静态资源
- 静态资源的配置指令
- 静态资源优化配置
- 静态资源压缩
- Gzip模块配置指令
- Gzip压缩功能的实例
- Gzip和sendfile共存问题
- gzip_static测试使用
- 静态资源的缓存处理
- 浏览器缓存相关指令
- Nginx的跨域问题解决
- 静态资源防盗链
- 防盗链的实现原理
- 防盗链的具体实现
上网搜索访问资源是通过浏览器发送一个HTTP请求实现从客户端发送请求到服务器端获取所需要内容后并把内容回显展示在页面。这时所请求的内容就分为两种类型,一类是静态资源、一类是动态资源。
静态资源: 指在服务器端真实存在并且能直接拿来展示的一些文件,比如常见的html页面、css文件、js文件、图 片、视频等资源。
动态资源: 指在服务器端真实存在但是要想获取需要经过一定的业务逻辑处理,根据不同的条件展示在页面不同这 一部分内容,比如说报表数据展示、根据当前登录用户展示相关具体数据等资源。
Nginx处理静态资源的内容,需要考虑下面这几个问题:
- 静态资源的配置指令
- 静态资源的配置优化
- 静态资源的压缩配置指令
- 静态资源的缓存处理
- 静态资源的访问控制,包括跨域问题和防盗链问题
静态资源的配置指令
listen指令: 配置监听的端口
| 语法 | listen address[:port] [default_server]…; listen port [default_server]…; |
|---|---|
| 默认值 | listen *:80 | *:8000 |
| 位置 | server |
listen的设置比较灵活,常用的设置方式如下:
# 监听指定的IP和端口
listen 127.0.0.1:8000; // listen localhost:8000
# 监听指定IP的所有端口
listen 127.0.0.1;
# 监听指定端口上的连接
listen 8000;
# 监听指定端口上的连接
listen *:8000;
default_server: 此虚拟主机设置成默认主机
默认主机指如果没有匹配到对应的address:port,则会默认执行的。如果不指定默认使用的是第一个server。
访问192.168.221.199:8080匹配127.0.0.1:8080匹配不到,访问默认主机为第一个server127.0.0.1:8080
server{
listen 8080;
server_name 127.0.0.1;
location /{
root html;
index index.html;
}
}
访问192.168.221.199:8080匹配127.0.0.1:8080匹配不到,访问默认主机为配置的localhost:8080
server{
listen 8080;
server_name 127.0.0.1;
location /{
root html;
index index.html;
}
}
server{
listen 8080 default_server;
server_name localhost;
default_type text/plain;
return 444 'This is a error request';
}
server_name指令: 设置虚拟主机服务名称,可以是ip或者域名
127.0.0.1 、 localhost 、域名[www.baidu.com | www.jd.com]
| 语法 | server_name name …; name可以提供多个中间用空格分隔 |
|---|---|
| 默认值 | server_name “”; |
| 位置 | server |
方式一:精确匹配
server {
listen 80;
server_name www.nginx521.cn;
...
}
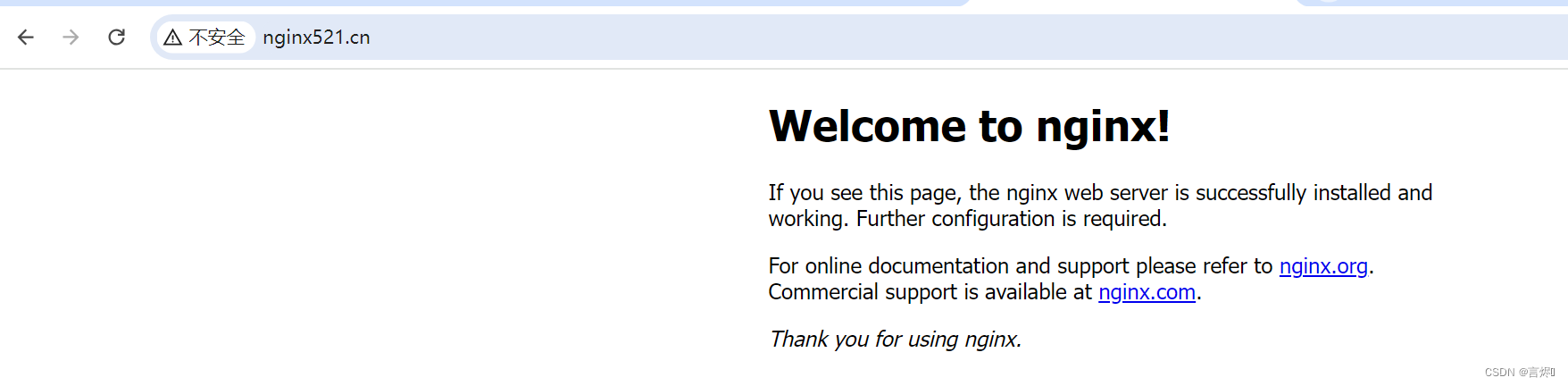
修改本机host文件:

可以直接访问:http://www.nginx521.cn/
hosts是一个没有扩展名的系统文件,可以用记事本等工具打开,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从hosts文件中寻找对应的IP地址,一旦找到,系统会立即打开对应网页,如果没有找到,则系统会再将网址提交DNS域名解析服务器进行IP地址的解析。
windows:C:\Windows\System32\drivers\etc
centos:/etc/hosts
因为域名是要收取一定的费用,所以可以使用修改hosts文件来制作一些虚拟域名来使用,修改 /etc/hosts文件来添加:
vim /etc/hosts
127.0.0.1 www.itcast.cn
127.0.0.1 www.itheima.cn
方式二:使用通配符配置
server_name中支持通配符 " *",但需要注意的是通配符不能出现在域名的中间,只能出现在首段或尾段,如:
server {
listen 80;
server_name *.itcast.cn www.itheima.*;
# www.itcast.cn abc.itcast.cn www.itheima.cn www.itheima.com
...
}
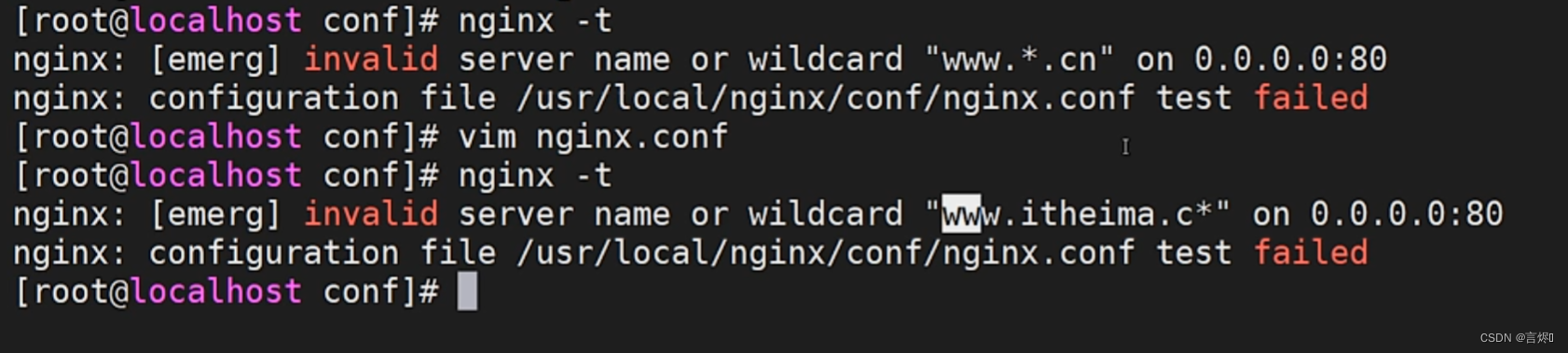
下面的配置就会报错:
server {
listen 80;
server_name www.*.cn www.itheima.c*
...
}
配置方式三:使用正则表达式配置
server_name中可以使用正则表达式,并且使用~作为正则表达式字符串的开始标记。
常见的正则表达式:
| 代码 | 说明 |
|---|---|
| ^ | 匹配搜索字符串开始位置 |
| $ | 匹配搜索字符串结束位置 |
| . | 匹配除换行符\n之外的任何单个字符 |
| \ | 转义字符,将下一个字符标记为特殊字符 |
| [xyz] | 字符集,与任意一个指定字符匹配 |
| [a-z] | 字符范围,匹配指定范围内的任何字符 |
| \w | 与以下任意字符匹配 A-Z a-z 0-9 和下划线,等效于[A-Za-z0-9_] |
| \d | 数字字符匹配,等效于[0-9] |
| {n} | 正好匹配n次 |
| {n,} | 至少匹配n次 |
| {n,m} | 匹配至少n次至多m次 |
| * | 零次或多次,等效于{0,} |
| + | 一次或多次,等效于{1,} |
| ? | 零次或一次,等效于{0,1} |
配置如下:
server{
listen 80;
server_name ~^www\.(\w+)\.com$;
default_type text/plain;
return 200 ‘===>access===>$1’;
}
注意: ~后面不能加空格,括号可以取值


匹配执行顺序
由于server_name指令支持通配符和正则表达式,因此在包含多个虚拟主机的配置文件中,可能会出现一个名称被多个虚拟主机的server_name匹配成功,当遇到这种情况,当前的请求交给谁来处理呢?
