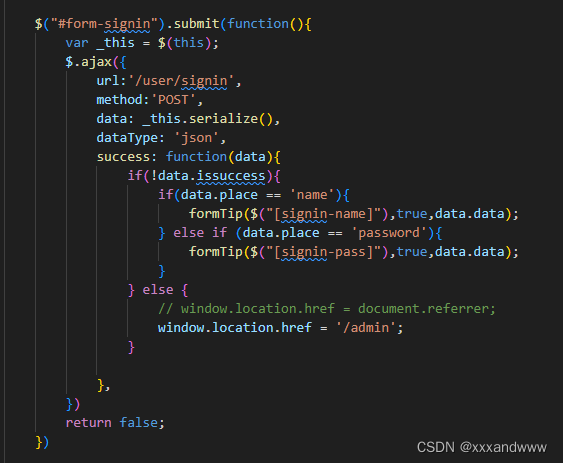
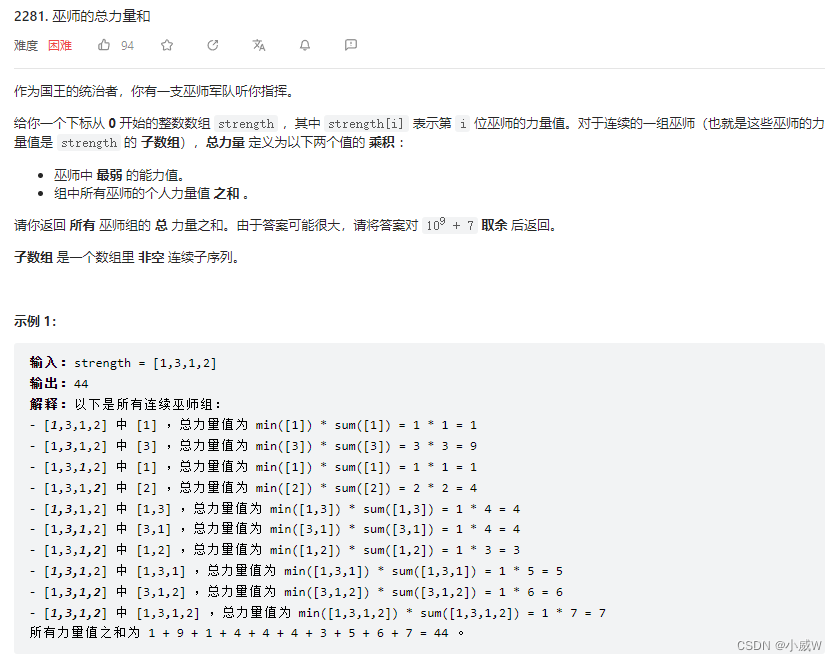
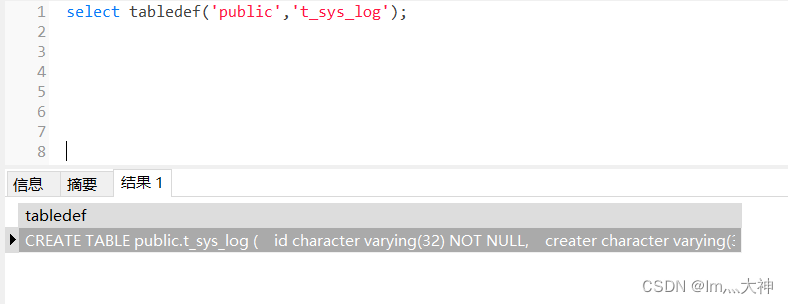
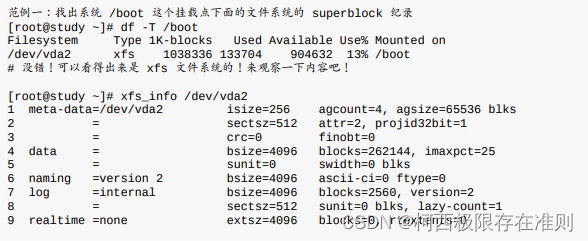
CUDA缓存包括L1缓存和L2缓存。
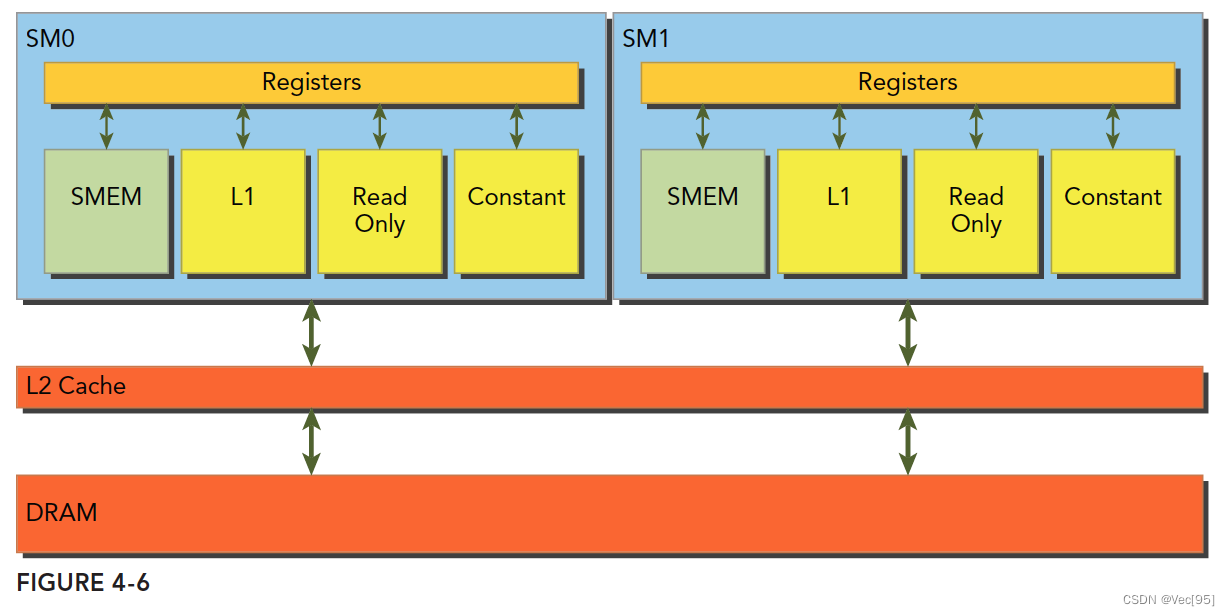
SM加载数据,根据不同的设备和类型分为三种路径:
- 一级和二级缓存
- 常量缓存
- 只读缓存
常规的路径是一级和二级缓存,需要使用常量和只读缓存的需要在代码中显式声明。但是提高性能,主要还是要取决于访问模式。
控制全局加载操作是否通过一级缓存可以通过编译选项来控制,当然比较老的设备可能就没有一级缓存。
编译器禁用一级缓存的选项是:
1
| -Xptxas -dlcm=cg
|
编译器启用一级缓存的选项是:
1
| -Xptxas -dlcm=ca
|
