目标检测算法之YOLOv6 (2)量化与部署详解
-
- 详解量化训练方式
-
- 详解部署方法:onnx 、openvnio、 tensorrt
-
- YLOLOv6目前发布的模型:从模型大小方面来看,可分为微小型(Nano),小(Small),中(Medium),大模型(Large);从用户使用场景方面来看,可分为基础版(base),进阶版(advance),高精版(high-precision)。
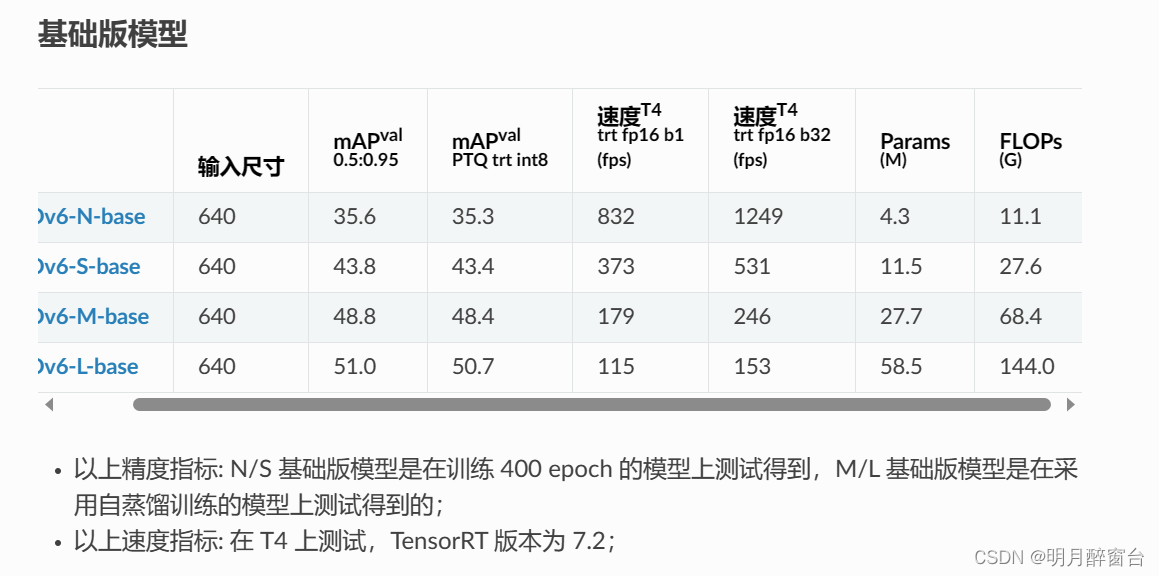
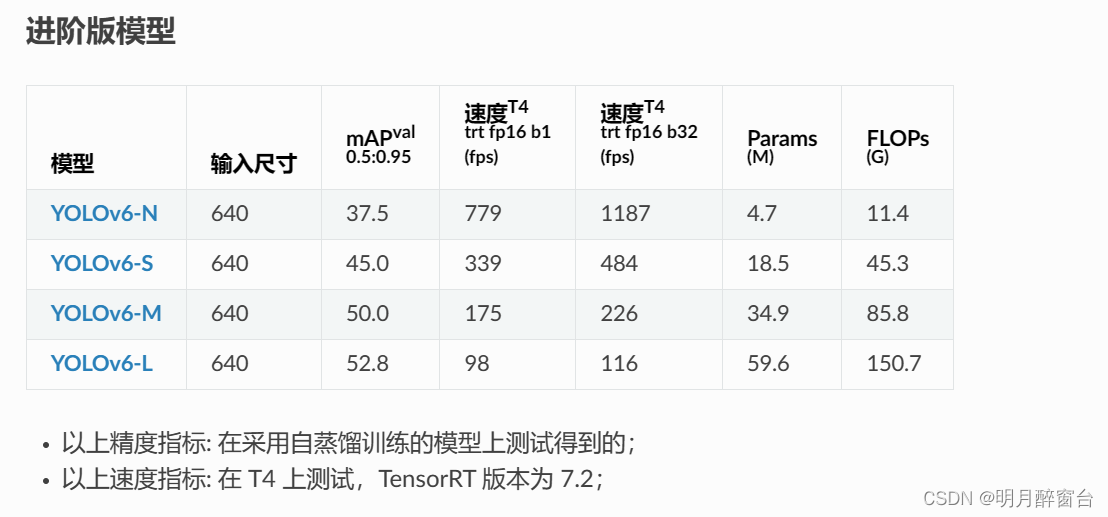
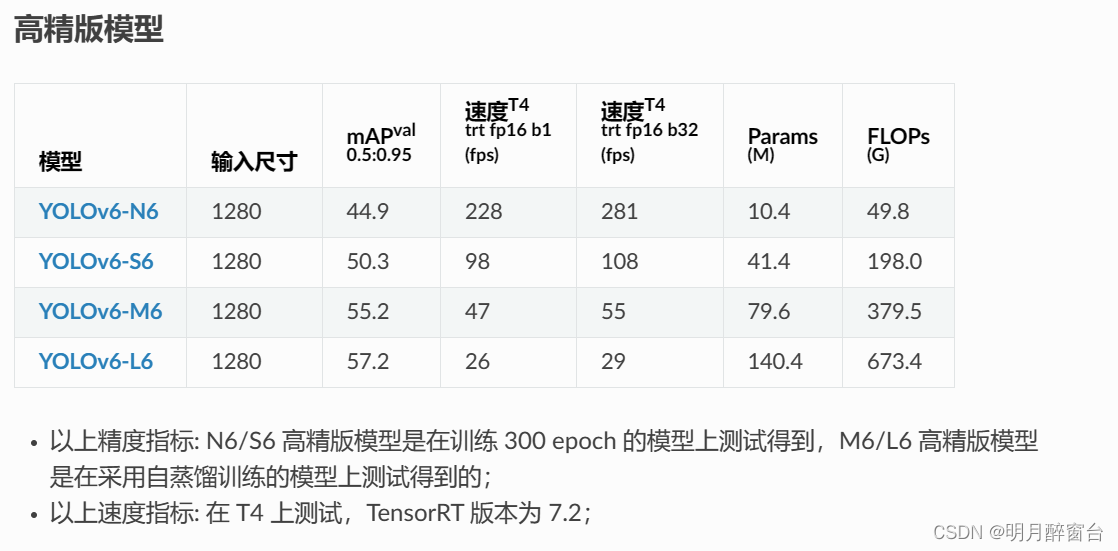
- YLOLOv6目前发布的模型:从模型大小方面来看,可分为微小型(Nano),小(Small),中(Medium),大模型(Large);从用户使用场景方面来看,可分为基础版(base),进阶版(advance),高精版(high-precision)。
1. 量化
- 对于量化新手同学,我们推荐选择基础版(base)模型,并直接采用 PTQ 的方式进行模型量化并部署。
1.1 基础版模型PTQ量化(推荐)
- 模型训练完成后,首先参考ONNX模型导出生成对应的ONNX模型,然后根据以下命令进行 PTQ生成 TRT 量化模型
python deploy/TensorRT/onnx_to_trt.py -m ./yolov6s_base.onnx \
-d int8 \
--batch-size 32 \
--num-calib-batch 4 \
--calib-img-dir ../coco/images/train2017/ \
--calib-cache ./yolov6s_base-int8-4x32.cache
