0.啰嗦几句
最近公司又变动了,所以又做了一个关于视觉的项目。简单说就是栈板定位,主要应用在AGV叉车上,当然这一套流程基本适用于所有的视觉项目。主要是看算法的设计和一些人为的经验。
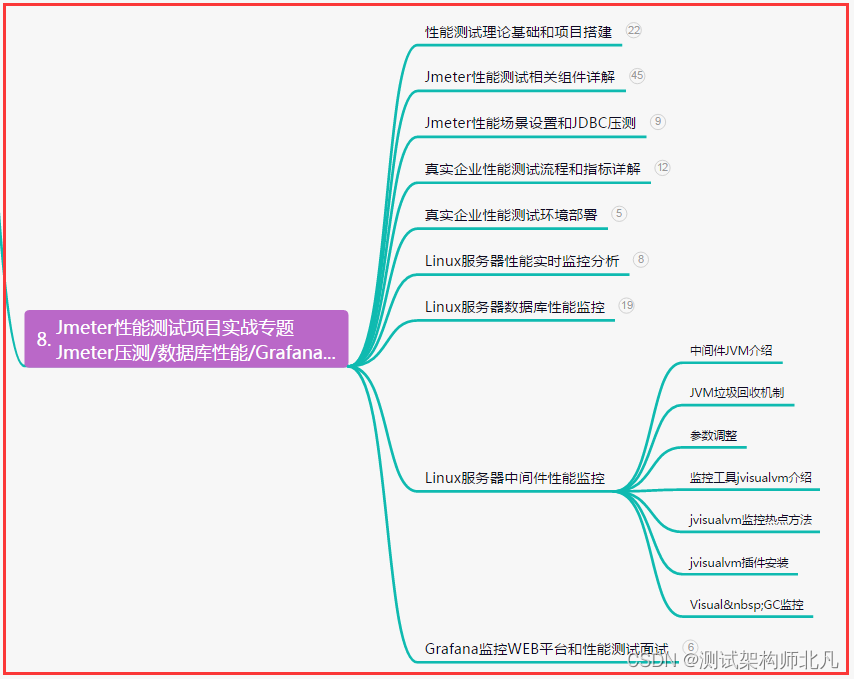
1.结果图
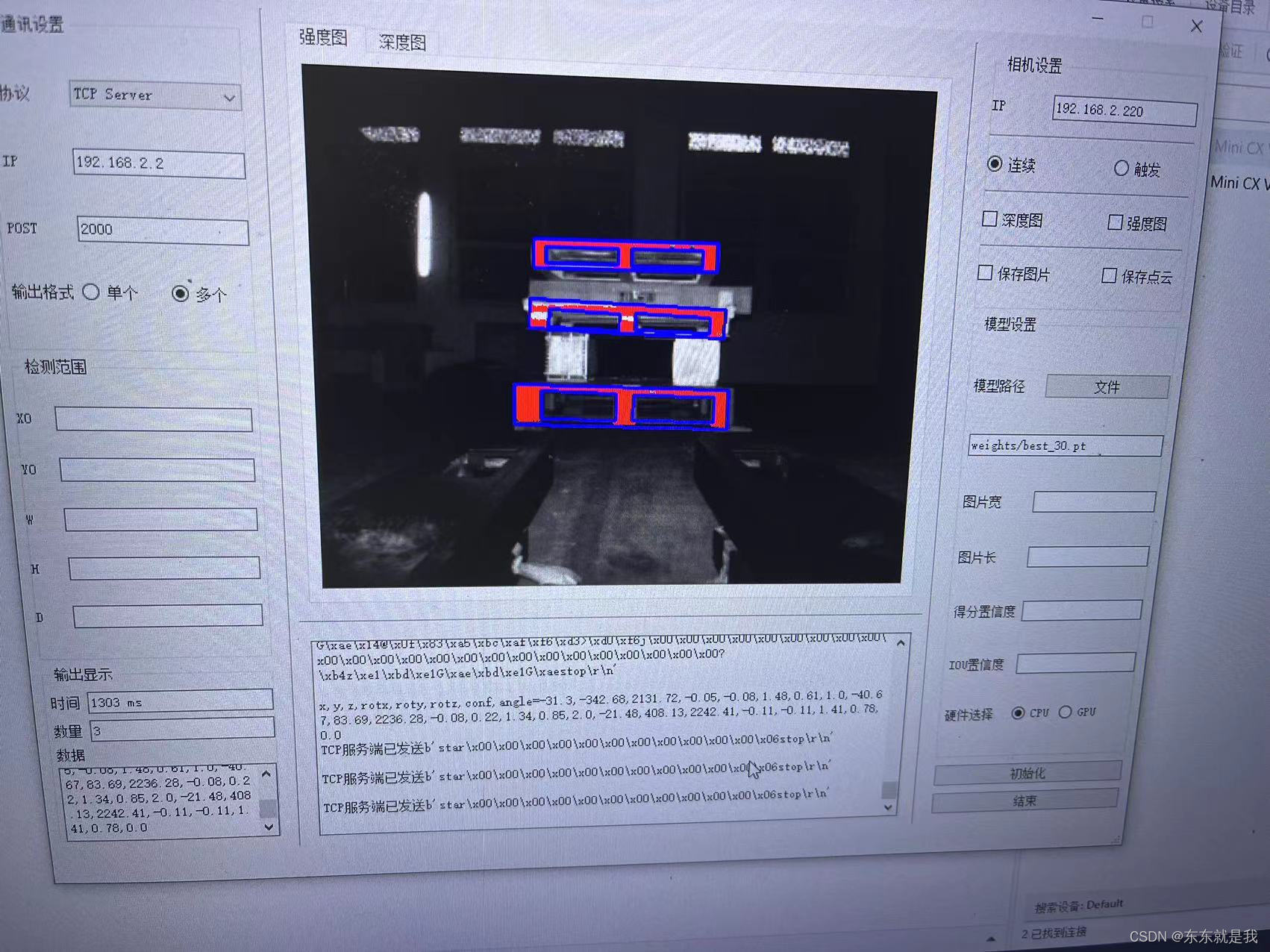

可以看到在图像上3个托盘都分割出来了,然后现在的数据是栈板中心点的x、y、z、含有栈板插取面的倾斜角rotx、栈板识别的时间、栈板识别的置信度、还有一个栈板水平的倾角
2.视觉项目的流程
2.1 取图
获取图像是最重要的一步,毕竟巧妇难为无米之炊。一个视觉的项目做的好不好或者能不能做,80%的原因就在于数据的获取。
这次的数据是是用了sick 的visionary-t mini 。这个相机可以获取2种数据,一个是强度图一个是深度图。深度图可以转为点云图。所以这就意味着我们可以使用3种数据去完成栈板的识别。那么选择哪一个?或者怎么组合才是最好用的呢。
经过我的猜测和测试,我使用的是强度图和深度图相与,然后经过4分位获取的图像数据去训练模型。
2.2 训练
训练这一步没啥好说的,首先根据项目的要求,(包括检测的时间、精度、部署的设备、后期的更新和维护等),找到对应的baseline。我这里就直接使用yolov7(因为yolov8的协议要求使用yolov8的代码要开源)。
2.3推理
