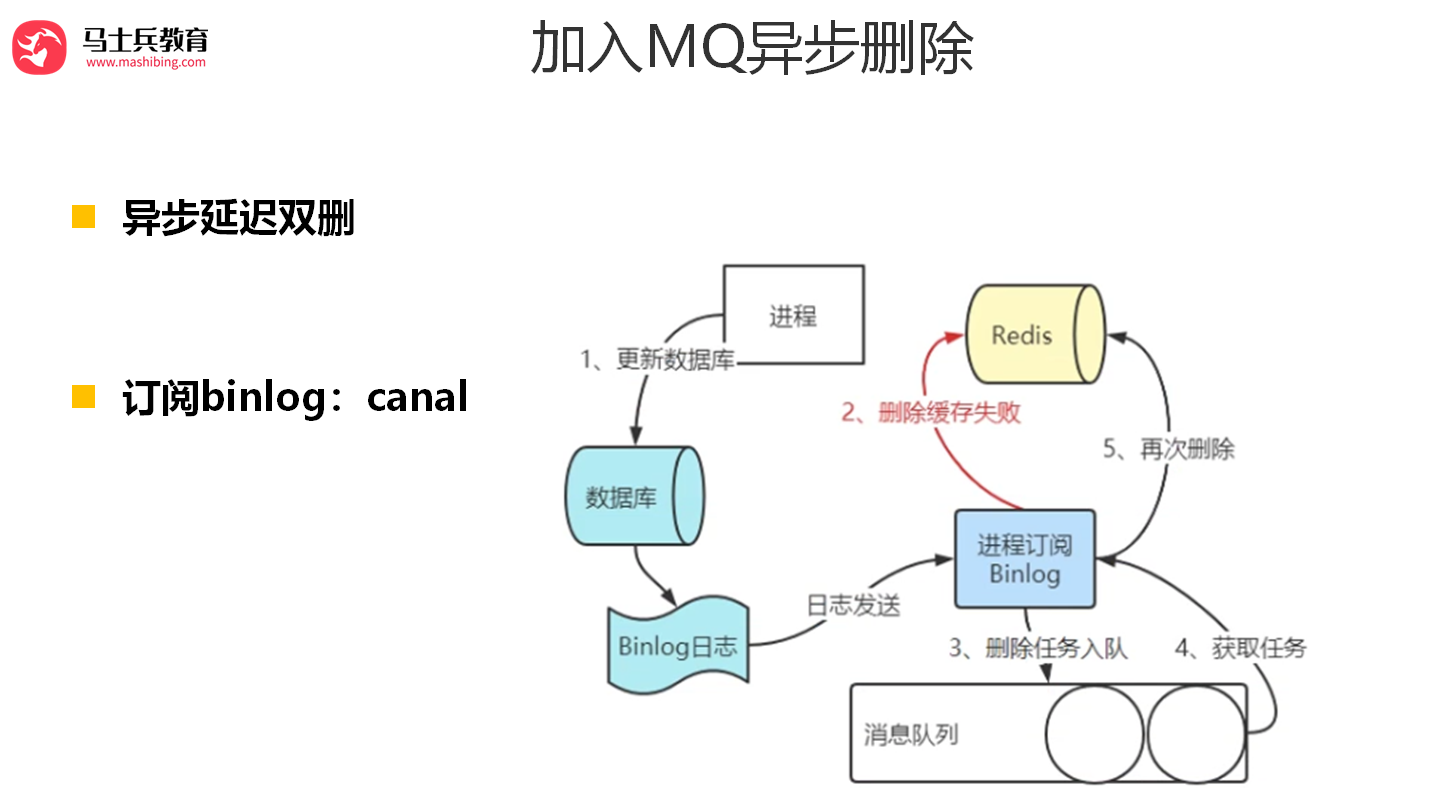
【海量数据挖掘/数据分析】 之 K-NN 分类(K-NN、K-NN实例、准确率评估方法、准确率、召回率)
目录
【海量数据挖掘/数据分析】 之 K-NN 分类(K-NN、K-NN实例、准确率评估方法、准确率、召回率)
一、 K-NN 简介
二、K-NN 分类
三、K-NN 分类实例
1、1-NN 分类 : 此时 A 类别有 1 个 , B 类别有 0 个 , 红色点被分为 A 类别 ;
2、3-NN 分类 : 此时 A 类别有 1 个 , B 类别有 2 个 , 红色点被分为 B 类别 ;
3、9-NN 分类 : 此时 A 类别有 5 个 , B 类别有 2 个 , 红色点被分为 A 类别 ;编辑
4、15-NN 分类 : 此时 A 类别有 5 个 , B 类别有 9 个 , 红色点被分为 B 类别 ;编辑
6、 K-NN 分类 准确度 : 数据量越大 , 准确度越高 ; K-NN 的思想是与周围的大多数样本保持一致 ;
四、K-NN 分类 准确性评估方法
1、保持法 :
2、k-交叉确认法
五、 分类 判定 二维表
六、K-NN 分类结果评价指标
1、准确率
2、 召回率
3、准确率与召回率关联
4、准确率 与 召回率 综合考虑
一、 K-NN 简介
① 全称 : K-NN 全称是 K-Nearest Neighbors , 即 K 最近邻 算法 ;
② 定义 : 给定查询点 p , 找出离 p 最近的 K 个点 , 找出所有的 qk 点 , qk 点的要求是 点到 p 的距离 小于其第 k 个邻居的距离 ;
③ 理解方式 : 以 p 点为圆心画圆 , 数一下圆内 , 和圆的边上的点是由有 K 个 , 如果个数不足 K 个 , 扩大半径 , 直到圆边上和园内的点的个数大于等于 K 为止 ;
④ 图示 : 红色的点是 p 点 , 绿色的点是 p 点的 9 个最近的邻居 , 圆上的绿点是第 9 个最近的邻居 ;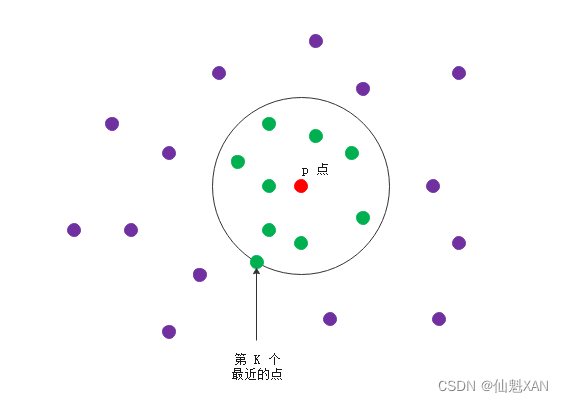
二、K-NN 分类
① 已知条件 : 假设给定查询点 p , 已经直到其 K 个最近邻居 ;