1.2 进阶版RepOPT
进阶版模型大量采用重参数化结构,但在提升模型精度的同时,也为模型的量化带来了困难,该模型直接采用 PTQ 部署一般很难获得可接受的量化精度。为此,我们针对进阶版模型准备了一套基于 RepOPT 算法的量化流程。该方案需要首先采用 RepOPT 结构重新训练网络,然后再基于该网络预训练权重进行模型量化。该网络的部署模型结构与原网络基于 RepVGG 版本的 deploy 模型完全一致。
- RepOpt两阶段训练
- RepOptimizer给出了一种量化友好的重参数化网络训练范式。该方法采用优化器Optimizer的重参数化操作来代替结构的重参数化过程,从而保持网络结构在train和deploy阶段保持一致。该方法分为两个步骤: 步骤一: 超参数搜索(Hyper-Search)。该阶段通过训练LinearAddBlock获得超参数scale(通过 scale.pt 的形式存储),来初始化RepOPT结构的Optimizer。您可以直接使用我们所发布的超参数预训练模型,跳过该步骤;或者选择重新搜索获得自己的超参数scale
python tools/train.py --batch 32 --conf configs/repopt/yolov6s_hs.py --data data/coco.yaml --device 0
已发布的scale.pt见:yolov6n_scale.pt、yolov6t_scale.pt、yolov6s_scale.pt、yolov6m_scale.pt.
- 步骤二: 模型训练,载入上一步所得
scale.pt文件,config中配置flag training_mode='hyper_search',训练代码如下,获得预训练模型yolov6s_reopt.pt.
