本文翻译自:Modern Microprocessors A 90-Minute Guide!,,我认为原文是相当好的计算机体系结构方面的概述,与时代相结合是国内计算机课本普遍缺失的一环,本文可作为一个有效的补充,向原作者和其他译者表示感谢。
文章标题说90分钟的简介,但是内容却十分精彩,作者主要从一下方面介绍
- 首先从处理器的频率出发,分析处理器为什么要引入流水线?为什么会出现超标量流水线?为什么要乱序执行?为什么需要分支预测?流水线的深度是否越深越好?处理器的发射带宽是否越宽越好?是否乱序执行一定比顺序执行要好?业界的驻留CPU厂商是如何做的?
- 分析完这些基础的概念后,继而分析为什么单核的性能不能无限制提升(POWER WALL),什么时候需要SIMD?然后分析了同时多线程SMT和多核在提升处理器性能方面的对比,同时又分析了cache对处理器的作用以及性能的影响
本文是一个简要的,不拖泥带水的,快节奏的介绍现今处理器微架构主要设计的文章。
现在的机器人还都是非常初级的,只能够理解简单的指令,比如"往左",“往右”,或者"造车"
— John Sladek
1 前言
警告:本文章非权威,仅仅只是兴趣
好吧,你可能是一个计算机专业的毕业生,也许作为学位课程的一部分你学习过硬件课程,但是也许这已经是几年前的事了,现在你也没记住多少关于处理器设计的一些细节了,那么这篇文章可能正适合于你。
特别是,您可能没有意识到最近迅速发展的一些关键主题…
- 流水线(超变量superscalar,乱序执行OOO,超长指令字VLIW,分枝预测branch prediction,假设predication)
- multi-core and simultaneous multi-threading (SMT, hyper-threading)
多核和同时多线程(SMT,又称超线程) - SIMD vector instructions (MMX/SSE/AVX, AltiVec, NEON)
单指令多数据的向量指令 - 缓存或者内存层次结构
不要怕!这篇文章将会快速带你跟上时代的节奏。在任何时候,你都可以像专业人士般参与讨论顺序执行,乱序执行,超线程,多核,缓存组织等话题。
但是请注意: 这篇文章是简要的,点到为止。它不拖泥带水,节奏相当的快,好吧,我们开始…
2 不仅仅是频率_More Than Just Megahertz_
第一个要弄清楚的话题是处理器的时钟速度和它的性能之间的关系: 它们不是一回事。是不是主频越高,CPU性能就越好,这似乎是很多人的误区。先来看看几年前的处理器的性能和频率(上世纪 90 年代末)
- 对于200MHz的MIPS R10000处理器、300MHz的UltraSPARC处理器,以及400MHz的Alpha 21164处理器在运行大多数程序上,速度相当,但是它们在时钟频率上却相差了两倍
- 300MHz的Pentium II处理器在大多数情况下也有相同的速度,但是在处理浮点运算时的速度却只有一半
- PowerPC G3 的处理器频率也是300MHz它在处理常规整形运算时比其他处理器快,但是浮点运算性能却远远低于前三名
- 更极端的情况是IBM POWER2处理器仅仅只有135MHz的频率,它的浮点运算性能却与400MHz的Alpha 21164处理器相当,而整型运算能力却只有它的一半
为什么会出现这种情况呢?显然,不仅仅只有时钟频率,还有更多的影响程序执行速度的因素,但是归根结底,还是处理器每个时钟周期内能够完成的工作量。所以,这就导致了引入下面的流水线和指令并行的话题。
