前言
SAM就是一类处理图像分割任务的通用模型。与以往只能处理某种特定类型图片的图像分割模型不同,SAM可以处理所有类型的图像。
在SAM出现前,基本上所有的图像分割模型都是专有模型。比如,在医学领域,有专门分割核磁图像的人工智能模型,也有专门分割CT影像的人工智能模型。但这些模型往往只在分割专有领域内的图像时,才具有良好性能,而在分割其他领域的图像时往往性能不佳。
沿着前两篇文章之后,本文讲下面带下划线的三个图像分割模型
| 1月 | 3月 | 4月 | 5月 | 6月 | 8月 | 10月 | 11月 | |
| 2020 | DETR | DDPM | DDIM VisionTransformer | |||||
| 2021 | CLIP DALL·E | SwinTransformer | MAE SwinTransformerV2 | |||||
| 2022 | BLIP | DALL·E 2 | StableDiffusion BEiT-3 Midjourney V3 | |||||
| 2023 | BLIP2 | VisualChatGPT GPT4 Midjourney V5 | SAM(Segment Anything Model) | FastSAM (中科院版SAM) MobileSAM |
第一部分 SAM(Segment Anything Model)
1.1 SAM(分割一切):建立通用分割模型且依据提示灵活分割
- 在网络数据集上预训练的大语言模型具有强大的zero-shot(零样本)和few-shot(少样本)的泛化能力,这些"基础模型"可以推广到超出训练过程中的任务和数据分布,这种能力通过“prompt engineering”实现,具体就是输入提示语得到有效的文本输出,使用网络上的大量文本资料库进行缩放和训练后,发现这种零样本和少样本的训练的模型比微调模型效果还要好,数据集越大,效果越明显,比如GPT3
- 视觉任务上也对这种基础模型进行了探索,比如CLIP和ALIGN利用对比学习,将文本和图像编码进行了对齐,通过提示语生成image encoder,就可以扩展到下游任务,比如生成图像
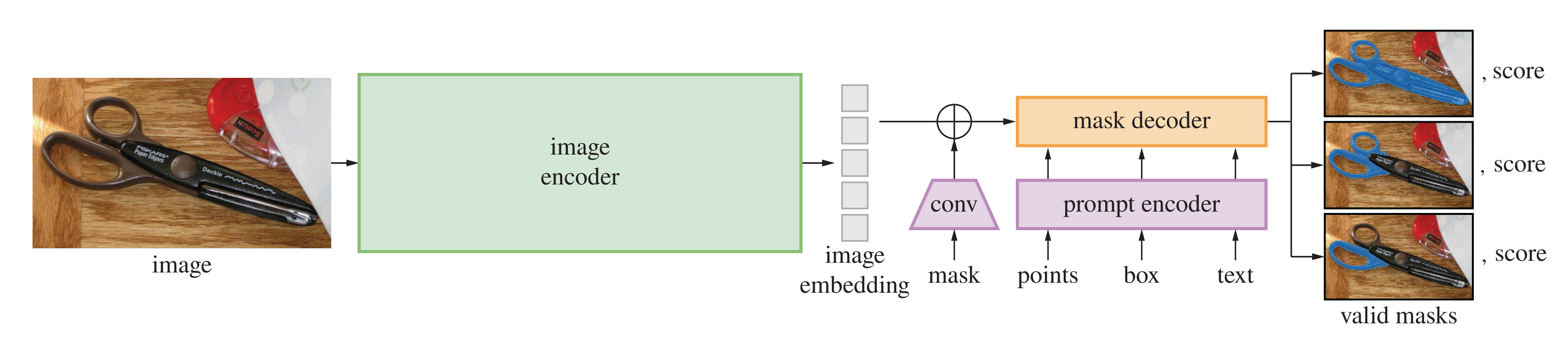
SAM(论文地址、代码地址)的目的是建立一个图像分割的基础模型,开发一个具有提示能力的模型
要解决的3个问题:
- 什么任务可以实现零样本?
通过提示输入,生成有效的mask,当提示是不确定的,能生成多个objects(比如衣服上的一个点,既可以表示衣服,也表示穿衣服的人),如下图所示:提示可以是点,矩形框,文字,mask,或者是图像
- 模型结构应该是什么样?
模型要支持灵活的提示,且要实时生成mask,对输出也是模糊的(比如表示衣服还是穿衣服的人),设计结构如下:一个prompt encoder,对提示进行编码

- 数据怎么支持这些任务?
需要一个大量且多样化的mask数据。自然语言数据是通过在线获取,但是mask数据是不足的,需要一个替代策略。
方案就是建立一个“数据引擎”,分成3步:
如下图所示:先标注数据进行训练模型,然后用模型辅助标注数据,如此建立一个数据循环。最终从1100万张图像中生成了10亿的mask,是当前最大的数据,比当前已有的数据集多了400倍的mask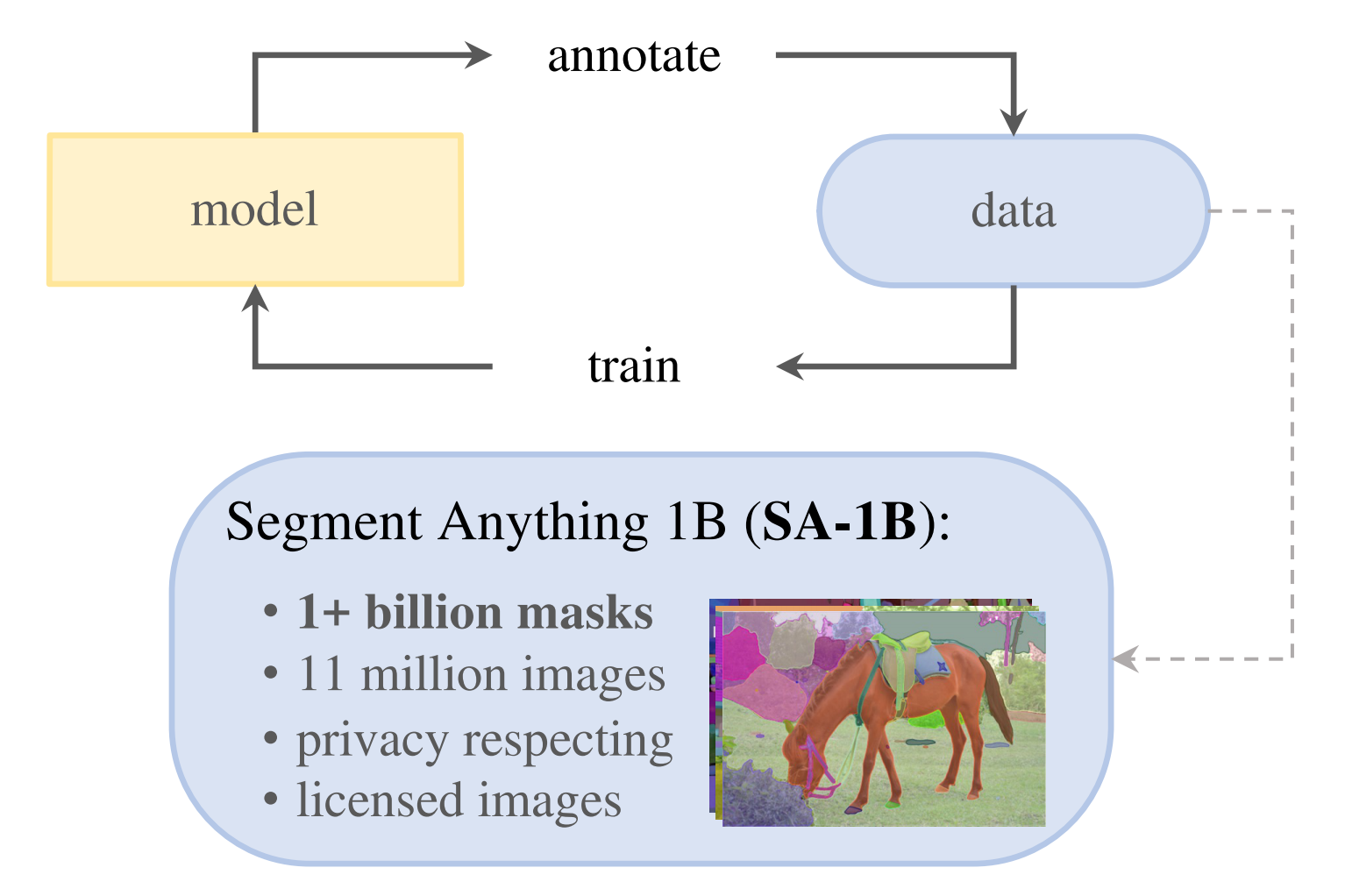
1.2 模型的结构(image encoder + prompt encoder + mask decoder)与训练
模型结构如下
1.2.1 image encoder的构成(ViT)与其编码实现
利用MAE预训练的视觉Transformer (即ViT,如果忘了ViT长啥样,可回顾此文第4部分),最低限度适应高分辨率的输入,该encoder在prompt encoder之前,对每张图像只运行一次
输入(c,h,w)的图像,对图像进行缩放,按照长边缩放成1024,短边不够就pad,得到(c,1024,1024)的图像,经过image encoder,得到对图像16倍下采样的feature,大小为(256,64,64)
至于其代码实现主要实现以下几个类
- 一个是定义ImageEncoderViT类,这是一个基于Vision Transformer的图像编码器,该类从nn.Module继承
import torch import torch.nn as nn import torch.nn.functional as F from typing import Optional, Tuple, Type # 导入.common模块中的LayerNorm2d和MLPBlock from .common import LayerNorm2d, MLPBlock # 定义ImageEncoderViT类,这是一个基于Vision Transformer的图像编码器,该类从nn.Module继承 class ImageEncoderViT(nn.Module): # 类的构造函数,定义了一系列的参数,例如图像大小,块大小,输入通道数,嵌入维度,Transformer的深度,注意力头部数等。 def __init__( self, img_size: int = 1024, patch_size: int = 16, in_chans: int = 3, embed_dim: int = 768, depth: int = 12, num_heads: int = 12, mlp_ratio: float = 4.0, out_chans: int = 256, qkv_bias: bool = True, norm_layer: Type[nn.Module] = nn.LayerNorm, act_layer: Type[nn.Module] = nn.GELU, use_abs_pos: bool = True, use_rel_pos: bool = False, rel_pos_zero_init: bool = True, window_size: int = 0, global_attn_indexes: Tuple[int, ...] = (), ) -> None: # 使用super函数调用父类的初始化函数 super().__init__() # 将图像大小保存为类的一个属性 self.img_size = img_size # 创建PatchEmbed实例,用于将输入图像划分为多个patch,并将每个patch嵌入到一个向量空间中 self.patch_embed = PatchEmbed( kernel_size=(patch_size, patch_size), stride=(patch_size, patch_size), in_chans=in_chans, embed_dim=embed_dim, ) # 创建位置嵌入属性,如果使用绝对位置嵌入,则初始化这个属性 self.pos_embed: Optional[nn.Parameter] = None if use_abs_pos: self.pos_embed = nn.Parameter( torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim) ) # 创建Transformer的主体,包含多个Transformer block self.blocks = nn.ModuleList() for i in range(depth): block = Block( dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, norm_layer=norm_layer, act_layer=act_layer, use_rel_pos=use_rel_pos, rel_pos_zero_init=rel_pos_zero_init, window_size=window_size if i not in global_attn_indexes else 0, input_size=(img_size // patch_size, img_size // patch_size), ) self.blocks.append(block) # 创建neck属性,包含一个卷积层,一个LayerNorm层,另一个卷积层和另一个LayerNorm层 self.neck = nn.Sequential( nn.Conv2d( embed_dim, out_chans, kernel_size=1, bias=False, ), LayerNorm2d(out_chans), nn.Conv2d( out_chans, out_chans, kernel_size=3, padding=1, bias=False, ), LayerNorm2d(out_chans), ) # 前向传播函数 def forward(self, x: torch.Tensor) -> torch.Tensor: # 对输入x进行patch embedding x = self.patch_embed(x) # 如果使用了位置嵌入,将位置嵌入加到x上 if self.pos_embed is not None: x = x + self.pos_embed # 将x通过所有的Transformer block for blk in self.blocks: x = blk(x) # 将x通过neck,得到最终的输出 x = self.neck(x.permute(0, 3, 1, 2)) return x - 定义Block类,这是Transformer的基本组成模块,包括注意力机制和前馈神经网络,该类从nn.Module继承
