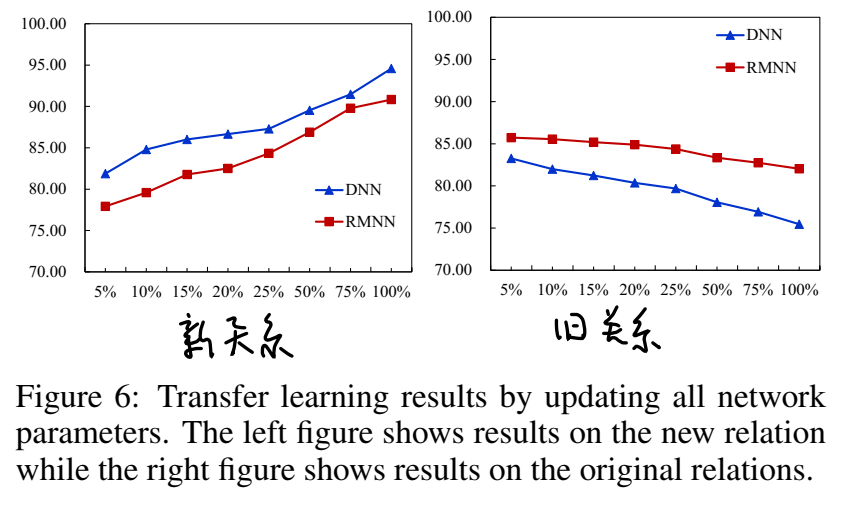
写在前面:
本文为科研理论笔记的第三篇,其余笔记目录传送门:
理论笔记专栏目录
介绍结束下面开始进入正题:
1 高斯分布
一元高斯分布的概率密度函数为:
p
(
x
)
=
1
σ
2
π
exp
(
−
(
x
−
μ
)
2
2
σ
2
)
;
简
写
为
:
x
∼
N
(
μ
,
σ
2
)
p(x) = \frac{1}{\sigma\sqrt{2\pi}}\exp (-\frac{(x-\mu)^2}{2\sigma^2}); 简写为:x \sim N(\mu, \sigma^2)
p(x)=σ2π1exp(−2σ2(x−μ)2);简写为:x∼N(μ,σ2)
其中的
σ
\sigma
σ和
μ
\mu
μ分别表示均值和方差,它们决定了高斯曲线的形状。
二维高斯分布图如下图所示,从XOZ和YOZ两个方向看过去,可以看出两个截面形状均遵循一维高斯分布,也就是说两个均值和两个方差可以唯一的确定一个二维高斯分布。

再推广到多元高斯分布,假设各维度之间相互独立,则一个n维的高斯分布的概率密度函数为:
p
(
x
1
,
x
2
,
.
.
.
,
x
n
)
=
∏
i
=
1
n
p
(
x
i
)
=
1
(
2
π
)
n
2
σ
1
σ
2
.
.
.
σ
n
exp
(
−
1
2
[
(
x
1
−
μ
1
)
2
σ
1
2
+
(
x
2
−
μ
2
)
2
σ
2
2
+
.
.
.
+
(
x
n
−
μ
n
)
2
σ
n
2
]
)
(1)
p(x_1, x_2, ..., x_n) = \prod_{i=1}^{n}p(x_i)=\frac{1}{(2\pi)^{\frac{n}{2}}\sigma_1\sigma_2...\sigma_n}\exp \left(-\frac{1}{2}\left [\frac{(x_1-\mu_1)^2}{\sigma_1^2} + \frac{(x_2-\mu_2)^2}{\sigma_2^2} + ... + \frac{(x_n-\mu_n)^2}{\sigma_n^2}\right]\right) \tag{1}
p(x1,x2,...,xn)=i=1∏np(xi)=(2π)2nσ1σ2...σn1exp(−21[σ12(x1−μ1)2+σ22(x2−μ2)2+...+σn2(xn−μn)2])(1)
其中的
σ
1
,
σ
2
,
.
.
.
\sigma_1,\sigma_2,...
σ1,σ2,...和
μ
1
,
μ
2
,
.
.
.
\mu_1,\mu_2,...
μ1,μ2,...分别为第一维、第二维
.
.
.
...
...高斯分布的均值和方差,为了简化上式,令:
x
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
T
μ
=
[
μ
1
,
μ
2
,
.
