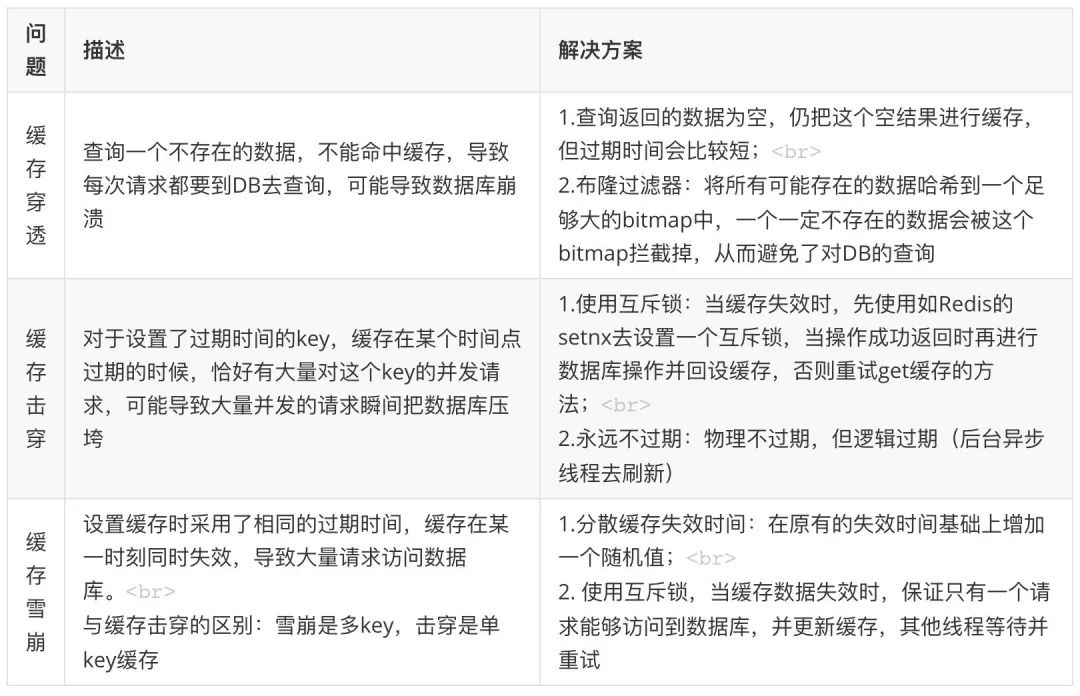
丨目录:
· 摘要
· 背景
· 方法
· 实验分析
· 总结
· 参考文献
1. 摘要
工业推荐系统通常拥有多个业务场景,并需要同时为这些场景提供推荐服务。在召回阶段,从大量商品库中选出的个高质量商品需要针对不同场景进行相应调整。以阿里妈妈展示广告为例,不同场景下的淘宝用户行为模式多种多样,同时广告主分配给不同场景的出价差异也较大。传统方法或是单独为每个场景训练模型,忽略了用户和商品的跨场景关联关系;或是简单地混合所有样本并维护一个共享模型,这使得模型很难捕获场景之间的显著差异。
在本文中,我们提出了自适应领域兴趣网络(Adaptive Domain Interest Network,简称ADIN),它能自适应地处理数据在不同场景下的共性和差异性,因此该网络能在训练过程中充分利用来自不同场景的大量数据。通过在线推理过程中为不同的场景提供不同的候选集,ADIN能够有效提高各个业务场景的在线效果。具体而言,我们提出的ADIN包含共享网络和场景私有网络,分别对不同场景数据的共性和差异性进行建模。此外,我们还使用场景感知的批归一化方法,并设计了用于特征级领域适配的领域兴趣自适应层。最后,ADIN还结合了自监督训练策略,以捕获跨场景的标签级关联关系。目前,ADIN已在阿里妈妈展示广告系统中全量上线,并获得了可观广告收入增长。
2. 背景
现代推荐/广告系统通常包含召回、粗排、精排、重排等多个阶段。在召回阶段,最重要的目标是从海量商品库中筛选出个高质量商品候选集并送入后续的排序模块[1]。而现代工业级推荐/广告系统通常会接入多个业务场景,来自不同业务场景的数据通常拥有一定的共性和差异性。就共性而言,不同业务场景通常在商品/用户上有一部分重叠;换言之,用户的兴趣和商品信息可以直接从一个场景迁移至另一个场景。就差异性而言,由于不同业务场景的用户行为,商品准入规则以及广告主的出价都不尽相同,导致不同场景的数据分布存在着一定的差异性。现有的解决方案通常可以分为三类:a)单独为每个场景学习不同的模型,这样做的缺点在于维护多条数据链路和模型需要耗费很多的人力和算力,同时模型无法学习到场景间的可迁移知识;b)混合不同场景的样本并训练一个共享模型,这种方案需要进行针对性的设计,否则不同场景的任务在训练时可能会发生冲突;c)混合不同场景的样本并以多任务学习结构训练一个统一的模型。虽然多场景学习和多任务学习在结构上相似,但是我们认为这两种任务还是存在一定区别:多场景学习输入的数据分布通常有较大的差异,但各场景的学习目标是一致的[2];多任务学习的输入通常一致,但是不同任务的学习目标不同[3]。