# 定义Block类,这是Transformer的基本组成模块,包括注意力机制和前馈神经网络。该类从nn.Module继承 class Block(nn.Module): # 类的构造函数,定义了一系列的参数,例如输入通道数,注意力头部数,mlp隐藏层与嵌入层的比例,是否添加偏置到查询,键,值,归一化层,激活函数等。 def __init__( self, dim: int, num_heads: int, mlp_ratio: float = 4.0, qkv_bias: bool = True, norm_layer: Type[nn.Module] = nn.LayerNorm, act_layer: Type[nn.Module] = nn.GELU, use_rel_pos: bool = False, rel_pos_zero_init: bool = True, window_size: int = 0, input_size: Optional[Tuple[int, int]] = None, ) -> None: # 使用super函数调用父类的初始化函数 super().__init__() # 创建第一个归一化层 self.norm1 = norm_layer(dim) # 创建注意力机制层 self.attn = Attention( dim, num_heads=num_heads, qkv_bias=qkv_bias, use_rel_pos=use_rel_pos, rel_pos_zero_init=rel_pos_zero_init, input_size=input_size if window_size == 0 else (window_size, window_size), ) # 创建第二个归一化层 self.norm2 = norm_layer(dim) # 创建MLP层 self.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer) # 定义窗口大小 self.window_size = window_size # 前向传播函数 def forward(self, x: torch.Tensor) -> torch.Tensor: # 保存输入x,以便稍后进行残差连接 shortcut = x # 对x进行第一次归一化处理 x = self.norm1(x) # 如果定义了窗口大小,则对x进行窗口划分 if self.window_size > 0: H, W = x.shape[1], x.shape[2] x, pad_hw = window_partition(x, self.window_size) # 对x进行注意力处理 x = self.attn(x) # 如果定义了窗口大小,则对x进行窗口合并 if self.window_size > 0: x = window_unpartition(x, self.window_size, pad_hw, (H, W)) # 对x进行残差连接 x = shortcut + x # 对x进行第二次归一化处理并通过MLP层,然后进行第二次残差连接 x = x + self.mlp(self.norm2(x)) return x - 定义Attention类,这是一个多头注意力机制的块,支持相对位置嵌入,该类从nn.Module继承
# 定义Attention类,这是一个多头注意力机制的块,支持相对位置嵌入,该类从nn.Module继承 class Attention(nn.Module): # 类的构造函数,定义了一系列的参数,例如输入通道数,注意力头部数,是否添加偏置到查询,键,值,是否使用相对位置嵌入等。 def __init__( self, dim: int, num_heads: int = 8, qkv_bias: bool = True, use_rel_pos: bool = False, rel_pos_zero_init: bool = True, input_size: Optional[Tuple[int, int]] = None, ) -> None: # 使用super函数调用父类的初始化函数 super().__init__() # 保存注意力头部数 self.num_heads = num_heads # 计算每个注意力头部的维度 head_dim = dim // num_heads # 缩放因子 self.scale = head_dim**-0.5 # 创建线性变换层,用于生成查询、键、值 self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 创建线性变换层,用于将注意力加权后的值进行线性变换 self.proj = nn.Linear(dim, dim) # 是否使用相对位置嵌入 self.use_rel_pos = use_rel_pos if self.use_rel_pos: assert ( input_size is not None ), "Input size must be provided if using relative positional encoding." # 初始化相对位置嵌入参数 self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim)) self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim)) # 前向传播函数 def forward(self, x: torch.Tensor) -> torch.Tensor: B, H, W, _ = x.shape # 对输入x进行线性变换得到查询、键、值 qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4) # 将查询、键、值拆分出来 q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0) # 计算注意力权重 attn = (q * self.scale) @ k.transpose(-2, -1) # 如果使用相对位置嵌入,将相对位置嵌入添加到注意力权重中 if self.use_rel_pos: attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W)) # 对注意力权重进行softmax归一化 attn = attn.softmax(dim=-1) # 计算注意力加权后的值,并重新调整形状 x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1) # 将注意力加权后的值进行线性变换 x = self.proj(x) return x - 定义两个函数 window_partition 和 window_unpartition,用于将输入的张量进行窗口划分和合并。这些函数在 Vision Transformer 的实现中用于实现窗口注意力机制
# 定义window_partition函数,用于将输入x分割为不重叠的窗口,并进行填充。 def window_partition(x: torch.Tensor, window_size: int) -> Tuple[torch.Tensor, Tuple[int, int]]: """ Partition into non-overlapping windows with padding if needed. Args: x (tensor): input tokens with [B, H, W, C]. window_size (int): window size. Returns: windows: windows after partition with [B * num_windows, window_size, window_size, C]. (Hp, Wp): padded height and width before partition """ B, H, W, C = x.shape # 计算需要进行填充的行和列的数量 pad_h = (window_size - H % window_size) % window_size pad_w = (window_size - W % window_size) % window_size # 如果需要进行填充,则使用F.pad函数进行填充 if pad_h > 0 or pad_w > 0: x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h)) # 计算填充后的高度和宽度 Hp, Wp = H + pad_h, W + pad_w # 将输入x重新调整形状为窗口大小的倍数 x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C) # 对调换维度进行重排列,并重新调整形状 windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C) # 返回分割后的窗口和填充前的高度和宽度 return windows, (Hp, Wp) # 定义window_unpartition函数,用于将窗口合并为原始序列,并移除填充。 