当一级缓存被禁用的时候,对全局内存的加载请求直接进入二级缓存,如果二级缓存缺失,则由DRAM完成请求。
每次内存事务可由一个两个或者四个部分执行,每个部分有32个字节,也就是32,64或者128字节一次(注意前面我们讲到是否使用一级缓存决定了读取粒度是128还是32字节,这里增加的64并不在此情况,所以需要注意)。
启用一级缓存后,当SM有全局加载请求会首先通过尝试一级缓存,如果一级缓存缺失,则尝试二级缓存,如果二级缓存也没有,那么直接DRAM。
在有些设备上一级缓存不用来缓存全局内存访问,而是只用来存储寄存器溢出的本地数据,比如Kepler 的K10,K20。
内存加载可以分为两类:
- 缓存加载
- 没有缓存的加载
内存访问有以下特点:
- 是否使用缓存:一级缓存是否介入加载过程
- 对齐与非对齐的:如果访问的第一个地址是32的倍数(前面说是32或者128的偶数倍,这里似乎产生了矛盾,为什么我现在也很迷惑)
- 合并与非合并,访问连续数据块则是合并的
缓存加载
下面是使用一级缓存的加载过程,图片表达很清楚,我们只用少量文字进行说明:
-
对齐合并的访问,利用率100%

