前言
在前端实际开发中,有关JS原生的堆和栈也是很重要的点,关于底层和原理的掌握使用,尤其是在性能优化方面甚为重要。众所周知,JS的变量都是存放在内存中的,而且内存给变量开辟了两块区域,即堆区域和栈区域,其实堆和栈是数据存储的一种结构。所以在实际开发中,JS中堆和栈也是比较常见且重要的知识点,而且在前端求职面试的时候二者也是常考知识点,可以说非常重要,那么本文就来做一下总结,方便查阅使用。
JS数据类型
在介绍栈和堆之前,首先再来看一下JS数据类型。前端开发者应该都知道,JS数据类型分为:基本数据类型和引用数据类型。基本数据类型其实就是保存在栈内存中的简单数据段,每种类型的数据所占用的空间大小都是确定的;引用数据类型则是保存在堆内存中的对象,每种类型的数据所占用的空间大小不确定。
1、基本数据类型
- Number:数字类型,
- Boolean:布尔类型,
- String:字符串类型,
- null,
- undefined,
- symbol(ES6新增的),
注意:null虽然是基本数据类型,但输出的结果是Object是因为null被认为是空的对象引用。
2、引用数据类型
- array:数组,
- Math:对象,
- function:函数,
- Date。
注意:函数不是基本数据类型,但是调用typeof后会出现function类型,那是因为函数是对象。但是也有一些特殊属性,因此利用typeof来区分函数和对象是有必要的。
具体关于JS数据类型的内容可以参看三掌柜的这篇文章,里面有详解:前端开发:JS中常用数据类型的转换以及使用场景集锦_前端2每次数据绑定时都需要转换类型吗_三掌柜666的博客-CSDN博客。
栈
1、栈的概念
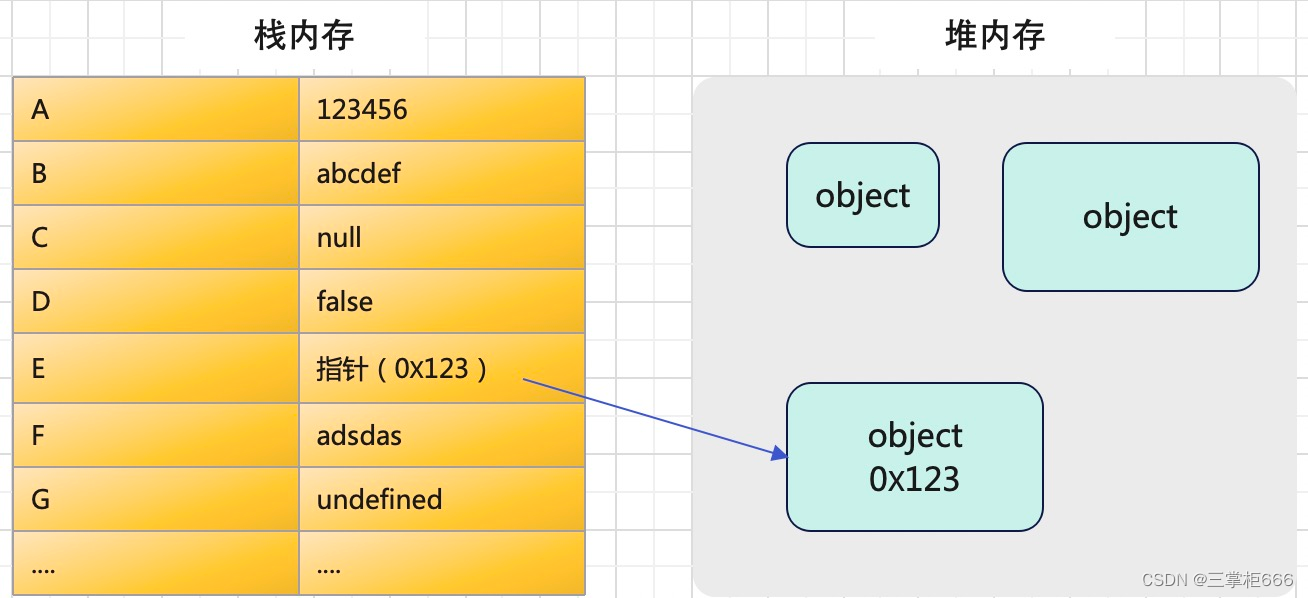
栈(stack): 栈其实是栈内存的简称,栈是由操作系统自动分配相对固定大小的内存空间,且会自动释放,存储的是基础数据类型变量以及一些对象的引用变量,占用固定大小的空间;而且栈数据结构遵循FILO(first in last out)先进后出的原则。
2、栈的代表
栈的经典代表就是:乒乓球盒结构,先放进去的乒乓球只能最后才能取出来。这里举一个简单的示例说明一下,具体如下所示:
//先来定义变量
var a = 1000;
var b = true;
var c = 'hello world';执行的顺序如下所示

