目录
导言:
1. 应用
2. 结构介绍
3. 代码案例
导言:
深度学习的迅速发展在图像识别、语音处理和自然语言处理等领域取得了巨大的突破。然而,深度神经网络在训练过程中遇到了梯度消失和梯度爆炸等问题,限制了模型的性能和训练的深度。为了解决这些问题,研究人员于2015年提出了一种创新的网络结构——ResNet(Residual Network)。本文将详细介绍ResNet的历史演变、作用影响、结构、使用方法以及提供一个代码案例。
1. 应用
ResNet是由何凯明等人于2015年提出的,作为ImageNet图像分类比赛中的冠军模型而闻名。在此之前,深度神经网络的训练存在梯度消失和梯度爆炸的问题,难以训练深层网络。ResNet通过引入残差学习的概念,解决了这一问题,为深度学习的发展开辟了新的道路。
ResNet的提出对深度学习领域有着重大的影响。首先,它引入了残差学习的思想,使得深层网络的训练更加容易,允许网络达到更深的层数。其次,ResNet在图像分类、目标检测、语义分割等计算机视觉任务中取得了显著的性能提升,推动了计算机视觉技术的发展。此外,ResNet的思想也被广泛应用于其他领域,如自然语言处理和语音识别等。
自lenet出现以来,相关领域人才都在优化网络上朝着更大更深的网络去研究,但是也会出现一些问题,如下如,对于某些非嵌套函数,不一定越大越深的网络可以有更好的结果,比如L1>L2,但对于嵌套函数是一定的,为了解决这个问题,何恺明等人提出了残差网络(ResNet) (He et al., 2016)。 它在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经网络的设计。 残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。 于是,残差块(residual blocks)便诞生了,这个设计对如何建立深层神经网络产生了深远的影响。 凭借它,ResNet赢得了2015年ImageNet大规模视觉识别挑战赛。

2. 结构介绍
首先是什么是残差块:
让我们聚焦于神经网络局部:如图所示,假设我们的原始输入为x。 左图虚线框中的部分需要直接拟合出该映射f(x),而右图虚线框中的部分则需要拟合出残差映射f(x)−x。 残差映射在现实中往往更容易优化。 右图是ResNet的基础架构–残差块(residual block)。 在残差块中,输入可通过跨层数据线路更快地向前传播。
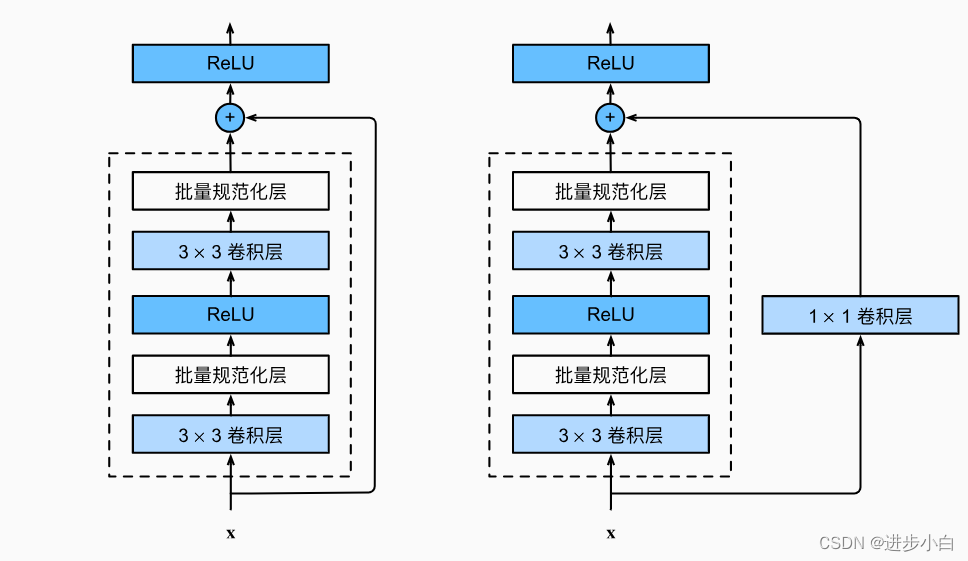
ResNet的核心结构是残差块(residual block),由两个或三个卷积层组成。每个残差块包含了跳跃连接(skip connection),将输入直接传递给输出。这种设计可以使得网络学习残差函数,更好地捕捉输入和输出之间的差异。ResNet还引入了全局平均池化层,将最后一个残差块的输出转化为分类结果。整个网络结构分为多个阶段,每个阶段包含若干个残差块。
结构图如下:
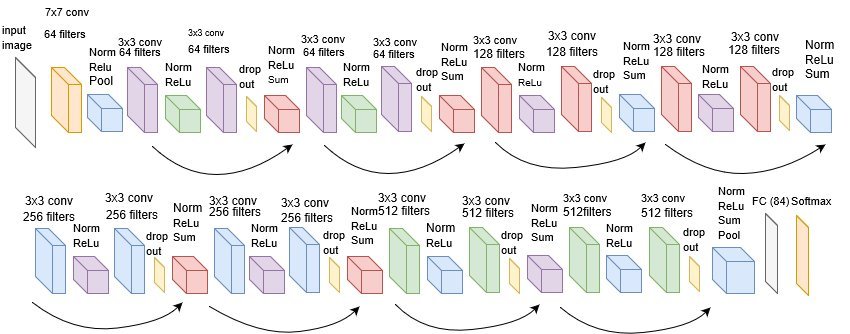
每个模块有4个卷积层(不包括恒等映射的1×1卷积层)。 加上第一个7×7卷积层和最后一个全连接层,共有18层。 因此,这种模型通常被称为ResNet-18。 通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。 虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。
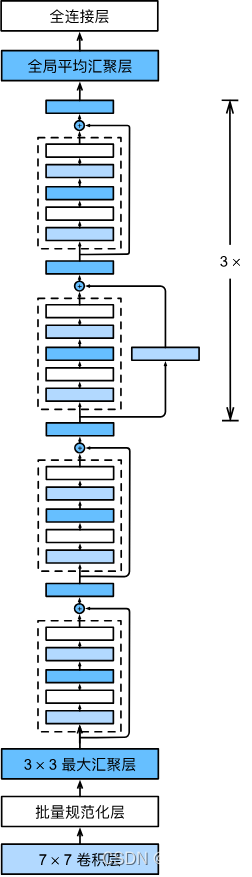
使用ResNet进行图像分类的方法相对简单。首先,需要准备一个带有标签的图像数据集进行训练。然后,根据任务的需求选择合适的ResNet结构,并在训练数据上进行网络的训练。训练完成后,可以使用测试数据对网络进行评估,并获得分类结果。
3. 代码案例
3.1案例
如下提供一个简单的代码案例:
import torch
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
# 设置随机种子以保持结果的一致性
torch.manual_seed(42)
# 定义超参数
batch_size = 64
num_epochs = 10
learning_rate = 0.001
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载和预处理数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = CIFAR10(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 加载ResNet预训练模型
