✍个人博客:https://blog.csdn.net/Newin2020?spm=1011.2415.3001.5343
📣专栏定位:为学习吴恩达机器学习视频的同学提供的随堂笔记。
📚专栏简介:在这个专栏,我将整理吴恩达机器学习视频的所有内容的笔记,方便大家参考学习。
💡专栏地址:https://blog.csdn.net/Newin2020/article/details/128125806
📝视频地址:吴恩达机器学习系列课程
❤️如果有收获的话,欢迎点赞👍收藏📁,您的支持就是我创作的最大动力💪
十五、大规模机器学习
1. 学习大数据
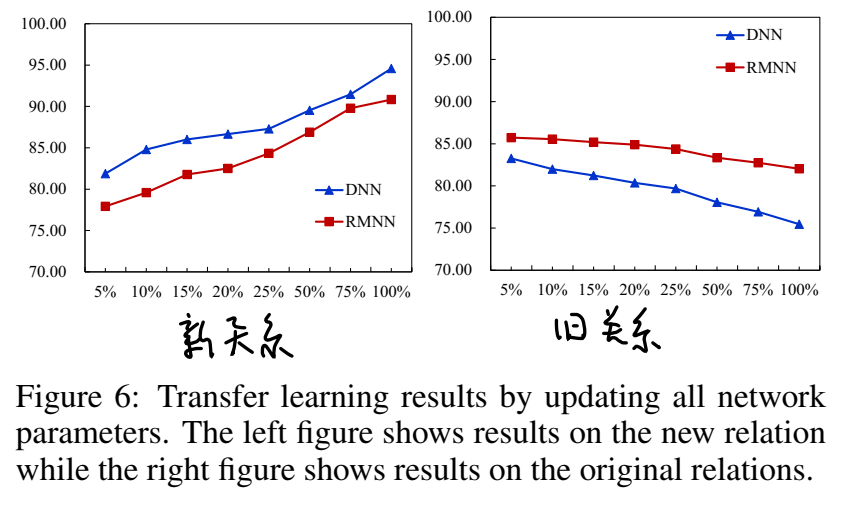
在开始这一章内容之前,我们先回顾一下之前学的高偏差和高方差问题。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mAB0HHzH-1670460299993)(吴恩达机器学习.assets/image-20211121101547868.png)]](https://img-blog.csdnimg.cn/e7bb9c96ccb34bc1a262658a4bf00901.png)
如果目前处于高方差问题,即出现上面左图情况,那么增加训练集数量是可以有效减少误差的。但如果处于高偏差问题,即出现上面右图情况,那么增加训练集数量并不能很好减少误差,所以这时就要通过增加特征量等方法去改善。
2. 随机梯度下降
我们之前讲到的梯度下降算法,其实并不能很好用在数据量十分大的情况下,因为它每次都要去遍历一遍数据集。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OKj2e0sN-1670460299998)(吴恩达机器学习.assets/image-20211121102959424.png)]](https://img-blog.csdnimg.cn/1027fe8d21b04445a152a17477ff00bc.png)
我们称之前用到梯度下降算法为批量梯度下降(Batch gradient descent),而接下来我们要介绍的就是随机梯度下降(Stochastic gradient descent)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wXidvGOb-1670460300000)(吴恩达机器学习.assets/image-20211121103421475.png)]](https://img-blog.csdnimg.cn/59677e8896aa4ea79e1331562de1509d.png)
随机梯度下降和批量梯度下降不同的地方就是,它每次拟合只使用一个数据,就修改一点点参数,对这个数据进行一次拟合,而不是将所有数据都遍历一遍再进行参数拟合。所以,这需要我们在一开始的时候就要对数据集进行一次打乱,并且得到的图像可能不会像批量梯度下降一样直接到达全局最小值,而是在一个范围内反复震荡最终接近于全局最小值。
3. Mini-Batch梯度下降
这节课我们来将学习大数据的另一种算法Mini-Batch梯度下降,它有时候会比随机梯度下降算法还要快。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BAojxNpT-1670460300002)(吴恩达机器学习.assets/image-20211121104114334.png)]](https://img-blog.csdnimg.cn/e52ef8fb4952497ebe495a5274156669.png)
这个算法就是前面两个算法的折中,我们每次参数拟合既不将所有数据都遍历,也不仅仅只使用一个数据,而是使用b个数据,而这个数一般在2-100之间,要根据实际数据量进行调整。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-041dMJdw-1670460300008)(吴恩达机器学习.assets/image-20211121104734694.png)]](https://img-blog.csdnimg.cn/ce0857321ebc4c3ea1f12ddd6d85873c.png)
从上面的具体步骤来看,这要比随机梯度下降算法更快,但是如果效果要比它更好的话,一般是要在有优秀的向量化方法下进行,这个算法的还有一个缺点就是要取b值,这可能也要花费一些时间。
4. 随机梯度下降收敛
上面讲完随机梯度下降算法后,我们还要考虑的是该如何判断训练是否已经达到收敛。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rAq5zyHP-1670460300011)(吴恩达机器学习.assets/image-20211121105523021.png)]](https://img-blog.csdnimg.cn/6483e96d9f0a4acfb96bfad9342a29b2.png)
比起批量算法每次都要遍历所有数据集算出代价函数来判断是否收敛,随机梯度则是只用在每次更新θ之前计算一次cost函数值,然后每进行1000次迭代,就对这1000次的cost函数值取一次平均值,最后画出图像来判断是否收敛。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JSo1Lbec-1670460300013)(吴恩达机器学习.assets/image-20211121110205155.png)]](https://img-blog.csdnimg.cn/ef6669aa0e0446c89802cf52a446ab7c.png)
如果你用的学习速率更小,可能会收敛到一个更低的位置,但是下降的会更缓慢一些,例如上图中红线代表学习速率更低的那条曲线。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LgicEBQT-1670460300015)(吴恩达机器学习.assets/image-20211121110352809.png)]](https://img-blog.csdnimg.cn/d0854c4e9dc549b0b28012e323ebc9de.png)