② 分类内容 : K-NN 的目的是为了给查询点 p 进行分类 ;
③ 数据集样本抽象成点 : 将训练集的数据样本 , 当做 n 维空间中的的点 ;
④ 预测分类 : 给定一个未知样本 p , 要给该位置样本分类 , 首先以该未知样本作为查询点 , 以 p 点为中心 , 找到该样本的点在 n 维空间中的 K 个近邻 , 将这 K 个近邻按照某个属性的值进行分组 , 该未知样本 p 被分到样本最多的那个组 ;
三、K-NN 分类实例
为下面的红色点进行分类 : 有两种分类 , 绿色点的分类是 A , 和 紫色点的分类是 B , 为红点进行分类 ;
1、1-NN 分类 : 此时 A 类别有 1 个 , B 类别有 0 个 , 红色点被分为 A 类别 ;
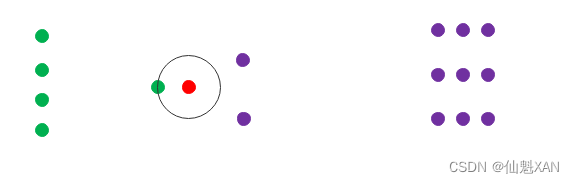
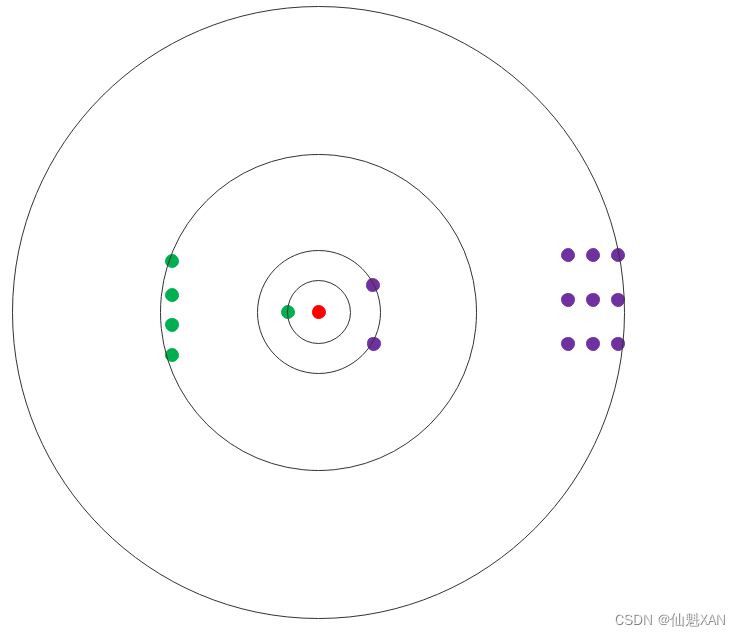
2、3-NN 分类 : 此时 A 类别有 1 个 , B 类别有 2 个 , 红色点被分为 B 类别 ;

3、9-NN 分类 : 此时 A 类别有 5 个 , B 类别有 2 个 , 红色点被分为 A 类别 ;

4、15-NN 分类 : 此时 A 类别有 5 个 , B 类别有 9 个 , 红色点被分为 B 类别 ;

6、 K-NN 分类 准确度 : 数据量越大 , 准确度越高 ; K-NN 的思想是与周围的大多数样本保持一致 ;
四、K-NN 分类 准确性评估方法
K-NN 分类准确性评估方法 :
- 保持法
- k-交叉确认法
这两种方法是常用的 K-NN 评估分类准确率的方法
1、保持法 :
① 训练集测试集划分 : 将数据集样本随机分成两个独立的数据集 , 分别是用于训练学习的训练集 , 和用于验证测试的测试集 ;
② 训练集测试集 样本比例 : 数据集划分比例 , 通常是 , 训练集 2 / 3 , 测试集 1/ 3 ;
③ 随机划分 : 划分一定要保证随机性 , 划分时不能有任何偏好 ;
2 . 随机选样法 : 执行 K 次保持法 , 得到 K 个准确率 , 总体的准确率取这 K 次准确率的平均值 ;
3 . 随机选样法本质 : 保持法的另一种形式 , 相当于使用多次保持法 ;
2、k-交叉确认法
