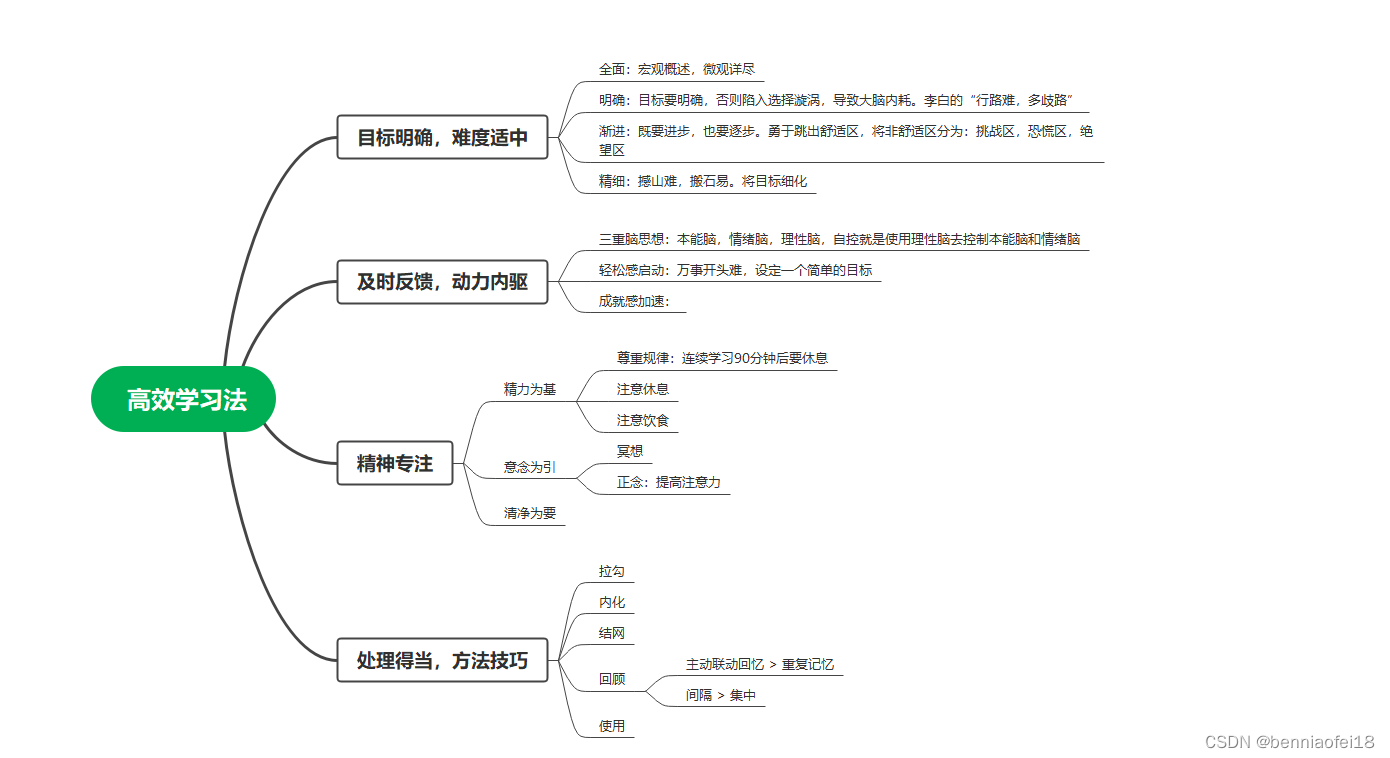
文章目录
- 需求分析
- 项目初始化
- 读取语料库文件
- 实现随机模块
- 生成文章
- 保存文章
- 命令行配置参数
- 命令行交互
- 废话版ChatGPT网页版
废话版ChatGPT 的功能是能根据语料库的配置和用户输入的规则,随机生成一篇可长可短的文本,里面的内容语句通顺,但是废话连篇。

需求分析
废话版ChatGPT的产品原型非常简单,就是用户设定主题和字数,应用根据内置的语料库,按照规则自动生成一篇随机的文章。
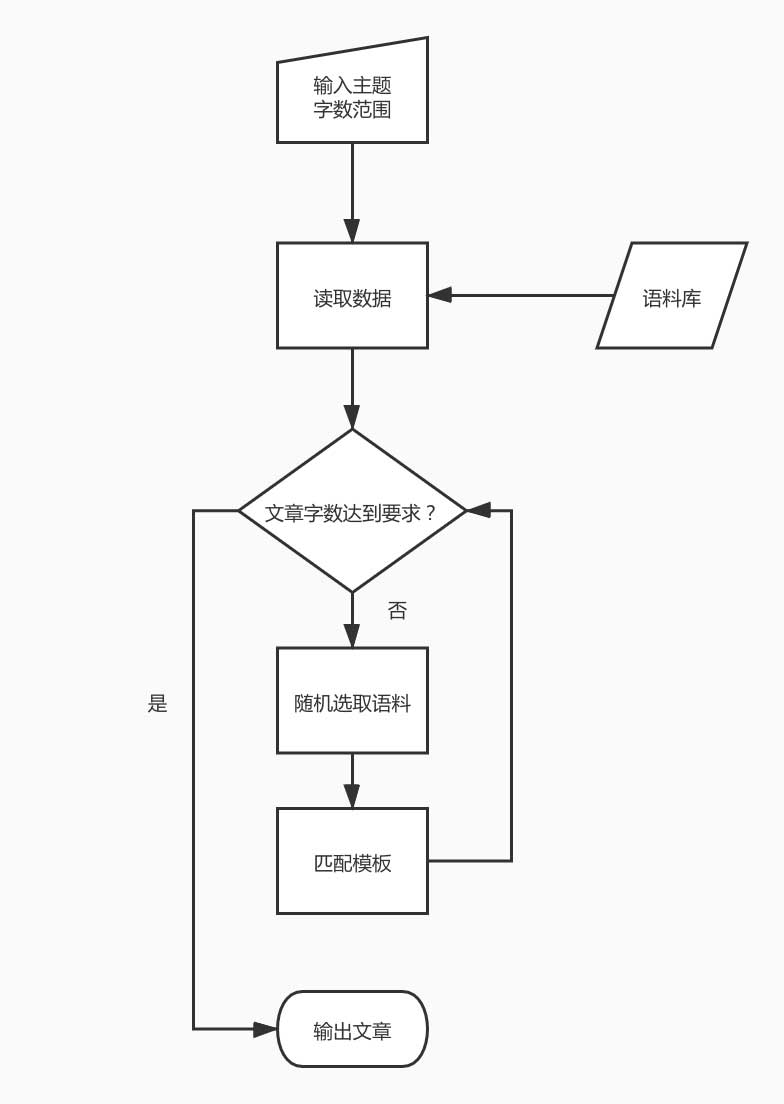
所以我们需要实现以下功能:
- 读取语料库并解析;
- 随机选取语料的随机算法;
- 字符串模板的参数替换;
- 文章内容的拼装;
- 生成文章输出。
如果再考虑到用户交互,我们还要完成:
- 接收命令行输入的参数;
- 提供给用户命令行使用指引;
- 输出文本内容的格式和存储。
总的来说,对应的技术点如下:
- 利用 fs 模块读取语料库文件内容;
- 实现一个随机模块,提供符合要求的随机算法;
- 使用正则表达式和字符串模板替换以及字符串拼接,完成文章生成;
- 使用 process.argv 接收用户参数,根据参数输出不同内容;
- 利用 fs 模块、二进制模块,将生成的文本内容保存成文本和图片格式。
项目初始化
我们npm init -y新建项目,叫 bullshit_generator,项目目录结构如下:
.