-- 正则表达式
server{
listen 80;
server_name ~^www\.\w+\.com$;
default_type text/plain;
return 200 'regex_success';
}
-- 后通配符
server{
listen 80;
server_name www.itheima.*;
default_type text/plain;
return 200 'wildcard_after_success';
}
-- 前通配符
server{
listen 80;
server_name *.itheima.com;
default_type text/plain;
return 200 'wildcard_before_success';
}
-- 精确匹配
server{
listen 80;
server_name www.itheima.com;
default_type text/plain;
return 200 'exact_success';
}
-- 默认server
server{
listen 80 default_server;
server_name _;
default_type text/plain;
return 444 'default_server not found server';
}
结论:
exact_success
wildcard_before_success
wildcard_after_success
regex_success
default_server not found server!!
No1:准确匹配server_name
No2:通配符在开始时匹配server_name成功
No3:通配符在结束时匹配server_name成功
No4:正则表达式匹配server_name成功
No5:被默认的default_server处理,如果没有指定默认找第一个server
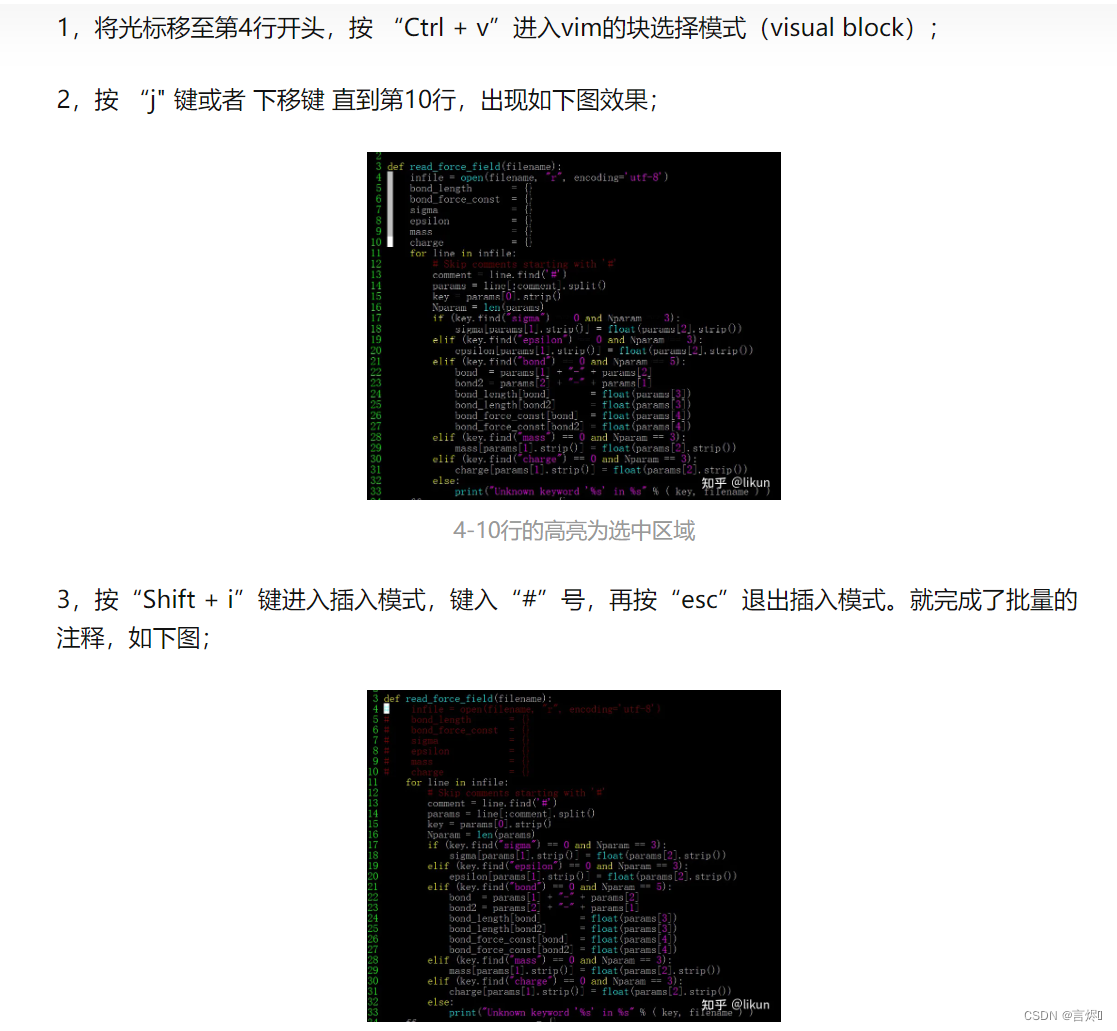
vim批量注释:
location指令: 用来设置请求的URI
-- 用户的请求发送到后台以后匹配对应的listen和server_name,匹配成功后会讲请求交给location处理
server{
listen 80;
server_name localhost;
location / {
}
location /abc{
}
...
}
location语法:
| 语法 | location [ = | ~ | ~* | ^~ |@ ] uri{…} |
|---|---|
| 默认值 | — |
| 位置 | server,location |
uri变量是待匹配的请求字符串,可以不包含正则表达式,也可以包含正则表达式,nginx服务器在搜索匹配location的时候,先使用不包含正则表达式进行匹配,找到一个匹配度最高的一个,然后再通过包含正则表达式的进行匹配,如果能匹配到直接访问,匹配不到,就使用刚才匹配度最高的那个location来处理请求。
- 不带符号,要求必须以指定模式开始
server {
listen 80;
server_name 127.0.0.1;
location /abc{
default_type text/plain;
return 200 "access success";
}
}
以下访问都是正确的
http://192.168.200.133/abc
http://192.168.200.133/abc?p1=TOM
http://192.168.200.133/abc/
http://192.168.200.133/abcdef
- = : 用于不包含正则表达式的uri前,必须与指定的模式精确匹配
server {
listen 80;
server_name 127.0.0.1;
location =/abc{
default_type text/plain;
return 200 "access success";
}
}
可以匹配到
http://192.168.200.133/abc
http://192.168.200.133/abc?p1=TOM
匹配不到
http://192.168.200.133/abc/
http://192.168.200.133/abcdef
- ~ : 用于表示当前uri中包含了正则表达式,并且区分大小写
- ~*: 用于表示当前uri中包含了正则表达式,并且不区分大小写
换句话说,如果uri包含了正则表达式,需要用上述两个符合来标识
server {
listen 80;
server_name 127.0.0.1;
location ~^/abc\w${
default_type text/plain;
return 200 "access success";
}
}
server {
listen 80;
server_name 127.0.0.1;
location ~*^/abc\w${
default_type text/plain;
return 200 "access success";
}
}
- ^~: 用于不包含正则表达式的uri前,功能和不加符号的一致,唯一不同的是,如果模式匹配,那么就停止搜索其他模式了。
server {
listen 80;
server_name 127.0.0.1;
location ^~/abcd{
default_type text/plain;
return 200 "abcd access success";
}
location ~*^/abc\w${
default_type text/plain;
return 200 "access success";
}
}
匹配顺序:
第一、=是精准,第二是正则,第三是/ 指定模式
设置请求资源的目录root / alias
root: 设置请求的根目录
| 语法 | root path; |
|---|---|
| 默认值 | root html; |
| 位置 | http、server、location |
path为Nginx服务器接收到请求以后查找资源的根目录路径。
alias: 用来更改location的URI
| 语法 | alias path; |
|---|---|
| 默认值 | — |
| 位置 | location |
path为修改后的根路径。
以上两个指令都可以来指定访问资源的路径,那么这两者之间的区别是什么?