def window_unpartition( windows: torch.Tensor, window_size: int, pad_hw: Tuple[int, int], hw: Tuple[int, int] ) -> torch.Tensor: """ Window unpartition into original sequences and removing padding. Args: windows (tensor): input tokens with [B * num_windows, window_size, window_size, C]. window_size (int): window size. pad_hw (Tuple): padded height and width (Hp, Wp). hw (Tuple): original height and width (H, W) before padding. Returns: x: unpartitioned sequences with [B, H, W, C]. """ Hp, Wp = pad_hw H, W = hw B = windows.shape[0] // (Hp * Wp // window_size // window_size) # 将窗口重新调整为原始序列 x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1) # 对调换维度进行重排列,并重新调整形状 x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1) # 如果填充的高度或宽度大于原始高度或宽度,则移除填充部分 if Hp > H or Wp > W: x = x[:, :H, :W, :].contiguous() # 返回合并后的序列 return x - 定义两个函数 get_rel_pos 和 add_decomposed_rel_pos,用于处理相对位置嵌入。在 Vision Transformer 的实现中,相对位置嵌入用于提供序列元素之间的相对位置信息,以帮助模型更好地捕捉序列中的关系。这些函数用于生成和应用相对位置嵌入
# 定义get_rel_pos函数,根据查询和键的大小获取相对位置嵌入。 def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor: """ Get relative positional embeddings according to the relative positions of query and key sizes. Args: q_size (int): size of query q. k_size (int): size of key k. rel_pos (Tensor): relative position embeddings (L, C). Returns: Extracted positional embeddings according to relative positions. """ # 计算相对距离的最大值 max_rel_dist = int(2 * max(q_size, k_size) - 1) # 如果相对位置嵌入的形状与最大相对距离不一致,则进行插值处理 if rel_pos.shape[0] != max_rel_dist: # 插值相对位置嵌入 rel_pos_resized = F.interpolate( rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1), size=max_rel_dist, mode="linear", ) rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0) else: rel_pos_resized = rel_pos # 根据形状的不同,使用短边的长度进行坐标缩放 q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0) k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0) relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0) return rel_pos_resized[relative_coords.long()] # 定义add_decomposed_rel_pos函数,计算分解的相对位置嵌入 def add_decomposed_rel_pos( attn: torch.Tensor, q: torch.Tensor, rel_pos_h: torch.Tensor, rel_pos_w: torch.Tensor, q_size: Tuple[int, int], k_size: Tuple[int, int], ) -> torch.Tensor: """ Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`. https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py # noqa B950 Args: attn (Tensor): attention map. q (Tensor): query q in the attention layer with shape (B, q_h * q_w, C). rel_pos_h (Tensor): relative position embeddings (Lh, C) for height axis. rel_pos_w (Tensor): relative position embeddings (Lw, C) for width axis. q_size (Tuple): spatial sequence size of query q with (q_h, q_w). k_size (Tuple): spatial sequence size of key k with (k_h, k_w). Returns: attn (Tensor): attention map with added relative positional embeddings. """ q_h, q_w = q_size k_h, k_w = k_size # 获取相对位置嵌入 Rh = get_rel_pos(q_h, k_h, rel_pos_h) Rw = get_rel_pos(q_w, k_w, rel_pos_w) B, _, dim = q.shape r_q = q.reshape(B, q_h, q_w, dim) rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh) rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw) attn = ( attn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :] ).view(B, q_h * q_w, k_h * k_w) return attn -
定义一个 PatchEmbed 类,用于将图像转换为补丁嵌入。它使用卷积层将输入图像转换为指定维度的补丁嵌入表示。在前向传播中,输入经过卷积层进行投影,并调换维度的顺序,以使得输出为批量-高度-宽度-通道的形状
# 定义PatchEmbed类,用于将图像转换为补丁嵌入。 class PatchEmbed(nn.Module): """ Image to Patch Embedding. """ def __init__( self, kernel_size: Tuple[int, int] = (16, 16), stride: Tuple[int, int] = (16, 16), padding: Tuple[int, int] = (0, 0), in_chans: int = 3, embed_dim: int = 768, ) -> None: """ Args: kernel_size (Tuple): kernel size of the projection layer. stride (Tuple): stride of the projection layer. padding (Tuple): padding size of the projection layer. in_chans (int): Number of input image channels. embed_dim (int): Patch embedding dimension. """ # 使用super函数调用父类的初始化函数 super().__init__() # 创建卷积层,用于将图像转换为补丁嵌入 self.proj = nn.Conv2d( in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding ) # 前向传播函数 def forward(self, x: torch.Tensor) -> torch.Tensor: # 将输入x进行投影 x = self.proj(x) # 调换维度的顺序,B C H W -> B H W C x = x.permute(0, 2, 3, 1) return x
1.2.2 prompt encoder
分成2类:稀疏的(点/box/文本)、稠密的(mask)
- 对于稀疏的点、box、文本
point
