python 基础
- 变量
- 函数
- 函数定义
- 函数参数说明
- 匿名函数 lambda
- 文件
- 文件编码
- 文件读取
- 文件写入
- 异常
- try
- Exception
- else
- finally
- 异常的传递
- 模块
- 模块导入
- 自定义python包并导入
- 第三方包的导入
- JSON
变量
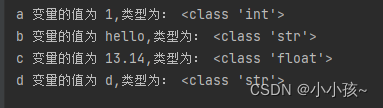
python 中变量的定义不需要指定变量的类型,直接进行定义,系统会根据设置的变量内容自动获取改变量的数据类型:
a=1
b='hello'
c=13.14
d='d'
print(f'a 变量的值为 {a},类型为:',type(a))
# 其中 f 表示输出的内容中存在格式化的输出数据
print(f'b 变量的值为 {b},类型为:',type(b))
print(f'c 变量的值为 {c},类型为:',type(c))
print(f'd 变量的值为 {d},类型为:',type(d))
运行结果:
函数
函数定义
在 python 程序中定义一个函数的基本格式为:
def 函数名(参数1,参数2,...):
函数体
return 返回值信息
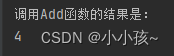
例如,我们需要实现一个 加法函数:
def Add(x,y):
return x+y
print("调用Add函数的结果是:")
# 调用函数: 函数名(参数列表)
print(Add(1,3))
运行结果:
函数参数说明
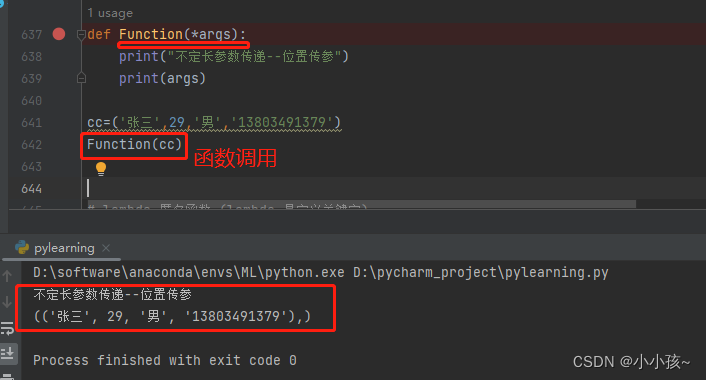
若定义一个函数,函数的形参个数不确定,则可以传入不定长度的形参:
1:位置传递不定长:按照位置信息传入参数列表
# 默认 args 为元组类型
def function(*args):
***********
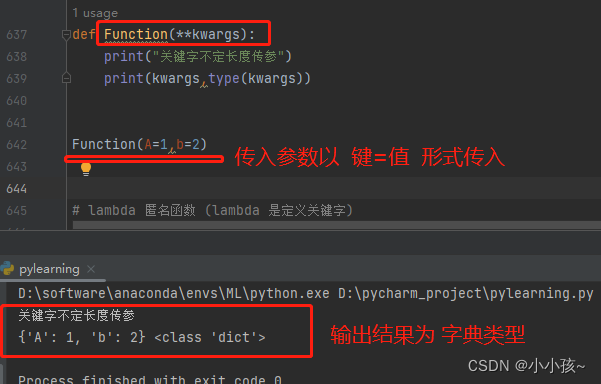
2:关键字传递不定长:
# 默认 kwargs 以字典形式存储,函数实参传递时候必须是 键=值 形式传入
def function(**kwargs):
*********
当一个函数作为参数进行传递
函数作为参数传递------传递的是函数的执行逻辑
def Add(x,y):
return x+y
def S(Add):
result=Add(1,2)
return result
print(S(Add))
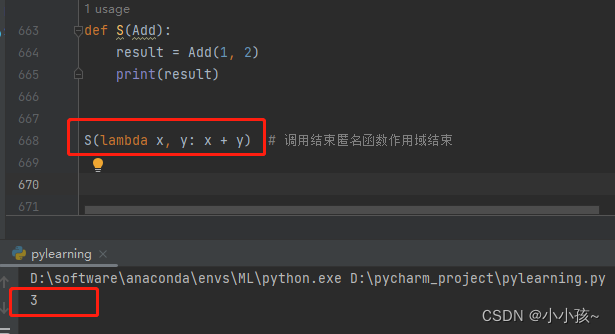
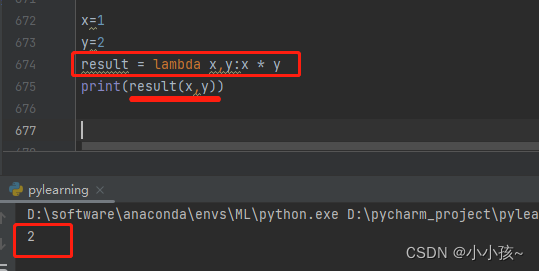
匿名函数 lambda
lambda 传入参数:函数体(一行代码)
result = lambda[arg1[,arg2,…,argn]]:expression
定义匿名函数要求必须使用关键字 lambda ,并且匿名函数的函数体只有一行
文件
文件编码
计算机中可用编码:UTF-8 (默认使用)\ GBK \ Big5 (中文繁体)
文件读取
打开文件 open