举例说明:
1.在/usr/local/nginx/html目录下创建一个 images目录,并在目录下放入一张图片mv.png图片
server {
listen 80;
server_name localhost;
location /images {
root html;
}
访问图片的路径为:http://192.168.200.133/images/mv.png
2.如果把root改为alias
server {
listen 80;
server_name localhost;
location /images {
alias html;
}
再次访问上述地址,页面会出现404的错误,查看错误日志会发现是因为地址不对,

所以验证了:
root的处理结果是: root路径+location路径
/usr/local/nginx/html/images/mv.png
alias的处理结果是:使用alias路径替换location路径
/usr/local/nginx/html/mv.png
需要在alias后面路径改为
location /images {
alias html/images;
}
3.如果location路径是以/结尾,则alias也必须是以/结尾,root没有要求,将上述配置修改为
server {
listen 80;
server_name localhost;
location /images/ {
alias /usr/local/nginx/html/images;
}
访问就会出问题,查看错误日志还是路径不对,所以需要把alias后面加上 /
server {
listen 80;
server_name localhost;
location /images/ {
alias /usr/local/nginx/html/images/;
}

小结:
root的处理结果是: root路径+location路径
alias的处理结果是:使用alias路径替换location路径
alias是一个目录别名的定义,root则是最上层目录的含义。
如果location路径是以/结尾,则alias也必须是以/结尾,root没有要求
index指令: 设置网站的默认首页
| 语法 | index file …; |
|---|---|
| 默认值 | index index.html; |
| 位置 | http、server、location |
index后面可以跟多个设置,如果访问的时候没有指定具体访问的资源,则会依次进行查找,找到第一个为止,也可以设置图片。
举例说明:
location / {
root /usr/local/nginx/html;
index index.html index.htm 456.png;
}
访问该location的时候,可以通过 http://ip:port/,地址后面如果不添加任何内容,则默认依次访问index.html和index.htm,找到第一个来进行返回
error_page指令: 设置网站的错误页面
| 语法 | error_page code … [=[response]] uri; |
|---|---|
| 默认值 | — |
| 位置 | http、server、location… |
当出现对应的响应code后,如何来处理。
- 可以指定具体跳转的地址
server {
error_page 404 http://www.itcast.cn;
}
- 可以指定重定向地址
server{
# 发生404错误重定向到/50x.html
error_page 404 /50x.html;
error_page 500 502 503 504 /50x.html;
# 指定/50x.html的地址
location =/50x.html{
root html;
}
}
- 使用location的@符号可以展示错误信息
server{
error_page 404 @jump_to_error;
location @jump_to_error {
default_type text/plain;
return 404 'Not Found Page...';
}
}
=[response]的作用是用来将相应代码更改为另外一个
server{
error_page 404 =200 /50x.html;
location =/50x.html{
root html;
}
}
这样的话,当返回404找不到对应的资源的时候,在浏览器上可以看到,最终返回的状态码是200,这块需要注意下,编写error_page后面的内容,404后面需要加空格,200前面不能加空格
静态资源优化配置
Nginx对静态资源如何进行优化配置,从三个属性配置进行优化:
sendfile on;
tcp_nopush on;
tcp_nodeplay on;
- sendfile,用来开启高效的文件传输模式。
| 语法 | sendfile on |off; |
|---|---|
| 默认值 | sendfile off; |
| 位置 | http、server、location… |
请求静态资源的过程:客户端通过网络接口向服务端发送请求,操作系统将这些客户端的请求传递给服务器端应用程序,服务器端应用程序会处理这些请求,请求处理完成以后,操作系统还需要将处理得到的结果通过网络适配器传递回去。
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html;
}
}
在html目录下有一个welcome.html页面,访问地址
http://192.168.200.133/welcome.html
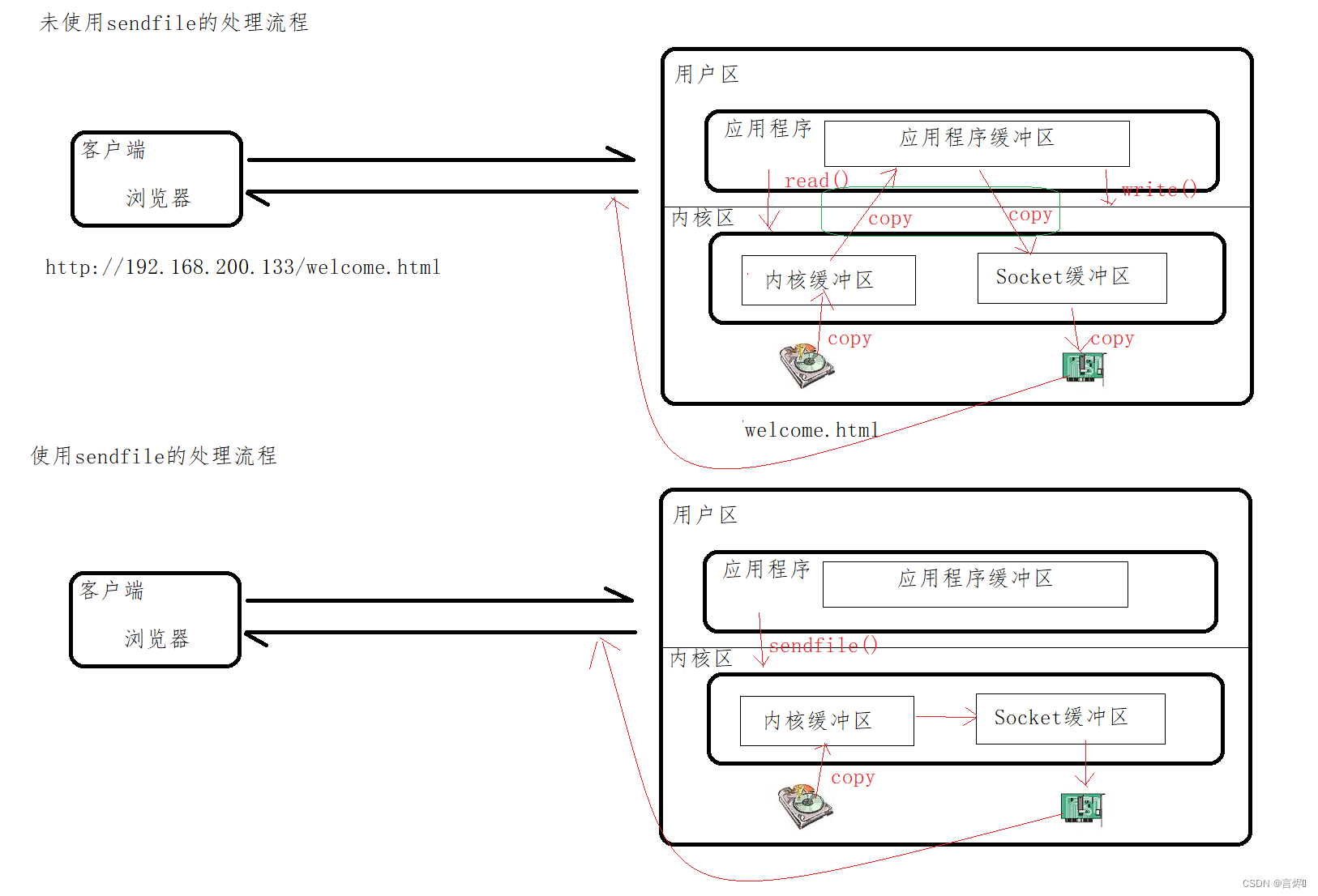
未使用sendfile的处理流程:
客户端在浏览器输入地址,按回车之后就会将请求发送给服务端。
应用程序要想访问磁盘的文件,首先应用程序给操作系统发送read()命令,操作系统将磁盘文件copy到内核缓冲区,再次copy到应用程序缓冲区。
要将取到的静态资源通过适配器传回,首先应用程序给操作系统发送write()指令,应用缓冲区的文件copy到socket缓冲区,再cpy到网卡,通过网络发送到客户端,客户端通过浏览器解析,就可以查看内容。
使用sendfile的处理流程:
客户端在浏览器输入地址,按回车之后就会将请求发送给服务端。
sendfile()是操作系统的底层函数,不需要再调用write()和read(),会指定从哪读取文件,交给哪个socket
应用程序给操作系统发送sendfile()命令,先从磁盘中找到指定资源,再copy到内核缓冲区,在内核区进行传递交给socket,再cpy到网卡,通过网络发送到客户端,客户端通过浏览器解析,就可以查看内容。
- tcp_nopush:该指令必须在sendfile打开的状态下才会生效,主要是用来提升网络包的传输’效率’(添加一个缓存区,存满后再发送)
| 语法 | tcp_nopush on|off; |
|---|---|
| 默认值 | tcp_nopush off; |
| 位置 | http、server、location |
- tcp_nodelay:该指令必须在keep-alive连接开启的情况下才生效,来提高网络包传输的’实时性’(有数据就发,不延迟)
| 语法 | tcp_nodelay on|off; |
|---|---|
| 默认值 | tcp_nodelay on; |
| 位置 | http、server、location |

经过刚才的分析,“tcp_nopush"和”tcp_nodelay“看起来是"互斥的”,那么为什么要将这两个值都打开,在linux2.5.9以后的版本中两者是可以兼容的,三个指令都开启的好处是,sendfile可以开启高效的文件传输模式,tcp_nopush开启可以确保在发送到客户端之前数据包已经充分“填满”, 这大大减少了网络开销,并加快了文件发送的速度。 然后,当它到达最后一个可能因为没有“填满”而暂停的数据包时,Nginx会忽略tcp_nopush参数, 然后,tcp_nodelay强制套接字发送数据。由此可知,TCP_NOPUSH可以与TCP_NODELAY一起设置,它比单独配置TCP_NODELAY具有更强的性能。所以我们可以使用如下配置来优化Nginx静态资源的处理。
sendfile on;
tcp_nopush on;
tcp_nodelay on;
静态资源压缩
假如在满足上述优化的前提下,传送一个1M的数据和一个10M的数据那个效率高?,答案显而易见,传输内容小,速度就会快。那么问题又来了,同样的内容,如果把大小降下来,我们脑袋里面要蹦出一个词就是"压缩",在Nginx的配置文件中可以通过配置gzip来对静态资源进行压缩,相关的指令可以配置在http块、server块和location块中,Nginx可以通过
ngx_http_gzip_module模块
ngx_http_gzip_static_module模块
ngx_http_gunzip_module模块
对这些指令进行解析和处理。
Gzip模块配置指令
接下来的指令都来在ngx_http_gzip_module模块,该模块会在Nginx安装的时候内置到Nginx的安装环境中,所以可以直接使用这些指令。