映射到256维的向量,包含:代表点位置的 positional encoding,加2个代表该点是前景/背景的可学习的embedding
Sparse prompts are mapped to 256-dimensional vectorial embeddings as follows. A point is represented as the sum of a positional encoding [95] of thepoint’s location and one of two learned embeddings that indicate if the point is either in the foreground or background.
box
用一个embedding对表示:1) 可学习的embedding代表左上角,2) 可学习的embedding代表右下角
文本
通过CLIP模型进行文本编码 - 对于稠密的mask
用输入图像1/4分辨率的mask,然后用(2,2)卷积核,stride-2输出channel为4和16,再用(1,1)卷积核将channel升到256
We input masks at a 4× lower resolution than the input image, then downscale an additional 4× using two 2×2, stride-2 convolutions with output channels 4 and 16, respectively. A final 1×1 convolution maps the channel dimension to 256.
mask 和iamge embedding通过element-wise相乘 (逐元素相乘,可以理解成mask的feature对image的feature进行加权)
其代码实现为
import numpy as np
import torch
from torch import nn
from typing import Any, Optional, Tuple, Type
from .common import LayerNorm2d
class PromptEncoder(nn.Module):
def __init__(
self,
embed_dim: int,
image_embedding_size: Tuple[int, int],
input_image_size: Tuple[int, int],
mask_in_chans: int,
activation: Type[nn.Module] = nn.GELU,
) -> None:
"""
SAM模型的PromptEncoder类,用于编码输入到遮罩解码器的提示。
参数:
embed_dim (int): 提示的嵌入维度
image_embedding_size (tuple(int, int)): 图像嵌入的空间尺寸,格式为(H, W)。
input_image_size (int): 输入到图像编码器的图像填充尺寸,格式为(H, W)。
mask_in_chans (int): 用于编码输入遮罩的隐藏通道数。
activation (nn.Module): 用于编码输入遮罩时使用的激活函数。
"""
super().__init__()
self.embed_dim = embed_dim
self.input_image_size = input_image_size
self.image_embedding_size = image_embedding_size
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
self.num_point_embeddings: int = 4 # 正/负点 + 2个框角
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)]
self.point_embeddings = nn.ModuleList(point_embeddings)
self.not_a_point_embed = nn.Embedding(1, embed_dim)
self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1])
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
self.no_mask_embed = nn.Embedding(1, embed_dim)
def get_dense_pe(self) -> torch.Tensor:
"""
返回用于编码点提示的位置编码,应用于与图像编码尺寸相同的密集点集。
返回:
torch.Tensor: 形状为1x(embed_dim)x(embedding_h)x(embedding_w)的位置编码。
"""
return self.pe_layer(self.image_embedding_size).unsqueeze(0)
def _embed_points(
self,
points: torch.Tensor,
labels: torch.Tensor,
pad: bool,
) -> torch.Tensor:
"""嵌入点提示。"""
points = points + 0.5 # 移动到像素的中心
if pad:
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
points = torch.cat([points, padding_point], dim=1)
labels = torch.cat([labels, padding_label], dim=1)
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += self.not_a_point_embed.weight
point_embedding[labels == 0] += self.point_embeddings[0].weight
point_embedding[labels == 1] += self.point_embeddings[1].weight
return point_embedding
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""嵌入框提示。"""
boxes = boxes + 0.5 # 移动到像素的中心
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
"""嵌入遮罩输入。"""
mask_embedding = self.mask_downscaling(masks)
return mask_embedding
def _get_batch_size(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> int:
"""
根据输入提示的批大小获取输出的批大小。
"""
if points is not None:
return points[0].shape[0]
elif boxes is not None:
return boxes.shape[0]
elif masks is not None:
return masks.shape[0]
else:
return 1
def _get_device(self) -> torch.device:
return self.point_embeddings[0].weight.device
def forward(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
嵌入不同类型的提示,返回稀疏和密集的嵌入。
参数:
points (tuple(torch.Tensor, torch.Tensor) or none): 要嵌入的点坐标和标签。
boxes (torch.Tensor or none): 要嵌入的框。
masks (torch.Tensor or none): 要嵌入的遮罩。
返回:
torch.Tensor: 稀疏的点和框嵌入,形状为BxNx(embed_dim),其中N由输入点和框的数量决定。
torch.Tensor: 密集的遮罩嵌入,形状为Bx(embed_dim)x(embed_H)x(embed_W)。
"""
bs = self._get_batch_size(points, boxes, masks)
sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device())
if points is not None:
coords, labels = points
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
if boxes is not None:
box_embeddings = self._embed_boxes(boxes)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
if masks is not None:
dense_embeddings = self._embed_masks(masks)
else:
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
)
return sparse_embeddings, dense_embeddings
