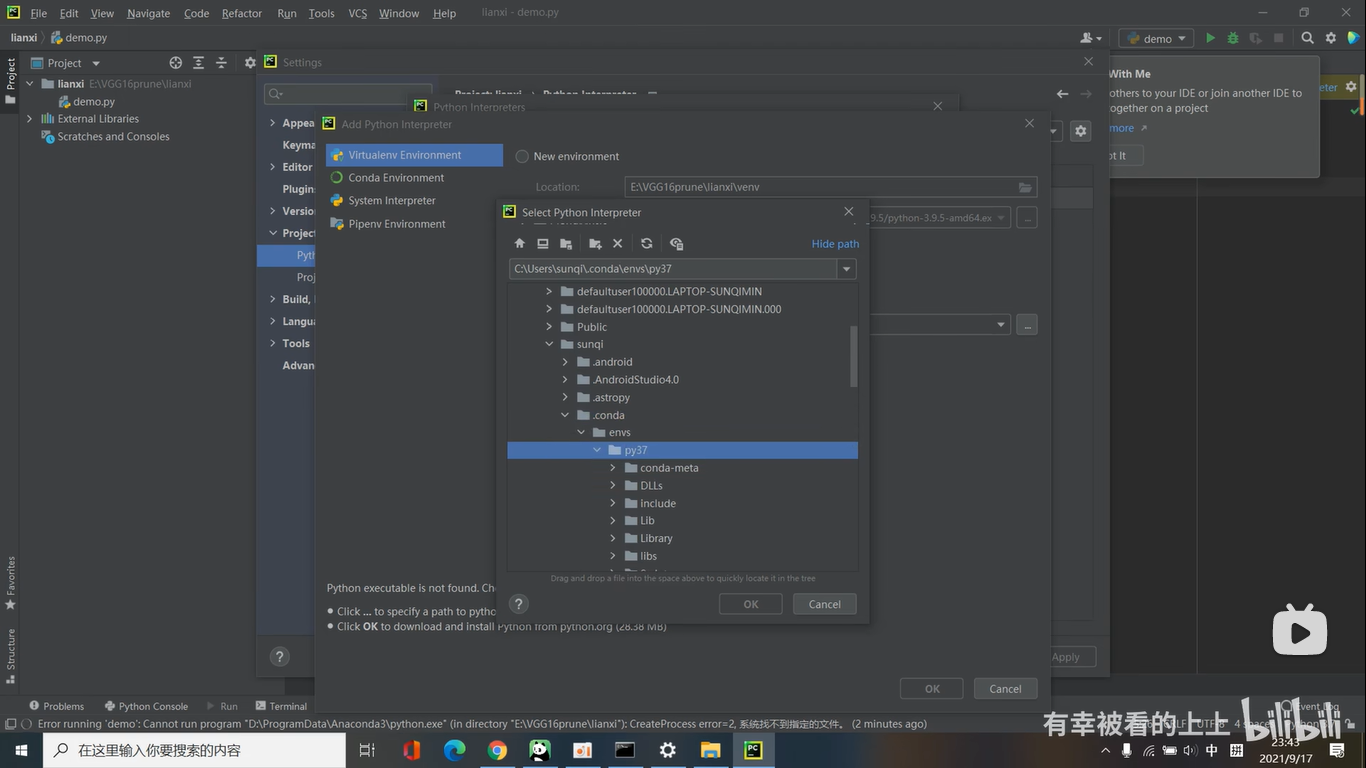
Distractor-aware Siamese Networks for Visual Object Tracking(DaSiamRPN,ECCV2018)
该论文针对以下三个问题,分别进行了改进:
- 常见的Siam类跟踪方法只能区分目标和无语义信息的背景(即简单背景),当背景是有语义的物体时,也就是有干扰物(distractor)时(即背景是同类物体,或不同类物体但它是个物体),表现不是很好,也就是在真目标变形或消失时容易drifting(漂移)到这些有语义的distractor上,所以这些方法的鲁棒性和长时跟踪效果不好。
- 大部分Siam类跟踪器在跟踪阶段不能更新模型,即它们的模板输入一直是第一帧被框住的目标,训练好的模型对不同特定目标都是一样的。这样带来了高速度,也相应牺牲了精度。
- 在长时跟踪的应用上,Siam类跟踪器不能很好的应对全遮挡、目标出画面等挑战,自己在做实验时发现跟踪器在目标消失时很容易把假的目标当成真的去跟踪,这样当真目标再次出现时,由于只是在局部搜索,跟踪器可能也不会再次把它当做真目标了,可能一直跟着那个假目标走了,说明网络没有学到这个目标的细粒度特征,只是学了个大概,只能区分简单的背景和目标。
针对上述三个问题,提出的解决方法如下:
-
针对训练数据中的非语义背景和具有语义的干扰物背景的数据不平衡问题(就是简单背景样本太多了,而困难负样本太少),作者把ImageNet和COCO检测数据库中的数据也通过数据增广的方式做成正样本对来扩大训练数据集的种类,提高网络的泛化能力;在不同的类别中和相同类别中分别提取照片作为负样本,制造困难负样本,这篇文章中除了使用简单的转换,光线变换,还使用了运动方向模糊的方法(运动方向可以从低层特征得到),以此来提升跟踪器的判别能力。
-
目前的训练策略已经增强了模型的判别力,但是模型还是难区分图像中对象很相似的情况,针对模型不更新(没有充分利用这个视频里的上下文信息)以及抑制distractor的问题,文中提出了干扰物识别模型(Distractor-aware Incremental Learning)。

