Mysql高级篇知识点,全篇手打,大家觉得有用的话点一个赞,持续更新
目录
1.Mysql锁的机制:粒度分类,思想分类,实现分类,状态分类,算法分类
2.Mysql的隔离级别:读未提交,读已提交,可重复读,串行化,脏读,不可重复读,幻读,解决办法
3.Mysql的索引:树->二叉树->BST二叉查找树->AVL平衡查找树->红黑树->B树(B-树)->B+树
4.B+树存储结构:
5.索引失效:
1.Mysql锁的机制:
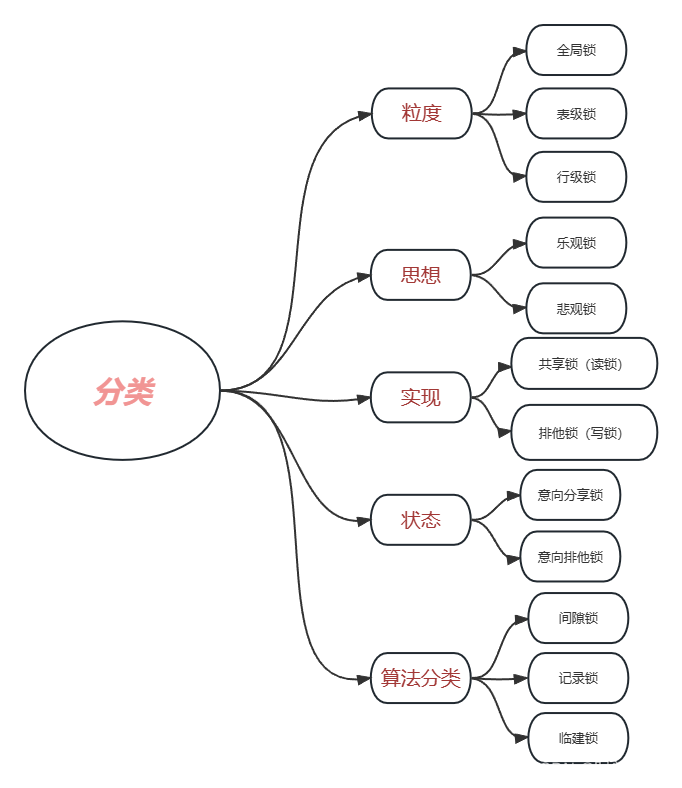
如上图所示我们将锁分为了五大部分进行理解,如果按照网上大多数博主那样上来一直说大白话显得很难读懂,索性我们按照分类来进行记忆,这样会显得更加清晰明了。
粒度分类:
全局锁:
定义:全局锁是对整个数据库实例加锁,它可以确保整个数据库处于只读状态,防止并发的写操作。
为什么要存在全局锁?
场景:当前我们需要对整个数据库表进行导出(假设当前以银行为背景,并且没有加全局锁),在我们导出sql文件的一瞬间,有人进行了消费,转账改变了原表数据(原用户表金额属性发生了变化),那么请问当前导出的sql文件是改呢?还是不改呢?
应用:
所以我们加上了全局锁就可以防止在导出表,或者恢复表的时候其他DDL语句对数据进行改变。
表级锁:
定义:表级锁是对数据表加锁,可以是读锁(共享锁)或写锁(排他锁)的形式。读锁之间不互斥,多个事务可以同时持有读锁;(在MYISAM中读操作,会自动加上读锁,写操作自动加上写锁,因为这个引擎不支持事务,所有他会加强行锁来保证稳定性,而在InnoDB中必要情况下会用表锁,大多情况用的是行锁,这个后面会解释)
为什么要存在表级锁?