本文提出了一种自适应领域兴趣网络(ADIN)用于同时为多个场景的用户兴趣建模。首先,ADIN用一组共享网络和私有网络建模不同场景间的共性和差异性;其次,为了完成特征级别的领域自适应,我们实现了两种领域自适应方案:场景感知的批归一化和领域兴趣自适应层;最后,我们实现了一种自监督学习方案,以捕获标签级别的场景关联关系。本文主要成果:
我们提出了在召回侧用于解决多场景推荐任务的网络结构ADIN,ADIN高效地建模不同场景间的共性和差异性,并最终为各个场景同时带来效果提升;
我们实现了两种领域自适应方案:场景感知的批归一化和领域兴趣自适应层,用于捕捉场景间的差异性;同时,我们实现了一种自监督学习策略,以捕获标签级别的场景关联关系;
我们在工业界和学术界数据集上验证了ADIN的优越性,同时在阿里妈妈展示广告系统中部署了ADIN,获得了1.8%的广告收入增长。
3. 方法
3.1 骨干网络
图3-1展示了ADIN的整体架构图,流程遵从灰色箭头顺序。整体架构属于双塔结构,用户侧和商品侧的模型结构类似(在实际线上应用中,我们基于二向箔算法[4]提供的ANN检索能力,将最后一层的用户、商品相似度量函数从内积形式升级为了DNN网络,具体可参考《TDM到二向箔:阿里妈妈展示广告Match底层技术架构演进》)。首先特征会被送入领域兴趣自适应层,进行特征级别的领域自适应,不同场景的样本特征将被分配以不同大小的特征权重;随后变换后的特征会被送入共享网络和场景私有网络,其中所有场景的样本都会通过共享网络,而当前场景样本会通过场景标志符选出场景私有网络并送入当前场景网络。得到共享网络和场景私有网络的输出后,两者的输出会经过一个融合层并送入最后的场景私有前向网络,最后计算Sampled Softmax Loss。
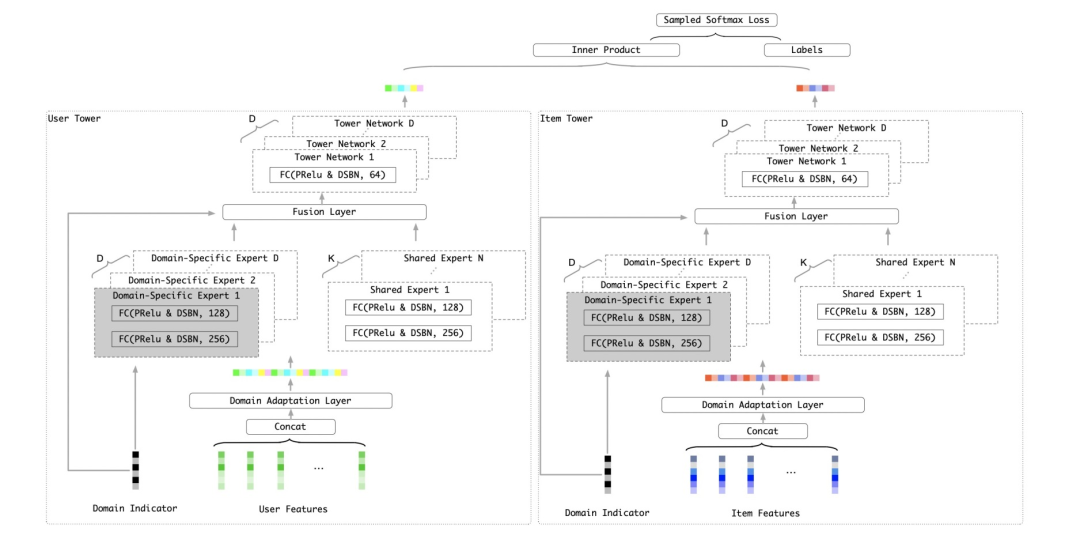
3.2 领域自适应
在本文中我们实现了两种领域自适应方案:场景感知的批归一化和领域兴趣自适应层。批归一化(Batch Normalization,简称BN)技术已经在神经网络设计中得到了广泛地应用;BN假定输入数据遵循独立同分布假设,这在单一场景下是适用的。然而在多场景推荐任务中,来自不同场景的数据分布往往具有较大差异;因此我们将现有模型中的批归一化部分升级为了场景感知的批归一化(Domain-Specific Batch Normalization,简称DSBN)[5]。如图3-2所示,通过计算不同场景batch内的参数统计值,DSBN实现了对场景相关信息的捕捉:
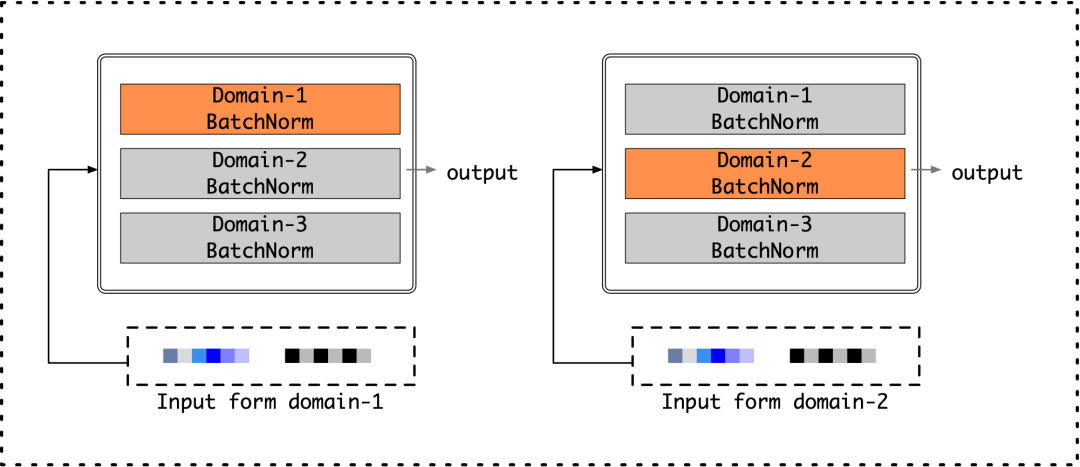