- 2015 年 12 月 31 日启用的中国超级电脑“神威太湖之光”,其“260 核心”(256 个用在运算,4 个用于资源管理)SW26010 处理器,也是基于 Alpha 指令集的产物,足以证明其架构的简洁性与前瞻性。
- 因产品价格与专利费用太过昂贵而叫好不叫座的 Alpha,未能让 DEC 摆脱“后 VAX 时期”留下的困境。从 1991~1994 年,总计亏损 40 亿美元,被迫断尾求生,全力卖掉“可割可弃”的部门。
评价一款CPU是否成功主要看三点:架构、制程、软件生态。架构靠先天遗传,制程靠后天努力,软件生态则靠合纵连横。RISC架构的确给了PowerPC一些先天优势,但后面两个的短板实在差距太大,AIM联盟忙活半天,发现自己骑的还是雅迪。
为什么x86架构会胜出呢?x86主要面对的是民用时长,而对于risc主要使用的服务器和军工,
https://finance.sina.cn/tech/csj/2023-02-01/detail-imyeffyf0055169.d.html?vt=4&pos=108&his=0
3 流水线和指令级并行Pipelining & Instruction-Level Parallelism
通常,我们简单的认为,指令在处理器内部是一个接一个执行,对吧?虽然这听起来很符合直觉,但这并不是实际情况,事实上,从19世纪80年代中期,有些处理器指令在内部就不是依照先后顺序执行了,而是多条指令同时部分执行。
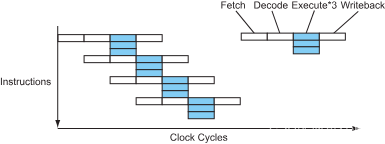
想一想cpu是怎么样执行的?首先是取指,接着是译码,然后被某个功能单元执行,最后将结果写回到寄存器。采用这样的方式,一个简单的处理器执行一条指令需要 4 个周期(CPI=4)。
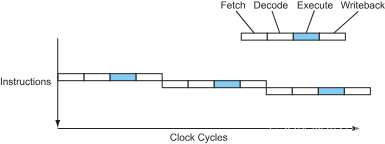
图 1 – 顺序处理器的指令流
现代处理器以流水线的形式将这些步骤进行重叠,就像工厂的装配流水线。当某条指令在执行时,下一条指令在译码阶段,下下条指令在取指阶段…
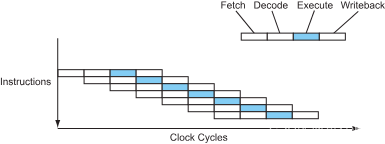
图 2 – 流水线处理器的指令流
现在处理器差不多可以在一个时钟周期完成1条指令了(CPI=1),这是在不改变时钟速度的情况下实现了4倍加速,非常不错,是吧?将CPU处理资料的部分分为数个stage,这种设计可以让处理器效益更好,因为每个stage在任意时间度有工作
从硬件的角度来看,流水线的每个阶段由一些组合的逻辑、可能访问寄存器组和高速缓存组成。流水线的每个阶段被锁存器latches分割开来,一个共同的时钟信号来同步每个流水线阶段之间的锁存器,以便于所有的锁存器在同一时间捕获流水线的每个阶段产生的结果。看起来时钟就像水泵一样,源源不断的向流水线输出指令。
在每个时钟周期的开始,流水线中的锁存器保存着当前正在执行指令的数据和控制信息,这些信息构成了该指令输入到流水线下一阶段的逻辑电路。在一个时钟周期中,信号通过这一阶段的组合逻辑传输到下一阶段,在时钟周期的最后阶段产生的输出正好被下一阶段的锁存器捕获
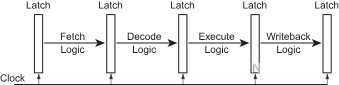
图 3 – 流水线微架构
在执行阶段结束后,指令的结果就应该被确定了,那么下一条指令应该就可以立即使用这个结果,而不是等待该结果在指令的写回(writeback)阶段保存到寄存器后才能使用。为了实现这一点,增加了被称为“旁路(bypass)”的转发线路,将结果沿着流水线返回。
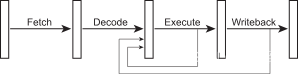