在大多情况下用不着将全局整个数据库进行加锁,我们可能只需要对某个经常读写的表进行加锁即可,那么我们就会选择粒度小一点的表级锁。
应用:
1.读密集型应用(读多写少的时候)
2.数据量比较小
3.全表更新或删除
缺点:
1.降低性能(因为锁了整个表,当并发量高的时候会很慢,因为大家都在等)
2.锁超时(当一些操作长时间无法进行提交的时候)
3.死锁(两线程互相锁)
行级锁
定义:行级锁是对某行数据加锁,其他事务可以访问表中其他行而不被阻塞。行级锁可以是共享锁或排他锁,类似于读锁和写锁的概念,但是行级锁是针对单行数据的。(粒度最小,死锁发生概率最大,CPU和资源耗费最多的一个锁)
为什么要存在行级锁?
适用于高并发环境下对数据库中特定行进行读写操作,可以提高并发性能。
应用:
1.高并发读写
2.单行操作
3.insert.update.delete,这些操作都会有行锁(排他锁)
缺点:
1.锁冲突(会比上面行锁小一点)
2.死锁
3.内存消耗(cpu和资源是最大的,因为粒度最细)
思想分类:
所谓的乐观锁和悲观锁不过是一种思想。
乐观锁
定义:主打一个乐观,认为不会发生冲突,所以任何时候都不加锁,当多操作同时对一个数据进行修改的时候,能否成功修改在于修改时的version和修改前的version是否相同来保证,如果相同则进行修改并让version进行加一,如果不同则进行回滚重新等下一次操作机会(数据库里面没有乐观锁的具体实现,我们一般用版本号version进行判断,初始值为零,每次修改成功进行加一,version也是我们建立用户表或者商品表的一个重要字段)
优点:
当并发量小的时候速度很快,因为我们任何时候都没有加锁,所以执行速度就会比较快
缺点:
相对于优点来说,如果并发量大的时候,同一时间涌进来了大量数据,但是一瞬间只有一个操作可以进行实现,其他的都需要等待,这个时间就会非常长。
应用:
比如说用户表,对于用户表来说大多时间我们都是一种读的形式,很少改,所以我们可以采用建立用户表的时候加入一个version字段进行乐观锁的表示。
悲观锁(并发机制)
定义:主打一个悲观,认为任何时候都会发生冲突,所以任何时候都会进行加锁,当多操作对同一数据修改的时候,可以保证数据的安全性和可靠性(mysql有实现方式,共享锁和排他锁都可以)
优点:
1.数据安全性(串行化)
2.实现简单
缺点:
1.在并发情况下,大家会直接等,然后一个一个来
2.锁冲突和死锁风险高
应用:
强一致性的时候,这个是优于乐观锁的,因为乐观锁说白了是用回滚,而悲观锁是直接强行锁住一个一个来。
实现分类:
共享锁(S锁/读锁),排他锁(X锁/写锁)--------这两个锁也是我们用的最多的两个锁
共享锁
定义:阻止用户进行更新修改数据,只允许读取数据。
特点:
共享锁允许多个事务同时持有锁,用于读操作。共享锁之间不会互斥,多个事务可以同时读取同一数据,不会互相干扰。
优点:
共享锁适用于并发度较高的读操作场景,可以提高并发性能。
缺点:
在持有共享锁的情况下,其他事务无法获取排他锁,从而阻塞了写操作的执行。
应用:
共享锁常被用于多个事务并发读取数据的情况,例如读取数据的查询操作。多个事务可以共享对数据的读取权限,不会相互冲突。
排他锁
定义:阻止用户进行读取数据,只允许修改操作数据。
特点:
排他锁只允许独占访问,用于写操作。在一个事务持有排他锁期间,其他事务无法获取共享锁或排他锁,从而确保数据的独占性。
优点:
排他锁适用于独占式的写操作,保证了数据的一致性和完整性。
缺点:
在持有排他锁的情况下,其他事务无法读取或修改数据,从而对并发性能产生影响。
应用:
排他锁常被用于修改数据的操作,例如插入、更新或删除操作。事务持有排他锁时,其他事务无法同时进行写操作,防止数据的并发冲突。
状态分类:
其实主要就是在实现(排他锁和共享锁)上加了一个意向锁,它是一个表锁,为了协调行锁和表锁的关系,支持多粒度(行锁和表锁)共存。
作用:当事务A已经存在行锁的时候,mysql会自动为其增加一个意向锁,事务B如果想申请表级写锁,那么就不需要在遍历每一行是否有行锁(因为表级写锁和行级写锁不共存),直接判断是否存在意向锁即可,大大提高了时间效率(如果没有意向锁,那么就会循环遍历,浪费时间)