而领域兴趣自适应层用于自动赋予不同场景的样本不同的特征权重,考虑到不同的场景可能会关注于原始特征的不同部分。我们实现了三种形式的领域兴趣自适应层,并在实践中发现基于SE-Block注意力机制[6]实现的版本效果最好,具体实现如下:
其中是一个标准的SE-Block,由()这样的网络结构组成。领域兴趣自适应层通过学习不同场景下的不同注意力权重,以一种轻量且高效的方式捕获跨场景差异性。
3.3 自监督学习
自监督学习是一种在训练时高效利用无标签数据的训练策略,我们首次将这种技术引入多场景推荐任务中。因为当不同场景的用户/商品存在重叠时,训练数据中存在潜在的标签级关联关系;具体而言,若用户在一个场景下交互某个商品,该用户仍有概率在另一场景交互该商品。这一假设尤其适用于数据量丰富的场景帮助数据量稀疏的场景,甚至一个新场景。
给定用户、商品以及场景,自监督学习策略会计算该用户在其他场景对该商品的匹配分数,大于一定阈值则将这条样本训练产生的梯度回传给场景的模型参数。简单而言,该策略在模型正常训练中交替执行以下两个步骤:
冻结模型参数,生成伪标签,并根据阈值筛选置信的伪标签;
冻结伪标签,微调模型参数。具体实现如图3-3所示。

4. 实验分析
本节中我们选择了部分实验结论进行展示,更多实验细节与结论请参考原论文。(Adaptive Domain Interest Network for Multi-domain Recommendation,https://dl.acm.org/doi/abs/10.1145/3511808.3557137)
4.1 对比和消融实验
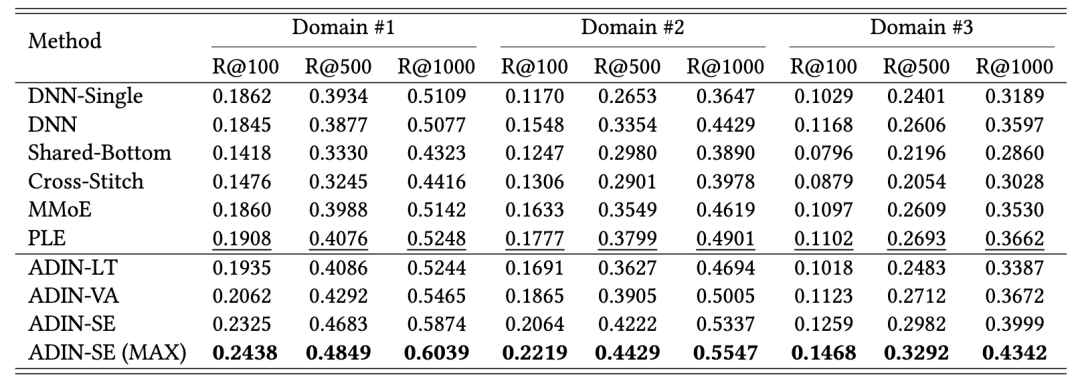
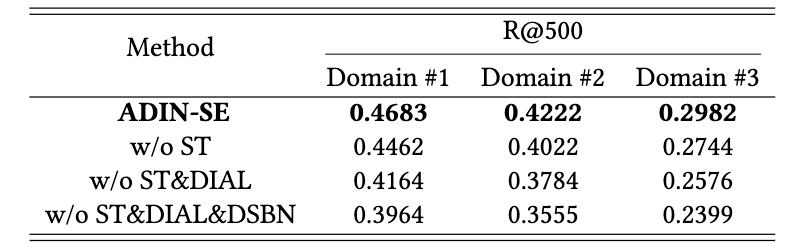
我们在真实在线系统的数据集进行训练及测试,该数据集包含三个场景的样本。从表4-1可见,ADIN相对于各类基线模型均能获得显著的提升。值得注意的是,混合三场景样本共同训练的DNN在场景二、场景三上的效果优于独立场景独立训练的DNN-single,然而在场景一上的效果却更差。这种现象表明,简单地混合训练数据而不设计特定的模型结构可能会损害模型性能。
在表4-2中,详细的消融实验结果表明,该方法在各个场景下均能带来正向收益。升级后的场景感知的批归一化技术能够有效解决不同场景数据分布不一致的问题,建模场景间的差异性;领域兴趣自适应层能自动给予不同场景下特征的不同权重;而自监督学习策略能有效捕捉不同场景间样本在标签级别的关联关系,进一步提升多场景建模的效果。
4.2 SE-Block使用方案对比实验
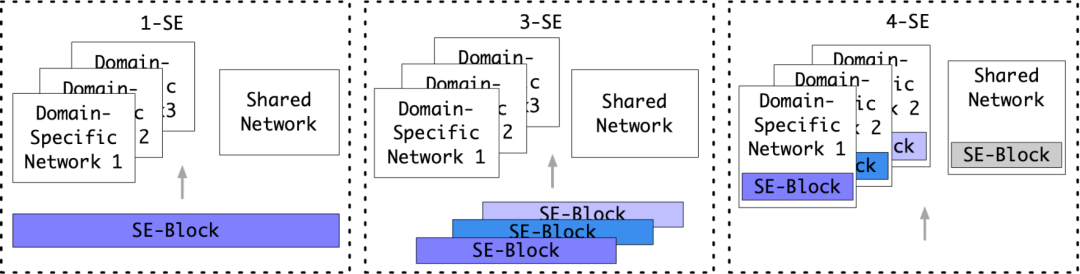
我们认为SE-Block的正确使用方法对最终模型效果至关重要。如图4-1所示,我们对比三种不同的SE-Block的使用方案,分别是:
1-SE:使用一个全局SE-Block作为通用的特征权重放缩层;
3-SE:为每个场景设计一个SE-Block作为领域兴趣自适应层,对应场景的样本会通过对应场景的SE-Block;
4-SE:在私有/公有网络中均加入SE-Block,单纯增加模型的复杂度而不是对特征进行领域自适应操作。
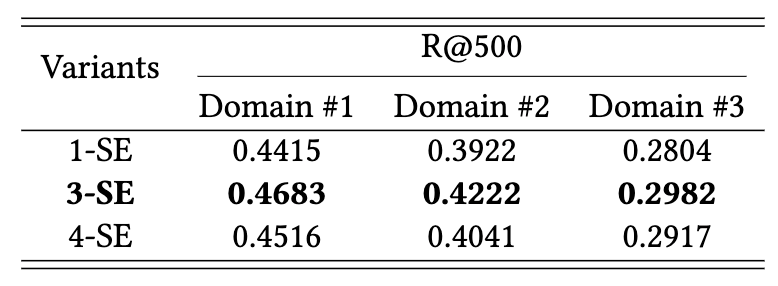
从表4-2的结果可知,1-SE版本的性能最差,3-SE版本的性能最好。一个有趣的现象是,即使模型参数增加,4-SE版本的效果并不比3-SE更好。因此,我们建议使用3-SE版本作为领域兴趣自适应层,而不是单纯地增加网络复杂度。
4.3 可视化
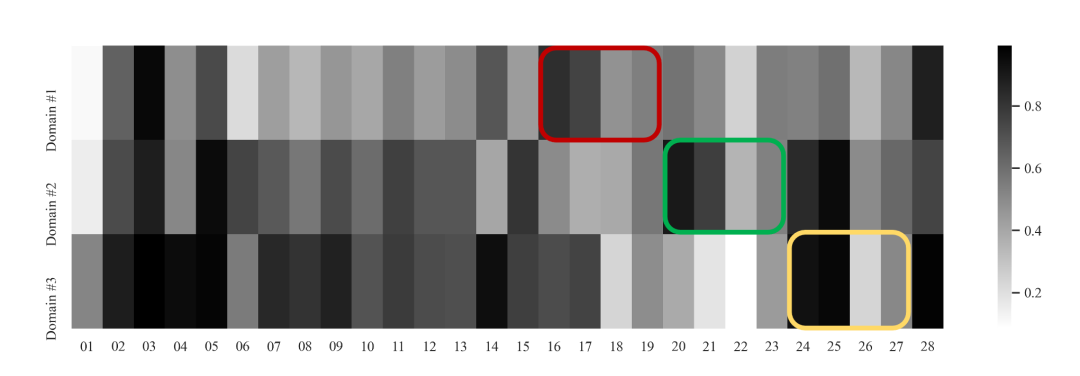
为了给出领域兴趣自适应层有效性的直观证据,我们可视化了不同场景的SE-Block注意力权重。如图4-3所示,不同的暗度分布表明每个场景关注特征的强度差异。值得注意的是,我们将场景一、场景二、场景三中提取的统计特征(CTR、CLICK、COST和PAYNUM)分别用红色、绿色和黄色线框框出。可以看到,领域兴趣自适应层自动分配给场景相关特征更高的注意力分数,这证明了我们提出的场景兴趣适应层的有效性。
4.4 在线实验
目前该模型已部署在阿里妈妈展示广告系统。为得到稳定结论,我们观察了一段时间的在线实验。广告系统中的三个常用指标用于衡量在线性能:RPM(千次展示消耗)、PPC(单次点击成本)和CTR(点击率)。如表4-4所示,在我们的在线A/B测试实验中,ADIN在三个场景下均取得了在线指标的有效提升。

5. 总结
本文聚焦多场景下的推荐问题。与现有工作相比,我们提出的ADIN尝试将领域自适应技术应用于推荐系统的召回阶段。骨干网络有效地学习多个场景间潜在的共性和多样性;DSBN组件和领域兴趣自适应层用于特征级领域自适应;自监督学习训练策略则可以捕获跨场景的潜在标签级连接。在公共和工业数据集上的实验验证了该方法的优越性。同时,我们从多个维度广泛地讨论和验证了所提出方法的有效性,并对每个组件的正确使用方案给出了建议。ADIN已在阿里妈妈展示广告系统全量上线,并获得了可观广告收入增长。
该项工作相关内容已发表在 CIKM 2022,欢迎阅读交流。
论文:Adaptive Domain Interest Network for Multi-domain Recommendation
下载:https://dl.acm.org/doi/abs/10.1145/3511808.3557137
参考文献
[1] Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems, 191–198.
[2] Yang Zou, Zhiding Yu, Xiaofeng Liu, BVK Kumar, and JinsongWang. 2019. Confidence regularized self training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 5982–5991.
[3] Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire space multi-task model: an effective approach for estimating post-click conversion rate. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, 1137–1140.
[4] Rihan Chen, Bin Liu, Han Zhu, Yaoxuan Wang, Qi Li, Buting Ma, Qingbo Hua, Jun Jiang, Yunlong Xu, Hongbo Deng, et al. 2022. Approximate nearest neighbor search under neural similarity metric for large-scale recommendation. arXiv preprint arXiv:2202.10226.
[5] Woong-Gi Chang, Tackgeun You, Seonguk Seo, Suha Kwak, and Bohyung Han. 2019. Domain-specific batch normalization for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7354–7362.
[6] Jie Hu, Li Shen, and Gang Sun. 2018. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7132–7141.
END

也许你还想看
丨TDM到二向箔:阿里妈妈展示广告Match底层技术架构演进
丨从二值检索到层次竞买图——让搜索广告关键词召回焕然新生
丨DC-GNN:面向大规模广告召回场景的解耦式图模型方法
丨阿里妈妈展示广告智能拍卖机制的演进之路
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”ღ~
↓欢迎留言参与讨论↓