-
对齐的,但是不是连续的,每个线程访问的数据都在一个块内,但是位置是交叉的,利用率100%

-
连续非对齐的,线程束请求一个连续的非对齐的,32个4字节数据,那么会出现,数据横跨两个块,但是没有对齐,当启用一级缓存的时候,就要两个128字节的事务来完成

-
线程束所有线程请求同一个地址,那么肯定落在一个缓存行范围(缓存行的概念没提到过,就是主存上一个可以被一次读到缓存中的一段数据。),那么如果按照请求的是4字节数据来说,使用一级缓存的利用率是 4128=3.125%4128=3.125%

-
比较坏的情况,前面提到过最坏的,就是每个线程束内的线程请求的都是不同的缓存行内,这里比较坏的情况就是,所有数据分布在 NN 个缓存行上,其中 1≤N≤321≤N≤32,那么请求32个4字节的数据,就需要 NN 个事务来完成,利用率也是 1N1N

CPU和GPU的一级缓存有显著的差异,GPU的一级缓存可以通过编译选项等控制,CPU不可以,而且CPU的一级缓存是的替换算法是有使用频率和时间局部性的,GPU则没有。
没有缓存的加载
没有缓存的加载是指的没有通过一级缓存,二级缓存则是不得不经过的。
当不使用一级缓存的时候,内存事务的粒度变为32字节,更细粒度的好处是提高利用律,这个很好理解,比如你每次喝水只能选择一瓶大瓶500ml的或则一个小瓶的250ml,当你非常渴的时候需要400ml水分,喝大瓶的,比较方便,因为如果喝小瓶的一瓶不够,还需要再喝一瓶,此时大瓶的方便.但如果你需要200ml的水分的时候,小瓶的利用率就高很多。细粒度的访问就是用小瓶喝水,虽然体积小,但是每次的利用率都高了不少,针对上面使用缓存的情况5,可能效果会更好。
继续我们的图解:
- 对齐合并访问128字节,不用说,还是最理想的情况,使用4个段,利用率 100%100%
-
对齐不连续访问128字节,都在四个段内,且互不相同,这样的利用率也是 100%100%

-
连续不对齐,一个段32字节,所以,一个连续的128字节的请求,即使不对齐,最多也不会超过五个段,所以利用率是 45=80%45=80% ,如果不明白为啥不能超过5个段,请注意前提是连续的,这个时候不可能超过五段

-
所有线程访问一个4字节的数据,那么此时的利用率是 432=12.5%432=12.5%

-
最欢的情况,所有目标数据分散在内存的各个角落,那么需要 N个内存段, 此时与使用一级缓存的作比较也是有优势的因为 N×128N×128 还是要比 N×32N×32 大不少,这里假设 NN 不会因为 128128 还是 3232 而变的,而实际情况,当使用大粒度的缓存行的时候, NN 有可能会减小

