分类目录:《自然语言处理从入门到应用》总目录
相关文章:
· 预训练模型总览:从宏观视角了解预训练模型
· 预训练模型总览:词嵌入的两大范式
· 预训练模型总览:两大任务类型
· 预训练模型总览:预训练模型的拓展
· 预训练模型总览:迁移学习与微调
· 预训练模型总览:预训练模型存在的问题
从大量无标注数据中进行预训练使许多自然语言处理任务获得显著的性能提升。总的来看,预训练模型的优势包括:
- 在庞大的无标注数据上进行预训练可以获取更通用的语言表示,并有利于下游任务
- 为模型提供了一个更好的初始化参数,在目标任务上具备更好的泛化性能、并加速收敛
- 是一种有效的正则化手段,避免在小数据集上过拟合,而一个随机初始化的深层模型容易对小数据集过拟合
下图就是各种预训练模型的思维导图,其分别按照词嵌入(Word Embedding)方式分为静态词向量(Static Word Embedding)和动态词向量(Dynamic Word Embedding)方式分类、按照监督学习和自监督学习方式进行分类、按照拓展能力等分类方式展现:
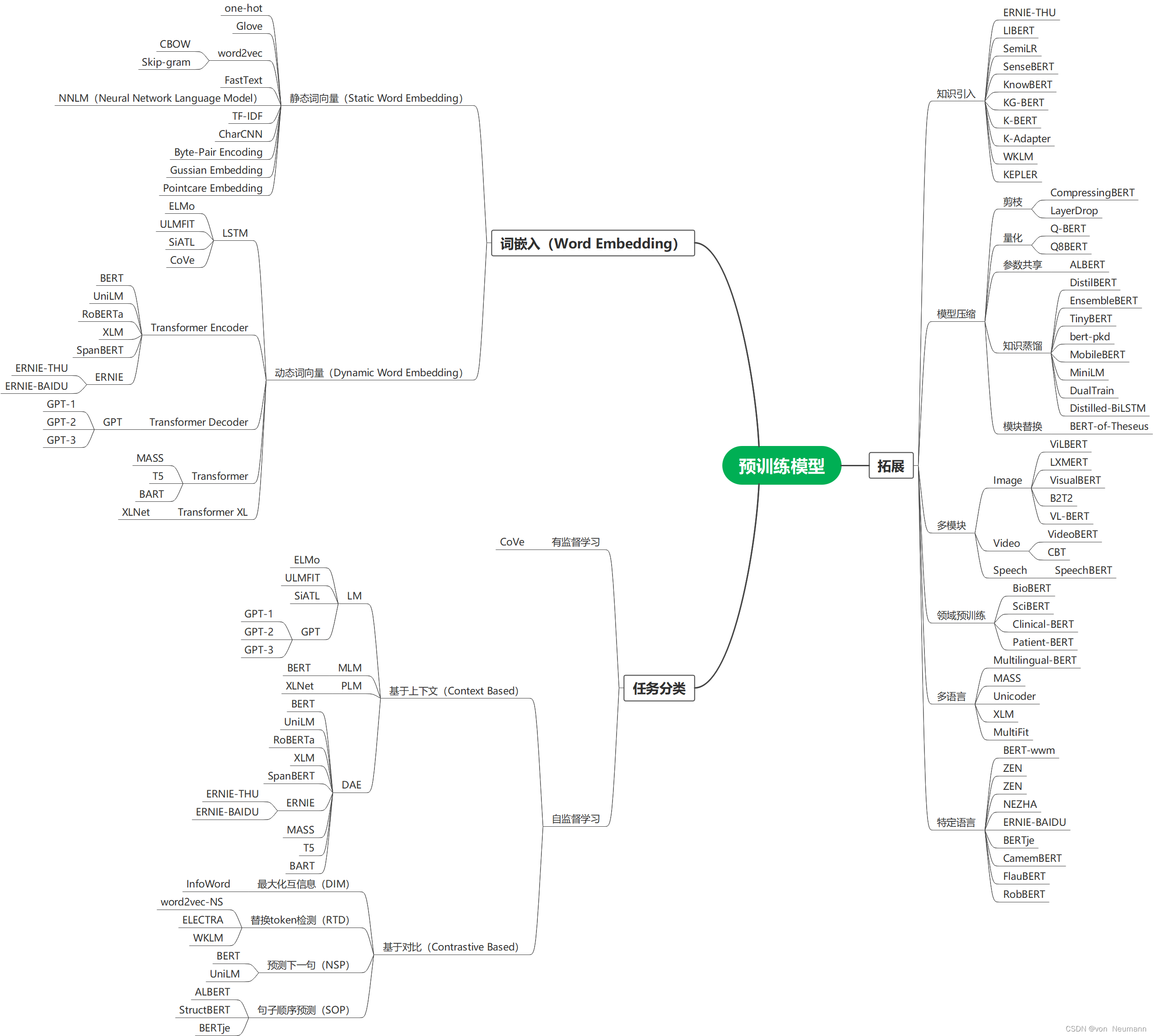
思维导图可编辑源文件下载地址:https://download.csdn.net/download/hy592070616/87954682
虽然预训练模型已经在很多自然语言处理任务中显示出了他们强大的能力,然而由于语言的复杂性,仍存在诸多挑战:
- 预训练模型的上限:目前,预训练模型并没有达到其上限。大多数的预训练模型可通过使用更长训练步长和更大数据集来提升其性能。目前自然语言处理中的SOTA也可通过加深模型层数来更进一步提升。这将导致更加高昂的训练成本。因此,一个更加务实的方向是在现有的软硬件基础上,设计出更高效的模型结构、自监督预训练任务、优化器和训练技巧等。例如, ELECTRA就是此方向上很好的一个解决方案。
- 面向任务的预训练和模型压缩:在实践中,不同的目标任务需要预训练模型拥有不同功能。而预训练模型与下游目标任务间的差异通常在于两方面:模型架构与数据分布。尽管较大的预训练模型通常情况下会带来更好的性能表现,但在低计算资源下如何使用是一个实际问题。例如,对于自然语言处理的预训练模型来说,对于模型压缩的研究只是个开始,Transformer的全连接架构也使得模型压缩具有挑战性。
- 预训练模型的架构设计:对于预训练模型,Transformer已经被证实是一个高效的架构。然而Transformer最大的局限在于其计算复杂度(输入序列长度的平方倍)。受限于GPU显存大小,目前大多数预训练模型无法处理超过512个token的序列长度。打破这一限制需要改进Transformer的结构设计,例如Transformer-XL。
- 微调中的知识迁移:微调是目前将预训练模型的知识转移至下游任务的主要方法,但效率却很低,每个下游任务都需要有特定的微调参数。一个可以改进的解决方案是固定预训练模型的原始参数,并为特定任务添加小型的微调适配器,这样就可以使用共享的预训练模型服务于多个下游任务。
- 预训练模型的解释性与可靠性:预训练模型的可解释性与可靠性仍然需要从各个方面去探索,它能够帮助我们理解预训练模型的工作机制,为更好的使用及性能改进提供指引。
参考文献:
[1] QIU XIPENG, SUN TIANXIANG, XU YIGE, et al. Pre-trained models for natural language processing: A survey[J]. 中国科学:技术科学(英文版),2020.