图 4 – 流水线微架构中的旁路
虽然每个流水线阶段看起来很简单,但是最重要的一点是,在关键的执行Execute阶段其实是由几个不同的逻辑电路组成,这些逻辑电路组组成了处理器执行各种操作的功能单元unctional units,如整型计算、浮点数计算、分支预测、内存读取等。
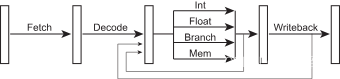
图 5 – 流水线微架构中的更多细节
早期的RISC处理器,例如IBM的801研究原型机,MIPS R2000(基于斯坦福大学的 MIPS 架构)和原版的SPARC(伯克利 RISC 的衍生项目),都实现了一个不同于上面展示的简单的5级流水线。同时,在同一时期主流的 80386, 68030 和 VAX 这些 CISC 处理器主要采用顺序执行的工作方式。这是因为采用流水线来执行RISC更简单,指令大多数是简单的寄存器之间操作,因而更容易实现流水线。而采用复杂指令集的x86、68k或者VAX,因为指令较为复杂,采用流水线来执行则比较困难。结果,使用了流水线工作模式的 SPARC@20MHz 比顺序处理的 386@33MHz 运行速度快得多,从那时起,每个处理器都被流水线化,至少在某种程度上是这样。David Patterson 的这篇文章 1985 CACM article 对早期 RISC 研究项目做了一个很好的总结
4 深度流水线_Deeper Pipelines – Superpipelining_
在不考虑其他因素的前提下,由于时钟频率受限制于流水线中最长、最慢的那个阶段,那么组成这些极端的逻辑门电路可以再进一步的分解,特别是对于那些较长的阶段,这样,就将较长的流水线转换为包含数目更多、长度更短更深的超级流水线,那么整个处理器的主频就可以运行得更高。
当然,此时每条指令需要花费更多的时钟周期来完成(每个时钟周期有额外的时延,一条指令拆分成多个周期执行,总的时延可能会增加),但是处理器仍然是每个周期完成一条指令(吞吐量),由于时钟频率更快,所以实际上处理器每秒可以执行更多的指令。
(译注:一个时钟周期要大于流水线中最慢的那个阶段,而随着外界环境变化不同逻辑门的反应时间可能发生改变,因此段首注明不考虑其他因素。拆分流水线阶段的这个思想被称为 multi-cycle processing)
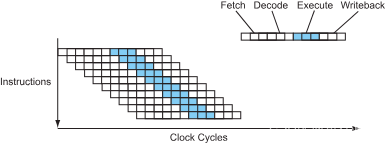
图 6 – 超级流水线处理器的指令流
Alpha 架构特别喜欢这个设计思想,这也是为什么拥有深度流水线的早期 Alphas 处理器在当时可以运行在如此高的时钟频率下。如今,现代处理器致力于控制逻辑门的数量以减少每个流水线阶段的延迟,每个流水线阶段大概 12-25 级门电路加上另外 3-5 个锁存器,但是大多数处理器都有非常深度的流水线。
通常x86处理器流水线级数比同时代的RISC处理器多,因为它们需要额外的工作来解码复杂的x86指令集。UltraSPARC T1/T2/T3 Niagara处理器是个例外, UltraSPARC T1只有6级流水线深度,T2/T3也只有8级流水线深度,这样做的目的是为了让核更小(后面会介绍更多)。
既然流水线可以增加我们的吞吐率,你可能要问了,为什么我们不把流水线级数做得更深呢?为什么不做成 20 级,乃至 40 级呢?这个其实有很多原因,我在之后几讲里面会详细讲解。这里,我先讲一个最基本的原因,就是增加流水线深度,其实是有性能成本的。