class PositionEmbeddingRandom(nn.Module):
"""
使用随机空间频率的位置编码。
"""
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
super().__init__()
if scale is None or scale <= 0.0:
scale = 1.0
self.register_buffer(
"positional_encoding_gaussian_matrix",
scale * torch.randn((2, num_pos_feats)),
)
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
"""对归一化到[0,1]的点进行位置编码。"""
# 假设坐标在[0, 1]^2的正方形内,并具有d_1 x ... x d_n x 2的形状
coords = 2 * coords - 1
coords = coords @ self.positional_encoding_gaussian_matrix
coords = 2 * np.pi * coords
# 输出形状为d_1 x ... x d_n x C
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
"""为指定大小的网格生成位置编码。"""
h, w = size
device: Any = self.positional_encoding_gaussian_matrix.device
grid = torch.ones((h, w), device=device, dtype=torch.float32)
y_embed = grid.cumsum(dim=0) - 0.5
x_embed = grid.cumsum(dim=1) - 0.5
y_embed = y_embed / h
x_embed = x_embed / w
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
return pe.permute(2, 0, 1) # C x H x W
def forward_with_coords(
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
) -> torch.Tensor:
"""对未归一化到[0,1]的点进行位置编码。"""
coords = coords_input.clone()
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
return self._pe_encoding(coords.to(torch.float)) # B x N x C1.2.3 mask decoder
mask decoder模块:在prompt embeddings中插入一个可学习的token,用于docoder的输出
对于下图的左侧部分,依次进行如下4个步骤
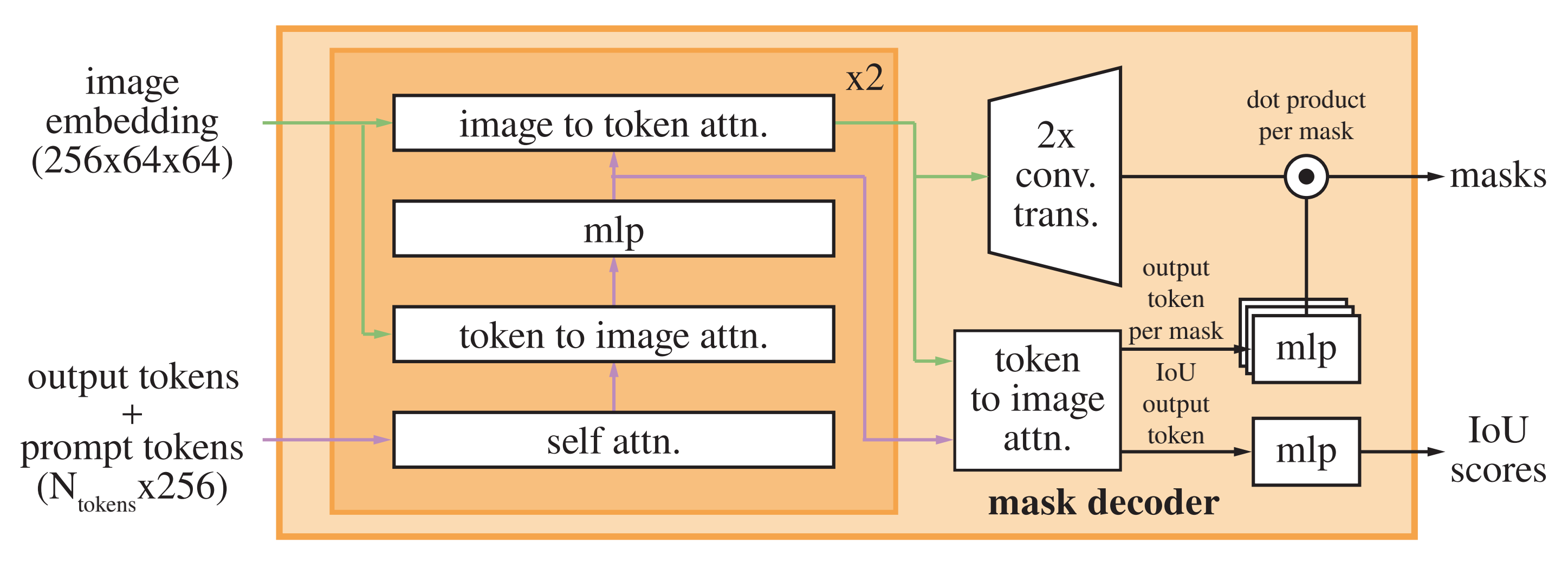
- prompt toekns+output tokens进行self attn
self-attention on the tokens - 用得到的token和image embedding进行 cross attn(token作为Q)
cross-attention from tokens (as queries) to the image embedding - point-wise MLP 更新token
a point-wise MLP updates each token - 用image embedding和步骤3的token进行cross atten(image embedding作为Q)
cross-attention from the image embedding (as queries) to tokens
重复上述步骤2次,再将attn再通过残差进行连接,最终输出masks和iou scores,这段的代码实现为
import torch
from torch import Tensor, nn
import math
from typing import Tuple, Type
from .common import MLPBlock
class TwoWayTransformer(nn.Module):
def __init__(
self,
depth: int,
embedding_dim: int,
num_heads: int,
mlp_dim: int,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
) -> None:
"""
使用位置嵌入提供的查询,对输入图像进行注意力操作的Transformer解码器。
参数:
depth (int): Transformer中的层数
embedding_dim (int): 输入嵌入的通道维度
num_heads (int): 多头注意力的头数。embedding_dim必须是num_heads的倍数
mlp_dim (int): MLP块内部的通道维度
activation (nn.Module): MLP块中使用的激活函数
"""
super().__init__()
self.depth = depth
self.embedding_dim = embedding_dim
self.num_heads = num_heads
self.mlp_dim = mlp_dim
self.layers = nn.ModuleList()
for i in range(depth):
self.layers.append(
TwoWayAttentionBlock(
embedding_dim=embedding_dim,
num_heads=num_heads,
mlp_dim=mlp_dim,
activation=activation,
attention_downsample_rate=attention_downsample_rate,
skip_first_layer_pe=(i == 0),
)
)
self.final_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm_final_attn = nn.LayerNorm(embedding_dim)
def forward(
self,
image_embedding: Tensor,
image_pe: Tensor,
point_embedding: Tensor,
) -> Tuple[Tensor, Tensor]:
"""
参数:
image_embedding (torch.Tensor): 要进行注意力操作的图像。形状应为B x embedding_dim x h x w,其中h和w可以是任意值。
image_pe (torch.Tensor): 添加到图像的位置编码。形状必须与image_embedding相同。
point_embedding (torch.Tensor): 添加到查询点的嵌入。形状必须为B x N_points x embedding_dim,其中N_points可以是任意值。
返回:
torch.Tensor: 处理后的point_embedding
torch.Tensor: 处理后的image_embedding
"""
# BxCxHxW -> BxHWxC == B x N_image_tokens x C
bs, c, h, w = image_embedding.shape
image_embedding = image_embedding.flatten(2).permute(0, 2, 1)
image_pe = image_pe.flatten(2).permute(0, 2, 1)
# 准备查询
queries = point_embedding
keys = image_embedding
# 应用Transformer块和最终的LayerNorm
for layer in self.layers:
queries, keys = layer(
queries=queries,
keys=keys,
query_pe=point_embedding,
key_pe=image_pe,
)
# 应用从点到图像的最终注意力层
q = queries + point_embedding
k = keys + image_pe
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm_final_attn(queries)
return queries, keys
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
num_heads: int,
mlp_dim: int = 2048,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
skip_first_layer_pe: bool = False,
) -> None:
"""
一个具有四个层的Transformer块:
(1) 稀疏输入的自注意力,
(2) 将稀疏输入与密集输入的交叉注意力,
(3) 稀疏输入的MLP块,
(4) 将密集输入与稀疏输入的交叉注意力。
参数:
embedding_dim (int): 嵌入的通道维度
num_heads (int): 注意力层中的头数