├── corpus # 存放语料库文件
│ └── data.json
├── index.js # 项目主文件
├── lib # 项目依赖的库文件
│ ├── generator.js # 生成文章内容
│ └── random.js # 提供随机算法
├── package.json # 项目的配置文件
└── output # 项目输入结果
corpus存放语料库文件,这是一份 json 文件,文件名 data.jsonindex.js是项目主文件,是一个可以运行的 Node.js 脚本lib目录下是项目依赖的库文件,这里我们不依赖外部的库,自己实现两个模块,一个是 generator.js 模块,用来生成文章内容,另一个是随机模块,用来提供随机算法package.json是项目的配置文件output存放项目输入结果
我们先按照这个项目目录结构来创建文件,跟着我往下走,接下来我们会一点点往里面填充内容。
读取语料库文件
首先来看看我们准备的语料库内容,它是一份 JSON 文件,可以直接复制过去,大致内容如下:
{
"title": [
"一天掉多少根头发",
"中午吃什么",
"学生会退会",
"好好学习",
"生活的意义",
"科学和人文谁更有意义",
"熬夜一时爽"
],
"famous":[
"爱迪生{{said}},天才是百分之一的勤奋加百分之九十九的汗水。{{conclude}}",
"查尔斯·史{{said}},一个人几乎可以在任何他怀有无限热忱的事情上成功。{{conclude}}",
"培根说过,深窥自己的心,而后发觉一切的奇迹在你自己。{{conclude}}",
"歌德曾经{{said}},流水在碰到底处时才会释放活力。{{conclude}}",
"莎士比亚{{said}},那脑袋里的智慧,就像打火石里的火花一样,不去打它是不肯出来的。{{conclude}}",
"戴尔·卡耐基{{said}},多数人都拥有自己不了解的能力和机会,都有可能做到未曾梦想的事情。{{conclude}}",
"白哲特{{said}},坚强的信念能赢得强者的心,并使他们变得更坚强。{{conclude}}",
"伏尔泰{{said}},不经巨大的困难,不会有伟大的事业。{{conclude}}",
"富勒曾经{{said}},苦难磨炼一些人,也毁灭另一些人。{{conclude}}",
"文森特·皮尔{{said}},改变你的想法,你就改变了自己的世界。{{conclude}}",
"拿破仑·希尔{{said}},不要等待,时机永远不会恰到好处。{{conclude}}",
"塞涅卡{{said}},生命如同寓言,其价值不在与长短,而在与内容。{{conclude}}",
"奥普拉·温弗瑞{{said}},你相信什么,你就成为什么样的人。{{conclude}}",
"吕凯特{{said}},生命不可能有两次,但许多人连一次也不善于度过。{{conclude}}",
"莎士比亚{{said}},人的一生是短的,但如果卑劣地过这一生,就太长了。{{conclude}}",
"笛卡儿{{said}},我的努力求学没有得到别的好处,只不过是愈来愈发觉自己的无知。{{conclude}}",
"左拉{{said}},生活的道路一旦选定,就要勇敢地走到底,决不回头。{{conclude}}",
"米歇潘{{said}},生命是一条艰险的峡谷,只有勇敢的人才能通过。{{conclude}}",
"吉姆·罗恩{{said}},要么你主宰生活,要么你被生活主宰。{{conclude}}",
"日本谚语{{said}},不幸可能成为通向幸福的桥梁。{{conclude}}",
"海贝尔{{said}},人生就是学校。在那里,与其说好的教师是幸福,不如说好的教师是不幸。{{conclude}}",
"杰纳勒尔·乔治·S·巴顿{{said}},接受挑战,就可以享受胜利的喜悦。{{conclude}}",
"德谟克利特{{said}},节制使快乐增加并使享受加强。{{conclude}}",
"裴斯泰洛齐{{said}},今天应做的事没有做,明天再早也是耽误了。{{conclude}}",
"歌德{{said}},决定一个人的一生,以及整个命运的,只是一瞬之间。{{conclude}}",
"卡耐基{{said}},一个不注意小事情的人,永远不会成就大事业。{{conclude}}",
"卢梭{{said}},浪费时间是一桩大罪过。{{conclude}}",
"康德{{said}},既然我已经踏上这条道路,那么,任何东西都不应妨碍我沿着这条路走下去。{{conclude}}",
"克劳斯·莫瑟爵士{{said}},教育需要花费钱,而无知也是一样。{{conclude}}",
"伏尔泰{{said}},坚持意志伟大的事业需要始终不渝的精神。{{conclude}}",
"亚伯拉罕·林肯{{said}},你活了多少岁不算什么,重要的是你是如何度过这些岁月的。{{conclude}}",
"韩非{{said}},内外相应,言行相称。{{conclude}}",
"富兰克林{{said}},你热爱生命吗?那么别浪费时间,因为时间是组成生命的材料。{{conclude}}",
"马尔顿{{said}},坚强的信心,能使平凡的人做出惊人的事业。{{conclude}}",
"笛卡儿{{said}},读一切好书,就是和许多高尚的人谈话。{{conclude}}",
"塞涅卡{{said}},真正的人生,只有在经过艰难卓绝的斗争之后才能实现。{{conclude}}",
"易卜生{{said}},伟大的事业,需要决心,能力,组织和责任感。{{conclude}}",
"歌德{{said}},没有人事先了解自己到底有多大的力量,直到他试过以后才知道。{{conclude}}",
"达尔文{{said}},敢于浪费哪怕一个钟头时间的人,说明他还不懂得珍惜生命的全部价值。{{conclude}}",
"佚名{{said}},感激每一个新的挑战,因为它会锻造你的意志和品格。{{conclude}}",
"奥斯特洛夫斯基{{said}},共同的事业,共同的斗争,可以使人们产生忍受一切的力量。 {{conclude}}",