我们用来同步时钟周期的,不再是指令级别的,而是流水线阶段级别的。每一级流水线对应的输出,都要放到流水线寄存器(Pipeline Register)里面,然后在下一个时钟周期,交给下一个流水线级去处理。所以,每增加一级的流水线,就要多一级写入到流水线寄存器的操作。虽然流水线寄存器非常快,比如只有 20 皮秒(ps,10−12 秒)。 
但是,如果我们不断加深流水线,这些操作占整个指令的执行时间的比例就会不断增加。最后,我们的性能瓶颈就会出现在这些 overhead 上。如果我们指令的执行有 3 纳秒,也就是 3000 皮秒。我们需要 20 级的流水线,那流水线寄存器的写入就需要花费 400 皮秒,占了超过 10%。如果我们需要 50 级流水线,就要多花费 1 纳秒在流水线寄存器上,占到 25%。这也就意味着,单纯地增加流水线级数,不仅不能提升性能,反而会有更多的 overhead 的开销。所以,设计合理的流水线级数也是现代 CPU 中非常重要的一点。
总结:
流水线技术是一个提升性能的灵丹妙药,它通过把一条指令的操作切分成更细的多个步骤,可以避免CPU浪费。每一个细分的流水线步骤都很简单,所以我们的单个时钟周期的时间就可以设置的更短,这也变相让cpu的主频提升的很快。
5 多发射:超标量_Multiple Issue – Superscalar_
由于流水线的执行阶段由不同的功能单元来执行,每个功能单元能独立完成自己的任务,所以不同功能单元负责的指令可以同时执行,这看上去再吸引着我们去尝试并行运算多个指令,每个指令采用各自的功能单元。要做到这样,必须改进取指和译码阶段,这样我们可以并行译码多条指令并将他们发送到执行单元中。
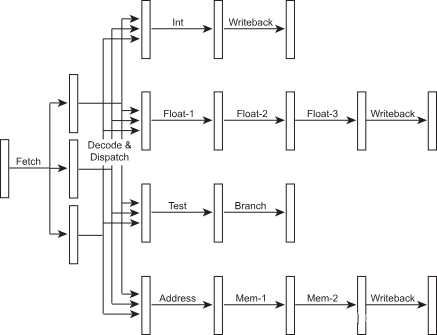
图 7 – 超标量微架构
当然,现在每个功能单元之间的流水线都相互独立,它们甚至可以有不同数量的流水线级数,使简单的指令更快的执行,从而减少延迟_latency_(我们很快会讲到延迟的概念)。既然这样的处理器拥有不同的流水线深度,我们通常将处理器中执行整型运算指令的流水线深度叫做处理器的流水线深度,这也差不多是处理器中最短的流水线了,因为内存或者浮点数相关的流水线通常还会有几个额外的阶段。因此,我们说个一个10级流水线的处理器使用10级来执行整型指令,可能使用 12 或 13 个阶段来执行内存指令,可能使用 14 或 15 个阶段来执行浮点数。当然流水线内部或流水线之间也会有一堆旁路bypasses,为了简化上图中省略了旁路。
在上面的例子中,处理器可能在一个时钟周期内发送3个不同的指令,例如1个整型指令,一个浮点型指令和一个存取指令。甚至可以添加更多的功能单元,这样处理器1个时钟周期内可以执行2个整型,或2个浮点数,或2个内存指令,或者使目标应用程序可以最高效率运行的任何指令组合。
在一个超标量处理器中,指令执行的流程如下图所示:
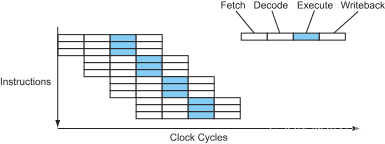
图 8 – 超标量处理器中的指令流
这样看起来好极了,现在每个时钟周期内有3条指令被执行完成(CPI=0.33,or IPC=3,也可以写成 ILP=3, instruction-level parallelism – 指令级并行)。处理器每个时钟周期内能够同时发射,执行或者完成的指令数量称为处理器宽度。
注意,由于不同的代码序列有不同的指令组成,因此发射宽度一般小于功能单元的数量。假设我们的目标是达到每个时钟周期执行3条指令,但是这些指令不可能总是1个整型指令+1个浮点指令+1个内存操作指令,因此功能单元的数量是需要大于3个。