mlp_dim (int): MLP块的隐藏维度
activation (nn.Module): MLP块的激活函数
skip_first_layer_pe (bool): 是否跳过第一层的位置编码
"""
super().__init__()
self.self_attn = Attention(embedding_dim, num_heads)
self.norm1 = nn.LayerNorm(embedding_dim)
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
self.norm3 = nn.LayerNorm(embedding_dim)
self.norm4 = nn.LayerNorm(embedding_dim)
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# 自注意力块
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# 交叉注意力块,将token与图像嵌入进行注意力操作
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP块
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# 交叉注意力块,将图像嵌入与token进行注意力操作
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keys
class Attention(nn.Module):
"""
允许在将查询、键和值投影后缩小嵌入大小的注意力层。
"""
def __init__(
self,
embedding_dim: int,
num_heads: int,
downsample_rate: int = 1,
) -> None:
super().__init__()
self.embedding_dim = embedding_dim
self.internal_dim = embedding_dim // downsample_rate
self.num_heads = num_heads
assert self.internal_dim % num_heads == 0, "num_heads must divide embedding_dim."
self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
self.k_proj = nn.Linear(embedding_dim, self.internal_dim)
self.v_proj = nn.Linear(embedding_dim, self.internal_dim)
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
b, n, c = x.shape
x = x.reshape(b, n, num_heads, c // num_heads)
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
def _recombine_heads(self, x: Tensor) -> Tensor:
b, n_heads, n_tokens, c_per_head = x.shape
x = x.transpose(1, 2)
return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
# 输入投影
q = self.q_proj(q)
k = self.k_proj(k)
v = self.v_proj(v)
# 分割为头部
q = self._separate_heads(q, self.num_heads)
k = self._separate_heads(k, self.num_heads)
v = self._separate_heads(v, self.num_heads)
# 注意力操作
_, _, _, c_per_head = q.shape
attn = q @ k.permute(0, 1, 3, 2) # B x N_heads x N_tokens x N_tokens
attn = attn / math.sqrt(c_per_head)
attn = torch.softmax(attn, dim=-1)
# 获取输出
out = attn @ v
out = self._recombine_heads(out)
out = self.out_proj(out)
return out对于下图的右侧部分
- 运行解码器后,我们使用两个转置卷积对更新的图像嵌入进行4倍上采样图层(现在相对于输入图像缩小了4倍)
After running the decoder, we upsample the updated image embedding by 4× with two transposed convolutional 16 layers (now it’s downscaled 4× relative to the input image) - 然后,token再次参与图像嵌入,即将更新的输出token嵌入传递给一个小的3层MLP,该MLP输出一个与升级图像嵌入的通道维数匹配的向量
Then, the tokens attend once more to the image embedding and we pass the updated output token embedding to a small 3-layer MLP that outputs a vector matching the channel dimension of the upscaled image embedding - 最后,我们用升级图像嵌入和 MLP输出之间的空间点积来预测一个掩模
Finally, we predict a mask with a spatially point-wise product between the upscaled image embedding and the MLP’s output
其中,有几个问题值得提一下
- transformer使用的嵌入维度为256,MLP块 的内部尺寸较大,为2048,但是MLP仅应用于提示值相对较少(很少大于20)的提示值。然而,在我们有64× 64图像嵌入的交叉注意力层中,为了计算效率,我们将查询、键和值的通道维度减少了2倍至128,所有的注意力层都使用了8个头
The transformer uses an embedding dimension of 256. The transformer MLP blocks have a large internal dimension of 2048, but the MLP is applied only to the prompt tokens for which there are relatively few (rarely greater than 20). However, in cross-attention layers where we have a 64×64 image embedding, we reduce the channel dimension of the queries, keys, and values by 2× to 128 for computational efficiency. All attention layers use 8 heads. - 用于放大输出图像嵌入的转置卷积是2×2,输出通道维度为64和32的stride 2,并具有GELU激活,最后通过层归一化将它们分开
The transposed convolutions used to upscale the output image embedding are 2×2, stride 2 with output channel dimensions of 64 and 32 and have GELU activations. They are separated by layer normalization. - 为了解决输出模糊性问题(一个提示可能生成多个mask,比如衣服上的一个点,既可以表示衣服,也表示穿衣服的人),预测输出多个masks 「即使用少量输出token并同时预测多个掩码,而不是预测单个掩码,默认情况下预测三个掩码,因为三层(整体、部分和子部分)通常足以描述嵌套的掩码,即three layers (whole, part, and subpart) are often enough to describe nested masks」
在训练过程中,只回传最小的loss,为了对mask进行排序,增加一个小的head预测mask和目标的iou
当输入多个提示时,生成的mask会比较接近,为了减少loss退化和确保获取明确的mask,此时只预测一个mask (作为第4个预测mask,只有多个提示时才预测,当单个提示时不用,即This is accomplished by adding a fourth output token for an additional mask prediction. This fourth mask is never returned for a single prompt and is the only mask returned for multiple prompts.)