"苏轼{{said}},古之立大事者,不惟有超世之才,亦必有坚忍不拔之志。{{conclude}}",
"王阳明{{said}},故立志者,为学之心也;为学者,立志之事也。{{conclude}}",
"歌德{{said}},读一本好书,就如同和一个高尚的人在交谈。{{conclude}}",
"乌申斯基{{said}},学习是劳动,是充满思想的劳动。{{conclude}}",
"别林斯基{{said}},好的书籍是最贵重的珍宝。{{conclude}}",
"富兰克林{{said}},读书是易事,思索是难事,但两者缺一,便全无用处。{{conclude}}",
"鲁巴金{{said}},读书是在别人思想的帮助下,建立起自己的思想。{{conclude}}",
"培根{{said}},合理安排时间,就等于节约时间。{{conclude}}",
"屠格涅夫{{said}},你想成为幸福的人吗?但愿你首先学会吃得起苦。{{conclude}}",
"莎士比亚{{said}},抛弃时间的人,时间也抛弃他。{{conclude}}",
"叔本华{{said}},普通人只想到如何度过时间,有才能的人设法利用时间。{{conclude}}",
"博{{said}},一次失败,只是证明我们成功的决心还够坚强。 维{{conclude}}",
"拉罗什夫科{{said}},取得成就时坚持不懈,要比遭到失败时顽强不屈更重要。{{conclude}}",
"莎士比亚{{said}},人的一生是短的,但如果卑劣地过这一生,就太长了。{{conclude}}",
"俾斯麦{{said}},失败是坚忍的最后考验。{{conclude}}",
"池田大作{{said}},不要回避苦恼和困难,挺起身来向它挑战,进而克服它。{{conclude}}",
"莎士比亚{{said}},那脑袋里的智慧,就像打火石里的火花一样,不去打它是不肯出来的。{{conclude}}",
"希腊{{said}},最困难的事情就是认识自己。{{conclude}}",
"黑塞{{said}},有勇气承担命运这才是英雄好汉。{{conclude}}",
"非洲{{said}},最灵繁的人也看不见自己的背脊。{{conclude}}",
"培根{{said}},阅读使人充实,会谈使人敏捷,写作使人精确。{{conclude}}",
"斯宾诺莎{{said}},最大的骄傲于最大的自卑都表示心灵的最软弱无力。{{conclude}}",
"西班牙{{said}},自知之明是最难得的知识。{{conclude}}",
"塞内加{{said}},勇气通往天堂,怯懦通往地狱。{{conclude}}",
"赫尔普斯{{said}},有时候读书是一种巧妙地避开思考的方法。{{conclude}}",
"笛卡儿{{said}},阅读一切好书如同和过去最杰出的人谈话。{{conclude}}",
"邓拓{{said}},越是没有本领的就越加自命不凡。{{conclude}}",
"爱尔兰{{said}},越是无能的人,越喜欢挑剔别人的错儿。{{conclude}}",
"老子{{said}},知人者智,自知者明。胜人者有力,自胜者强。{{conclude}}",
"歌德{{said}},意志坚强的人能把世界放在手中像泥块一样任意揉捏。{{conclude}}",
"迈克尔·F·斯特利{{said}},最具挑战性的挑战莫过于提升自我。{{conclude}}",
"爱迪生{{said}},失败也是我需要的,它和成功对我一样有价值。{{conclude}}",
"罗素·贝克{{said}},一个人即使已登上顶峰,也仍要自强不息。{{conclude}}",
"马云{{said}},最大的挑战和突破在于用人,而用人最大的突破在于信任人。{{conclude}}",
"雷锋{{said}},自己活着,就是为了使别人过得更美好。{{conclude}}",
"布尔沃{{said}},要掌握书,莫被书掌握;要为生而读,莫为读而生。{{conclude}}",
"培根{{said}},要知道对好事的称颂过于夸大,也会招来人们的反感轻蔑和嫉妒。{{conclude}}",
"莫扎特{{said}},谁和我一样用功,谁就会和我一样成功。{{conclude}}",
"马克思{{said}},一切节省,归根到底都归结为时间的节省。{{conclude}}",
"莎士比亚{{said}},意志命运往往背道而驰,决心到最后会全部推倒。{{conclude}}",
"卡莱尔{{said}},过去一切时代的精华尽在书中。{{conclude}}",
"培根{{said}},深窥自己的心,而后发觉一切的奇迹在你自己。{{conclude}}",
"罗曼·罗兰{{said}},只有把抱怨环境的心情,化为上进的力量,才是成功的保证。{{conclude}}",
"孔子{{said}},知之者不如好之者,好之者不如乐之者。{{conclude}}",
"达·芬奇{{said}},大胆和坚定的决心能够抵得上武器的精良。{{conclude}}",
"叔本华{{said}},意志是一个强壮的盲人,倚靠在明眼的跛子肩上。{{conclude}}",
"黑格尔{{said}},只有永远躺在泥坑里的人,才不会再掉进坑里。{{conclude}}",
"普列姆昌德{{said}},希望的灯一旦熄灭,生活刹那间变成了一片黑暗。{{conclude}}",
"维龙{{said}},要成功不需要什么特别的才能,只要把你能做的小事做得好就行了。{{conclude}}",
"郭沫若{{said}},形成天才的决定因素应该是勤奋。{{conclude}}",
"洛克{{said}},学到很多东西的诀窍,就是一下子不要学很多。{{conclude}}",
"西班牙{{said}},自己的鞋子,自己知道紧在哪里。{{conclude}}",
"拉罗什福科{{said}},我们唯一不会改正的缺点是软弱。{{conclude}}",
"亚伯拉罕·林肯{{said}},我这个人走得很慢,但是我从不后退。{{conclude}}",
"美华纳{{said}},勿问成功的秘诀为何,且尽全力做你应该做的事吧。{{conclude}}",