PowerPC 的前身,IBM POWER1 是第一个主流超标量处理器。之后大多数 RISC 处理器(SuperSPARC, Alpha 21064)都开始使用超标量。Intel 也试图制造 x86 架构的超标量处理器 – Pentium 处理器的原始版本 – 然而复杂的 x86 指令集是一个很大的障碍。
当然,没有什么可以阻止一个处理器同时拥有较深的流水线以及多指令发射机制,所以处理器可以同时是超流水线和超标量(superpipelined and superscalar)。
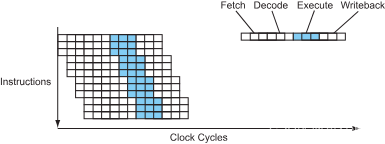
图 9 – 超流水线 – 超标量处理器的指令流
今天,差不多所有的处理器都是超流水线-超标量,所以我们通常简称为超标量。严格来说,超流水线只是拥有更深的流水线而已,现代处理器之间的带宽差别很大:
每款处理器的功能单元的实际数量和类型取决于目标市场,某些处理器的浮点运算资源更多(IBM POWER产品线),其他的处理器则更加倾向于整型运算(Pentium Pro/II/III/M),还有一些处理器则将资源投向SIMD向量质量(PowerPC G4/G4e),然而总的来说大多数处理器尽量使各种资源均衡。
6 Explicit Parallelism – VLIW
如果不考虑向后兼容,指令集单元可以显示的将那些将要并行执行的指令组合成一条指令。采用这种方法,在指令分发阶段,就不必进行复杂的指令间依赖检查,可以使处理器更容易设计,更小,更简单的提高处理器时钟速度(至少在理论上)。
在这种类型的处理器中,“指令”其实被分组成更小的子指令集合,因此“指令”本身非常长,通常使128bit或者更多,所以 VLIW 的意思是超长指令字(very long instruction word),每条指令包含了多个并行操作的信息。
一个VLIW类型的处理器的指令流和超标量的指令流看起来差不多,只不过它的译码/分发stage非常简单,只作用于当前组的子指令。
除了简单的分发dispatch逻辑外,VLIW处理器和超标量处理器非常相似。尤其是站在编译器的角度来看(稍后会详细介绍)。
值得注意的是,大多数VLIW的指令相互之间没有关联,这意味着指令之间不需要依赖性检查,并且当缓存未命中时,没有办法停止单独指令的执行,只能停止整个流水线。因此编译器需要将有依赖关系的指令进行适当协调,使其之间相隔合适的时钟周期。如果没有合适指令来填充这个间隔时间,甚至会使用nop(空指令)来填充,这使得编译器变得复杂。而超标量处理器上通常是在运行时刻做这些调度的,为了节约处理器宝贵的片上资源,编译器中尽可能减少空指令的插入。
现在还没有VLIW类型的处理器像主流处理器那样成功商用,但是Intel的IA-64架构的Itanium(安腾)处理器曾经试图取代x86架构。Intel将IA-64称为EPIC设计,意思是“显示并行指令计算”(explicitly parallel instruction computing),但是实际上就是 VLIW 的基础上加上智能分组(保证长期兼容性)和分支预测功能。图形处理器(GPU)中的可编程着色器有时候也采用 VLIW 设计,同时还有很多数字信号处理器(DSP),也有 Transmeta(全美达)这样的公司使用 VLIW。
7 指令依赖和延迟_Instruction Dependencies & Latencies_
流水线和超标量能够发展多久?如果5级流水线可以快5倍,为什么不制作20级的流水线?如果超标量每秒发射4调指令可以完美运行,为什么不发展为每秒发射8条指令?更进一步,为什么不制作一款50级流水线并且每个时钟可以发射20条指令的cpu?