其代码实现为 (定义一个MaskDecoder类,用于预测给定图像和提示嵌入的掩码,其使用的Transformer架构。同时,也定义了一个MLP类,即多层感知器网络)
import torch
from torch import nn
from torch.nn import functional as F
from typing import List, Tuple, Type
from .common import LayerNorm2d
# 定义MaskDecoder类,继承自nn.Module
class MaskDecoder(nn.Module):
# 构造函数
def __init__(
self,
*,
transformer_dim: int, # Transformer的维度
transformer: nn.Module,
num_multimask_outputs: int = 3, # 多重掩码输出的数量,默认为3
activation: Type[nn.Module] = nn.GELU, # 激活函数类型,默认为nn.GELU
iou_head_depth: int = 3, # 预测掩码质量的MLP的深度,默认为3
iou_head_hidden_dim: int = 256, # 预测掩码质量的MLP的隐藏维度,默认为256
) -> None:
super().__init__() # 调用父类的初始化函数
self.transformer_dim = transformer_dim # 初始化Transformer的维度
self.transformer = transformer # 初始化Transformer模块
# 初始化多重掩码输出的数量
self.num_multimask_outputs = num_multimask_outputs
self.iou_token = nn.Embedding(1, transformer_dim) # 初始化IOU嵌入
self.num_mask_tokens = num_multimask_outputs + 1 # 初始化掩码token的数量
# 初始化掩码token的嵌入
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
# 初始化输出缩放的网络
self.output_upscaling = nn.Sequential(
# 卷积反卷积2d
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),
LayerNorm2d(transformer_dim // 4),
# 激活函数
activation(),
# 卷积反卷积2d
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
activation(),
)
# 初始化输出超网络的MLP列表
self.output_hypernetworks_mlps = nn.ModuleList(
[
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
# 初始化IOU预测头
self.iou_prediction_head = MLP(
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
# 前向传播函数
def forward(
self,
image_embeddings: torch.Tensor, # 图像的嵌入表示
image_pe: torch.Tensor, # 图像的位置编码
sparse_prompt_embeddings: torch.Tensor, # 稀疏提示的嵌入表示
dense_prompt_embeddings: torch.Tensor, # 密集提示的嵌入表示
multimask_output: bool, # 是否返回多个掩码
) -> Tuple[torch.Tensor, torch.Tensor]: # 预测的掩码
masks, iou_pred = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
)
# 根据multimask_output选择掩码输出
if multimask_output:
mask_slice = slice(1, None)
else:
mask_slice = slice(0, 1)
masks = masks[:, mask_slice, :, :]
iou_pred = iou_pred[:, mask_slice]
# 准备输出
return masks, iou_pred
# 预测掩码函数
def predict_masks(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
# 预测掩码。参考'forward'获取更多细节
"""
# 拼接输出token
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# 在batch方向上扩展每个图像数据,以便在mask上进行处理
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
src = src + dense_prompt_embeddings
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
b, c, h, w = src.shape
# 运行Transformer
hs, src = self.transformer(src, pos_src, tokens)
iou_token_out = hs[:, 0, :]
mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :]
# 缩放mask嵌入并使用mask tokens预测masks
src = src.transpose(1, 2).view(b, c, h, w)
upscaled_embedding = self.output_upscaling(src)
hyper_in_list: List[torch.Tensor] = []
for i in range(self.num_mask_tokens):
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding.shape
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# 生成mask质量预测
iou_pred = self.iou_prediction_head(iou_token_out)
return masks, iou_pred
# MLP类,继承自nn.Module
class MLP(nn.Module):
# 构造函数
def __init__(
self,
input_dim: int, # 输入维度
hidden_dim: int, # 隐藏层维度
output_dim: int, # 输出维度
num_layers: int, # 层数
sigmoid_output: bool = False, # 是否在输出上应用sigmoid函数
) -> None:
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
# 初始化各层
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output
# 前向传播函数
def forward(self, x):
# 遍历每一层,逐层处理输入
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
# 如果sigmoid_output为真,对输出应用sigmoid函数
if self.sigmoid_output:
x = F.sigmoid(x)
return x在分别实现了上述三个结构后,在实际分割时便可以直接调用了
import torch
from torch import nn
from torch.nn import functional as F
from typing import Any, Dict, List, Tuple
from .image_encoder import ImageEncoderViT
from .mask_decoder import MaskDecoder
from .prompt_encoder import PromptEncoder
class Sam(nn.Module):
mask_threshold: float = 0.0
image_format: str = "RGB"
def __init__(
self,
image_encoder: ImageEncoderViT,
prompt_encoder: PromptEncoder,
mask_decoder: MaskDecoder,
pixel_mean: List[float] = [123.675, 116.28, 103.53],
pixel_std: List[float] = [58.395, 57.12, 57.375],
) -> None:
"""
SAM从图像和输入提示中预测对象的遮罩。
参数:
image_encoder (ImageEncoderViT): 用于将图像编码为图像嵌入的主干。
prompt_encoder (PromptEncoder): 对各种类型的输入提示进行编码。
mask_decoder (MaskDecoder): 从图像嵌入和编码的提示中预测遮罩。
pixel_mean (list(float)): 输入图像中像素归一化的平均值。
pixel_std (list(float)): 输入图像中像素归一化的标准差。
"""
super().__init__()
self.image_encoder = image_encoder
self.prompt_encoder = prompt_encoder
self.mask_decoder = mask_decoder
self.register_buffer("pixel_mean", torch.Tensor(pixel_mean).view(-1, 1, 1), False)