"俾斯麦{{said}},对于不屈不挠的人来说,没有失败这回事。{{conclude}}",
"阿卜·日·法拉兹{{said}},学问是异常珍贵的东西,从任何源泉吸收都不可耻。{{conclude}}",
"白哲特{{said}},坚强的信念能赢得强者的心,并使他们变得更坚强。 {{conclude}}",
"查尔斯·史考伯{{said}},一个人几乎可以在任何他怀有无限热忱的事情上成功。 {{conclude}}",
"贝多芬{{said}},卓越的人一大优点是:在不利与艰难的遭遇里百折不饶。{{conclude}}",
"莎士比亚{{said}},本来无望的事,大胆尝试,往往能成功。{{conclude}}",
"卡耐基{{said}},我们若已接受最坏的,就再没有什么损失。{{conclude}}",
"德国{{said}},只有在人群中间,才能认识自己。{{conclude}}",
"史美尔斯{{said}},书籍把我们引入最美好的社会,使我们认识各个时代的伟大智者。{{conclude}}",
"冯学峰{{said}},当一个人用工作去迎接光明,光明很快就会来照耀着他。{{conclude}}",
"吉格·金克拉{{said}},如果你能做梦,你就能实现它。{{conclude}}"
],
"bosh_before": [
"既然如此,",
"那么,",
"我认为,",
"一般来说,",
"总结的来说,",
"无论如何,",
"经过上述讨论,",
"这样看来,",
"从这个角度来看,",
"现在,解决{{title}}的问题,是非常非常重要的。 所以,",
"每个人都不得不面对这些问题。在面对这种问题时,",
"我们不得不面对一个非常尴尬的事实,那就是,",
"而这些并不是完全重要,更加重要的问题是,",
"我们不妨可以这样来想: "
],
"bosh":[
"{{title}}的发生,到底需要如何做到,不{{title}}的发生,又会如何产生。 ",
"{{title}},到底应该如何实现。 ",
"带着这些问题,我们来审视一下{{title}}。 ",
"所谓{{title}},关键是{{title}}需要如何写。 ",
"我们一般认为,抓住了问题的关键,其他一切则会迎刃而解。",
"问题的关键究竟为何? ",
"{{title}}因何而发生?",
"一般来讲,我们都必须务必慎重的考虑考虑。 ",
"要想清楚,{{title}},到底是一种怎么样的存在。 ",
"了解清楚{{title}}到底是一种怎么样的存在,是解决一切问题的关键。",
"就我个人来说,{{title}}对我的意义,不能不说非常重大。 ",
"本人也是经过了深思熟虑,在每个日日夜夜思考这个问题。 ",
"{{title}},发生了会如何,不发生又会如何。 ",
"在这种困难的抉择下,本人思来想去,寝食难安。",
"生活中,若{{title}}出现了,我们就不得不考虑它出现了的事实。 ",
"这种事实对本人来说意义重大,相信对这个世界也是有一定意义的。",
"我们都知道,只要有意义,那么就必须慎重考虑。",
"这是不可避免的。 ",
"可是,即使是这样,{{title}}的出现仍然代表了一定的意义。 ",
"{{title}}似乎是一种巧合,但如果我们从一个更大的角度看待问题,这似乎是一种不可避免的事实。 ",
"在这种不可避免的冲突下,我们必须解决这个问题。 ",
"对我个人而言,{{title}}不仅仅是一个重大的事件,还可能会改变我的人生。 "
],
"conclude":[
"这不禁令我深思。 ",
"带着这句话,我们还要更加慎重的审视这个问题: ",
"这启发了我。",
"我希望诸位也能好好地体会这句话。 ",
"这句话语虽然很短,但令我浮想联翩。",
"这句话看似简单,但其中的阴郁不禁让人深思。",
"这句话把我们带到了一个新的维度去思考这个问题:",
"这似乎解答了我的疑惑。"
],
"said":[
"曾经说过",
"在不经意间这样说过",
"说过一句著名的话",
"曾经提到过",
"说过一句富有哲理的话"
]
}
我们将这份文件保存在项目的 corpus 目录下,我们发现这份文件里面一共有六个字段:
title表示文章的主题famous表示名人名言bosh_before表示废话的前置分句bosh表示废话的主体conclude表示结论said是名人名言中可选的文字片段
我们这个项目采用 ES Modules 模块规范,所以我们先在 package.json 中配置一下 type: module
接下来我们就编写 index.js 文件来从项目中读取这份语料库配置
读取文件内容可以采用 fs 内置模块,读取文件的内容用到两个 API:
readFile异步地读取文件内容readFileSync同步地读取文件内容
// index.js
import {readFile,readFileSync} from 'fs';
// readFile 是异步方法,第一个参数是要读取的文件的路径,第二个参数是编码格式,用来将返回的二进制Buffer对象转变成文本信息,第三个参数可以是一个回调函数,当文件读取成功或读取失败时,readFile 都会回调这个函数,根据不同的情况返回不同的内容。如果成功,返回的 err 为 null,data 为实际文件内容;否则,err 为一个包含了错误信息的对象。
readFile('./corpus/data.json', {encoding: 'utf-8'}, (err, data) => {
if(!err) {
console.log(data);
} else {
console.error(err);
}
});
// readFile 是异步读取文件内容,如果读取的文件很大,又不希望阻塞后续的操作,可以使用这个方法
// 但是如果文件不大,更简单的方式是使用同步读取文件的 readFileSync 方法
const data = readFileSync('./corpus/data.json', {encoding: 'utf-8'});
console.log(data);