下面,考虑以下两条指令:
a = b * c;
d = a + 1;
第二条指令依赖于第一条指令,处理器只有在第一条指令执行完毕,运算出结果后,才能执行第二条指令。这是一个非常严重的问题,因为相互依赖的指令不能并行执行,因此多发射在这种情况下不能使用。
如果第一条语句是一个简单的整型假发运算对于单发射的流水线是可行的,因为整型假发的运算非常快,第一条语句的结构可以及时反馈给下一条语句。但是对于乘法,则会浪费几个周期来完成运算,因此没办法再一个时钟周期间隔内将第一条指令的结果传送给已经达到执行阶段的第二条指令。所以,处理器需要停止执行第二条指令直到第一条指令的结果可用,通常在流水线中插入气泡(bubble)来实现停顿。
当一条指令从执行阶段到它结果可以被其他指令使用这之间间隔的时钟周期数量称为指令的延迟(latency)。流水线越深,级数越多指令延时就越长。所以一个很长的流水线并不会比一个短流水线的效率高,由于指令之间的依赖会使越长的流水线中填充越多的气泡(bubble)。
站在编译器的角度来看,现代处理器的典型延迟时间范围从1个时钟周期(整型操作)到3-6个时钟周期(浮点加法,乘法运算可能相同或者稍微更长一点),再到十几个时钟周期(整型除法)。
对于内存加载指令来说延迟是要给非常麻烦的问题,部分原因是它们通常发生在代码序列的早期,导致很难使用有效的指令来填充,另外一个重要的原因是他们都是不可预测的,加载延迟的时间很大程度取决于访问缓存是否命中。
8 分支和分支预测_Branches & Branch Prediction_
流水线中的另外一个关键问题是分支预测,可以考虑如下代码:
if (a > 7) {
b = c;
}
else {
b = d;
}
编译后汇编代码如下:
cmp a, 7 ; a > 7 ?
ble L1
mov c, b ; b = c
br L2
L1: mov d, b ; b = d
L2: ...
现在想象流水线处理器执行这段代码,当第2行的条件分支在流水线中到了执行阶段,处理器该取指并解码下一条指令了,但是它该取哪一条呢?应该取if分支(3,4行)还是else分支(第5行)?这个问题需要一直到条件分支执行完毕才能直到答案。
但是在一个深度流水线处理器中,此时距离知道答案可能还有好几个时钟周期,遇到分支就单纯的等待是不可行的,处理器等不起,因为处理器平均6条指令就会遇到一个分支,如果在每个分支下都等待几个时钟周期,流水线带来的性能提升就基本被抵消掉了。
因此处理器必须赌一把,必须做出猜测,处理器将会顺着它的猜测路径进行取指和译码,当然,在分支预测的结果出来之前,它不会真正的将指令执行的结果写回寄存器。所以坏的情况下,如果赌输了,已经执行的指令将会被取消,执行这些指令的时钟周期将被浪费掉;但是如果赌对了,处理器将能够继续全速运行。
所以问题的关键是处理器应该怎么样进行猜测?有两种方案可供选择,第一,编译器来给某个分支做标记,告诉编译器来选择哪个分支,通常称这个为静态分支预测。理想情况下要是指令格式中能够有一个标记位能够来存储预测信息,作为预测的依据,但是对于较老的处理器架构中,不可能有这个选项。所以可以采用通用的惯例来作为判断的依据,比如向后的分支预测为真,向前的分支预测为假。更重要的是,这种方法要求编译器非常只能,这样我们才能依赖它做出正确的决策,这在循环分支判断中很容易,但是对于其他分支预测可能回很困难。
另外一种方法是处理器在运行时做判断,通常使用一个片上分支预测表来实现,表中保存着最近使用过的分支的地址,并且用一位来标记每个分支在上一次运行中是否被执行。实际上,大多数处理器使用两位来标记,这样就可以避免单个偶然时间的发生影响预测结果(尤其在循环边缘的时候)。当然这个动态分支预测表需要占用处理器片上的宝贵资源但是分支预测是如此重要,所以这点资源是值得的。
