以下内容为讲课时使用到的泰坦尼克数据集分析、建模过程,整体比较完整,分享出来,希望能帮助大家。部分内容由于版本问题,可能无法顺利运行。
Table of Contents
经典又有趣的Titanic问题
目标
【Jack and Rose】的故事大家都熟悉,然而今天,我们要探讨的问题是我们该如何预测豪华游轮上的乘客的存活状况。也就是说,我们要利用已有的训练和测试数据,其中包含一些乘客的个人信息及存活状况,利用这些信息,生成合适的模型,最终去预测其他人的存活状况。
解决方法
这是一个二分类问题,有很多分类算法都可以用来解决这个问题。我们希望:
- 同学们先从最简单最基础的逻辑回归模型入手,实现逻辑回归算法。
- 再利用其他算法来解决这个问题,进行模型比较或者模型融合,最终给出一个最优的解决方案。
项目目的
通过完成这个项目,我们希望同学们可以学习到:
- 在本地电脑上,完成机器学习建模的的基本流程。
- 能够使用逻辑回归来解决二分类问题。
- 能够运用其他已学习过的分类算法来解决分类问题,进一步理解分类算法。
- 理解并能够运用常用技巧来提高模型的预测准确性。
- 实现你的第一个神经网络。
导入模块
# 进行数据分析和整合数据
import pandas as pd
import numpy as np
import random as rnd
# 用于数据可视化
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# 使用机器学习算法进行建模
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
加载数据
八卦一句,有人的地方就有鄙视链。跟知乎一样。Kaggle的也是个处处呵呵的危险地带。Kaggle上默认把数据放在input文件夹下。所以我们没事儿写个教程什么的,也可以依据这个convention来,显得很入流。
# 使用Pandas分别加载训练数据和测试数据
train_df = pd.read_csv('../input/train.csv')
test_df = pd.read_csv('../input/test.csv')
# 将训练集和测试集合并
combine = [train_df, test_df]
已给的数据描述:
PassengerId/乘客ID
Survived/是否获救 ==> 0/否, 1/是
Pclass/船票等级 ==> 1/上等, 2/中等, 3/下等
Name/乘客姓名
Sex/乘客性别
Age/乘客年龄
SibSp/乘客的堂兄弟或堂妹或配偶的个数
Parch/父母与小孩个数
Ticket/船票号码
Fare/乘客的船票票价
Cabin/客舱号码
Embarked/登船港口 ==> C/Cherbourg, Q/Queenstown, S/Southampton
探索性数据分析
描述性统计分析
了解数据集的总体情况
- 说明:本章节需要回答的问题中,会涉及到一些统计学的专业术语,如果对于术语概念不了解的,推荐大家先阅读相关书籍的介绍,对统计术语理解后,然后再进行回答。
- 推荐书目:
- 数据挖掘
- 深入浅出统计学
# 显示训练集和测试集总体信息
train_df.info()
print ("#"*40)
test_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
########################################
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
# 显示train_df/test_df列数据类型
train_df.dtypes,test_df.dtypes
(PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object,
PassengerId int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object)
# 显示train_df和test_df的行数和特征数量
train_df.shape,test_df.shape
((891, 12), (418, 11))
# 打印训练集和测试集中所有特征列的名称
print(train_df.columns.values)
print("#"*40)
print(test_df.columns.values)
['PassengerId' 'Survived' 'Pclass' 'Name' 'Sex' 'Age' 'SibSp' 'Parch'
'Ticket' 'Fare' 'Cabin' 'Embarked']
########################################
['PassengerId' 'Pclass' 'Name' 'Sex' 'Age' 'SibSp' 'Parch' 'Ticket' 'Fare'
'Cabin' 'Embarked']
问题1:特征在python中的数据类型和数据集基本信息
- 训练集中,哪些特征在python中的数据类型为interger或者floats?
PassengerId,Survived,Pclass,Age,SibSp,Parch,Fare - 训练集中,哪些特征在python中数据类型为Object?
Name,Sex,Ticket,Cabin,Embarked - 训练集中,特征___、___、___有缺失值,测试机中特征___、___、___有缺失值?
Age,Cabin,Embarked; Age,Fare,Cabin - 训练集中,总共有___名乘客的记录,___个特征?
891, 12 - 测试集中,总共有___名乘客的记录,___个特征?
418, 11 - 测试集与训练集相比,缺少特征___?
Survived - 泰坦尼克号上,实际总共有2224人登船,测试集和训练集的样本分别约占总人数的___%,___%(保留整数)?
40,19
预览数据
对于大数据集,我们很难去查看所有的数据记录,然而,我们可以查看其中的多个小样本来了解数据。这些样本可以直接告诉我们哪些特征是需要修正的。
# 显示数据集前5行的记录
train_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
# 显示训练集最后5行的记录
train_df.tail()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.00 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.00 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.45 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.00 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.75 | NaN | Q |
问题2:特征类型
- 特征___是数值和字母数字混合型的数据?