算法分类:
间隙锁,记录锁,临建锁都与行级锁是相关的(行锁依赖于索引,如果没有索引就会自动退化为表级锁)。
间隙锁
定义:是一种用于并发控制的锁类型,用于锁定索引键之间的间隙,以防止其他事务在该间隙内插入新记录。间隙锁基于
非唯一索引,它锁定一段范围内的索引记录。请务必牢记:使用间隙锁锁住的是一个区间,而不仅仅是这个区间中的每一条数据((1,10)-->2.3.4.5.6.7.8.9行数据插入就会堵塞)。特点:
它用于避免幻读(Phantom Read)问题,解决范围查询。
记录锁
定义:锁用于锁定数据库中的单个记录,以防止其他事务修改或删除该记录,是一种行级锁。
特点:
select * from table where id = 1 for update;
id为1的记录就会被锁住(id列必须是唯一索引或者主键列,而且只能精准匹配(=,不能为>.<.like),负责上述锁就会成为临建锁)
正常情况下我们进行单行的增删改查都会加上记录锁的(安全性,可靠性)。
临建锁
定义:每个数据行的非唯一索引上都会存在一把临建锁,当某个事物持有该数据行的临建锁时,会锁住一段左开右闭区间的数据。(可以理解为一种特殊的间隙锁,临建锁只与非唯一索引有关,在唯一索引上不存在临建锁。
特点:
临建锁锁定当前记录和下一条间隙,确保查询结果的准确性和可重复性,避免了其他事务在查询范围内插入新的数据行。
2.Mysql的隔离级别
隔离级别一般是对于事务(ACID)而言
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| 读未提交 | * | * | * |
| 读已提交 | * | * | |
| 可重复读 | * | ||
| 串行化(序列化) |
四个隔离级别(在事务A和事务B的背景下):
读未提交:事务A读到了事务B还未提交的数据 (存在脏读,不可重复读,幻读)
| 事务A(START TRANSACTION) | 事务B(START TRANSACTION) |
|---|---|
| select name from table where id = ‘1’(结果是‘wangwu’) | |
| update table set name = ‘lisi’ where id = ‘1’ | |
| select name from table where id = ‘1’(结果是‘lisi’) | |
| commit | commit |
读已提交:事务A读到了事务B已经提交的数据 (存在不可重复读,幻读)
| 事务A(START TRANSACTION) | 事务B(START TRANSACTION) |
|---|---|
| select name from table where id = ‘1’(结果是‘wangwu’) | |
| update table set name = ‘lisi’ where id = ‘1’ | |
| select name from table where id = ‘1’(结果是‘wangwu‘) | |
| commit | |
| select name from table where id = ‘1’(结果是‘lisi‘) | |
| commit |
可重复读:确保一个事务中的查询操作在整个事务期间始终返回一致的结果,即在同一事务内多次查询相同的数据会得到相同的结果。(存在幻读)
| 事务A(START TRANSACTION) | 事务B(START TRANSACTION) |
|---|---|
| select name from table where id >= 1 and id <=10(结果是5条数据) | |
| insert into table values('6','zhangsan') | |
| select name from table where id >= 1 and id <=10(结果是6条数据) | |