- gzip指令:开启或者关闭gzip功能
| 语法 | gzip on|off; |
|---|---|
| 默认值 | gzip off; |
| 位置 | http、server、location… |
注意只有该指令为打开状态,下面的指令才有效果
http{
gzip on;
}
- gzip_types指令:该指令可以根据响应页的MIME类型选择性地开启Gzip压缩功能
| 语法 | gzip_types mime-type …; |
|---|---|
| 默认值 | gzip_types text/html; |
| 位置 | http、server、location |
所选择的值可以从mime.types文件中进行查找,也可以使用"*"代表所有(图片视频再压缩 意义不大,text/html不用添加)
http{
gzip_types application/javascript;
}
- gzip_comp_level指令:该指令用于设置Gzip压缩程度,级别从1-9,1表示要是程度最低,要是效率最高,9刚好相反,压缩程度最高,但是效率最低最费时间。
| 语法 | gzip_comp_level level; |
|---|---|
| 默认值 | gzip_comp_level 1; |
| 位置 | http、server、location |
http{
gzip_comp_level 6;(建议)
}
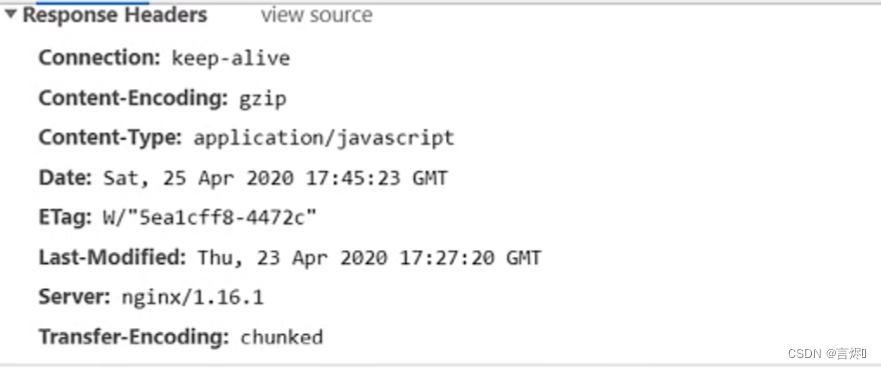
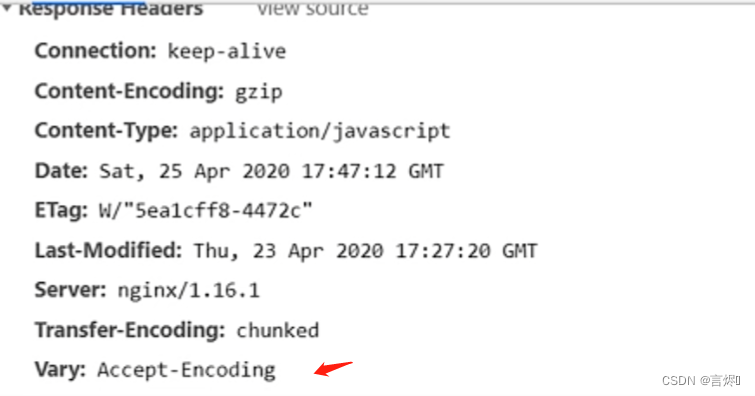
- gzip_vary指令:该指令用于设置使用Gzip进行压缩发送是否携带“Vary:Accept-Encoding”头域的响应头部。主要是告诉接收方,所发送的数据经过了Gzip压缩处理。
| 语法 | gzip_vary on|off; |
|---|---|
| 默认值 | gzip_vary off; |
| 位置 | http、server、location |
- gzip_buffers指令:该指令用于处理请求压缩的缓冲区数量和大小。
| 语法 | gzip_buffers number size; |
|---|---|
| 默认值 | gzip_buffers 32 4k|16 8k; |
| 位置 | http、server、location |
其中number:指定Nginx服务器向系统申请缓存空间个数,size指的是每个缓存空间的大小。主要实现的是申请number个每个大小为size的内存空间。这个值的设定一般会和服务器的操作系统有关,所以建议此项不设置,使用默认值即可。
gzip_buffers 4 16K; #缓存空间大小
- gzip_disable指令:针对不同种类客户端发起的请求,可以选择性地开启和关闭Gzip功能。
| 语法 | gzip_disable regex …; |
|---|---|
| 默认值 | — |
| 位置 | http、server、location |
regex:根据客户端的浏览器标志(user-agent)来设置,支持使用正则表达式。指定的浏览器标志不使用Gzip.该指令一般是用来排除一些明显不支持Gzip的浏览器。
gzip_disable "MSIE [1-6]\.";
- gzip_http_version指令:针对不同的HTTP协议版本,可以选择性地开启和关闭Gzip功能。
| 语法 | gzip_http_version 1.0|1.1; |
|---|---|
| 默认值 | gzip_http_version 1.1; |
| 位置 | http、server、location |
该指令是指定使用Gzip的HTTP最低版本,该指令一般采用默认值即可。
- gzip_min_length指令:该指令针对传输数据的大小,比该值小就不压缩,可以选择性地开启和关闭Gzip功能
| 语法 | gzip_min_length length; |
|---|---|
| 默认值 | gzip_min_length 20; |
| 位置 | http、server、location |
nignx计量大小的单位:bytes[字节] / kb[千字节] / M[兆]
例如: 1024 / 10k|K / 10m|M
Gzip压缩功能对大数据的压缩效果明显,但是如果要压缩的数据比较小的化,可能出现越压缩数据量越大的情况,因此我们需要根据响应内容的大小来决定是否使用Gzip功能,响应页面的大小可以通过头信息中的Content-Length来获取。但是如何使用了Chunk编码动态压缩,该指令将被忽略。建议设置为1K或以上。
- gzip_proxied指令:该指令设置是否对服务端返回的结果进行Gzip压缩。
| 语法 | gzip_proxied off|expired|no-cache| no-store|private|no_last_modified|no_etag|auth|any; |
|---|---|
| 默认值 | gzip_proxied off; |
| 位置 | http、server、location |
- off - 关闭Nginx服务器对后台服务器返回结果的Gzip压缩
- expired - 启用压缩,如果header头中包含 “Expires” 头信息
- no-cache - 启用压缩,如果header头中包含 “Cache-Control:no-cache” 头信息
- no-store - 启用压缩,如果header头中包含 “Cache-Control:no-store” 头信息
- private - 启用压缩,如果header头中包含 “Cache-Control:private” 头信息
- no_last_modified - 启用压缩,如果header头中不包含 “Last-Modified” 头信息
- no_etag - 启用压缩 ,如果header头中不包含 “ETag” 头信息
- auth - 启用压缩 , 如果header头中包含 “Authorization” 头信息
- any - 无条件启用压缩
Gzip压缩功能的实例
gzip on; #开启gzip功能
gzip_types *; #压缩源文件类型,根据具体的访问资源类型设定
gzip_comp_level 6; #gzip压缩级别
gzip_min_length 1024; #进行压缩响应页面的最小长度,content-length
gzip_buffers 4 16K; #缓存空间大小
gzip_http_version 1.1; #指定压缩响应所需要的最低HTTP请求版本
gzip_vary on; #往头信息中添加压缩标识
gzip_disable "MSIE [1-6]\."; #对IE6以下的版本都不进行压缩
gzip_proxied off; #nginx作为反向代理压缩服务端返回数据的条件
这些配置在很多地方可能都会用到,所以可以将这些内容抽取到一个配置文件中,然后通过include指令把配置文件再次加载到nginx.conf配置文件中,方法使用。
nginx_gzip.conf
gzip on;
gzip_types *;
gzip_comp_level 6;
gzip_min_length 1024;
gzip_buffers 4 16K;
gzip_http_version 1.1;
gzip_vary on;
gzip_disable "MSIE [1-6]\.";
gzip_proxied off;
nginx.conf
include nginx_gzip.conf
Gzip和sendfile共存问题
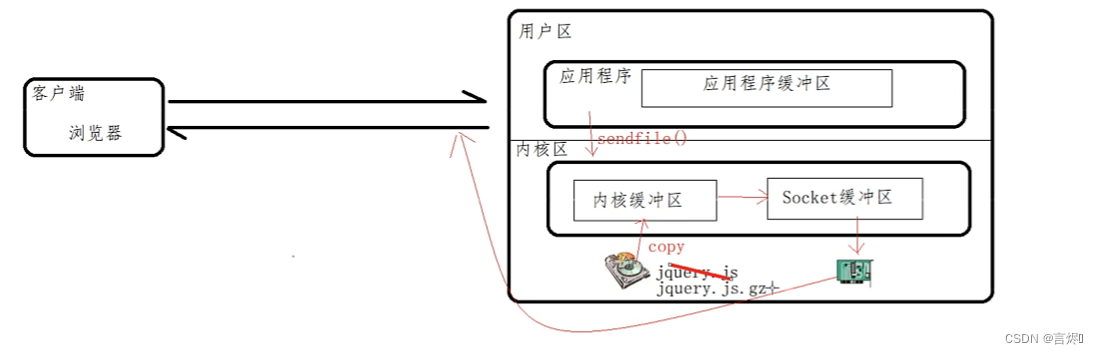
前面在讲解sendfile的时候,提到过,开启sendfile以后,在读取磁盘上的静态资源文件的时候,可以减少拷贝的次数,可以不经过用户进程将静态文件通过网络设备发送出去,但是Gzip要想对资源压缩,是需要经过用户进程进行操作的。所以如何解决两个设置的共存问题。
在应用访问之前,把js文件压缩为js.gz,当再次访问时,在磁盘找数据时直接找js.gz文件,再copy到内核缓冲区,再通过网卡发送到客户端浏览器,只要浏览器支持gzip,就会把发送的文件解压缩,在浏览器上展示。
可以使用ngx_http_gzip_static_module模块的gzip_static指令来解决。
gzip_static: 检查与访问资源同名的.gz文件时,response中以gzip相关的header返回.gz文件的内容。
| 语法 | gzip_static on | off | always; |
|---|---|
| 默认值 | gzip_static off; |
| 位置 | http、server、location |
- on 判断客户的浏览器是否支持gzip,支持再发送.gz文件
- always 不管是否支持,都会以.gz文件发送
添加上述命令后,会报一个错误,unknown directive "gzip_static"主要的原因是Nginx默认是没有添加ngx_http_gzip_static_module模块。如何来添加?

