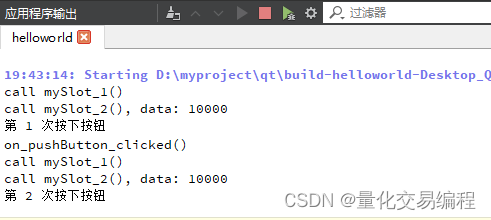
1. bo1公版介绍
Jetson NanoBO1公版的实物图如下图所示。其中1是TF卡接口,可以进行系统镜像烧写;2是40PIN GPIO扩展接口;3是用来传输数据或使用电源供电的Micro USB接口;4是千兆以太网口;5是USB3.0接口;6是HDMI接口;7是用来连接DP屏幕的Display Port接口;8是DC电源接口;9是连接摄像头的接口;10是poe接口。

Jetson Nano开发套件的占地面积仅为80x100mm,具有四个高速USB 3.0端口,MIPI CSI-2摄像头连接器,HDMI 2.0和DisplayPort 1.3,千兆以太网,M.2 Key-E模块,MicroSD卡插槽,和40引脚GPIO接头。端口和GPIO接头开箱即用,具有各种流行的外围设备,传感器和即用型项目,例如 NVIDIA在GitHub上开源的3D可打印深度学习JetBot。
公版可以从移动的MicroSD卡启动,也可以将U盘插入到usb口通过U盘启动系统,可以通过Micro USB端口或5V DC桶形插孔适配器方便地供电。相机连接器兼容经济实惠的MIPI CSI传感器,包括基于JPS生态系统合作伙伴提供的8MP IMX219的模块。还支持Raspberry Pi Camera Module v2,其中包括JetPack中的驱动程序支持,下图是技术规格书

2. 公版深度推理基准
Jetson Nano可以运行各种各样的高级网络,包括流行的ML框架的完整原生版本,如TensorFlow,PyTorch,Caffe / Caffe2,Keras,MXNet等。通过实现图像识别,对象检测和定位,姿势估计,语义分割,视频增强和智能分析等强大功能,这些网络可用于构建自动机器和复杂AI系统
下图显示了在线提供的流行模型的推理基准测试结果。包括其他平台的性能,如Raspberry Pi 3,Intel Neural Compute Stick 2和Google Edge TPU Coral Dev Board:
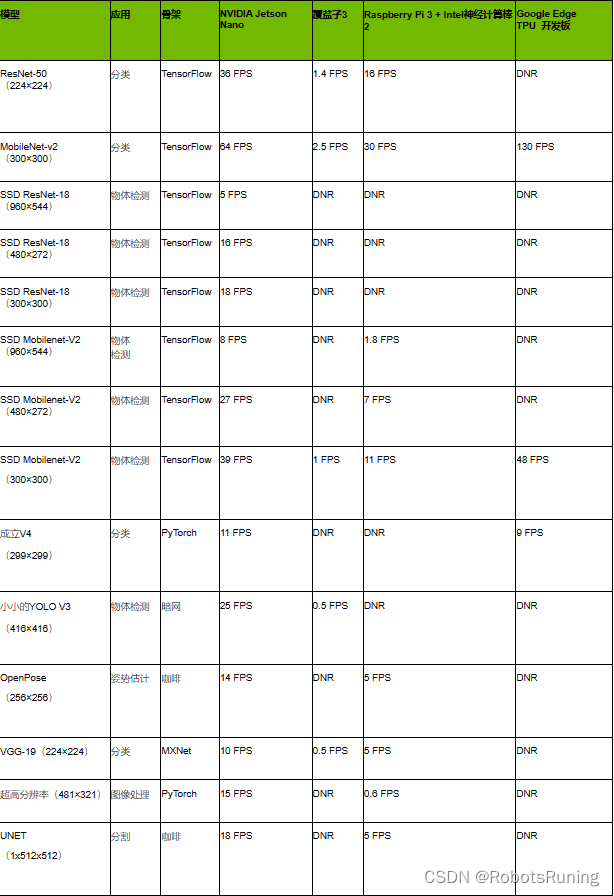
由于内存容量有限,网络层不受支持或硬件/软件限制,DNR(未运行)结果频繁发生。固定功能神经网络加速器通常支持相对较窄的一组用例,硬件支持专用层操作,需要网络权重和激活以适应有限的片上高速缓存,以避免重大的数据传输损失。它们可能会回退到主机CPU上以运行硬件中不支持的层,并且可能依赖于支持减少的框架子集的模型编译器(例如,TFLite)。
Jetson Nano灵活的软件和完整的框架支持,内存容量和统一内存子系统使其能够运行多种不同的网络,达到全高清分辨率,包括同时在多个传感器流上的可变批量大小。这些基准测试代表了流行网络的一些示例,但用户可以通过加速性能为Jetson Nano部署各种模型和定制架构。而Jetson Nano不仅限于DNN推理。其CUDA架构可用于计算机视觉和数字信号处理(DSP),使用包括FFT,BLAS和LAPACK操作在内的算法,以及用户定义的CUDA内核。
3.多流视频分析
Jetson Nano可实时处理多达8个高清全动态视频流,并可部署为网络视频录像机(NVR),智能相机和物联网网关的低功耗边缘智能视频分析平台。NVIDIA的DeepStream SDK 使用ZeroCopy和TensorRT优化端到端推理管道,以在边缘和本地服务器上实现最佳性能。Jetson Nano在8个1080p30流上同时执行物体检测,基于ResNet的模型以全分辨率运行,吞吐量为每秒500万像素(MP / s)。
在Jetson Nano上运行的DeepStream应用程序,基于ResNet的对象检测器同时在八个独立的1080p30视频流上运行。
下面框图显示了使用Jetson Nano通过深度学习分析在千兆以太网上摄取和处理多达八个数字流的示例NVR架构。该系统可解码500 MP / s的H.264 / H.265,并编码250 MP / s的H.264 / H.265视频。

4.AI模型训练
想要尝试培训他们自己的模型的开发人员可以遵循完整的“ 两天演示 ”教程,该教程涵盖了图像分类,对象检测和带有转移学习的语义分割模型的重新训练和定制。传递学习可以精确调整特定数据集的模型权重,并避免必须从头开始训练模型。传输学习最有效地在连接了NVIDIA独立GPU的PC或云实例上执行,因为培训需要比推理更多的计算资源和时间。
然而,由于Jetson Nano可以运行TensorFlow,PyTorch和Caffe等完整的培训框架,因此它还能够为那些可能无法访问另一台专用培训机并且愿意等待更长时间才能获得结果的人进行转学。下图突出了PyTorch使用Jetson Nano在200天图像,22.5GB ImageNet子集上训练Alexnet和ResNet-18的两天到演示教程的转移学习的初步结果:
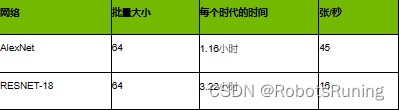
每个时期的时间是完全通过200K图像的训练数据集所需的时间。对于可用结果,分类网络可能需要2-5个时期,并且应该在离散GPU系统上训练生产模型以获得更多时期,直到它们达到最大准确度。但是,Jetson Nano让您可以通过让网络在一夜之间重新培训,在低成本平台上体验深度学习和人工智能。并非所有自定义数据集都可能与此处使用的22.5GB示例一样大。因此,图像/秒表示Jetson Nano的训练性能,每个时期的时间缩放与数据集的大小,训练批量大小和网络复杂性。其他型号也可以在Jetson Nano上重新训练,同时增加训练时间。