上面的代码我们通过路径./corpus/data.json 来读取文件,如果我们在项目根目录运行 index.js,这没有问题。但是,如果我们从其他目录执行它就会报错,错误信息是./corpus/data.json 文件不存在。
这是因为我们使用的相对路径./corpus/data.json 是相对于脚本的运行目录(即 node 执行脚本的目录),而不是脚本文件的目录。
要让这个命令在任何目录下运行都能正确找到文件,我们必须要修改路径的方式,从相对于脚本运行的目录改为相对于脚本文件的目录。
import {readFileSync} from 'fs';
import {fileURLToPath} from 'url';
import {dirname, resolve} from 'path';
const url = import.meta.url; // 获得当前脚本文件的 URL 地址
const path = resolve(dirname(fileURLToPath(url)), 'corpus/data.json');// 这条语句表示将当前脚本文件的 url 地址转化成文件路径,然后再通过 resolve 将相对路径转变成 data.json 文件的绝对路径
const data = readFileSync(path, {encoding: 'utf-8'});
console.log(data);
import.meta.url表示获得当前脚本文件的 URL 地址,因为ES Modules是通过 URL 规范来引用文件的(这就统一了浏览器和 Node.js 环境)url是 Node.js 的内置模块,用来解析 url 地址。fileURLToPath是这个模块的方法,可以将 url 转为文件路径path是 Node.js 处理文件路径的内置模块。dirname和resolve是它的两个方法,dirname方法可以获得当前 JS 文件的目录,而resolve方法可以将 JS 文件目录和相对路径corpus/data.json拼在一起,最终获得正确的文件路径。
💡因为本项目采用
ES Modules模块规范,所以需要通过fileURLToPath来转换路径。如果采用
CommonJS规范,就可以直接通过模块中的内置变量__dirname获得当前 JS 文件的工作目录。因此在使用
CommonJS规范时,上面的代码可以简写为const path = resolve(__dirname, 'corpus/data.json')。
到目前为止,我们成功读取了文件的字符串内容
要将它转成 JSON 对象使用,我们只需要调用 JSON.parse 即可: const corpus = JSON.parse(data);
实现随机模块
刚刚介绍了如何使用 fs 模块读取语料库文件(corpus/data.json)。现在我们来实现一个随机模块,从语料库文件中随机选择内容。
我们知道,语料库中的数据是基础语料内容。生成文章时,我们需要读取这些内容,从中随机选择一些句子进行拼接,所以我们需要实现一个能够随机选取内容的模块。
我们在lib模块下创建 random.js。这个模块有两个方法:randomInt 和 randomPick
randomInt 方法是返回一定范围内的整数,用来控制随机生成的文章和段落的长度范围
实现 randomInt 原理很简单,我们只需要用 Math.random() 对 min 和 max 两个参数进行线性插值,然后将结果向下取整即可:
// randomInt 函数返回一个大于等于 min,小于 max 的随机整数
export function randomInt(min = 0, max = 100) {
const p = Math.random();
return Math.floor(min * (1 - p) + max * p);
}
const articleLength = randomInt(3000, 5000); //设置文章长度介于3000~5000字
const sectionLength = randomInt(200, 500); // 设置段落长度介于200到500字
randomPick 方法可以从数组中随机选择元素,具体实现细节可以看下面的注释:
// 避免原本数组末位的那个元素在第一次随机取时永远取不到的问题
export function createRandomPicker(arr) {
arr = [...arr]; // copy 数组,以免修改原始数据
// 随机选出数组中的一个元素
function randomPick() {
// 避免连续两次选择到同样的元素
// 将随机取数的范围从数组长度更改为数组长度减一,这样就不会取到数组最后一位的元素
const len = arr.length - 1;
const index = randomInt(0, len);
const picked = arr[index];
// 把每次取到的元素都和数组最后一位的元素进行交换,这样每次取过的元素下一次就在数组最后一位了
// 下一次也就不能取到它了,而下一次取到的数又会将它换出来,那么再一次就又能取到它了
[arr[index], arr[len]] = [arr[len], arr[index]];
return picked;
}
randomPick(); // 抛弃第一次选择结果,初始在数组末位的那个元素第一次肯定不会被取到,破坏了随机性
return randomPick;
}
有了这两个函数,我们就实现了随机模块 random.js:
randomInt返回一定范围内的整数,用来控制随机生成的文章和段落的长度范围randomPick函数能够从语料库的数组中随机地选择元素并返回
接下来我们就使用这个 random.js随机模块生成我们的文章
生成文章
我们来实现文章生成的模块,把生成文章模块命名为 generator.js
它导出一个 generate 函数,这个函数根据传入的 title(文章主题)和语料库以及配置信息来生成文章内容
我们先来定义句子生成的规则,还记得corpus/data.json里的结构吗?可以回去看一眼!