添加模块到Nginx的实现步骤
- 查询当前Nginx的配置参数
nginx -V
- 将nginx安装目录下sbin目录中的nginx二进制文件进行更名
cd /usr/local/nginx/sbin
mv nginx nginxold
- 进入Nginx的安装目录
cd /root/nginx/core/nginx-1.16.1
- 执行make clean清空之前编译的内容
make clean
- 使用configure来配置参数
./configure --with-http_gzip_static_module

- 使用make命令进行编译
make
- 将objs目录下的nginx二进制执行文件移动到nginx安装目录下的sbin目录中
将objs目录下的nginx二进制执行文件移动到nginx安装目录下的sbin目录中
- 执行更新命令
make upgrade
gzip_static测试使用
1.直接访问http://192.168.200.133/jquery.js
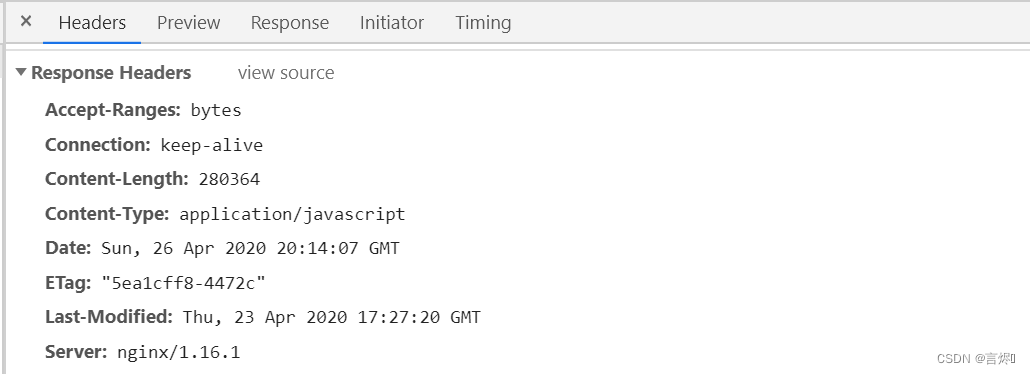
2.使用gzip命令进行压缩
cd /usr/local/nginx/html
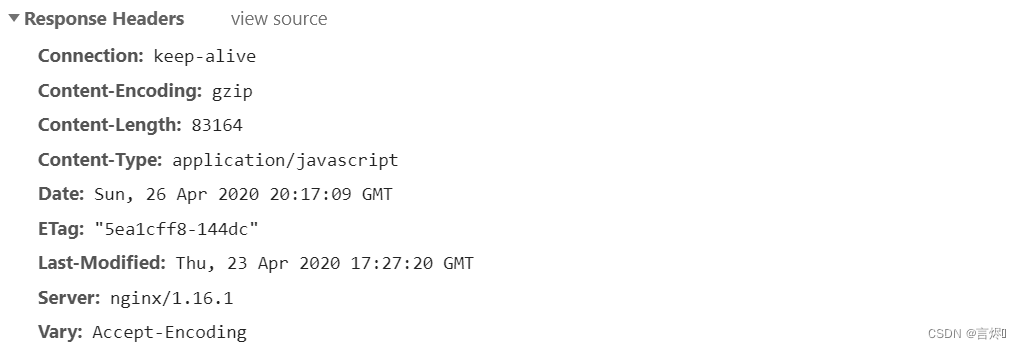
gzip jquery.js
3.再次访问http://192.168.200.133/jquery.js
静态资源的缓存处理
什么是缓存
缓存(cache),原始意义是指访问速度比一般随机存取存储器(RAM)快的一种高速存储器,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。缓存的设置是所有现代计算机系统发挥高性能的重要因素之一。
什么是web缓存
Web缓存是指一个Web资源(如html页面,图片,js,数据等)存在于Web服务器和客户端(浏览器)之间的副本。缓存会根据进来的请求保存输出内容的副本;当下一个请求来到的时候,如果是相同的URL,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。比较常见的就是浏览器会缓存访问过网站的网页,当再次访问这个URL地址的时候,如果网页没有更新,就不会再次下载网页,而是直接使用本地缓存的网页。只有当网站明确标识资源已经更新,浏览器才会再次下载网页。
web缓存的种类
客户端缓存:浏览器缓存
服务端缓存:Nginx / Redis / Memcached等
浏览器缓存
是为了节约网络的资源加速浏览,浏览器在用户磁盘上对最近请求过的文档进行存储,当访问者再次请求这个页面时,浏览器就可以从本地磁盘显示文档,这样就可以加速页面的阅览.
为什么要用浏览器缓存
- 成本最低的一种缓存实现
- 减少网络带宽消耗
- 降低服务器压力
- 减少网络延迟,加快页面打开速度
浏览器缓存的执行流程,HTTP协议中和页面缓存相关的字段如下:
| header | 说明 |
|---|---|
| Expires | 缓存过期的日期和时间 |
| Cache-Control | 设置和缓存相关的配置信息 |
| Last-Modified | 请求资源最后修改时间,服务端时间 |
| ETag | 请求变量的实体标签的当前值,比如文件的MD5值 |
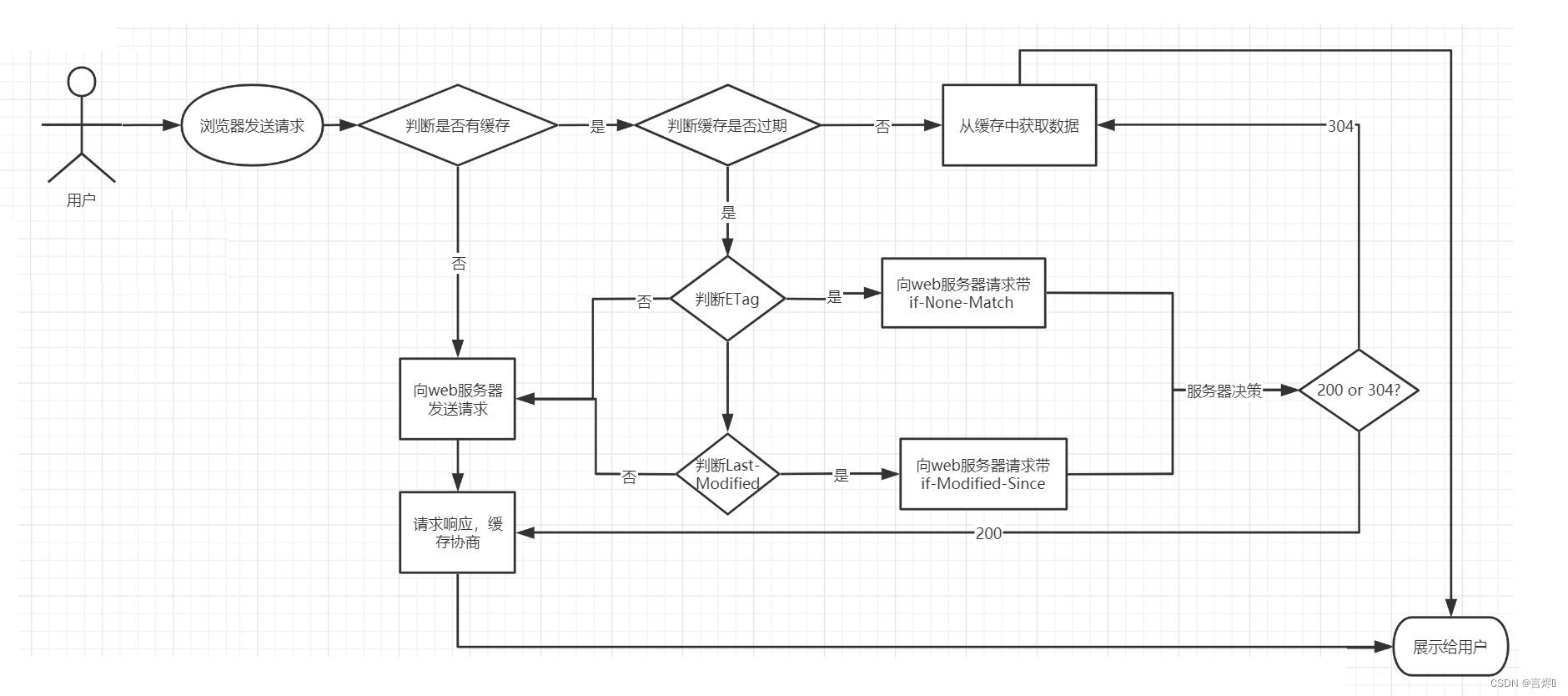
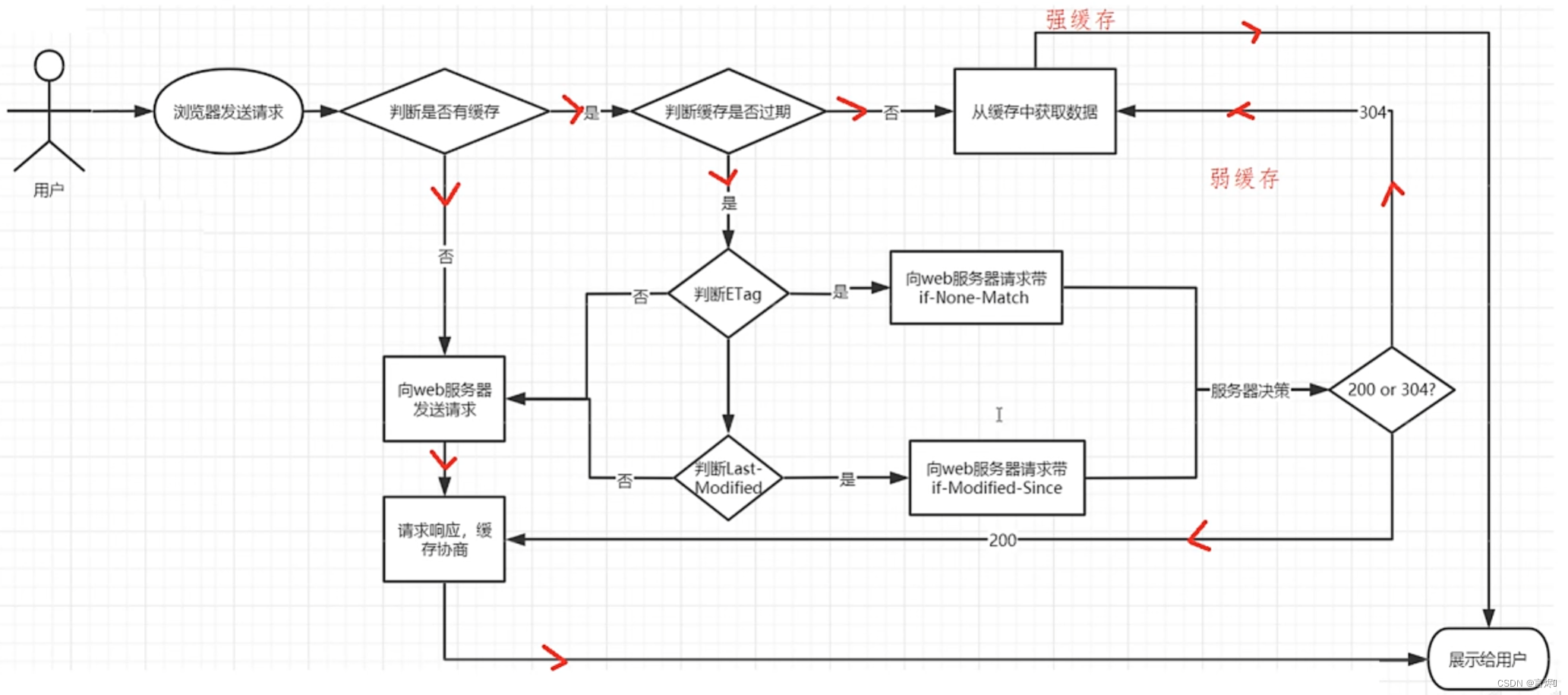
- 用户首次通过浏览器发送请求到服务端获取数据,客户端是没有对应的缓存,所以需要发送request请求来获取数据;
- 服务端接收到请求后,获取服务端的数据及服务端缓存的允许后,返回200的成功状态码并且在响应头上附上对应资源以及缓存信息;
- 当用户再次访问相同资源的时候,客户端会在浏览器的缓存目录中查找是否存在响应的缓存文件