self.register_buffer("pixel_std", torch.Tensor(pixel_std).view(-1, 1, 1), False)
@property
def device(self) -> Any:
return self.pixel_mean.device
@torch.no_grad()
def forward(
self,
batched_input: List[Dict[str, Any]],
multimask_output: bool,
) -> List[Dict[str, torch.Tensor]]:
"""
从提供的图像和提示中端到端地预测遮罩。
如果事先不知道提示,建议使用SamPredictor而不是直接调用模型。
参数:
batched_input (list(dict)): 输入图像的列表,每个图像是一个包含以下键的字典。如果不存在提示键,则可以排除。
'image': 图像作为3xHxW格式的torch张量,已经转换为模型输入格式。
'original_size': (tuple(int, int)) 转换前图像的原始大小,格式为(H, W)。
'point_coords': (torch.Tensor) 该图像的批处理点提示,形状为BxNx2。已转换为模型的输入帧。
'point_labels': (torch.Tensor) 批处理点提示的标签,形状为BxN。
'boxes': (torch.Tensor) 批处理的框输入,形状为Bx4。已转换为模型的输入帧。
'mask_inputs': (torch.Tensor) 输入模型的批处理遮罩输入,形式为Bx1xHxW。
multimask_output (bool): 模型是否应该预测多个消除歧义的遮罩,还是返回单个遮罩。
返回:
(list(dict)): 输入图像的列表,每个元素是一个包含以下键的字典。
'masks': (torch.Tensor) 批处理的二进制遮罩预测,形状为BxCxHxW,其中B是输入提示的数量,C由multimask_output决定,(H, W)是图像的原始大小。
'iou_predictions': (torch.Tensor) 遮罩质量的模型预测,形状为BxC。
'low_res_logits': (torch.Tensor) 低分辨率的逻辑张量,形状为BxCxHxW,其中H=W=256。可以作为遮罩输入传递给后续的预测迭代。
"""
input_images = torch.stack([self.preprocess(x["image"]) for x in batched_input], dim=0)
image_embeddings = self.image_encoder(input_images)
outputs = []
for image_record, curr_embedding in zip(batched_input, image_embeddings):
if "point_coords" in image_record:
points = (image_record["point_coords"], image_record["point_labels"])
else:
points = None
sparse_embeddings, dense_embeddings = self.prompt_encoder(
points=points,
boxes=image_record.get("boxes", None),
masks=image_record.get("mask_inputs", None),
)
low_res_masks, iou_predictions = self.mask_decoder(
image_embeddings=curr_embedding.unsqueeze(0),
image_pe=self.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
masks = self.postprocess_masks(
low_res_masks,
input_size=image_record["image"].shape[-2:],
original_size=image_record["original_size"],
)
masks = masks > self.mask_threshold
outputs.append(
{
"masks": masks,
"iou_predictions": iou_predictions,
"low_res_logits": low_res_masks,
}
)
return outputs
def postprocess_masks(
self,
masks: torch.Tensor,
input_size: Tuple[int, ...],
original_size: Tuple[int, ...],
) -> torch.Tensor:
"""
去除填充并将遮罩放大到原始图像大小。
参数:
masks (torch.Tensor): MaskDecoder生成的批处理遮罩,格式为BxCxHxW。
input_size (tuple(int, int)): 输入到模型的图像的大小,格式为(H, W)。用于去除填充。
original_size (tuple(int, int)): 调整为输入模型的图像的原始大小,格式为(H, W)。
返回:
(torch.Tensor): 格式为BxCxHxW的批处理遮罩,其中(H, W)由original_size给出。
"""
masks = F.interpolate(
masks,
(self.image_encoder.img_size, self.image_encoder.img_size),
mode="bilinear",
align_corners=False,
)
masks = masks[..., : input_size[0], : input_size[1]]
masks = F.interpolate(masks, original_size, mode="bilinear", align_corners=False)
return masks
def preprocess(self, x: torch.Tensor) -> torch.Tensor:
"""归一化像素值并填充为方形输入。"""
# 归一化颜色
x = (x - self.pixel_mean) / self.pixel_std
# 填充
h, w = x.shape[-2:]
padh = self.image_encoder.img_size - h
padw = self.image_encoder.img_size - w
x = F.pad(x, (0, padw, 0, padh))
return x1.2.4 模型训练
训练时模拟交互分割的过程,从目标mask中随机选取前景点或者box,点是从gt mask选取,box增加长边10%的噪声,最大20像素
在第一次prompt预测mask之后,后续是从预测mask和gt mask有差异的区域采样点
- 如果新生成的点是FN,则作为前景
- 如果是FP,则作为背景
同时,将预测的mask(unthresholded mask logits代替二值化的mask,不过滤阈值,默认为0),作为prompt作为迭代
训练过程中,发现用8个采样点比较合适(对比16个,没有明显增益),为了鼓励模型从mask中获益,其中2个迭代不用新采样的点,总共11个迭代,一个是初始化的prompt输入,然后是8个上述迭代,再加2个不重新采样点的迭代(这样可以refine mask)。由于mask decoder比较轻,所以可以进行更多次的迭代
- loss
mask 用focal loss和dice loss进行线性组合,系数(20:1),iou 用mse loss - 训练时间
256 A100 GPUs,3-5天(A100价格6万左右,256个,1000多万,你懂的..)
1.3 data engine(数据引擎):辅助人工、半自动、全自动
- 辅助人工标注
通过SAM基于浏览器的交互式分割工具,通过“brush”和"eraser"工具,进行标注。模型可以实时输出mask,建议标注者优先标记他们命名的对象,按图层顺序标记,如果一个mask标记超过30s,先处理下一张
SAM先用公开数据集训练,然后再用新增的标注mask训练。随着数据越多,image-encoder的能力越强,retrained了6次。随着模型改进,每个mask平均标注时间从34s到14s,平均每张图像mask从22增加到44个。在这个过程中,从12万图像中,收集了430万个mask。 - 半自动
增加mask的多样性,首先检测出可信的mask,然后用预测mask填充图像,让标注者标注未标记的mask。为了检测可信的mask,先用第一步的mask训练了一个类别一样的box检测器。半自动过程中,从18万张图像中生成了590万个mask。用新收集的数据,重新训练模型,平均标注时间又回到了34s,因为新的mask都是比较有难度的。每张图像上mask从44增加到72。 - 全自动
利用前2步,得到的大量的和多样性的mask,结合模型可以根据不明确的输入也能输出有效的mask(参考mask encoder),对图像生成(32,32)个格网点,每个点预测一系列mask,如果一个点落在部分、子部分上,模型返回部分、子部分和整体的object。同时,通过预测的iou筛选 confident(可信的mask),选取一个stable的mask(稳定的mask,在相似的mask中,概率阈值在 0.5-δ和 0.5-δ之间);最后,通过nms过滤confident和stable中重复的mask
为了提高mask比较小的,还通过放大图像进行crop,处理多个mask覆盖的情况
最终在1100万数据集上,生成了11亿高质量的mask
数据情况
- 图片:从合作商获取1100万张图像,按短边重采样到1500像素
- mask:99.1%都是自动生成的,通过对比分析,自动生成的mask质量也是非常高的。为了评估质量,随机选500张图像(约5万个mask),让专业的标注人员进行标注,通过对比发现94%的mask有90%以上的iou
- 数据分布更广,从全世界获取数据,mask更多,数据偏向性较小
参考文献与推荐阅读
- Meta发布的SAM原始论文
- 关于SAM论文的几篇解读:【论文解读】MetaAi SAM(Segment Anything) 分割一切、SAM解读PPT