| commit | |
| select name from table where id >= 1 and id <=10(结果是6条数据) | |
| commit |
串行化:让所有事务串行进行操作,那么肯定就不会有任何问题了,但是对于系统性能来说会让其大大降低,因为大家都在排队进行操作,当并发量高的时候就会非常慢。
| 事务A(START TRANSACTION) | 事务B(START TRANSACTION) |
|---|---|
| select name from table where id = 1 | |
| select name from table where id = 1(等待) | |
| 返回结果为name=’lisi‘ | 等待...... |
| commit | 返回结果为name=’lisi‘ |
| commit |
那么对于上述问题的脏读,不可重复读,幻读我作以下解释:
脏读:就是读到了脏数据,也就是别人还没有提交到的数据。
不可重复读:指对于单条数据来说,我们第一次读和第二次读到的数据不一样,因为在第二次读之前,其他事务对该数据进行了增删改的操作,使其发生了变化。
幻读:对于一个范围集来说,第一次我们查询id为1-10之间的数据总共是5条,第二次我们查询id为1-10之间的数据总共为6条,因为在第二次查询之前,其他事务对该范围数据进行了增删的操作,使得其发生了变化。
解决办法:
因为mysql在innodb引擎下,默认是可重复读的隔离级别,所以就已经避免了脏读和不可重复读,那么就剩余了幻读,上面的加锁我已经介绍过了,幻读可以用行级锁(间隙锁,临建锁)来进行避免,所以我们需要在特定情况下加入特定锁即可。
3.Mysql的索引
介绍:
索引是Mysql里面很重要的一个概念,数据库crud速度完全依靠于索引建立,举一个很简单的例子,当你select * from table where id = ‘123’,如果没有索引就是全表扫描,一行一行遍历(行式存储时),直到遍历到需要的行时才会停止,时间复杂度为o(n),但我们如果有索引(BTREE、HASH),按照树的规则遍历则只需要o(logn)即可
优点:
1.所有的MySql列类型(字段类型)都可以被索引,也就是可以给任意字段设置索引
2.查询快,避免了全表扫描
3.加快排序(order by)和连接操作(union,join)
4.优化数据访问,减少i/o磁盘读写(在innodb的引擎下,我们是需要将磁盘的存储信息拿取到内存进行查询计算)
缺点:
1.索引也会占用内存,对于大型表或拥有多个索引的数据库,索引所占的存储空间可能会相当可观。
2.索引维护,数据的更新和变化,为了保证索引的有效性和一致性,索引也需要变化,所以对于写的消耗也会增加,频繁更新操作的表,索引的维护成本就会比较高
3.索引的复杂性,设计良好的索引是不容易的(错误的索引设计可能会使得查询性能下降)。
使用原则:
1、对经常更新的表就避免对其进行过多的索引,对经常用于查询的字段应该创建索引,
2、数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
3、在一同值少的列上(字段上)不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在一个字段上不同值较多可是建立索引。
我们对于Mysql在InnoDb引擎(5.1版本之后默认是)的情况下,使用的B+树索引,下面我们将介绍B+树到底是什么?
介绍B+树之前我引出一些其他存储索引的概念:
1.hash
2.树->二叉树->BST二叉查找树->AVL平衡查找树->红黑树->B树(B-树)->B+树
Hash:
引言:众所周知,我们java在jdk-8之后对于hash表的存储引入了红黑树的概念,在单节点哈希冲突的次数超过8的时候,单节点的链表底层就会扩展为红黑树,加速我们查找,因为默认对于链表查询时间复杂度是o(n),而树的查找时间复杂度是o(logn)。
那么为什么我们不用hash来作为Mysql的索引呢?