resnet = models.resnet50(pretrained=True)
num_classes = 10
resnet.fc = nn.Linear(resnet.fc.in_features, num_classes)
resnet.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(resnet.parameters(), lr=learning_rate, momentum=0.9)
# 训练网络
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = resnet(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 输出训练信息
if (i+1) % 100 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}")
# 在测试集上评估模型
resnet.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = resnet(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")
3.2训练结果
Extracting ./data\cifar-10-python.tar.gz to ./data Files already downloaded and verified Epoch [1/10], Step [100/782], Loss: 1.0319 Epoch [1/10], Step [200/782], Loss: 1.1229 Epoch [1/10], Step [300/782], Loss: 0.8398 Epoch [1/10], Step [400/782], Loss: 0.8044 Epoch [1/10], Step [500/782], Loss: 0.8307 Epoch [1/10], Step [600/782], Loss: 0.7975 Epoch [1/10], Step [700/782], Loss: 0.7846 Epoch [2/10], Step [100/782], Loss: 0.3949 Epoch [2/10], Step [200/782], Loss: 0.5152 Epoch [2/10], Step [300/782], Loss: 0.7796 Epoch [2/10], Step [400/782], Loss: 0.3524 Epoch [2/10], Step [500/782], Loss: 0.6294 Epoch [2/10], Step [600/782], Loss: 0.6961 Epoch [2/10], Step [700/782], Loss: 0.4766 Epoch [3/10], Step [100/782], Loss: 0.4821 Epoch [3/10], Step [200/782], Loss: 0.3328 Epoch [3/10], Step [300/782], Loss: 0.2926 Epoch [3/10], Step [400/782], Loss: 0.3867 Epoch [3/10], Step [500/782], Loss: 0.3263 Epoch [3/10], Step [600/782], Loss: 0.3571 Epoch [3/10], Step [700/782], Loss: 0.4108 Epoch [4/10], Step [100/782], Loss: 0.1394 Epoch [4/10], Step [200/782], Loss: 0.0899 Epoch [4/10], Step [300/782], Loss: 0.2545 Epoch [4/10], Step [400/782], Loss: 0.2804 Epoch [4/10], Step [500/782], Loss: 0.3633 Epoch [4/10], Step [600/782], Loss: 0.3250 Epoch [4/10], Step [700/782], Loss: 0.1818 Epoch [5/10], Step [100/782], Loss: 0.2360 Epoch [5/10], Step [200/782], Loss: 0.1247 Epoch [5/10], Step [300/782], Loss: 0.1398 Epoch [5/10], Step [400/782], Loss: 0.1117 Epoch [5/10], Step [500/782], Loss: 0.1807 Epoch [5/10], Step [600/782], Loss: 0.1970 Epoch [5/10], Step [700/782], Loss: 0.1364 Epoch [6/10], Step [100/782], Loss: 0.1568 Epoch [6/10], Step [200/782], Loss: 0.1354 Epoch [6/10], Step [300/782], Loss: 0.0280 Epoch [6/10], Step [400/782], Loss: 0.1083 Epoch [6/10], Step [500/782], Loss: 0.0687 Epoch [6/10], Step [600/782], Loss: 0.0650 Epoch [6/10], Step [700/782], Loss: 0.1396 Epoch [7/10], Step [100/782], Loss: 0.0428 Epoch [7/10], Step [200/782], Loss: 0.0601 Epoch [7/10], Step [300/782], Loss: 0.1236 Epoch [7/10], Step [400/782], Loss: 0.0677 Epoch [7/10], Step [500/782], Loss: 0.0642 Epoch [7/10], Step [600/782], Loss: 0.2154 Epoch [7/10], Step [700/782], Loss: 0.2325 Epoch [8/10], Step [100/782], Loss: 0.2054 Epoch [8/10], Step [200/782], Loss: 0.0618 Epoch [8/10], Step [300/782], Loss: 0.1539 Epoch [8/10], Step [400/782], Loss: 0.1003 Epoch [8/10], Step [500/782], Loss: 0.0557 Epoch [8/10], Step [600/782], Loss: 0.1296 Epoch [8/10], Step [700/782], Loss: 0.1271 Epoch [9/10], Step [100/782], Loss: 0.0371 Epoch [9/10], Step [200/782], Loss: 0.0863 Epoch [9/10], Step [300/782], Loss: 0.0821 Epoch [9/10], Step [400/782], Loss: 0.0797 Epoch [9/10], Step [500/782], Loss: 0.0642 Epoch [9/10], Step [600/782], Loss: 0.0640 Epoch [9/10], Step [700/782], Loss: 0.0174 Epoch [10/10], Step [100/782], Loss: 0.0477 Epoch [10/10], Step [200/782], Loss: 0.0506 Epoch [10/10], Step [300/782], Loss: 0.0412 Epoch [10/10], Step [400/782], Loss: 0.0630 Epoch [10/10], Step [500/782], Loss: 0.0530 Epoch [10/10], Step [600/782], Loss: 0.0801 Epoch [10/10], Step [700/782], Loss: 0.0104 Test Accuracy: 83.99%
上述代码中,我们使用了CIFAR10数据集进行图像分类任务。代码首先加载并预处理数据集,然后加载预训练的ResNet模型,并对输出层进行修改以适应任务需求。接下来,我们定义了损失函数和优化器,并使用训练数据对网络进行训练。最后,在测试集上评估模型的准确率。
请确保安装了PyTorch和torchvision库,并将代码保存为一个Python文件后运行。注意,代码中使用了GPU(如果可用),可以在运行时进行加速,但如果没有GPU,也可以在CPU上运行。