文章中的句子有两种类型,名人名言定义在 corpus 对象的 famous 字段中;废话定义在 corpus 对象的 bosh 字段中。剩下的几个字段 bosh_before、said 和 conclude 是用来修饰和替换 famous 以及 bosh 里面的内容的。
我们利用实现的随机模块将句子中的内容从 famous、bosh 以及其他字段的数组中随机取出一条:
const pickFamous = createRandomPicker(corpus.famous);
const pickBosh = createRandomPicker(corpus.bosh);
pickFamous(); // 随机取出一条名人名言
pickBosh(); // 随机取出一条废话
语料库中名人名言和废话的内容都是模板,形式类似于下面这样:
"歌德曾经{{said}},流水在碰到底处时才会释放活力。{{conclude}}" // 名人名言
"{{title}}的发生,到底需要如何做到,不{{title}}的发生,又会如何产生。 " // 废话
因此,我们要将占位符 {{said}} 用 corpus.said 中随机取的内容替换,将占位符 {{conclude}} 用 corpus.conclude 中随机取的替换,将 {{title}} 用传入的 title 字符串替换。
我们来实现一个替换句子的通用方法:
// 替换方法
function sentence(pick, replacer) {
let ret = pick(); // 返回一个句子文本
for(const key in replacer) { // replacer是一个对象,存放替换占位符的规则
// 如果 replacer[key] 是一个 pick 函数,那么执行它随机取一条替换占位符,否则将它直接替换占位符
ret = ret.replace(new RegExp(`{{${key}}}`, 'g'),
typeof replacer[key] === 'function' ? replacer[key]() : replacer[key]);
}
return ret;
}
// 我们来试一试生成句子
const {famous, bosh_before, bosh, said, conclude} = corpus;
const [pickFamous, pickBoshBefore, pickBosh, pickSaid, pickConclude] = [famous, bosh_before, bosh, said, conclude].map((item) => {
return createRandomPicker(item);
});
sentence(pickFamous, {said: pickSaid, conclude: pickConclude}); // 生成一条名人名言
sentence(pickBosh, {title}); // 生成一条废话
好,现在已经可以生成了句子,那它们该如何组成段落和文章呢?
我们知道,段落由句子组成,文章又由段落组成,所以可以进行如下设置:
- 规定每个段落的字数在 200~500 字之间。每个段落包含 20% 的名人名言(famous),80% 的废话(bosh)。其中,废话里带前置从句(bosh_before)的废话占文章句子的 30%,不带前置从句的废话占文章句子的 50%;
- 规定文章的字数在用户设置的最小字数到最大字数之间。
按照上述的规则,我们来生成文章:
export function generate(title, {
corpus,
min = 6000, // 文章最少字数
max = 10000, // 文章最多字数
} = {}) {
// 将文章长度设置为 min 到 max之间的随机数
const articleLength = randomInt(min, max);
const {famous, bosh_before, bosh, said, conclude} = corpus;
const [pickFamous, pickBoshBefore, pickBosh, pickSaid, pickConclude] = [famous, bosh_before, bosh, said, conclude].map((item) => {
return createRandomPicker(item);
});
const article = [];
let totalLength = 0;
while(totalLength < articleLength) {
// 如果文章内容的字数未超过文章总字数
let section = ''; // 添加段落
const sectionLength = randomInt(200, 500); // 将段落长度设为200到500字之间
// 如果当前段落字数小于段落长度,或者当前段落不是以句号。和问号?结尾
while(section.length < sectionLength || !/[。?]$/.test(section)) {
// 取一个 0~100 的随机数
const n = randomInt(0, 100);
if(n < 20) { // 如果 n 小于 20,生成一条名人名言,也就是文章中有百分之二十的句子是名人名言
section += sentence(pickFamous, {said: pickSaid, conclude: pickConclude});
} else if(n < 50) {
// 如果 n 小于 50,生成一个带有前置从句的废话
section += sentence(pickBoshBefore, {title}) + sentence(pickBosh, {title});
} else {
// 否则生成一个不带有前置从句的废话
section += sentence(pickBosh, {title});
}
}
// 段落结束,更新总长度
totalLength += section.length;
// 将段落存放到文章列表中
article.push(section);
}
// 将文章返回,文章是段落数组形式
return article;
}
保存文章
我们生成了文章之后就可以将它输出到控制台或者保存成文件,我们先来看一下如何将它输出到控制台:
// index.js
import {readFileSync} from 'fs';
import {fileURLToPath} from 'url';
import {dirname, resolve} from 'path';
import {generate} from './lib/generator.js';
import {createRandomPicker} from './lib/random.js';
const __dirname = dirname(fileURLToPath(import.meta.url));
// 将读取 JSON 文件的代码封装成一个函数 loadCorpus
function loadCorpus(src) {
const path = resolve(__dirname, src);
const data = readFileSync(path, {encoding: 'utf-8'});
return JSON.parse(data);
}
const corpus = loadCorpus('corpus/data.json');
// 通过 pickTitle 随机选择一个 title
const pickTitle = createRandomPicker(corpus.title);
const title = pickTitle();
// 调用 generate 方法拿到 article 数组
const article = generate(title, {corpus});
// 通过字符串的 join 方法将数组里面的段落内容拼成文章,最后用 `console.log` 输出
console.log(`${title}\n\n ${article.join('\n ')}`);
如果我们想要将生成的文章保存下来,我们可以用 fs 模块的writeFileSync
先来封装一个保存文件的函数:
// index.js
function saveCorpus(title, article) {
const outputDir = resolve(__dirname, 'output');
const outputFile = resolve(outputDir, `${title}.txt`);
// 检查outputDir是否存在,没有则创建一个
if(!existsSync(outputDir)) {
mkdirSync(outputDir);
}
const text = `${title}\n\n ${article.join('\n ')}`;
writeFileSync(outputFile, text); // 将text写入outputFile文件中
return outputFile;
}
这样我们在项目下执行 node index.js,就能够在 output 目录中找到生成的文章了。
但是这样生成的文章到 output 目录有一个问题:如果我们两次生成同一个主题的文章,新的文章就会将旧的文章给覆盖掉。
一个比较好的解决办法是,我们在保存文件的时候,在文件名后面加上文件生成的时间。
我们这里使用第三方库 moment.js ,先来npm install moment --save安装一下
// 简单修改一下 saveCorpus 函数,在文件名后面添加时间戳
function saveCorpus(title, article) {
const outputDir = resolve(__dirname, 'output');
const time = moment().format('mmss');
const outputFile = resolve(outputDir, `${title}${time}.txt`);
if(!existsSync(outputDir)) {
mkdirSync(outputDir);
}
const text = `${title}\n\n ${article.join('\n ')}`;
writeFileSync(outputFile, text);
return outputFile;
}
我们来看一下实现的效果:

命令行配置参数
我们刚刚完成了文章生成和保存的功能,但是我们现在还不能自定义文章的标题,也不能配置文章的字数。现在我们就来通过命令行配置标题和字数,自由生成我们想要的文章。