其实我第一个版本使用的是paddle 的 fastdeploy推理框架。首先是真的简单,易安装易使用。但是模型更新后也是真的难改,而且再把训练好的模型转为onnx,然后再推理框架推理的时候,效果总是比pytorch原版差很多。期间我还使用了mmdetec的推理框架,在win下也是很难用。
最后还是老老实实的的用yolov7的源代码,就用pytorch。别整那么多幺蛾子了。
2.4 软件开发
软件开发的主线是,
AGV小车给触发信号,软件收到触发信号,然后获取相机的一帧数据,然后使用模型推理,获取数据中栈板的位置,再通过坐标转化,转为AGV小车的位置信息
重点:
1.和AGV小车通讯是把软件作为tcp server 。和相机通讯是把软件作为tcp client。
2.获取相机的图片数据并把数据展示在软件上要使用多线程。
3.相机坐标系下的数据要和AGV小车的坐标系做标定
其他还有一些软件的功能就不再介绍,总之把握好主线就行。
3.一些思考和一些问题
3.1数据
其实相机获取的数据是没办法直接训练的,不管是强度图还是深度图。要不就是数据的范围太大,比如强度图从0-200000。如果直接映射到0-255 势必导致很多信息丢失。要不就是数据相似没有边缘特征,比如深度图,栈板和物体在相机下基本一致。栈板和地板上的数据也基本一致。而且客户要求的检测范围1.5m到3m 。把1500 映射到0-255也是会导致很多信息丢失。
我现在的做法是
1.把深度图做一个过滤,把小于1500变成0 大于也3000的变成0
2.使用强度图和深度图相与。这样就过滤掉一部分强度数据
3.取强度图的4分位数据,原因是看数据的直方图
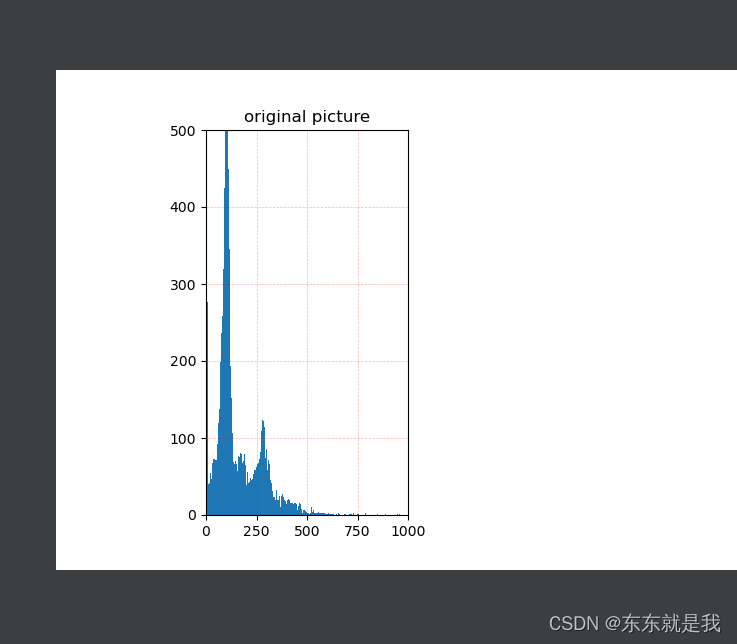