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 256 \
--conf configs/repopt/yolov6s_opt.py \
--data data/coco.yaml \
--epoch 300 \
--device 0,1,2,3,4,5,6,7 \
--name yolov6s_coco_repopt # yolov6l_coco
1.3 量化感知训练
- 对生产的RepOPT预训练模型进行QAT提升量化精度,该步骤依赖于
pytorch_quantization,请先参考教程安装。该过程需要首先通过calib过程获得一个calib.pt文件,然后传入第二步进行QAT训练. - 步骤一: 数据校准(Calibration)。
CUDA_VISIBLE_DEVICES=0 python tools/train.py \
--data ./data/coco.yaml \
--output-dir ./runs/opt_train_v6s_ptq \
--conf configs/repopt/yolov6s_opt_qat.py \
--quant \
--calib \
--batch 32 \
--workers 0
步骤二: 量化感知训练(QAT)。该过程结合了CWD蒸馏,加载calib.pt文件,训练10个epoch即可获得量化精度的提升,获得量化模型yolov6s_reopt_qat.pt。
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8 \
tools/train.py \
--data ./data/coco.yaml \
--output-dir ./runs/opt_train_v6s_qat \
--conf configs/repopt/yolov6s_opt_qat.py \
--quant \
--distill \
--distill_feat \
--batch 128 \
--epochs 10 \
--workers 32 \
--teacher_model_path ./assets/yolov6s_v2_reopt_43.1.pt \
--device 0,1,2,3,4,5,6,7
1.4 量化模型导出及转换
- 导入前两步所得pt模型,导出成ONNX模型。
python3 qat_export.py --weights yolov6s_reopt.pt --quant-weights yolov6s_reopt_qat.pt --graph-opt --export-batch-size 1
执行该步骤可以得到带QDQ算子的ONNX模型,和不带QDQ算子的ONNX模型及对应的cache文件(带_remove_qdq_后缀),然后在目标部署环境下使用trtexec工具来生成trt模型进行部署,例如:
trtexec --workspace=1024 --percentile=99 --streams=1 --onnx=***_remove_qdq.onnx --calib=***_remove_qdq_add_insert_
1.5 TRT模型精度测试
YOLOv6提供了TRT模型精度测试的脚本,使用如下:
python deploy/TensorRT/eval_yolo_trt.py \
--imgs-dir ../data/coco/images/val2017/ \
--annotations ../data/coco/annotations/instances_val2017.json \
-m ***_remove_qdq.trt
2. 部署
2.1 ONNX 模型导出
- 环境依赖
pip install onnx>=1.10.0
- 导出脚本
python ./deploy/ONNX/export_onnx.py \
--weights yolov6s.pt \
--img 640 \
--batch 1 \
--simplify
- Description of all arguments
--weights : yolov6 模型权重路径
--img : 模型输入图片尺寸,默认640
--batch : 模型输入的批大小
--half : 是否导出半精度(fp16)模型
--inplace : 是否需要设置Detect()类inplace为True
--simplify : 是否采用onnx-sim简化模型,端到端导出模型不支持简化
--end2end : 是否需要导出端到端的onnx模型,仅支持 onnxruntime 和 TensorRT >= 8.0.0
--trt-version : TensorRT 版本,支持7或8
--ort : 是否为 onnxruntime 后端导出模型
--with-preprocess : 是否需要预处理操作(bgr2rgb和归一化)
--topk-all : 保留每张图像的topK个目标
--iou-thres : NMS算法使用的IOU阈值
--conf-thres : NMS算法使用的置信度阈值
--device : 导出时用的环境设备,如显卡0或CPU
-
下载
- YOLOv6-N
- YOLOv6-S
- YOLOv6-M
- YOLOv6-L
-
端到端导出模型
- 现在 YOLOv6 支持 onnxruntime 和 TensorRT 的端到端检测!
- 如果你想在 TensorRT 中部署,请确保你已经安装了 TensorRT!