.
.
,
μ
n
]
T
x
−
μ
=
[
x
1
−
μ
1
,
x
2
−
μ
2
,
…
x
n
−
μ
n
]
T
\boldsymbol{x} = [x_1,x_2,...,x_n]^T \\ \boldsymbol{\mu} = [\mu_1,\mu_2,...,\mu_n]^T \\ \boldsymbol{x - \mu}=[x_1-\mu_1, \ x_2-\mu_2,\ … \ x_n-\mu_n]^T
x=[x1,x2,...,xn]Tμ=[μ1,μ2,...,μn]Tx−μ=[x1−μ1, x2−μ2, … xn−μn]T
K = [ σ 1 2 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋮ ⋮ ⋱ 0 0 0 0 σ n 2 ] K = \begin{bmatrix} \sigma_1^2 & 0 & \cdots & 0\\ 0 & \sigma_2^2 & \cdots & 0\\ \vdots & \vdots & \ddots & 0\\ 0 & 0 & 0 & \sigma_n^2 \end{bmatrix} K=⎣⎢⎢⎢⎡σ120⋮00σ22⋮0⋯⋯⋱0000σn2⎦⎥⎥⎥⎤
则有:
σ
1
σ
2
.
.
.
σ
n
=
∣
K
∣
1
2
\sigma_1\sigma_2...\sigma_n = |K|^{\frac{1}{2}}
σ1σ2...σn=∣K∣21
( x 1 − μ 1 ) 2 σ 1 2 + ( x 2 − μ 2 ) 2 σ 2 2 + . . . + ( x n − μ n ) 2 σ n 2 = ( x − μ ) T K − 1 ( x − μ ) \frac{(x_1-\mu_1)^2}{\sigma_1^2} + \frac{(x_2-\mu_2)^2}{\sigma_2^2} + ... + \frac{(x_n-\mu_n)^2}{\sigma_n^2}=(\boldsymbol{x-\mu})^TK^{-1}(\boldsymbol{x-\mu}) σ12(x1−μ1)2+σ22(x2−μ2)2+...+σn2(xn−μn)2=(x−μ)TK−1(x−μ)
将上述两式带入式(1)化简得:
p
(
x
)
=
(
2
π
)
−
n
2
∣
K
∣
−
1
2
exp
(
−
1
2
(
x
−
μ
)
T
K
−
1
(
x
−
μ
)
)
p(\boldsymbol{x}) = (2\pi)^{-\frac{n}{2}}|K|^{-\frac{1}{2}}\exp \left( -\frac{1}{2}(\boldsymbol{x-\mu})^TK^{-1}(\boldsymbol{x-\mu}) \right)
p(x)=(2π)−2n∣K∣−21exp(−21(x−μ)TK−1(x−μ))
其中
μ
∈
R
n
\boldsymbol{\mu} \in \mathbb{R}^n
μ∈Rn称为均值向量,
K
∈
R
n
×
n
\boldsymbol{K} \in \mathbb{R}^{n \times n}
K∈Rn×n称为协方差矩阵,其代表了多维高斯分布中各维分布之间的关系,当各维度之间相互独立时,
K
\boldsymbol{K}
K为对角矩阵;当各维度变量相关时,上式的形式仍然一致,但此时
K
\boldsymbol{K}
K不再是对角矩阵,只具备半正定和对称的性质。
上式通常简写为:
x
∼
N
(
μ
,
K
)
\boldsymbol x \sim \mathcal{N}(\boldsymbol{\mu}, K)
x∼N(μ,K)
2 高斯过程
从高斯分布到高斯过程(GP,Gaussian Process),就像手里抓着大把满足高斯分布的随机变量,而这些随机变量是按照时间或者空间这种连续性变量排列的,本质上它是一族随机变量的整体。举个并不太恰当的例子,倘若将我们人生的每一个时刻看做一个随机变量,且都是满足高斯分布,那么你的一生就可以看做一个GP样本,既有很多确定的东西,确定的是均值和核,例如在你高考的那一时刻你的分数均值为600,那么最终结果大概率会在[550,650]这个区间,你的家庭背景和自身天赋(均值函数和核函数)决定了的你人生的大致范围,但又有极大地不确定性,本质上是随机变量的整体,就像你可以凭借自身的努力改变很多东西,即你的人生就是属于你的高斯过程。