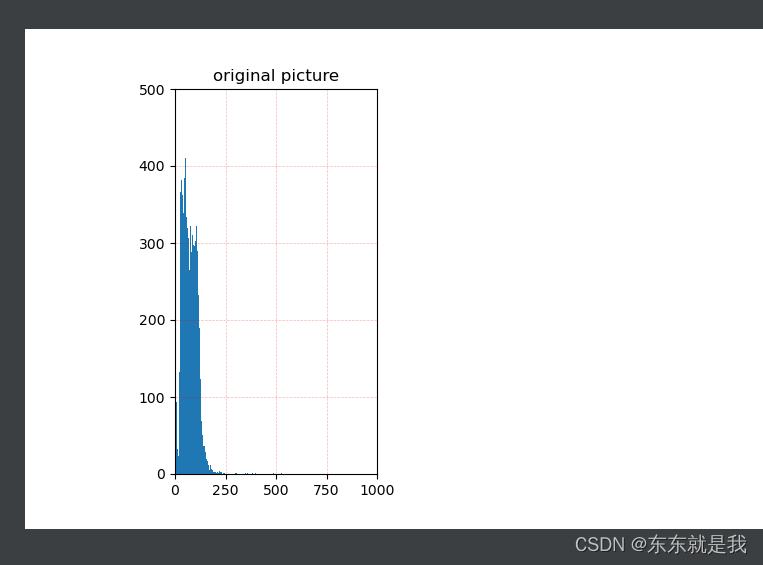
我们可以看到数据其实大部分在一个区间范围的,而且这个范围没有0-2000000那么大。大概可以看出来物体远一点就在0-255
物体近一点就在0-500左右。
所以我使用4分位获取 90%数据在那个范围。然后把数据裁剪到这个范围内再去做映射就会获得更好的效果。
最后在用一个直方图均衡保证图像的亮度均匀。
todo
这个还没有实际测试,所以在实验室效果还不错
3.2 结果
3.2.1 平面拟合
可以看到客户要求的结果还是挺多的,其中rotx是我们通过模型无法算出来的结果。
所以,我才用了平面拟合算法。获取栈板的平面法向量,然后用这个法向量作为栈板的倾斜角。
其中平面拟合算法,弄了好久。因为一开始使用的最小二乘法。这个算法有个优点就是快,但是缺点也很明显,对数据要求高。如果拟合平面的点是错误的,那么拟合的平面也是错误的。所以我们思考了好久怎么选取正确的点。后来发现怎么选择都是错的,因为这个算法就不适应。所以后面换成了使用RANSAC算法拟合平面。效果也是出奇的好。
3.2.2 直线拟合
客户还要栈板平面是否平整的判断,我只能说,虽然难,但是难不倒我。
我直接用模型推理的结果,然后做一个直线拟合,这样就可以把矩形框倾斜了。当然也获得了对应的倾斜角。

4.总结一下
对于视觉的项目,要多积极的思考。没有一个万能的模型。
我们可以通过数据,通过传统的机器视觉,通过统计学习。综合的思考才能完成项目
byd 数字图像处理(冈萨雷斯)真是太棒了