说到命令行,大家第一时间想到的一定是 process 模块,我们首先来用 process 试一试
我们可以通过将 process.argv 数组遍历出来的方式获取参数:
function parseOptions(options = {}) {
const argv = process.argv;
for(let i = 2; i < argv.length; i++) {
const cmd = argv[i - 1];
const value = argv[i];
// 判断 process.argv 的值
if(cmd === '--title') {
// 如果读取到 title,那么它后面紧跟着的参数即是我们要的文章主题
options.title = value;
// 读取到 min 和 max,那么将它们后面的参数作为最小字数 / 最大字数取出
} else if(cmd === '--min') {
options.min = Number(value);
} else if(cmd === '--max') {
options.max = Number(value);
}
}
return options;
}
这样,我们就可以读取命令行中的参数了,然后稍微改一下调用方式:
const corpus = loadCorpus('corpus/data.json');
const options = parseOptions();
const title = options.title || createRandomPicker(corpus.title)();
const article = generate(title, {corpus, ...options});
const output = saveToFile(title, article);
console.log(`生成成功!文章保存于:${output}`);
这样就可以选择标题、控制字数了,但是虽然我们完成了功能却并不完美,因为这样做不能控制用户输入的错误
如果我们传入一个未定义的参数,或者参数重复,程序都不会报错
因为 Node.js 内置的 process 模块无法方便地检查用户的输入
所以我们需要使用三方库 command-line-args 替代 process.argv,它不仅能获得用户的输入,还能检测用户的输入是否正确
我们在项目中安装一下:npm install command-line-args --save
然后修改 index.js :
import commandLineArgs from 'command-line-args';
const corpus = loadCorpus('corpus/data.json');
// command-line-args 是基于配置的,来配置我们的命令行参数
const optionDefinitions = [
{name: 'title', type: String},
{name: 'min', type: Number},
{name: 'max', type: Number},
];
const options = commandLineArgs(optionDefinitions); // 获取命令行的输入
const title = options.title || createRandomPicker(corpus.title)();
const article = generate(title, {corpus, ...options});
const output = saveToFile(title, article);
console.log(`生成成功!文章保存于:${output}`);
这样,如果我们传入重复的参数或者传入错误的参数,命令行都会报错
为了让我们的应用更加友好,我们还可以添加一个 --help 参数,告知用户有哪些合法的参数以及每个参数的意义。
这个功能可以通过第三方库command-line-usage来完成,我们来安装一下 command-line-usage 包:npm install command-line-usage --save
然后,我们使用它定义 help 输出的内容,这是一份 JSON 配置:
import commandLineUsage from 'command-line-usage';
// 定义help的内容
const sections = [
{
header: '狗屁不通文章生成器',
content: '生成随机的文章段落用于测试',
},
{
header: 'Options',
optionList: [
{
name: 'title',
typeLabel: '{underline string}',
description: '文章的主题。',
},
{
name: 'min',
typeLabel: '{underline number}',
description: '文章最小字数。',
},
{
name: 'max',
typeLabel: '{underline number}',
description: '文章最大字数。',
},
],
},
];
const usage = commandLineUsage(sections); // 生成帮助文本
然后,我们在 command-line-args 中添加一下 --help 命令的配置:
const corpus = loadCorpus('corpus/data.json');
const optionDefinitions = [
{name: 'help'}, // help命令配置
{name: 'title', type: String},
{name: 'min', type: Number},
{name: 'max', type: Number},
];
const options = commandLineArgs(optionDefinitions);
if('help' in options) { // 如果输入的是help,就打印帮助文本
console.log(usage);
} else {
const title = options.title || createRandomPicker(corpus.title)();
const article = generate(title, {corpus, ...options});
const output = saveCorpus(title, article);
console.log(`生成成功!文章保存于:${output}`);
}
我们判断命令中如果有 --help 那么就打印使用帮助,否则就输出文章。
那么运行 node index.js --help 实际效果如下图所示:

命令行交互
为了让程序可以和用户交互,我们将使用 process.stdin 和 readline 模块来让我们的文章生成器应用实现了交互式的命令行功能
stdin 是一个异步模块,它通过监听输入时间并执行回调来处理用户输入
我们先来用process.stdin实现一个 interact.js 的模块,让它接受我们定义好的一系列问题,并等待用户一一回答:
// interact.js
export function interact(questions) {
// questions 是一个数组,内容如 {text, value}
process.stdin.setEncoding('utf8');
return new Promise((resolve) => {
const answers = [];
let i = 0;
let {text, value} = questions[i++];
console.log(`${text}(${value})`);
process.stdin.on('readable', () => {
const chunk = process.stdin.read().slice(0, -1);
answers.push(chunk || value); // 保存用户的输入,如果用户输入为空,则使用缺省值
const nextQuestion = questions[i++];
if(nextQuestion) { //如果问题还未结束,继续监听用户输入
process.stdin.read();
text = nextQuestion.text;
value = nextQuestion.value;
console.log(`${text}(${value})`);
} else { // 如果问题结束了,结束readable监听事件
resolve(answers);
}
});
});
}
然后,我们可以在 index.js 中,通过 async/await 方式,等待用户回答所有问题后,再进行文章生成的操作:
// index.js
import {interact} from './lib/interact.js';
const corpus = loadCorpus('corpus/data.json');
let title = options.title || createRandomPicker(corpus.title)();
(async function () {
if(Object.keys(options).length <= 0) {
const answers = await interact([
{text: '请输入文章主题', value: title},
{text: '请输入最小字数', value: 6000},
{text: '请输入最大字数', value: 10000},
]);
title = answers[0];
options.min = answers[1];
options.max = answers[2];
}
const article = generate(title, {corpus, ...options});
const output = saveCorpus(title, article);
console.log(`生成成功!文章保存于:${output}`);
}());
用 process.stdin 实现命令行交互,需要在 readable 事件中多调一次 process.stdin.read() 方法,这看起来很奇怪,而且代码的可读性不高。
Node.js 为我们提供了一个比 process.stdin 更好用的内置模块 —— readline,它是专门用来实现可交互命令行的:
// interact.js
import readline from 'readline';
// 我们每次输出一个提问并等待用户输入答案,所以将它封装成一个返回 Promise 的异步方法