1.这是因为首先hash冲突(我们暂且不谈论数据库的数据量很小的时候),会在hash单节点下面形成链表,那么当hash冲突很多的时候,虽然查找单节点hash(x)只需要o(1),但是节点后面的链表查找数据确实o(n)的时间复杂度,所以总的时间复杂度还是接近于o(n)
。
2.无法进行范围查询,你想一想hash表的结构怎么进行范围查询。
普通的树,二叉树:
这就更不用说了,完全不行,连最基础的排序都没有,时间复杂度也是o(n)
BST二叉查找树:
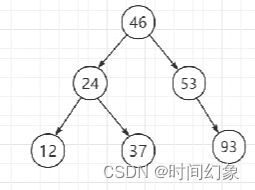
对于普通树的升级版,我们引入了顺序的概念:
最开始我们是这样想的,比根节点小的放在根节点的左边,比根节点大的放在根节点的右边(左小右大原则),看下面这张图,也就是对于数据12,24,37,46,53,93这几个节点进行了BST的构建,大家发现这个可以啊,有顺序,那么可以作为索引吗?不可以,为什么?按照正常逻辑我们数据库表的构建,主键一般都是auto自增的,并且人为不去干涉,这时候就会涉及到一个问题。
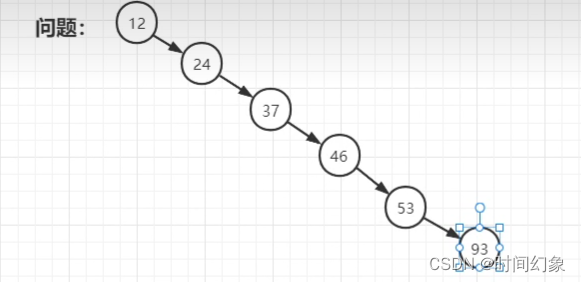
当我们顺序插入节点的时候,BST就会形成链表的结构,看下图,这个问题无疑是致命的,所以BST也不能用
AVL平衡查找树:
对于BST的加强版,我们引入了引入了平衡因子学过数据结构的都应该知道,深入的不需要了解(利用了平衡因子,R旋转,L旋转使得树的左子树和右子树深度是大体平衡的,左右子树高度差不能大于一),大体意思就是将原来的特殊情况进行了处理,并且使得树的结构永远是再平衡的状态。
但是这个时候出现了一个新的问题,如果我们插入的数据无规律,那么就会一直出现不平衡-再平衡这个过程,这个R/L旋转就会浪费很多的时间(当然了如果查询多的情况下,性能也还不错)
红黑树:
那么这个时候红黑树登场了,解决了AVL平衡查找树的多旋转问题,深度的不用了解,大体意思说可以不用旋转那么多次,也可以保持树的平衡。
但这时候还是出现了一个问题,众所周知我们的索引肯定是存储再磁盘的,而不是存在内存里面,所以我们CPU调度的时候需要将磁盘的内容通过I/O操作拉取到内存,这个时间耗费是不小的,而且当树的深度越深,我们需要的I/O次数就会越多,操作系统告诉我们磁盘读取是根据Page大小进行读取(局部优先性)。