不幸的是,即使是使用最好的分支预测技术,有时也会预测错误,从而导致一个深度流水线上的很多指令都要被回退,这被称为分支预测惩罚。Pentium Pro/II/III 处理器是一个很好的例子——它有 12 级流水线因此错误预测惩罚是 10-15 个时钟周期。即使 Pentium Pro/II/III 处理器的动态分支预测器非常智能(正确率高达90%),但高昂的分支预测惩罚依然会使其浪费掉 30% 的性能。换句话说 Pentium Pro/II/III 处理器三分之一的时间都在做没有用的工作,而是在 “哎呀,走错路了”
现代处理器致力于投入更多的硬件资源到分支预测上,试图提高预测的准确性以减小错误预测惩罚的开销。很多记录每个分支的方向并不是孤立的,而是由两个分支的执行情况来决定,这杯称为两级自适应预测器。有些处理器不保存单独的分支运行结果,而是维护一个全局的分支执行历史,以试图检测代码路径上距离较远的分支之间的关联性。这被称为 gshare 或者 gselect 预测器。现代最先进的处理器通常实现了多个分支预测器,然后选择那个看起来预测最精准的一个。
然而,即使是最先进的处理器上使用的最好,最智能的分支预测器也只能将正确率提升到95%,仍然会由于预测错误而失去相当一部分的性能。规则非常简单,流水行太深则收益减小,因为流水线越深你就必须预测越多的分支,所以错误的可能性就越大,并且错误预测惩罚也越大。
9 Eliminating Branches with Predication
处理条件分支太过麻烦,如果能完全去掉他们就好了!!!但是在编程语言中取消if语句是不可能的,那么怎样才能消除分支呢?答案就在一些分支的使用方法中。
再考虑上面的例子,5条指令中,有2条是分支指令,分支指令中有一条又是无条件分支。如果可以给mov指令做一个标记告诉他们只在某个条件下执行,则代码可以简化为:
cmp a, 7 ; a > 7 ?
mov c, b ; b = c
cmovle d, b ; if le, then b = d
这里引入了一条新的指令cmovle-“如果小于或等于则移动”。这条指令会正常执行但是只有在条件为真的时候才会提交执行结果。这种指令称为谓词指令,因为它的执行被一个谓词控制(判断真 / 假)。
使用这种新的谓词移动指令,代码中的两条消耗较大的分支指令都可以被移除。另外聪明的做法是总是首先执行mov指令,然后如果需要则覆盖mov指令的结果。同时也提高了代码的并行度,第1,2行的代码现在可以并行执行,结果是提速了50%(2个周期而不是3个)。更重要的是这种做法完全避免了分支预测错误的巨大惩罚。
当然如果 if 和 else 语句中的代码块非常大,则使用谓词会比使用分支执行需要执行更多的指令,因为处理器会将两条路径上的代码都执行一遍。这个棘手的问题是优化时不得不考虑的问题:多执行几条指令以消除分支是否值得?在很大或者很小的代码块中这个问题很容易决定,但是对于那些中等大小的代码块则需要经过复杂的权衡。
Alpha 架构在一开始就有条件移动指令,而 MIPS、SPARC 和 x86 是之后才加上的。在 IA-64 中 Intel 试图通过尽可能地把所有指令变成谓词指令,以减少循环内部中的分支问题(尤其是那些不可预测的分支例如编译器和 OS 内核中的分支)。有趣的是许多手机和平板中使用的 ARM 架构是第一种全谓词指令集的架构。更有趣的是早期的 ARM 处理器只有很短的流水线,因此它的错误预测惩罚相对较小。