3、栈的特点
栈的特点主要是:开口向上,速度快,容量小。
堆
1、堆的概念
堆(heap): 堆其实是堆内存的简称,堆是由操作系统动态分配的内存,且内存大小不固定,也不会自动释放,一般是由开发者分配释放内存,也可由垃圾回收机制回收内存。堆数据结构其实是一种无序堆树状结构,且满足键值对(key-value)的存储方式。而且栈数据结构遵循FIFO(First in, first out)先进先出的原则。
2、堆的代表
堆的经典代表就是:书架存书,读者根据书的名字,在书架上就可以找到对应的书。

这里举一个简单堆的示例,具体代码如下所示:
var student1 = {
name: 'John',
age: 30,
phone: '13100002222'
}
var student2 = student1;
student2.name = 'Jason';
console.log(student1.name); // 输出结果为:Jason3、栈的特点
栈的特点主要是:速度慢,容量大。
堆和栈的区别
1、栈:基本数据类型变量是存储在栈中的,而引用数据类型变量存储在栈中的是指向堆中的数组或者对象的地址,这就是为什么修改引用数据类型总是会影响到其他指向这个地址的引用变量。
栈的优点:
(1)栈中的内容是由操作系统自动创建、自动回收的,占用固定大小的内存空间,所以内存可以及时得到回收,相对于堆来说更容易管理内存空间;
(2)与堆相比存取速度更快,且栈内存中的数据是可以共享的。
栈的缺点:
存在栈中的数据大小与生存的周期必须是确定的,缺乏灵活性。
2、堆:堆内存中的对象不会因为方法的结束而销毁,即便方法结束,该对象也可能会被其他引用变量所引用,是因为参数间传递的原因。创建对象是为了反复利用,该对象将被保存到运行时数据区,即堆内存。只有当一个对象没有任何引用数据类型变量引用它的时候,系统的垃圾回收机制才会在核实时回收它。
堆的优点:
(1) 堆是由操作系统动态分配的、大小不定的内存,所以比较方便存储和开辟内存空间;
(2)堆中保存的对象不会自动释放,一般由开发者分配释放,也可由垃圾回收机制回收,所以生存周期比较灵活。
堆的缺点:
存在堆中的数据大小与生存周期是不确定的,比较混乱,杂乱无章,容易混淆。
3、小结
(1)JS的数据类型中,基本数据类型存在栈中,引用数据类型存在堆中;
(2)基本数据类型有固定的大小和值,存放在栈中;引用类型不固定大小,但其引用地址是固定的,它的地址存在栈中,指向存储在堆中的对象里面;
(3)基本数据类型在当前环境执行结束时自动销毁;引用类型只有在引用的它的变量不存在的时候,会被垃圾回收机制回收;
(4)基本数据类型是深拷贝,引用数据类型是浅拷贝,变量的复制其实是引用的传递;
(5)基本数据类型不可添加属性和方法,但引用数据类型可以添加属性和方法;
(6)基本数据类型在做比较相等的时候,可以直接用 == 或者 ===来做比较;但引用类型,即便let s = {}; 和let s1 = {}; 一样,但它们的内存地址不一样,所以做比较的结果依然不相等。
(7) 传值和传址:从一个变量向另一个变量复制引用数据类型的值,其实复制的是指针,因此两个变量最终指向同一个对象,即复制的是栈中的地址而不是堆中的对象。从一个变量复向另一个变量复制基本类型的值,会创建这个值的副本。
堆和栈的溢出
堆和栈的溢出,具体如下所示:
(1)若想要堆溢出,可以循环创建的对象或者外层的对象;
(2)若想要栈溢出,可以递归调用方法,随着栈深度的增加,虚拟机(JVM)会维持着一条很长的方法调用轨迹,直至内存不够分配为止,产生栈的溢出。
最后
通过本文关于前端开发中关于JS中堆和栈的区别的详细介绍,堆和栈的区别及其使用不管是在实际的前端开发工作中还是在前端求职面试中都是非常关键的知识点,所以作为前端开发者来说必须要掌握它相关的内容,尤其是从事前端开发不久的开发者来说尤为重要,是一篇值得阅读的文章,重要性就不在赘述。欢迎关注,一起交流,共同进步。











![[洛谷]B3601 [图论与代数结构 201] 最短路问题_1(负权)(spfa)](https://img-blog.csdnimg.cn/bb17d50e011141a5a12a23a34d98bb3c.png)