我们对于磁盘存储进行一个介绍
| 磁盘分类 | HDD磁盘 | SDD磁盘 |
| 读写速度 | 稍快 | 快 |
| 造价 | 正常 | 高 |
| 读写规则 | 单块读取 | 局部优先性读取 |
| ...... | ....... | ...... |
下面演示一个磁盘块的读取过程
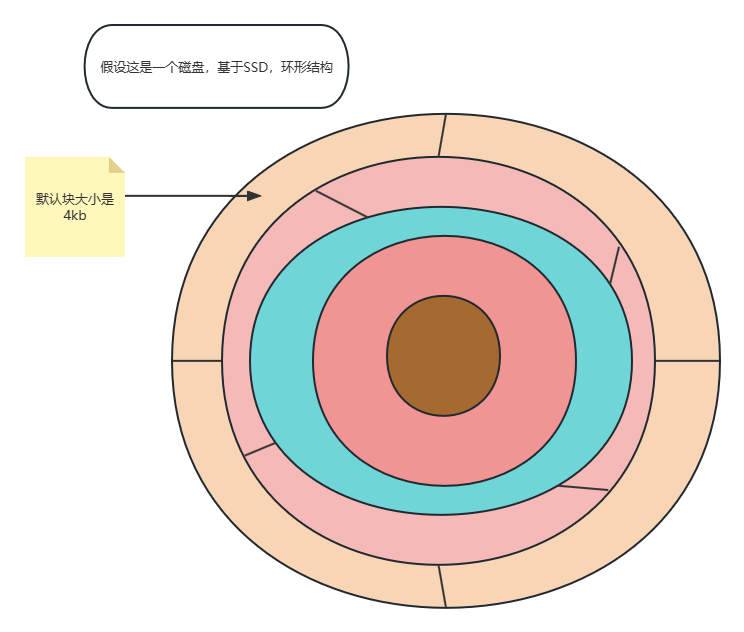
当我们数据存储在磁盘里面的时候,我们读取数据一般是将数据拉取到了内存进行读取,计算机有一个著名的原理叫做局部优先性,当我们读取到了磁盘的这个位置的数据时,我们通常认为它旁边的数据是很大概率被下次用到的,所以我们就会将周围数据一并带出,那么读取到的就是一个数据块(SSD磁盘默认大小是4kb)
B树:
引言:所以这个时候我们就必须把树的层数给降低下来,想到了一个办法,不论是红黑树还是AVT或者是BST都是二叉树啊,那么我们存储n个节点就需要logn深度的树取存储,所以我们想到了一个方法,将节点用多路去描述,引出了一个重要的概念多路查询树
这个时候就出现了B树(说一个题外话,这个B树有一个很奇葩的故事,这个B树本身是国外的程序员先发现的,于是人家命名为B-Tree,而我们国内的翻译版给翻译成了B-树,其实人家本名就是叫B树,所以我们选择所说的B-树和B树其实是同一个东西),言归正传,我们B树解决了什么问题呢?
用更矮的树去构造查找树,从而解决磁盘I/O问题,看似是不是已经解决了这个索引的存储问题,其实还差一点,因为按照我们之前的概念,每一个节点都存储数据和索引,而innodb引擎是默认Page大小是16kb,也就是说正常情况下我们一个Page也就存储(假设一行数据库的数据是1kb,我们忽略其他开始索引和结束索引)16行信息,而且B树有一个特征是m源多路查询树最多有m-1个源点,这就导致了,B树在存储更多数据的时候还是会出现树的层数偏高(但比红黑树有了较大的好转)。
所以接下来就引出了B+树。
B+树:
在B树的基础上增加了一个思想,非叶子节点只存储索引,而叶子节点存储data信息,这个想法一下就解决了树深度的问题,使得B+树成为了一个真正意义上的”矮树“。
下面我们着重介绍B+树存储结构:
引言:
想象一下,如果我们不用索引查询数据的时候会是什么样子呢?