高斯过程简单来说,就是一系列关于连续域(时间或空间)的随机变量的联合,而且其中每一个时间或空间点上的随机变量都是服从高斯分布的。
在下图中共有5条不同颜色的曲线,每条曲线都代表了一个GP的样本,首先观察其中橘黄色的曲线,对应x轴上找一个点,比如x=2大概对应的的y轴值约为2.6左右。但这并不是一个确定的点,它所代表的是对应x=2时的一个随机变量 X ( x = 2 ) X_{(x=2)} X(x=2)"正好"出现在2.6罢了,本质上对应x=2的是一个随机变量而不是一个确定的点。也就是说任意时刻的随机变量均服从一个确定的一维高斯分布(并不是说所有时刻对应的随机变量需要服从同一个高斯分布,只是服从的高斯分布的具体参数只跟时刻有关)。除此之外,若是GP的样本,还需要满足任意个点(对应不同时刻的随机变量)联合需要服从多元高斯分布,因此GP的分布就是对于时间域上所有随机变量的联合分布。

再仔细观察上图曲线,这个图中GP样本(不同颜色的曲线)虽然很多,但是它们是不是似乎都在围绕一个中心轴y=0上下震荡?这个规律就是由均值函数(mean function)
μ
(
x
)
\boldsymbol{\mu}(\boldsymbol{x})
μ(x)所决定的,事实上,均值函数决定的样本出现的整体位置,即基准线,若是均值函数恒为0的话那么基准线就是y=0。当然这也是常用的均值函数,其中原因就是它强调于刻画出现样本的整体的位置。另一个原因是GP在机器学习中的应用中,一般数据需要进行预处理,而归零中心常常是必须做的。除了0以外,一些线性的均值函数也是常用的。
既然每一个时刻对应的点都是随机变量,那为何似乎所有的时间差(x值相差)为2的的点对应y轴的值都是几乎一样的呢?这个规律就是由协方差函数(covariance function)
K
(
x
,
x
)
K(\boldsymbol{x},\boldsymbol{x})
K(x,x)所决定的,通常也称为核函数(kernel function),协方差函数在高斯过程中会生成一个协方差矩阵
K
\boldsymbol{K}
K来衡量任意两个点之间的距离,它捕捉了不同输入点之间的关系,并且反映在了之后样本的位置上。这样的话,就可以做到,利用点与点之间关系,以从输入的训练数据预测未知点的值。不同的核函数有不同的衡量方法,得到的高斯过程的性质也不一样,下面是一些常用的核函数:

其中
d
=
x
−
x
′
d=x-x'
d=x−x′,
σ
\sigma
σ和
l
l
l称为高斯核的超参数。
若给定协方差函数为
K
(
x
,
x
′
)
K(x,x')
K(x,x′) ,则其在高斯过程中生成的协方差矩阵为:
K
=
[
K
(
x
1
,
x
1
)
K
(
x
1
,
x
2
)
⋯
K
(
x
1
,
x
n
)
K
(
x
2
,
x
1
)
K
(
x
2
,
x
2
)
⋯
K
(
x
2
,
x
n
)
⋮
⋮
⋱
⋮
K
(
x
n
,
x
1
)
K
(
x
n
,
x
2
)
⋯
K
(
x
n
,
x
n
)
]
\boldsymbol K = \begin{bmatrix} K(x_1,x_1) & K(x_1,x_2) & \cdots & K(x_1,x_n)\\ K(x_2,x_1) & K(x_2,x_2) & \cdots & K(x_2,x_n)\\ \vdots & \vdots & \ddots & \vdots\\ K(x_n,x_1) & K(x_n,x_2) & \cdots & K(x_n,x_n) \end{bmatrix}
K=⎣⎢⎢⎢⎡K(x1,x1)K(x2,x1)⋮K(xn,x1)K(x1,x2)K(x2,x2)⋮K(xn,x2)⋯⋯⋱⋯K(x1,xn)K(x2,xn)⋮K(xn,xn)⎦⎥⎥⎥⎤
下图是一些基于其他核函数的GP样本:


结合之前所说的GP样本需要满足任意个点(对应不同时刻的随机变量)联合服从多元高斯分布,既然满足多元高斯分布,那么就需要一个确定的均值向量
μ
\boldsymbol{\mu}
μ和一个确定的协方差矩阵
K
\boldsymbol{K}
K,而这二者正是由均值函数和协方差函数所确定的,也就是说,若是给定一个均值函数和协方差函数,那么自然不同时刻的随机变量出现的整体位置和相关情况也就被限定住了。即:一个GP可以被协方差函数和核函数共同唯一决定。