只读缓存
只读缓存最初是留给纹理内存加载用的,在3.5以上的设备,只读缓存也支持使用全局内存加载代替一级缓存。也就是说3.5以后的设备,可以通过只读缓存从全局内存中读数据了。
只读缓存粒度32字节,对于分散读取,细粒度优于一级缓存
有两种方法指导内存从只读缓存读取: - 使用函数 _ldg
- 在间接引用的指针上使用修饰符
-
全局内存写入
内存的写入和读取(或者叫做加载)是完全不同的,并且写入相对简单很多。一级缓存不能用在 Fermi 和 Kepler GPU上进行存储操作,发送到设备前,只经过二级缓存,存储操作在32个字节的粒度上执行,内存事物也被分为一段两端或者四段,如果两个地址在一个128字节的段内但不在64字节范围内,则会产生一个四段的事务,其他情况以此类推。
我们将内存写入也参考前面的加载分为下面这些情况:
-
对齐的,访问一个连续的128字节范围。存储操作使用一个4段事务完成:
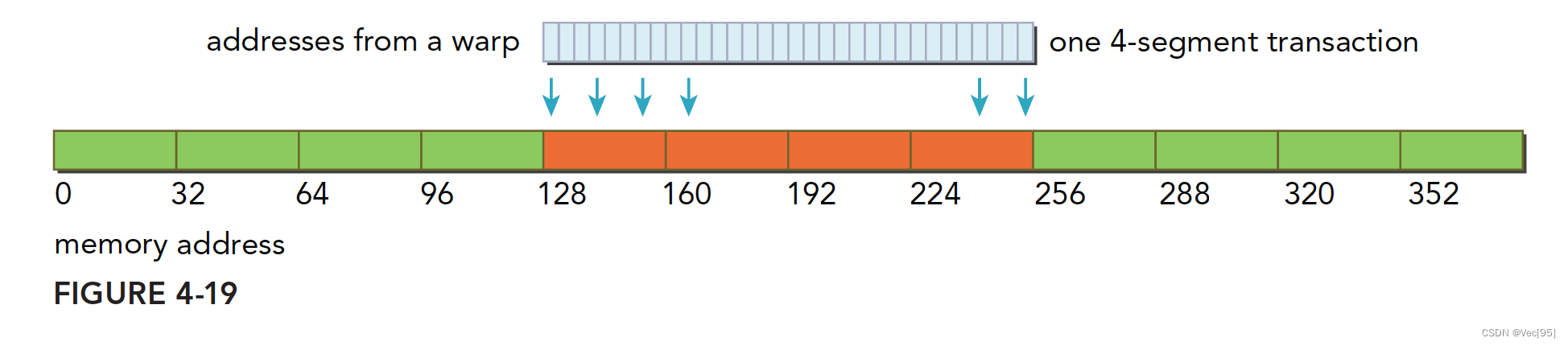
-
分散在一个192字节的范围内,不连续,使用3个一段事务来搞定
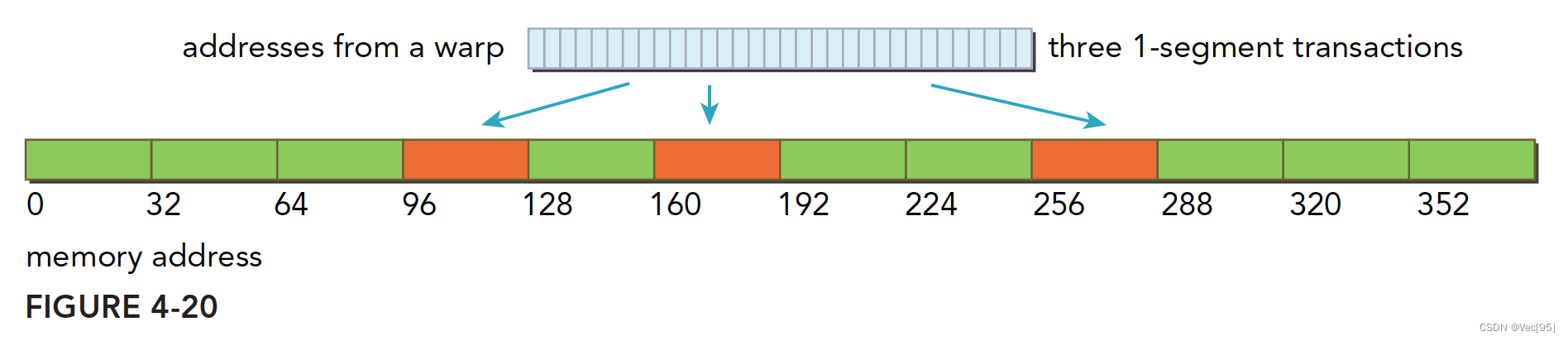
-
对齐的,在一个64字节的范围内,使用一个两段事务完成。
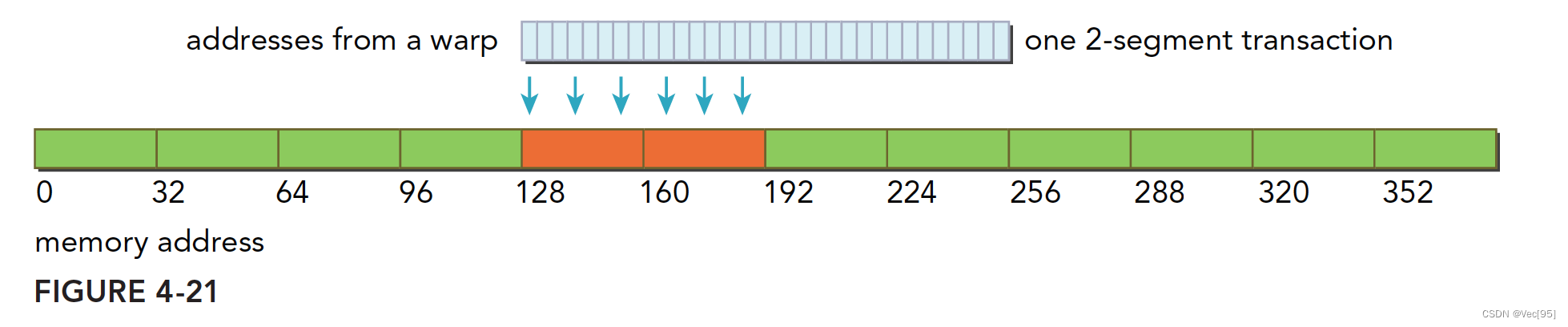
全局内存是一个逻辑层面的模型,我们编程的时候有两种模型考虑:一种是逻辑层面的,也就是我们在写程序的时候(包括串行程序和并行程序),写的一维(多维)数组,结构体,定义的变量,这些都是在逻辑层面的;一种是硬件角度,就是一块DRAM上的电信号,以及最底层内存驱动代码所完成数字信号的处理。
L1表示一级缓存,每个SM都有自己L1,但是L2是所有SM公用的,除了L1缓存外,还有只读缓存和常量缓存,这个我们后面会详细介绍。
核函数运行时需要从全局内存(DRAM)中读取数据,只有两种粒度,这个是关键的:
- 128字节
- 32字节
解释下“粒度”,可以理解为最小单位,也就是核函数运行时每次读内存,哪怕是读一个字节的变量,也要读128字节,或者32字节,而具体是到底是32还是128还是要看访问方式:
- 使用一级缓存
- 不使用一级缓存
对于CPU来说,一级缓存或者二级缓存是不能被编程的,但是CUDA是支持通过编译指令停用一级缓存的。如果启用一级缓存,那么每次从DRAM上加载数据的粒度是128字节,如果不适用一级缓存,只是用二级缓存,那么粒度是32字节。