(译注:谓词执行的本质是将控制依赖转变为数据依赖,也可以说是一种空间换时间的方法。另外,诺基亚时代的 ARM9 只有五级流水线,而到了 iPhone4 的 Cortex-A8 已经有了 14 级,和现代桌面接近)
10 指令调度,寄存器重命名和 OOO
如果分支预测和长延时的指令会造成流水线中产生气泡bubbles,这些本可以利用的时钟周期将会被浪费。为了避免这种浪费,可以将程序中的指令重新排序,再一条指令等待的间隔中执行其他指令。例如在上面的那个乘法例子中,可以在两条语句之间插入其他的语句。
有两种方法可以实现指令调度:
- 其中之一是程序运行时在硬件中对指令重新排序,为了实现这种动态调度,处理器需要实现更强大的指令分发逻辑,需要从指令组中找到能最大化利用功能单元的指令顺序,并将其重新排序后分发出去。这就是所谓的乱序执行,或者简称为OOO(有时写作OoO或OOE)
如果处理器乱序执行指令,那么它必须记住这些乱序指令间的依赖。这也可以通过不使用原生系统自定义的寄存器,而是通过一些重名的寄存器的方法来简化问题。比如,一个将某个寄存器内容写道内存的指令,后面跟着一个从其他内存块读值到该寄存器的操作,它们有不同的值,我们不必要使用同一个物理寄存器。更进一步,如果这些不同的指令对应到不同的物理寄存器,那么它们就可以并行运行了,这就是OOO执行的核心了。因此,处理器必须随时动态持有当前运行的所有指令以及它们使用的物理寄存器的对应关系。这个过程就称之为寄存器重命名。一个额外的好处是,处理器现在可以利用一个更多的真实寄存器来将代码最大程度并行化。
上面提到的这些依赖分析,寄存器重命名,乱序执行(OOO)使处理器的逻辑变得更复杂了,更难设计,芯片面积更大,更耗电。这些额外的逻辑特别耗电是因为这些晶体管一直工作着,不像功能单元那样有时候还能闲下来,甚至不通电。另一方面,乱序执行可以保证软件不必重新编译也可以运行在新处理器上,使用新处理器的某些优势,当然不是所有的优势。
另一种方法是让编译器来重排指令,这通常称为静态指令重排或者编译器指令重排。重排后的指令流就可以提供给简单设计的有序、多发射执行的处理器,这依赖于编译器要能够将最好的指令流喂给处理器。这避免了复杂的乱序执行逻辑,将让设计处理器轻松很多,处理器能耗也更低,面积也更小,这意味着在同一片芯片区域可以放更多的核,额外的缓存。
采用编译器重排指令是采用软件方法的方式,这和采用硬件支持乱序执行的方式相比,还有其他的优势。编译器比硬件可以看到程序程序更远的地方,它可以同时对多条执行路径进行推测而不是仅仅一条,这在分支不可预测时采用硬件的方式是个大问题。另一方面,大家都不指望处理器是全能的,所以处理器不必什么都是完没的。要是没有乱序执行的硬件,当编译器不能正确预测一些事情的时候,比如缓存不中,流水线将会挂起等待。
多数早期的超标量处理器采用的设计方式是有序的,比如SuperSPARC, hyperSPARC, UltraSPARC, Alpha 21064 & 21164, the original Pentium。早期采用乱序设计的处理器有MIPS R10000, Alpha 21264,以及整个带保留栈的POWER/PowerPC系列。如今,除了UltraSPARC III/IV, POWER6 和 Denver处理器外,几乎所有高性能处理器都采用乱序执行的方式。多数耗电低,性能低的处理器,比如Cortex-A7/A53 和 Atom,都是采用执行的设计方案,因为乱序执行的方式需要消耗很多的电能但是能够获得的性能提升却相对太小。