- 如果没有找到对应的缓存文件,则走(2)步
- 如果有缓存文件,接下来对缓存文件是否过期进行判断,过期的判断标准是(Expires),
- 如果没有过期,则直接从本地缓存中返回数据进行展示
- 如果Expires过期,接下来需要判断缓存文件是否发生过变化
- 判断的标准有两个,一个是ETag(Entity Tag),一个是Last-Modified
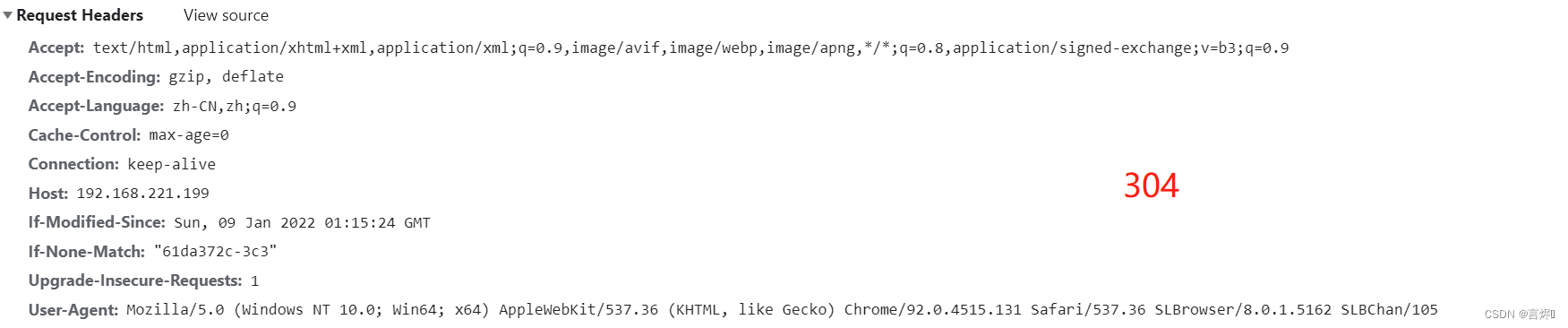
- 判断结果是未发生变化,则服务端返回304,直接从缓存文件中获取数据
- 如果判断是发生了变化,重新从服务端获取数据,并根据缓存协商(服务端所设置的是否需要进行缓存数据的设置)来进行数据缓存。

浏览器缓存相关指令
Nginx需要进行缓存相关设置,就需要用到如下的指令。
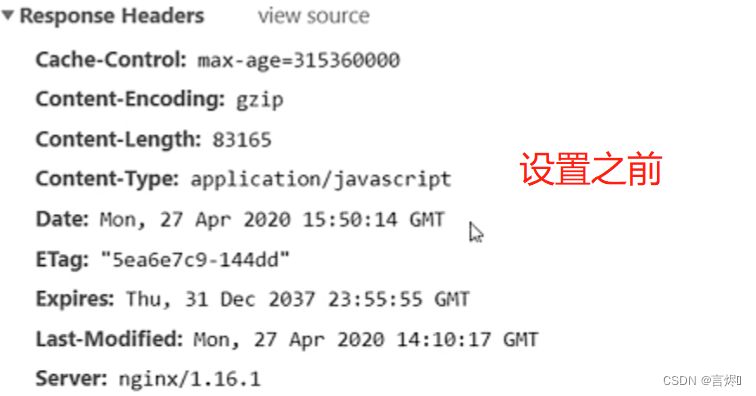
expires指令: 用来控制页面缓存的作用,通过该指令控制HTTP应答中的“Expires"和”Cache-Control"。
| 语法 | expires [modified] time expires epoch|max|off; |
|---|---|
| 默认值 | expires off; |
| 位置 | http、server、location |
- time:可以正数也可以是负数,指定过期时间,如果是负数,Cache-Control则为no-cache(不管缓存有没有过期,都需要发送请求到服务端确认文件资源有没有发送变化,弱缓存),如果为整数或0,设置Cache-Control里的max-age=time
- epoch::指定Expires的值为’1 January,1970,00:00:01 GMT’(1970-01-01 00:00:00),Cache-Control的值no-cache
- max:指定Expires的值为’31 December2037 23:59:59GMT’ (2037-12-31 23:59:59) ,Cache-Control的值为10年
- off:默认不缓存。
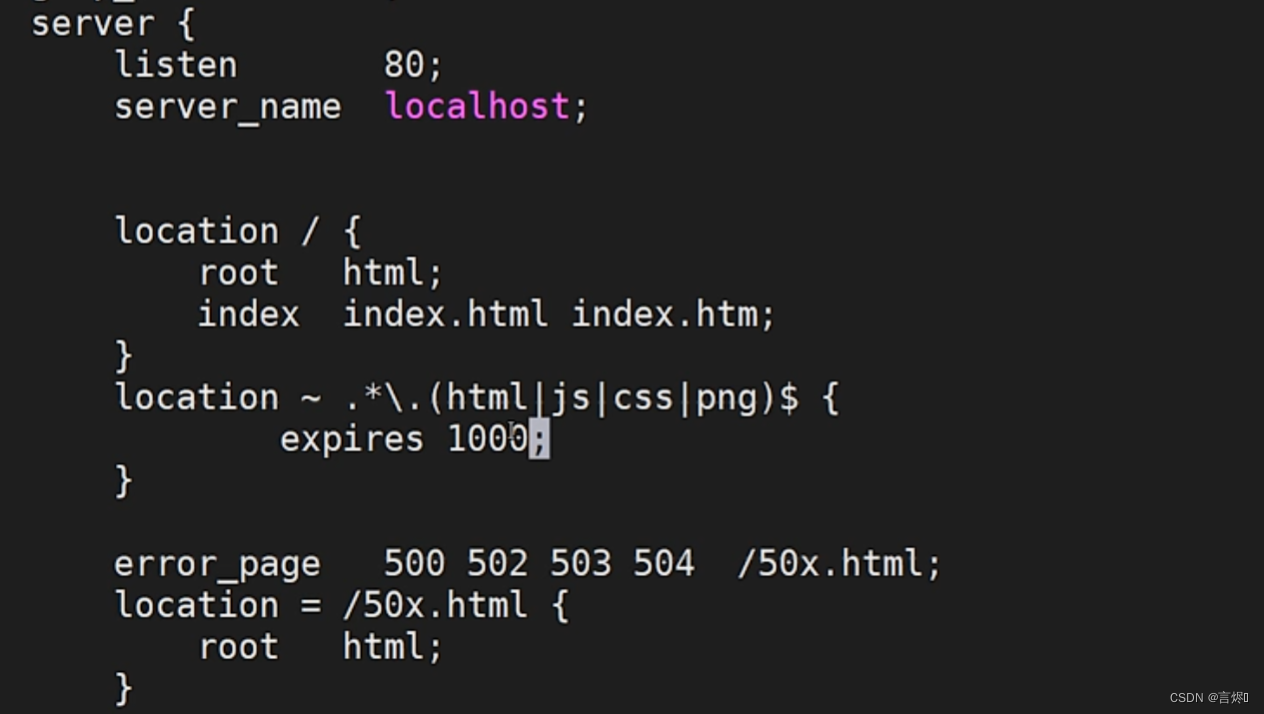
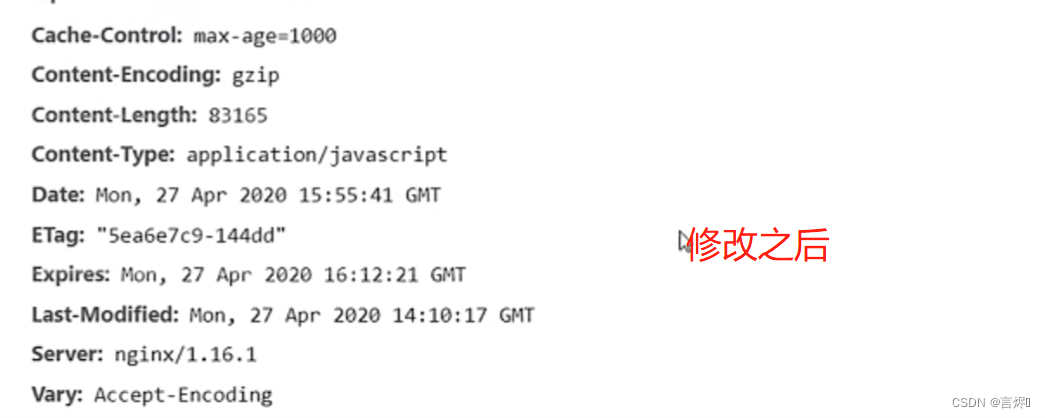
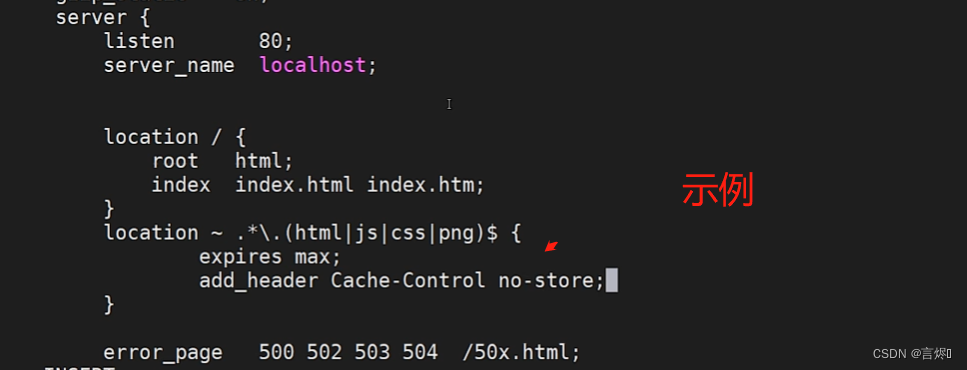
示例:
修改配置
add_header指令: 用来添加指定的响应头和响应值。
| 语法 | add_header name value [always]; |
|---|---|
| 默认值 | — |
| 位置 | http、server、location… |
| always不管支持否,都添加 | |
| Cache-Control作为响应头信息,可以设置如下值,缓存响应指令: |
Cache-control: must-revalidate
Cache-control: no-cache
Cache-control: no-store
Cache-control: no-transform
Cache-control: public
Cache-control: private
Cache-control: proxy-revalidate
Cache-Control: max-age=<seconds>
Cache-control: s-maxage=<seconds>
| 指令 | 说明 |
|---|---|
| must-revalidate | 可缓存但必须再向源服务器进行确认 |
| no-cache | 缓存前必须确认其有效性 |
| no-store | 不缓存请求或响应的任何内容 |
| no-transform | 代理不可更改媒体类型 |