1 . k-交叉确认法 : 首先要划分数据集 , 然后进行 k 次训练测试 , 最后计算出准确率 ;
2 . 划分数据集 : 将数据集样本划分成 k 个独立的子集 , 分别是 {S1,S2,⋯,Sk} , 每个子集的样本个数尽量相同 ;
3 . 训练测试 :
① 训练测试次数 : 训练 k 次 , 测试 k 次 , 每次训练都要对应一次测试 ;
② 训练测试过程 : 第 i 次训练 , 使用 Si 作为测试集 , 其余 (k−1) 个子集作为训练集 ;
4 . 训练测试 示例 : 训练 k 次 ;
第 1 次训练 , 使用 S1 作为测试集 , 其余 (k−1) 个子集作为训练集 ;
第 2 次训练 , 使用 S2 作为测试集 , 其余 (k−1) 个子集作为训练集 ;
⋮
第 k 次训练 , 使用 Sk 作为测试集 , 其余 (k−1) 个子集作为训练集 ;
5 . 准确率结果 :
① 单次训练测试结果 : k 次测试训练 , 每次使用 Si 作为测试集 , 测试的子集中有分类正确的 , 有分类错误的 ;
② 总体准确率 : k 次测试后 , 相当于将整个数据集的子集 {S1,S2,⋯,Sk} 都当做测试集测试了一遍 , 将整体的数据集的样本分类正确的样本个数 Y , 除以整体的样本个数 T , 即可得到 k-交叉确认 准确率结果 Y/ T ;
五、 分类 判定 二维表
1 . 分类 判定二维表 : 这里引入二维表 , 这个二维表表示 人 和 机器 , 对样本的判定情况 ;

2 . 样本分类正确性分析 :
① 样本分类的三种认知 : 样本实际的分类 , 人认为的分类 , 机器认为的分类 ;
② 样本的实际分类 : 样本的实际分类是 A ;
③ 人的判断 : 人认为该样本分类是 A , 说明人判定正确 , 人如果认为该样本分类为 B , 说明人判断错误 ;
④ 机器的判断 : 机器认为该样本分类是A , 说明机器判定正确 ; 机器如果认为该样本分类为 B , 说明机器判断错误 ;
3 . 表内数据含义 : 表格中的 a , b , c , d 值表示样本的个数 ; :
① a 含义 : 表示 人判断正确 , 机器判断正确 的样本个数 ; 数据集中人和机器同时分类正确的样本个数 ;