还要强调一下CUDA内存模型的内存读写,我们现在讨论的都是单个SM上的情况,多个SM只是下面我们描述的情形的复制:SM执行的基础是线程束,也就是说,当一个SM中正在被执行的某个线程需要访问内存,那么,和它同线程束的其他31个线程也要访问内存,这个基础就表示,即使每个线程只访问一个字节,那么在执行的时候,只要有内存请求,至少是32个字节,所以不使用一级缓存的内存加载,一次粒度是32字节而不是更小。
在优化内存的时候,我们要最关注的是以下两个特性:
- 对齐内存访问
- 合并内存访问
我们把一次内存请求——也就是从内核函数发起请求,到硬件响应返回数据这个过程称为一个内存事务(加载和存储都行)。
当一个内存事务的首个访问地址是缓存粒度(32或128字节)的偶数倍的时候:比如二级缓存32字节的偶数倍64,128字节的偶数倍256的时候,这个时候被称为对齐内存访问,非对齐访问就是除上述的其他情况,非对齐的内存访问会造成带宽浪费。
当一个线程束内的线程访问的内存都在一个内存块里的时候,就会出现合并访问。
对齐合并访问的状态是理想化的,也是最高速的访问方式,当线程束内的所有线程访问的数据在一个内存块,并且数据是从内存块的首地址开始被需要的,那么对齐合并访问出现了。为了最大化全局内存访问的理想状态,尽量将线程束访问内存组织成对齐合并的方式,这样的效率是最高的。下面看一个例子。
- 一个线程束加载数据,使用一级缓存,并且这个事务所请求的所有数据在一个128字节的对齐的地址段上(对齐的地址段是我自己发明的名字,就是首地址是粒度的偶数倍,那么上面这句话的意思是,所有请求的数据在某个首地址是粒度偶数倍的后128个字节里),具体形式如下图,这里请求的数据是连续的,其实可以不连续,但是不要越界就好。
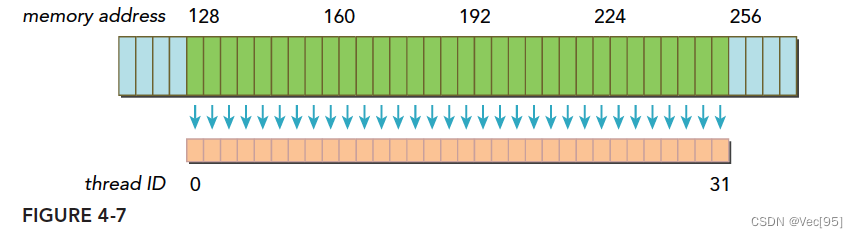
上面蓝色表示全局内存,下面橙色是线程束要的数据,绿色就是我称为对齐的地址段。- 如果一个事务加载的数据分布在不一个对齐的地址段上,就会有以下两种情况:
- 连续的,但是不在一个对齐的段上,比如,请求访问的数据分布在内存地址1~128,那么0~127和128~255这两段数据要传递两次到SM
- 不连续的,也不在一个对齐的段上,比如,请求访问的数据分布在内存地址0~63和128~191上,明显这也需要两次加载。

- 上图就是典型的一个线程束,数据分散开了,thread0的请求在128之前,后面还有请求在256之后,所以需要三个内存事务,而利用率,也就是从主存取回来的数据被使用到的比例,只有 128128×3128128×3 的比例。这个比例低会造成带宽的浪费,最极端的表现,就是如果每个线程的请求都在不同的段,也就是一个128字节的事务只有1个字节是有用的,那么利用率只有 11281128
这里总结一下内存事务的优化关键:用最少的事务次数满足最多的内存请