下面给出高斯过程正式的数学定义:对于所有
x
=
[
x
1
,
x
2
,
⋯
,
x
n
]
\boldsymbol{x} = [x_1, x_2, \cdots, x_n]
x=[x1,x2,⋯,xn]而言,
f
(
x
)
=
[
f
(
x
1
)
,
f
(
x
2
)
,
⋯
,
f
(
x
n
)
]
f(\boldsymbol{x})=[f(x_1), f(x_2), \cdots, f(x_n)]
f(x)=[f(x1),f(x2),⋯,f(xn)]都服从多元高斯分布,则称
f
f
f是一个高斯过程,表示为:
f
(
x
)
∼
G
P
(
μ
(
x
)
,
K
(
x
,
x
′
)
)
f(\boldsymbol{x}) \sim \mathcal{GP}(\boldsymbol{\mu}(\boldsymbol{x}), K(\boldsymbol{x},\boldsymbol{x'}))
f(x)∼GP(μ(x),K(x,x′))
其中
μ
(
x
)
=
E
(
f
(
x
)
)
:
R
n
→
R
n
\boldsymbol{\mu}(\boldsymbol{x})=\mathbb E(f(\boldsymbol x)): \mathbb{R^{n}} \rightarrow \mathbb{R^{n}}
μ(x)=E(f(x)):Rn→Rn表示均值函数,返回各个维度的均值;
K ( x , x ′ ) = E ( ( f ( x ) − μ ( x ) ) ( f ( x ′ ) − μ ( x ′ ) ) ) : R n × R n → R n × n K(\boldsymbol{x},\boldsymbol{x'})=\mathbb E((f(\boldsymbol x)-\mu(\boldsymbol x))(f(\boldsymbol x')-\mu(\boldsymbol x'))) : \mathbb{R^{n}} \times \mathbb{R^{n}} \rightarrow \mathbb{R^{n\times n}} K(x,x′)=E((f(x)−μ(x))(f(x′)−μ(x′))):Rn×Rn→Rn×n表示协方差函数(核函数),返回各个维度之间的协方差矩阵。
3 高斯过程回归预测
回归(regression):也可以理解为拟合,即把一些看似孤立的数据联系在一起,找到规律,这就叫回归。
机器学习大致可以分为两类:
监督学习(Supervised learning):其本质就是就是从给定的训练数据中学习得到一个映射函数,即当新的数据来到时可是直接代入到之前学习得到的映射函数中,直接获得一个预测结果。学习的训练集要求是输入与输出,当然更直接的说就是特征和目标,而其中的目标是由人为的标注的。监督学习中主要包括回归和分类。所谓回归就是人为标注的目标是连续的,比如说回归天气温度(34度,23度,这些连续的实数),所谓分类就是输出是离散的,比如说分类天气状况(晴,阴,雨)。这些的学习都算是监督学习,也就是这个学习的开始都有个明确的目标。
无监督学习(Unsupervised learning):相比于监督学习,这里的训练集没有人为标注的结果。常见的就有聚类。举个例子,给你一大堆手机,这年头的手机去掉logo,谁都不知道谁是谁,对,给你一堆去掉logo的手机去训练,把最相似的聚在一起(聚类),然后要求就是再给你一个手机,你就可以自动把他归进之前聚好的类别中。这里所谓的聚类是不知道明确要求的归类,而监督学习中的的分类是已知明确标签的,比如智能机和非智能机。
高斯过程回归(GPR,Gaussian Process Regression)就是一种机器学习的方法,其属于上述类型中监督学习里的回归。其主要用于解决的问题可描述如下:假设有一个未知函数
y
=
f
(
x
)
y=f(x)
y=f(x),且在训练集
D
D
D中有三个点
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
(
x
3
,
y
3
)
(x_1,y_1),(x_2,y_2),(x_3,y_3)
(x1,y1),(x2,y2),(x3,y3)如下图所示,那么如果再给一个
x
∗
x^*
x∗,高斯过程回归会给出其对应随机变量
y
∗
y^*
y∗所服从的分布,即作出预测。

高斯过程回归的关键假设为:上述