-
onnxruntime 后端
使用方式
python ./deploy/ONNX/export_onnx.py \
--weights yolov6s.pt \
--img 640 \
--batch 1 \
--end2end \
--ort
您将获得带有 NMS 操作的 onnx 模型。
- TensorRT 后端 (TensorRT version == 7.2.3.4)
使用方式
python ./deploy/ONNX/export_onnx.py \
--weights yolov6s.pt \
--img 640 \
--batch 1 \
--end2end \
--trt-version 7
您将获得带有 BatchedNMSDynamic_TRT 插件的 onnx 模型。
- TensorRT 后端 (TensorRT version>= 8.0.0)
使用方式
python ./deploy/ONNX/export_onnx.py \
--weights yolov6s.pt \
--img 640 \
--batch 1 \
--end2end \
--trt-version 8
您将获得带有 BatchedNMSDynamic_TRT 插件的 onnx 模型。
- 输出描述,onnx 输出如图所示:
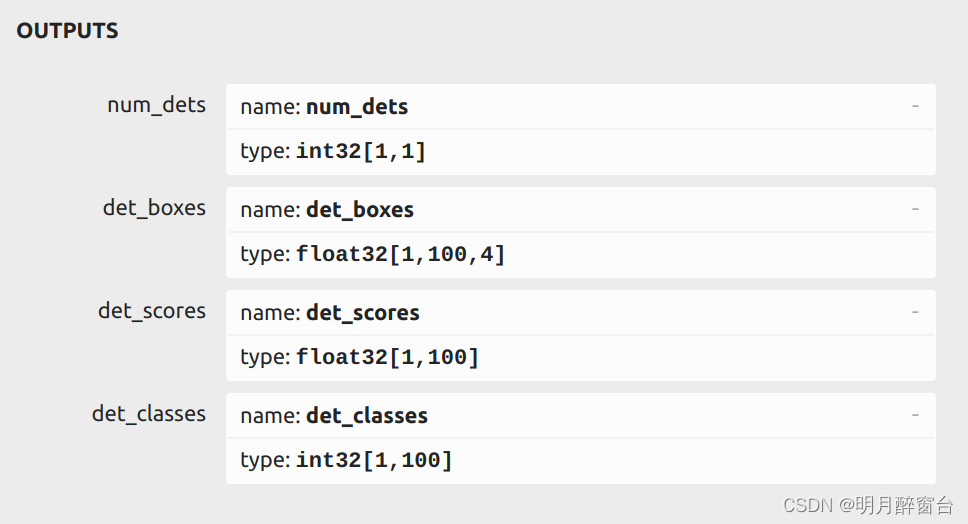
num_dets 表示其批次中每个图像中的目标数
det_boxes 表示 topk(100) 目标的坐标信息 [x0,y0,x1,y1] .
det_scores 表示每个 topk(100) 个对象的置信度分数
det_classes 表示每个 topk(100) 个对象的类别
您可以使用 trtexec 工具导出 TensorRT 引擎。
- 使用方式
trtexec --onnx=yolov6s.onnx \
--saveEngine=yolov6s.engine \
--workspace=8192 # 8GB
--fp16 # if export TensorRT fp16 model
- 评估 TensorRT 模型性能,当我们得到 TensorRT 模型后,我们可以通过以下方式评估其性能:
python deploy/ONNX/eval_trt.py --weights yolov6s.engine --batch-size=1 --data data/coco.yaml
-
动态批量推理,YOLOv6支持动态批量导出和推理,请参考以下教程:
-
export ONNX model with dynamic batch
-
export TensorRT model with dynamic batch
-
2.2 YOLOv6-TensorRT(C++)
- 环境依赖
TensorRT-8.2.3.0
OpenCV-4.1.0
- 第一步:获取onnx模型,按照指引 ONNX README 将 pt 模型转换为 onnx 模型
yolov6n.onnx.
python ./deploy/ONNX/export_onnx.py \
--weights yolov6n.pt \
--img 640 \
--batch 1
- 第二步:准备序列化引擎文件,按照指引 post training README 转换并保存序列化引擎文件
yolov6.engine.
python3 onnx_to_tensorrt.py --fp16 --int8 -v \
--max_calibration_size=${MAX_CALIBRATION_SIZE} \
--calibration-data=${CALIBRATION_DATA} \
--calibration-cache=${CACHE_FILENAME} \
--preprocess_func=${PREPROCESS_FUNC} \
--explicit-batch \
--onnx ${ONNX_MODEL} -o ${OUTPUT}
-
第三步:构建 demo,按照指引TensorRT Installation Guide 安装 TensorRT.
并且您应该在 CMakeLists.txt 中设置 TensorRT 路径和 CUDA 路径。 -
如果您训练自定义数据集,您可能需要修改
num_class、image width,image height和class name的值。
const int num_class = 80;
static const int INPUT_W = 640;
static const int INPUT_H = 640;
static const char* class_names[] = {
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
"potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
"hair drier", "toothbrush"
};
- 构建 demo:
mkdir build
cd build
cmake ..
make
- 运行 demo:
./yolov6 ../you.engine -i image_path
- 测试图像,您可以使用 .trt 权重对图像进行测试,只需提供图像目录的路径及其注释路径。
python3 deploy/TensorRT/eval_yolo_trt.py -v -m model.trt \
--imgs-dir /workdir/datasets/coco/images/val2017 \
--annotations /workdir/datasets/coco/annotations/instances_val2017.json \
--conf-thres 0.40 --iou-thres 0.45
2.3 OpenVINO 模型导出
- 环境依赖
pip install --upgrade pip
pip install openvino-dev
- 导出脚本
python deploy/OpenVINO/export_openvino.py --weights yolov6s.pt --img 640 --batch 1
- 速度测试
benchmark_app -m yolov6s_openvino/yolov6s.xml -i data/images/image1.jpg -d CPU -niter 100 -progress