f f f为互相关操作, z z z为当前帧的模板,该式最高的值 q q q是跟踪结果,通过非极大值抑制,选出大于某阈值的一些distractors就是干扰物 d i d_i di,然后到跟踪帧时,响应得分要减去这些干扰物与搜索区域的响应,即利用此函数对这些重新排序,当然从这个式子也可以看出,就是要使得target对象与模板之间越像越好,与 d i d_i di之间越不像越好。
有了上面的定义后,它们将跟踪当前帧作为一个增量学习过程,利用前面帧的信息来学习到当前帧的目标,就使得跟踪模板是在线更新的,可以处理很多目标严重遮挡,目标表观变化等问题。故这篇文章在跟踪的时候使用的是分类器而不是以往的相似性度量方式。 -
针对第三个不能长时跟踪的问题,本文提出了local-to-global的策略来进行长时间跟踪。注意:该策略的提出是在前两个改进的基础上提出的,是层层递进的关系,通过训练数据的增强和干扰物识别模型的提出,模型的判别能力已经很强了,这样在目标全遮挡时才可以扩大搜索区域。因为一扩大搜索区域,干扰物势必增多,如果没有前面的两个改进进行铺垫,肯定会把假目标当成真目标。
在做完SiamRPN之后,作者发现虽然跟踪的框已经回归地比较好了,但是响应的分数仍然相当不可靠,具体表现为在丢失目标的时候,分类的分数仍然比较高(例如0.8+),换句话说,作者推断SiamRPN只是学习到了objectness/non-objectness的区分。
之所以出现上面的问题,作者的结论是训练过程中的样本不均衡造成的。第一个是正样本种类不够多,导致模型的泛化性能不够强;作者的解决方案是加入detection的图片数据,pair可以由静态图片通过数据增益生成;加入detection数据生成的正样本之后,模型的泛化性能得到了比较大的提升。第二个样本不均衡来自于难例负样本,在之前的Siamese网络训练中, 负样本过于简单,很多事是没有语义信息的;作者的解决办法是用不同类之间的样本(还有同类的不同instance)构建难例负样本,从而增强分类器的判别能力。以上两个改进大大改善了相应分数的质量,跟踪器的判别能力得到了改善。
有了高质量的响应分数之后,一个bonus是可以做long-term的tracking。作者采用了一个比较简单local-to-global的扩展搜索区域方法,在UAV20L上面取得了state-of-the-art的结果。