| public | 可向任意方提供响应的缓存 |
| private | 仅向特定用户返回响应 |
| proxy-revalidate | 要求中间缓存服务器对缓存的响应有效性再进行确认 |
| max-age=<秒> | 响应最大Age值 |
| s-maxage=<秒> | 公共缓存服务器响应的最大Age值 |
Nginx的跨域问题解决
需要先了解浏览器的同源策略:是一种约定,是浏览器最核心也是最基本的安全功能,如果浏览器少了同源策略,则浏览器的正常功能可能都会受到影响。
同源: 协议、域名(IP)、端口相同即为同源。
http://192.168.200.131/user/1
https://192.168.200.131/user/1
协议不同
http://192.168.200.131/user/1
http://192.168.200.132/user/1
ip不同
http://192.168.200.131/user/1
http://192.168.200.131:8080/user/1
端口不同
http://www.nginx.com/user/1
http://www.nginx.org/user/1
域名不同
http://www.nginx.org:80/user/1
http://www.nginx.org/user/1
满足
跨域问题
有两台服务器分别为A,B,如果从服务器A的页面发送异步请求到服务器B获取数据,如果服务器A和服务器B不满足同源策略,则就会出现跨域问题。
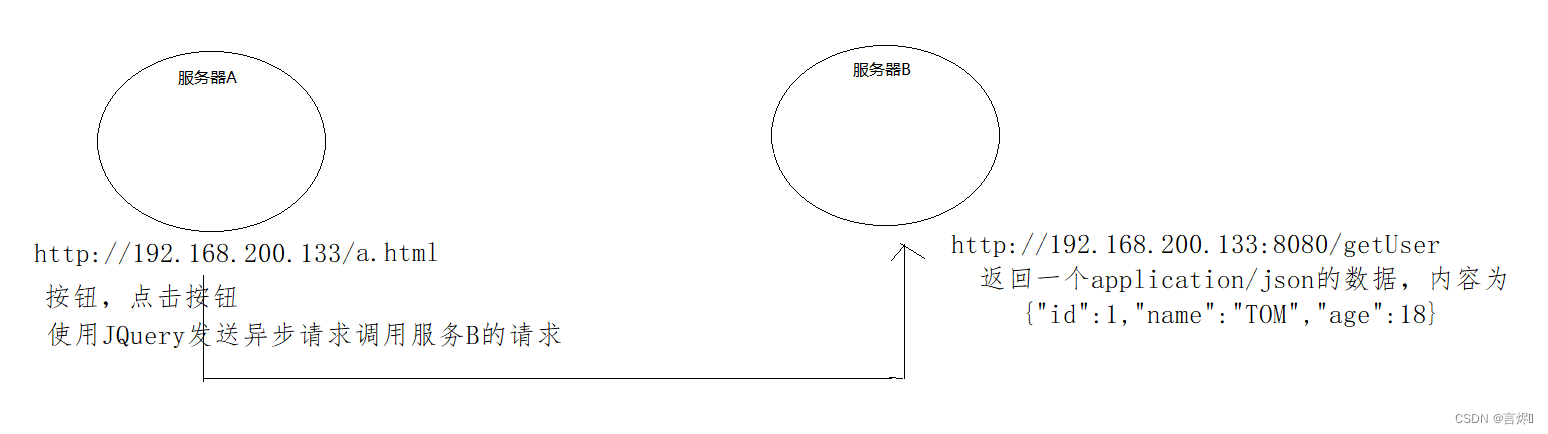
1.nginx的html目录下新建一个a.html
<html>
<head>
<meta charset="utf-8">
<title>跨域问题演示</title>
<script src="jquery.js"></script>
<script>
$(function(){
$("#btn").click(function(){
$.get('http://192.168.200.133:8080/getUser',function(data){
alert(JSON.stringify(data));
});
});
});
</script>
</head>
<body>
<input type="button" value="获取数据" id="btn"/>
</body>
</html>
2.在nginx.conf配置如下内容
server{
listen 8080;
server_name localhost;
location /getUser{
default_type application/json;
return 200 '{"id":1,"name":"TOM","age":18}';
}
}
server{
listen 80;
server_name localhost;
location /{
root html;
index index.html;
}
}
3.通过浏览器访问测试
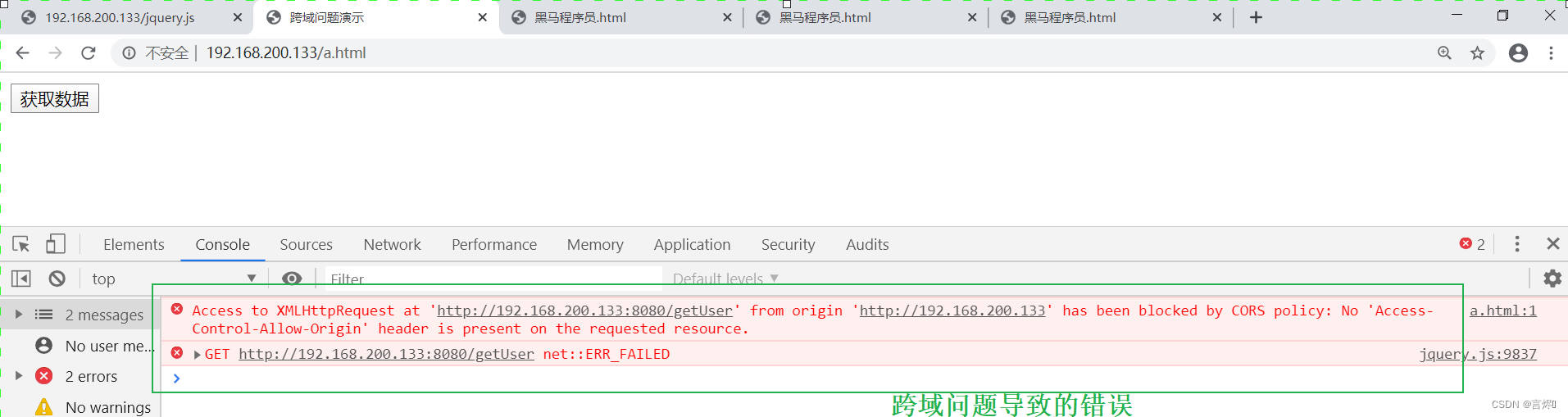
解决方案: 使用add_header指令,该指令可以用来添加一些头信息
| 语法 | add_header name value… |
|---|---|
| 默认值 | — |
| 位置 | http、server、location |
此处用来解决跨域问题,需要添加两个头信息,一个是Access-Control-Allow-Origin,Access-Control-Allow-Methods。
Access-Control-Allow-Origin:直译过来是允许跨域访问的源地址信息,可以配置多个(多个用逗号分隔),也可以使用*代表所有源。