首先需要打开文件,才能对文件内容进行相应的操作:
打开文件 : open(文件地址,打开方式,编码格式)
f=open(name,mode,encoding)
# name 文件名,mode 打开方式 (r 只读, w 清空写入文件不存在创建 ,a 追加写文件不存在创建),encoding 编码格式 utf-8
读取文件 read
文件对象.read(num) :从文件中读取 num 字节长度内容,num 默认为读取文件全部内容
文件对象.readlines() :读取文件中全部行信息,并放入列表中
文件对象.readline() 方法:一次读取一行内容
关闭文件 close
f.close()
执行完语句块之后自动关闭文件
with open(name,mode,encoding) as f:
操作***********
练习:
# 循环读取文件
for line in f: # 循环读取文件的每一行信息并进行输出
print(f'每一行数据是:{line}')
# 统计某个文件中 itheima 出现的次数
# 方法一:
f=open(name,'r',encodint='UTF-8')
content=f.read() #读取文件全部内容
count=content.count('itheima') # 使用 count 方法进行统计
print('itheima 在文件中出现了 {count} 次')
# 方法二:
count=0;
for line in f:
line=line.strip() # 去除每一行之后的换行符-------输出结果为列表
words=line.split(" ") # 按照空格将读取到的信息划分
for word in words: # 遍历每一个单词来进行统计
if word=='itheima':
count+=1
print('itheima 在文件中出现了 {count} 次')
文件写入
w 清空式写入,文件不存在会创建
f=open(name,'w',encoding='UTF-8') # 定义第二个参数为 w
f.write('要写入文件的内容')
f.flush() # 内容刷新 ,将内存中堆积的内容写入到硬盘中
f.close() # 关闭文件其实内置了刷新功能
a 追加写入,文件不存在会创建
f=open(name,'a',encoding='UTF-8') # 定义第二个参数为 a
f.write('要写入文件的内容')
f.flush()
f.close()
异常
try
1、异常捕获
try:
可能发生异常的内容
except:
捕获到异常应该进行的操作
2、捕获指定的异常
try:
可能发生异常的内容
except (异常名1,异常名2,...) as e:
捕获到异常应该进行的操作
Exception
3、捕获所有异常
try:
except Exception as e:
print(e)
else
try:
可能发生异常的内容
except:
发生异常之后执行该部分代码
else:
未发生异常时候会执行
finally
不论是否捕获到异常都会执行 finally 语句部分
try:
可能发生异常的内容
except:
发生异常之后执行该部分代码
else:
未发生异常时候会执行
finally:
不论是否出现异常都会执行 finally 语句
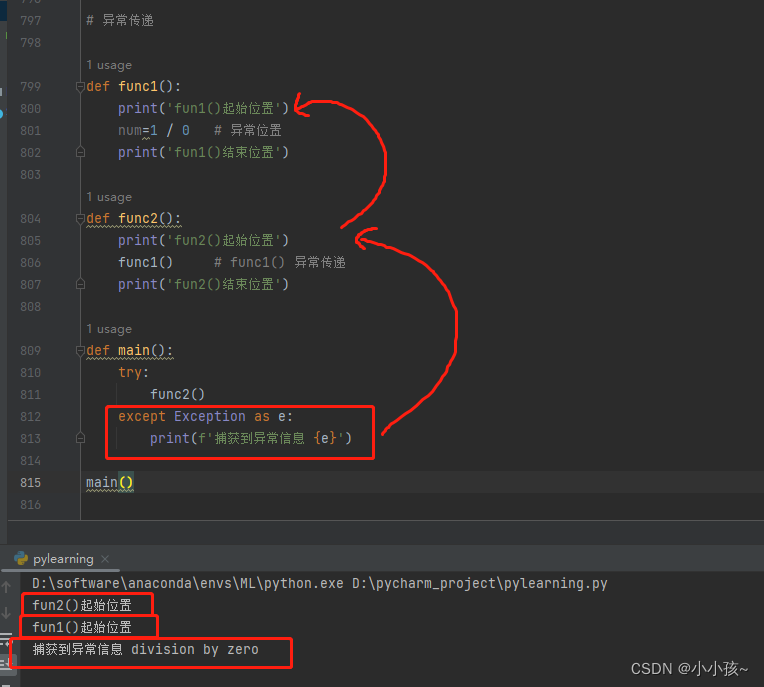
异常的传递
def func1():
print('fun1()起始位置')
num=1 / 0 # 异常位置
print('fun1()结束位置')
def func2():
print('fun2()起始位置')
func1() # func1() 异常传递
print('fun2()结束位置')
def main():
try:
func2()
except Exception as e:
print(f'捕获到异常信息 {e}')
模块
模块导入
自定义模块
定义一个模块时间上是定义一个 .py 文件,并在文件内部编写相应的功能(函数,变量…)
import 导入的包名 --------- 表示将包中所有内容导入
from 包名 import 函数/方法 ------- 表示从一个包中导入指定的函数/方法
# _main__ 变量:
# 表示只有当程序是直接执行的才会进入 if 语句,若是被导入的则不会进入 if 语句
if __name__ == '__main__':
*************
# 注意:
# 不同模块中同名的功能若都被导入同一文件,则后导入的会覆盖前边导入的同名功能
# __all__ 变量:
from 包名 import * # 表示导入所有内容
# __all__ 变量控制导入包的范围 ------- 控制 import*
# __all__ = [''] 列表形式设置
自定义python包并导入
在 pycharm 中依次执行:
file -> new -> python package 创建一个python包,内部自动包含一个 _init_.py 文件(若删除该文件,则不能表示 python 包,而只是一个普通的 python 文件),说明创建包成功; 然后新建 python file 来定义模块;
第三方包的导入
import 包名 ------ 导入包中所有内容
例如,
我们常用的数字计算包 numpy-----------import numpy
as 为导入的包取别名
加入我们所需要的包名特别长,那么在每一次调用包信息时候都需要加上包名称会非常繁琐,此时可以使用 as 对包取别名:
import numpy as np
from 包名 import 某方法/模块
例如,
从绘图工具 pyecharts.options 包中导入 TitleOpts 模块:
from pyecharts.options import TitleOpts
JSON
JSON 一种轻量级的数据交互格式本质上是一个带有特定格式的 ”字符串“
导入 JSON 模块 import json
将 python 数据转化为 json 数据 : data=json.dumps(data)
将 json 数据转化为 python 数据: data=json.loads(data)
ps:
每天学习一点点,进步一点点~~