② b 含义 : 表示 人判断错误 , 机器判断正确 的样本个数 ; 数据集中人分类错误 , 机器分类正确的样本个数 ;
③ c 含义 : 表示 人判断正确 , 机器判断错误 的样本个数 ; 数据集中人分类正确 , 机器分类错误的样本个数 ;
④ d 含义 : 表示 人判断错误 , 机器判断错误 的样本个数 ; 数据集中人和机器同时分类错误的样本个数 ;
六、K-NN 分类结果评价指标
K-NN 分类结果评价指标 :
① 准确率
② 召回率
1、准确率
1 ) 准确率计算公式 :
P = a /(a + b )
(a+b) 是 机器 分类正确 的样本的总数 ;
a 是人和机器都认为正确的样本个数;
2)准确率理解 : 机器分类正确的样本中 , 哪些是真正正确的样本 ; ( a + b ) 是机器认为正确的样本 , 其中只有 a 个样本是真正正确的 ;
2、 召回率
1 )召回率计算公式 :
R = a/( a + c )
(a+c) 是 人认为 分类正确 的样本的总数 ;
a 是人和机器都认为正确的样本个数;
2 ) 召回率理解 : 人认为分类正确的样本中 , 哪些是机器判定正确的 ; (a+c) 是人认为正确的样本个数 , 机器认为正确的是 a 个样本 ;
3、准确率与召回率关联
准确率 与 召回率 关系 : 这两个指标互相矛盾 ;
准确率 与 召回率 是互相影响的 , 准确率很高时 , 召回率很低 ;
准确率 100% 时 , 召回率很低 ; 召回率 100% 时 , 准确率很低 ;
4、准确率 与 召回率 综合考虑
1 ) 准确率 与 召回率 综合考虑 :
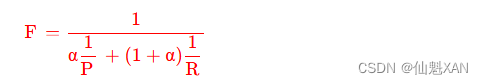
将准确率 与 召回率放在 上述公式中计算 , P 是准确率 , R 是召回率 ;
α 是一个系数 , 通常 α 取值 0.5 ;
2 ) α 取值 0.5 时公式为 : 此时的度量指标叫做 F1 值 , 这个值经常作为 K-NN分类结果的度量指标 , 即考虑了准确率 , 又考虑了召回率 ;

参考文章:
【数据挖掘】K-NN 分类 ( 简介 | 分类概念 | K-NN 分类实例 | K-NN 分类准确度评估 | K-NN 分类结果评价指标 | 准确率 | 召回率 )