select * from table where id = '1'
我们会对整体数据一行一行进行遍历,那么需要的时间就是o(n),数据量小的话还好说,如果一旦多并且复杂的时候那么就会特别的慢,所以引入了B+树来构建mysql的索引。
规则:
根据上面的磁盘读写规则,我们了解到了块存储的概念,因为索引或者说是数据都是存储在磁盘(在innodb的引擎下),当读写的时候会将磁盘数据读取到内存进行读写,那么innodb默认的块大小是16kb。
假设:
假设我们用BigInt存储索引,默认BigInt占6B,假设Key(存储指向Page的部分信息,主键的大小为8B),那么它两合起来是14B,对于一个大小为16kb的Page来说,默认可以存1170条索引,假设数据库表中一行数据大小是0.5kb,那么一个Page就可存储32行数据。

上面就是一个普通的B+树的结构,现在我对于里面每一个节点进行解释:
首先根节点:
我们需要知道B+树的插入规则:
假设:
我们现在新建了一个表,新建了一个主键(B+树默认对主键进行索引构建,当我们表没有设置主键的时候,对设置unique的属性进行构建,如果这个也没有,那么mysql会默认给我们一个主键,只不过我们看不到)。
现在我们插入数据:insert into table values(........)*200,插入了200行
B+树的构建规则主要是对索引的构建,我们拿出一个Page1(16kb)往里面插入数据,插入慢了之后,复制一个同等大小的空白Page2,将Page1数据完全进行转移至Page2里面,然后将Page1的数据清空,放至索引(这个索引需要指向Page2),并将Page1作为根节点,重复上述过程。
所以最后就成了上面图像的情况
对于根节点:
| key | 1 | 33 | 65 | ...... | 1170*32 |
| 索引 | 1 | 2 | 3 | ...... | 1170 |
对于叶子节点1来说(内部是链表存储):
| key | 1 | 2 | 3 | ...... | 32 |
| data | 一行数据(假设是行存储) | 一行数据(假设是行存储) | 一行数据(假设是行存储) | ...... | 一行数据(假设是行存储) |
然后根节点的索引1就指向了叶子节点1
叶子节点之间是双向链表(好处肯定比单向链表快多了,比如说范围查询),叶子节点内部是单向链表进行连接(因为增删改的场景多,所以比普通的顺序表好用一些)
根据上述树的结构我们可以清楚的看到,仅仅需要两层结构就可以存储1170*32(37440行数据),效率是很高的,这仅仅只是一级索引,如果是二级索引可以存储1170*1170*32(4000w行数据,三层树结构)。
对于B+树的一个总结(B+树只有在叶子节点存储data,其他非叶子节点只存储索引):
为什么矮树效率更呢?
因为树矮,那么我们需要的磁盘I/O操作就少,几层树结构我们就需要几次I/O操作,就比如select * from table where id = "1000"
步骤(这是一级索引--二层):
1.从磁盘取出根节点的Page页(第一次I/O)
2.缓存在内存中,读取根节点信息,发现id为1000的数据在Page32中
3.读取Page32(第二次I/O)
4.返回信息
如果是二级索引--三层:
1.从磁盘取出根节点的Page页(第一次I/O)
2.缓存在内存中,读取根节点信息,发现id为1000的数据在Page32中
3.读取Page32(第二次I/O)分析Page32发现在Page100中
4.读取Page100(第三次I/O)
5.返回信息
为什么不用二叉树呢?
这很明显了,虽然二叉树对于查找来说可能更适合更快速,B+树是m叉的多路平衡查找树,但是我们不应该至看重于查找速度,更多消耗其实是我们磁盘I/O时间,上面解释矮树的时候就已经说明白了,因为树越高,对于磁盘的I/O读写就会越耗费时间,传统的二叉树,总共n个节点,那么树的高度就是logn,而一般的B+树最多也就是四层结构吧(四层基本可以存储千亿级别的数据了)
索引失效:
我们了解了B+树之后对于索引失效应该是比较好理解了。
1.组合索引(最左原则):当我们查询where id = 1 and age =18 字段时,左边的id一定要是具有索引的,因为我们的B+树在构建联合索引的时候(id,age),是先按照左边的字段进行排序,当左边字段一样的时候,按照右边字段进行排序。这就导致了我们如果左边不是索引就根本没法查找
2.模糊匹配:where nam like ’%san‘,模糊匹配肯定也是不行的
3.where id = ’1‘ or age = ’18‘,这样肯定也是不行的
4.当我们使用了in/or时,可能我们的innodb引擎觉得不需要跑索引那么也就可以不用了,eg:当我们数据库的大小总共200行,我们where name in(.........100条),那我们一次性取了一般,这走索引还不如不走
5.我们使用了mysql的函数,破坏了原本的索引结构,比如lower(name),将名字小写化了。
.......