如果你选择的b更大的话,你就会得到一个更平滑的曲线,上图蓝线b为1000,红线b为5000。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6mHa2ZSm-1670460300017)(吴恩达机器学习.assets/image-20211121110606406.png)]](https://img-blog.csdnimg.cn/d612ee933c4445eea0a87468fb125ded.png)
有时候你可能会遇到上图蓝线的情况,这时候你可以增大b值即从1000变为5000,你可能就会得到红线,表明收敛还是在继续的,只是b太小的时候不图像并不明显,但是也有可能当你b调整为5000时会得到上面的紫线,并没有收敛,这时候你可能要考虑的就是要调整学习速率或调整特征或者其他东西了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2R8WQ9Y9-1670460300019)(吴恩达机器学习.assets/image-20211121110843028.png)]](https://img-blog.csdnimg.cn/03351fa7e8b848858b2da960d6833e8a.png)
如果得到了上面这个发散的图像,你要考虑的就是使用更小的学习速率。最后,再来讲一下学习速率。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5J5IHKZ5-1670460300021)(吴恩达机器学习.assets/image-20211121111524614.png)]](https://img-blog.csdnimg.cn/048640364d6e4e63ac90bad0f20a8ca2.png)
我们一般会让学习速率为一个常数,但是少数情况下有人也会使用让学习速率随时间的增加减少的方法,例如让一个常数除以迭代次数与另一个常数的和,这虽然最终会更接近最小值甚至找到最小值,但是会使算法变得更加复杂,因为要去选取合适的常数去计算,所以我们一般不会用这些方法,只要接近最小值就达到我们要求了。
5. 在线学习
接下来,我们来学习一个新的学习机制叫做在线学习机制,这当我们遇到有不断连续流入的数据的情况下可以使用。接下来,我们来看一个例子。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZKhxccGI-1670460300023)(吴恩达机器学习.assets/image-20211121112604554.png)]](https://img-blog.csdnimg.cn/d2677874f81649f5863a895d2d8d9533.png)
我们通过提取不断流入的数据进行学习,通过人们在什么价格下会选取我们的服务,来调整运费价格,从而可以满足新用户的期望。这种算法每用一次数据就会将其丢弃,因为这有大量连续的数据输入,不愁没有数据学习,并且这样还有一个好处就是可以跟上时代的步伐,适应不同时代人们的期望。下面来看关于在线学习的另一个例子。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ae3z1M0o-1670460300024)(吴恩达机器学习.assets/image-20211121113417934.png)]](https://img-blog.csdnimg.cn/5c88979ec4104f5d91ba08abaa6825ab.png)
在产品搜索中也可以用到在线学习,例如我们希望能通过用户输入的收集关键信息给他提供可能感兴趣的十部手机。这就需要我们通过学习其他用户的信息,通过不断学习训练判断用户输入的关键字中和我们手机匹配程度如何,通过他们在搜索结果中对产品的**点击率(CTR)**来不断改变我们的参数,更接近于用户的需求。
当然还有其他的应用,例如向用户展示什么样的特别优惠、在网站上给不同用户展示不同的新闻、商品推荐等等。
6. 减少映射与数据并行
如果你遇到了一些规模很大,随机梯度下降算法无法解决的问题,就可以用到接下来我们讲的Map-reduce方法。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G7K7jjGR-1670460300025)(吴恩达机器学习.assets/image-20211121124705557.png)]](https://img-blog.csdnimg.cn/c0ea68ab799e4d8dbb5a958f5d9d119d.png)
我们先来看看上面这个例子,假设我们用的是批量梯度下降算法并且有400个数据集,我们可以将它求和的部分分成四个部分然后发给四个不同的服务器计算,最终再将四个服务器的结果整合在一个中心服务器中,得到最终的结果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qMF779oi-1670460300027)(吴恩达机器学习.assets/image-20211121124948436.png)]](https://img-blog.csdnimg.cn/d6a92b35f95c46dc8fa7ff3b85b373a7.png)
所以Map_reduce可以看做是将数据集划分成相同的模块发送给不同服务器让他们并发运行,得到加倍的效率。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1z1GWa3s-1670460300028)(吴恩达机器学习.assets/image-20211121125301893.png)]](https://img-blog.csdnimg.cn/14afb1b099ea44e29ccd6536f82cc3ae.png)
故只要算法中包含求和的项,就可以使用Map_reduce对数据集进行划分处理,例如上面的另一个应用逻辑回归。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z7enYvYe-1670460300029)(吴恩达机器学习.assets/image-20211121125556538.png)]](https://img-blog.csdnimg.cn/6dbbf87c16c74924bfeaf75e73acdd2a.png)
当然,如果你有一台多核心的机器,你就可以将你划分出来的数据集分发给机器内的不同核心,这样就可以避免网络延迟的问题了。






![[选型] 实时数仓之技术选型](https://img-blog.csdnimg.cn/img_convert/41ccfc03b487d599a67a2b148245156b.png)