y
y
y值均服从联合正态分布。即对于上面的训练集例子而言,假设其满足:
[
y
1
y
2
y
3
]
∼
N
(
[
0
0
0
]
,
[
K
11
K
12
K
13
K
21
K
22
K
23
K
31
K
32
K
33
]
)
\begin{bmatrix}y_1 \\y_2 \\y_3 \end{bmatrix} \sim \mathcal{N}\left(\begin{bmatrix}0 \\0 \\0 \end{bmatrix},\begin{bmatrix}K_{11} &K_{12} &K_{13} \\K_{21} &K_{22} &K_{23} \\K_{31} &K_{32} &K_{33} \end{bmatrix} \right)
⎣⎡y1y2y3⎦⎤∼N⎝⎛⎣⎡000⎦⎤,⎣⎡K11K21K31K12K22K32K13K23K33⎦⎤⎠⎞
在这里我们取均值向量
μ
=
0
\boldsymbol{\mu}=0
μ=0,其协方差矩阵
K
=
[
K
11
K
12
K
13
K
21
K
22
K
23
K
31
K
32
K
33
]
\boldsymbol{K}=\begin{bmatrix}K_{11} &K_{12} &K_{13} \\K_{21} &K_{22} &K_{23} \\K_{31} &K_{32} &K_{33} \end{bmatrix}
K=⎣⎡K11K21K31K12K22K32K13K23K33⎦⎤由核函数给出。
以此类推进一步考虑
y
∗
y^*
y∗,他与
y
1
,
y
2
,
y
3
y_1,y_2,y_3
y1,y2,y3也应符合一个4维高斯分布,即:
[
y
1
y
2
y
3
y
∗
]
∼
N
(
[
0
0
0
0
]
,
[
K
11
K
12
K
13
K
1
∗
K
21
K
22
K
23
K
2
∗
K
31
K
32
K
33
K
3
∗
K
∗
1
K
∗
2
K
∗
3
K
∗
∗
]
)
\begin{bmatrix}y_1 \\y_2 \\y_3 \\y^* \end{bmatrix} \sim \mathcal{N}\left(\begin{bmatrix}0 \\0 \\0 \\0 \end{bmatrix},\begin{bmatrix}K_{11} &K_{12} &K_{13} &K_{1*} \\K_{21} &K_{22} &K_{23} &K_{2*} \\K_{31} &K_{32} &K_{33} &K_{3*} \\K_{*1} &K_{*2} &K_{*3} &K_{**}\end{bmatrix} \right)
⎣⎢⎢⎡y1y2y3y∗⎦⎥⎥⎤∼N⎝⎜⎜⎛⎣⎢⎢⎡0000⎦⎥⎥⎤,⎣⎢⎢⎡K11K21K31K∗1K12K22K32K∗2K13K23K33K∗3K1∗K2∗K3∗K∗∗⎦⎥⎥⎤⎠⎟⎟⎞
若给定了
x
∗
x^*
x∗,那么
K
1
∗
,
K
2
∗
,
K
3
∗
,
K
∗
1
,
K
∗
2
,
K
∗
3
K_{1*},K_{2*},K_{3*},K_{*1},K_{*2},K_{*3}
K1∗,K2∗,K3∗,K∗1,K∗2,K∗3都可以通过核函数求出,而
K
∗
∗
K_{**}
K∗∗一般取1即可。
设
y
⃗
=
[
y
1
y
2
y
3
]
\vec y=\begin{bmatrix}y_1 \\y_2 \\y_3 \end{bmatrix}
y=⎣⎡y1y2y3⎦⎤,
K
∗
=
[
K
1
∗
K
2
∗
K
3
∗
]
\boldsymbol{K}_*=\begin{bmatrix}K_{1*} \\K_{2*} \\K_{3*} \end{bmatrix}
K∗=⎣⎡K1∗K2∗K3∗⎦⎤,即
K
\boldsymbol{K}
K的右侧部分,那么套入公式即可得到
y
∗
y^*
y∗所服从的分布:
y
∗
∼
N
(
μ
∗
,
σ
∗
)
(2)
y^* \sim \mathcal{N}(\mu^*, \sigma^*) \tag{2}
y∗∼N(μ∗,σ∗)(2)
其中:
μ
∗
=
K
∗
T
K
−
1
y
⃗
\mu^* = \boldsymbol K_*^T\boldsymbol K^{-1}\vec y
μ∗=K∗TK−1y ,
σ
∗
=
−
K
∗
T
K
−
1
K
∗
+
K