function question(rl, {text, value}) {
const q = `${text}(${value})\n`;
return new Promise((resolve) => {
rl.question(q, (answer) => {
resolve(answer || value);
});
});
}
// readline.createInterface 返回的对象有一个 question 方法,它是个异步方法
// 接受一个问题描述和一个回调函数 —— 用于接受用户的输入
export async function interact(questions) {
const rl = readline.createInterface({ // 创建一个可交互的命令行对象
input: process.stdin,
output: process.stdout,
});
const answers = [];
for(let i = 0; i < questions.length; i++) {
const q = questions[i];
const answer = await question(rl, q); // 等待问题的输入
answers.push(answer);
}
rl.close();
return answers;
}
readline 模块是用来实现交互式命令行的,对于编写需要在终端与用户交互的 JavaScript 应用有很大帮助。
至此我们就实现了用户互动的方式完成文章生成器:

废话版ChatGPT网页版
到这里为止,我们已经实现了一个完整的命令行版本的文章生成器,但还可以做得更好,把它变成一个网页版的发布文章生成器,这样就可以在浏览器中直接使用了。
我们在这个项目使用了 ES Modules,使用这个新的规范有一个好处,就是理论上我们可以直接在浏览器中加载并使用同样的模块。
我们这里如果不考虑兼容性,直接将type="module"写在script上,然后把前面的模块直接 import 进来。我们在根目录创建index.html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>ShitGPT</title>
<style>
header {
height: 120px;
border-bottom: solid 1px #777;
}
.options {
float: right;
display: flex;
flex-direction: column;
}
.options div {
width: 300px;
}
#title {
font-size: 1.5rem;
}
.title {
clear: both;
line-height: 60px;
text-align: center;
font-size: 1.5rem;
padding-top: 12px;
}
.title input {
outline: none;
border: none;
border-bottom: solid 1px black;
text-align: center;
width: 45%;
max-width: 600px;
}
.options input {
margin-right: 10px;
}
.title button {
font-size: 1.5rem;
margin-left: 10px;
border: none;
background: #444;
color: #eee;
}
main {
padding-bottom: 40px;
}
section {
text-indent: 3rem;
padding: 10px;
}
footer {
position: fixed;
width: 100%;
bottom: 0;
background-color: white;
}
@media screen and (max-width: 480px) {
.title span {display: none;}
#title {font-size: 1.2rem;}
.title button {
font-size: 1.2rem;
}
section {text-indent: 2.4rem;}
}
</style>
</head>
<body>
<header>
<div class="options">
<div>最小字数:<input id="min" type="range" min="500" max="5000" step="100" value="2000"><span>2000</span></div>
<div>最大字数:<input id="max" type="range" min="1000" max="10000" step="100" value="5000"><span>5000</span></div>
</div>
<div class="title"><span>文章标题:</span><input id="title" type="text" value="">
<button id="generate">来一篇</button>
<button id="anotherTitle">不满意?换一篇</button>
</div>
</header>
<main>
<article></article>
</main>
<script type="module">
import {generate} from './lib/generator.js';
import {createRandomPicker} from './lib/random.js';
const options = document.querySelector('.options');
const config = {min: 2000, max: 5000};
options.addEventListener('change', ({target}) => {
const num = Number(target.value);
config[target.id] = num;
target.parentNode.querySelector('input + span').innerHTML = num;
});
const generateButton = document.getElementById('generate');
const anotherTitleButton = document.getElementById('anotherTitle');
const article = document.querySelector('article');
const titleEl = document.getElementById('title');
(async function () {
const corpus = await (await fetch('./corpus/data.json')).json();
const pickTitle = createRandomPicker(corpus.title);
titleEl.value = pickTitle();
generateButton.addEventListener('click', () => {
const text = generate(titleEl.value, {corpus, ...config});
article.innerHTML = `<section>${text.join('</section><section>')}</section>`;
});
anotherTitleButton.addEventListener('click', () => {
titleEl.value = pickTitle();
if(article.innerHTML) generateButton.click();
});
}());
</script>
</body>
</html>
上面的代码要以模块的方式加载到浏览器中,可能会带来两个问题:
- 一个是如果浏览器版本比较老,不支持 ES Module,就不能正常运行代码;
- 另一个是 ES Module 加载方式会增加 HTTP 请求数量,会影响网页的加载速度。
为了解决上述问题,我们可以将代码打包成一个单独的包 ,来直接用默认的方式加载。
可以使用的打包工具有很多种,比如流行的 Webpack、Rollup 和 Esbuild 等等。
我们选择 Esbuild 来打包,先安装:npm install esbuild --save-dev
我们需要在根目录创建一个 build.js 文件来进行打包配置:
import {build} from 'esbuild';
const buildOptions = {
entryPoints: ['./browser/index.js'],
outfile: './dist/index.js',
bundle: true,
minify: true,
};
build(buildOptions);
然后我们创建 browser/index.js 文件:
import {generate} from '../lib/generator.js';
import {createRandomPicker} from '../lib/random.js';
const defaultCorpus = require('../corpus/data.json');
async function loadCorpus(corpuspath) {
if(corpuspath) {
const corpus = await (await fetch(corpuspath)).json();
return corpus;
}
return defaultCorpus;
}
export {generate, createRandomPicker, loadCorpus};
接着我们修改项目的 package.json 文件,添加:
"scripts": {
"start": "http-server -c-1 -p3000",
"build": "node build.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
运行 npm run build,就可以编译生成 dist/index.js 文件,这就是打包后的文件
我们运行 npm run start,可以看到http-server已经启动了

我们打开浏览器,输入http://127.0.0.1:3000/就可以看到:

到此为止,我们的废话版ChatGPT就全部完成了!