Access-Control-Allow-Methods:直译过来是允许跨域访问的请求方式,值可以为 GET POST PUT DELETE…,可以全部设置,也可以根据需要设置,多个用逗号分隔。
具体配置方式:
location /getUser{
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods GET,POST,PUT,DELETE;
default_type application/json;
return 200 '{"id":1,"name":"TOM","age":18}';
}
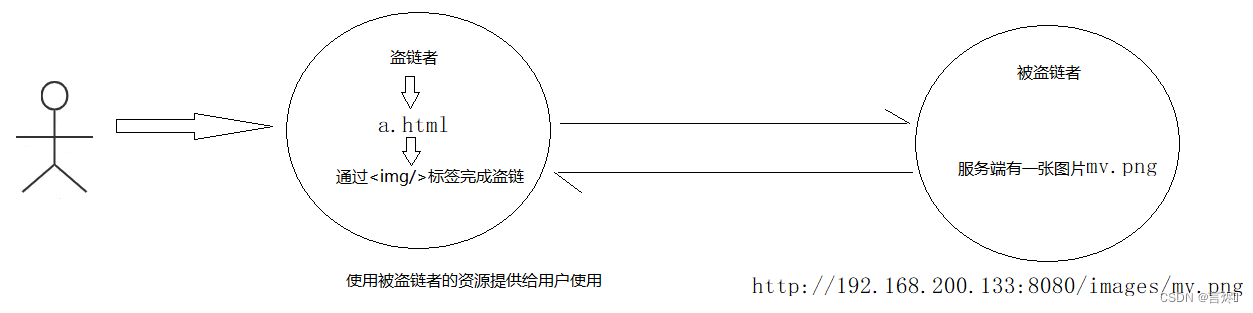
静态资源防盗链
资源盗链指的是此内容不在自己服务器上,而是通过技术手段,绕过别人的限制将别人的内容放到自己页面上最终展示给用户。以此来盗取大网站的空间和流量。简而言之就是用别人的东西成就自己的网站。
防盗链的实现原理
了解防盗链的原理之前,我们得先学习一个HTTP的头信息Referer,当浏览器向web服务器发送请求的时候,一般都会带上Referer,来告诉浏览器该网页是从哪个页面链接过来的。
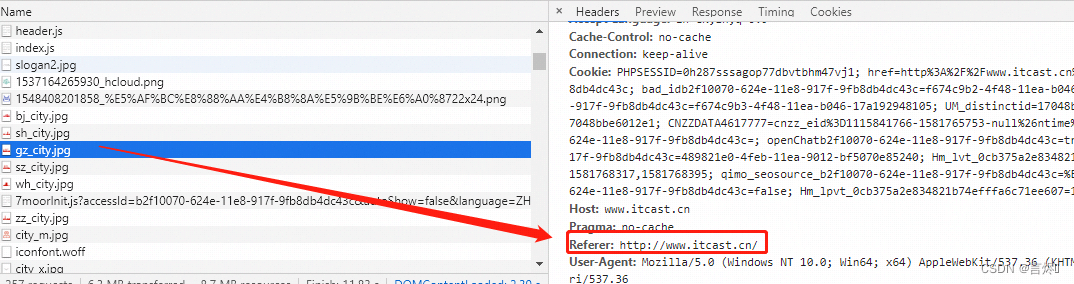
后台服务器可以根据获取到的这个Referer信息来判断是否为自己信任的网站地址,如果是则放行继续访问,如果不是则可以返回403(服务端拒绝访问)的状态信息。
在本地模拟上述的服务器效果:
防盗链的具体实现
valid_referers: nginx会通就过查看referer自动和valid_referers后面的内容进行匹配,如果匹配到了就将invalid_referer变量置0,如果没有匹配到,则将invalid_referer变量置为1,匹配的过程中不区分大小写。
| 语法 | valid_referers none|blocked|server_names|string… |
|---|---|
| 默认值 | — |
| 位置 | server、location |
- none::如果Header中的Referer为空,允许访问
- blocked:在Header中的Referer不为空,但是该值被防火墙或代理进行伪装过,如不带"http://" 、"https://"等协议头的资源允许访问。
- server_names:指定具体的域名或者IP
- string: 可以支持正则表达式和*的字符串。如果是正则表达式,需要以
~开头表示,例如
# 针对文件后缀 进行防盗链配置
location ~*\.(png|jpg|gif){
valid_referers none(referer为空允许访问) blocked www.baidu.com 192.168.200.222 *.example.com example.* www.example.org ~\.google\.;
if ($invalid_referer){
# 如果是1
return 403;
}
root /usr/local/nginx/html;
}
针对目录进行防盗链配置如下:
location /images {
valid_referers none blocked www.baidu.com 192.168.200.222 *.example.com example.* www.example.org ~\.google\.;
if ($invalid_referer){
return 403;
}
root /usr/local/nginx/html;
}
这样可以对一个目录下的所有资源进行翻到了操作。
遇到的问题:Referer的限制比较粗,比如随意加一个Referer,上面的方式是无法进行限制的。那么这个问题改如何解决?需要用到Nginx的第三方模块ngx_http_accesskey_module,参考【备注】