∗
∗
\sigma^* = -\boldsymbol K_*^T\boldsymbol K^{-1}\boldsymbol K_*+K_{**}
σ∗=−K∗TK−1K∗+K∗∗,该公式的推导涉及到贝叶斯公式和似然估计,有兴趣可自行百度。
若再加上一个高斯噪声,即: y = f ( x ) + ϵ y=f(x)+\epsilon y=f(x)+ϵ,这个方程刻画了理想的输入量和输出量之间的关系,其中 ϵ ∼ N ( 0 , σ n 2 ) \epsilon \sim N(0,\sigma_n^2) ϵ∼N(0,σn2),其分析过程同上,只不过需要再在上述协方差矩阵 K \boldsymbol K K的基础上加上一个 σ n 2 I \sigma_n^2I σn2I,即: K ′ = K + σ n 2 I \boldsymbol K'=\boldsymbol K+\sigma_n^2I K′=K+σn2I.
最后一步要考虑的就是当我们有了均值函数和核函数的具体形式后,该如何通过训练集 D D D去估计并优化核函数中的超参数,相应的算法不止一种,下面不加证明的(有兴趣自行百度)给出一个利用最大似然估计求解超参数的算法公式:
设训练集
D
=
(
X
,
y
)
=
{
(
x
i
,
y
i
)
∣
x
i
∈
R
n
,
y
i
∈
R
,
i
=
0
,
1
,
.
.
.
,
n
}
D=(X,y)=\{(x_i,y_i)|x_i\in \R^n,y_i\in \R,i=0,1,...,n \}
D=(X,y)={(xi,yi)∣xi∈Rn,yi∈R,i=0,1,...,n},
f
(
x
)
∼
G
P
(
0
,
K
θ
)
f(\boldsymbol{x}) \sim \mathcal{GP}(0, K_\theta)
f(x)∼GP(0,Kθ),其中
θ
\theta
θ表示超参数,
K
θ
K_\theta
Kθ表示带超参数的核函数,那么关于
θ
\theta
θ最大似然函数为:
L
(
θ
)
=
l
o
g
(
y
∣
x
,
θ
)
=
−
1
2
y
T
K
θ
−
1
y
−
1
2
l
o
g
∣
K
θ
∣
−
n
2
l
o
g
2
π
L(\theta)=log(y|x,\theta)=-\frac{1}{2}y^TK_\theta^{-1}y-\frac{1}{2}log|K_\theta|-\frac{n}{2}log2\pi
L(θ)=log(y∣x,θ)=−21yTKθ−1y−21log∣Kθ∣−2nlog2π
再令:
∂
L
∂
θ
=
1
2
t
r
(
K
θ
−
1
∂
K
θ
∂
θ
)
−
1
2
y
T
K
θ
−
1
∂
K
θ
∂
θ
K
θ
−
1
y
=
0
(3)
\frac{\partial L}{\partial\theta}=\frac{1}{2}tr(K_\theta^{-1}\frac{\partial K_\theta}{\partial\theta}) -\frac{1}{2}y^{T}K_\theta^{-1}\frac{\partial K_\theta}{\partial\theta}K_\theta^{-1}y=0 \tag{3}
∂θ∂L=21tr(Kθ−1∂θ∂Kθ)−21yTKθ−1∂θ∂KθKθ−1y=0(3)
即可解出
θ
\theta
θ的最大似然估计值
θ
^
\hat\theta
θ^,其中
t
r
tr
tr是指矩阵的迹。
下面举个简单的例子进行总结,请听题:
现有训练集: D = ( X , y ) = { ( − 1.5 , − 1.65 ) , ( − 1 , − 1.08 ) , ( − 0.75 , − 0.27 ) , ( − 0.4 , 0.27 ) , ( − 0.25 , 0.59 ) , ( 0 , 0.92 ) } D=(X,y)=\{(-1.5,-1.65),(-1,-1.08),(-0.75,-0.27),(-0.4,0.27),(-0.25,0.59),(0,0.92)\} D=(X,y)={(−1.5,−1.65),(−1,−1.08),(−0.75,−0.27),(−0.4,0.27),(−0.25,0.59),(0,0.92)},自选均值函数和核函数,预测当 x ∗ = 0.2 x^*=0.2 x∗=0.2时, y ∗ = ? y^*=? y∗=?
step1:确定训练集中的点为一个高斯过程的采样点,即: y ( x ) ∼ G P ( μ ( x ) , K ( x , x ′ ) ) y(\boldsymbol{x}) \sim \mathcal{GP}(\boldsymbol{\mu}(\boldsymbol{x}), K(\boldsymbol{x},\boldsymbol{x'})) y(x)∼GP(μ(x),K(x,x′));
step2:确定均值函数,不妨取 μ ( x ) = 0 \boldsymbol{\mu}(\boldsymbol{x})=0 μ(x)=0;
step3:确定核函数,选取 K ( x , x ′ ) = σ f 2 e x p [ − d 2 2 l 2 ] + σ n 2 δ ( x , x ′ ) K(\boldsymbol{x},\boldsymbol{x'})=\sigma_f^2exp[\frac{-d^2}{2l^2}]+\sigma_n^2\delta(x,x') K(x,x′)=σf2exp[2l2−d2]+σn2δ(x,x′),
其中取 σ n = 0.3 \sigma_n=0.3 σn=0.3, δ ( x , x ′ ) = { 1 , x = x ′ 0 , x ≠ x ′ \delta(x,x')=\begin{cases}1,&{x=x'} \\0,&{x\neq x'} \end{cases} δ(x,x′)={1,0,x=x′x=x′, σ f \sigma_f σf和 l l l为超参数;
step4:根据后验概率确定预测点的表达式,即上式(2);
step5:利用最大似然估计求解超参数,即套用上式(3),解出 l ^ = 1 , σ ^ f = 1.27 \hat l=1,\hat \sigma_f=1.27 l^=1,σ^f=1.27,注意在编程时一般这一步可以调用内置函数实现;
step6:代入数据,求得协方差矩阵 K = [ 1.70 1.42 1.21 0.87 0.72 0.51 1.42 1.70 1.56 1.34 1.21 0.97 1.21 1.56 1.70 1.51 1.42 1.21 0.87 1.34 1.51 1.70 1.59 1.48 0.72 1.21 1.42 1.59 1.70 1.56 0.51 0.97 1.21 1.48 1.56 1.70 ] \boldsymbol{K}=\begin{bmatrix}1.70&1.42&1.21&0.87&0.72&0.51 \\1.42&1.70&1.56&1.34&1.21&0.97 \\1.21&1.56&1.70&1.51&1.42&1.21 \\0.87&1.34&1.51&1.70&1.59&1.48 \\0.72&1.21&1.42&1.59&1.70&1.56 \\0.51&0.97&1.21&1.48&1.56&1.70 \end{bmatrix} K=⎣⎢⎢⎢⎢⎢⎢⎡1.701.421.210.870.720.511.421.701.561.341.210.971.211.561.701.511.421.210.871.341.511.701.591.480.721.211.421.591.701.560.510.971.211.481.561.70⎦⎥⎥⎥⎥⎥⎥⎤
K ∗ = [ 0.38 0.79 1.03 1.35 1.46 1.58 ] \boldsymbol K_*=\begin{bmatrix}0.38&0.79&1.03&1.35&1.46&1.58 \end{bmatrix} K∗=[0.380.791.031.351.461.58],取 K ∗ ∗ = 1.70 K_{**}=1.70 K∗∗=1.70,
最后带入式(2)即可解出: μ ∗ = 0.95 \mu^*=0.95 μ∗=0.95, σ ∗ = 0.21 \sigma^*=0.21 σ∗=0.21,即 y ∗ ∼ N ( 0.95 , 0.21 ) y^* \sim \mathcal{N}(0.95,0.21) y∗∼N(0.95,0.21),解毕。
最后总结如下图:










![[选型] 实时数仓之技术选型](https://img-blog.csdnimg.cn/img_convert/41ccfc03b487d599a67a2b148245156b.png)