Ticket - 特征___是字母数字型数据?
Cabin - 特征___有可能包含错误或者拼写错误?
Name
提示:Name特征中包含title信息,如Mr.,Miss等,包含括号信息,包含双引号信息。 - 哪些是分类特征?
Survived, Sex, Embarked, Pclass - 哪些分类特征是二分类型?
Survived, Sex - 哪些分类特征是定序类型?
Pclass - 哪些是数值特征?
Age, Fare, SibSp, Parch - 哪些数值特征是连续型特征?
Age, Fare - 哪些数值特征是离散型特征?
SibSp, Parch
了解数据的中心趋势和离散趋势
# python中数据类型为float64和int64的特征信息
train_df.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
# 查看train_df不同特征的分位数,以确定不同特征的分布情况
train_df['Survived'].quantile([.61, .62])
train_df['Parch'].quantile([.75, .8])
train_df['Age'].quantile([.1, .2, .3, .4, .5, .6, .7, .8, .9, .99])
train_df['Fare'].quantile([.1, .2, .3, .4, .5, .6, .7, .8, .9, .99])
0.10 7.55000
0.20 7.85420
0.30 8.05000
0.40 10.50000
0.50 14.45420
0.60 21.67920
0.70 27.00000
0.80 39.68750
0.90 77.95830
0.99 249.00622
Name: Fare, dtype: float64
问题3:统计指标与信息
统计意义上:
- 以上指标中,可以用于度量中心趋势的有___?
mean/均值 - 以上指标中,可以用于度量离散趋势的有___?
std/标准差,极差(min最小值,max最大值),四分位数(25%,50%,75%)
说明:当我们不把50%与25%和75%组合在一起作为四分位数时,而是把它看成一个单独的值时,它实际为中心趋势度量指标的中位数,我们可以通过这个数值来判断特征的大致分布情况。 - 训练集中,有___%的人获救了(保留整数)?
38 - 特征Survived的取值为___和___?
0,1 - 训练集中,三种船票等级中人数最多的是___?
3 - 忽略掉空值,训练集中乘客的平均年龄为___岁(保留一位小数)?
29.7 - 训练集中,特征Parch在75%的位置值为0,说明?
训练集中,75%以上的乘客没有和家人或者孩子一起出行。 - 约有___%的乘客有兄弟姐妹或伴侣一起登船(保留整数)?
30 - 票价为$512的乘客小于___%?
1 - 年龄在65-80岁的乘客小于___%?
1
# python中数据类型为object的特征信息
train_df.describe(include=['O'])
| Name | Sex | Ticket | Cabin | Embarked | |
|---|---|---|---|---|---|
| count | 891 | 891 | 891 | 204 | 889 |
| unique | 891 | 2 | 681 | 147 | 3 |
| top | Braund, Mr. Owen Harris | male | 347082 | B96 B98 | S |
| freq | 1 | 577 | 7 | 4 | 644 |
问题4:区分特征
统计意义上(注意不是以Python中的数据类型来定义的):
- 哪些是分类特征? Survived, Sex, Embarked, Pclass
- 哪些分类特征是二分类型? Survived, Sex
- 哪些分类特征是定序类型? Pclass
- 哪些是数值特征? Age, Fare, SibSp, Parch
- 哪些数值特征是连续型特征? Age, Fare
- 哪些数值特征是离散型特征? SibSp, Parch
特征间相关性的热图
特征间相关性的热图可以帮助我们了解哪些变量可能更重要。
# 定义特征间相关性热图函数,查看变量之间的相关性大小
def plot_correlation_map(df):
corr = df.corr() # 查看的是train_df的特征间相关性
_ , ax = plt.subplots(figsize = (10,8))
cmap = sns.diverging_palette(220,10,as_cmap = True)
_ = sns.heatmap(
corr,
cmap = cmap,
square=True,
cbar_kws={'shrink':.9},
ax=ax,
annot = True,
annot_kws = {'fontsize':12}
)
plot_correlation_map(train_df)

问题5:特征相关性
- 从热图中你能了解到哪些信息?
提示:
1) 所有特征与Survived之间的相关性:
与其他特征相比,Fare,Pclass与Survived相关性较大。Fare与Survived负相关,Pclass与Survived正相关。
2) 除Survived之外,特征之间的相关性特点:
特征之间相关性较强:Age与Pclass负相关,Sibsp与Age负相关,Parch与Sibsp正相关,Fare与Parch正相关。
提出假设
问题6:你想到了哪些可能性?
根据目前我们已经完成的【描述性统计分析】部分提供给我们的信息,我们可以提出以下假设:
- 相关性
了解所有特征与要预测的特征Survival/是否获救之间的关系。 - 处理缺失值
- 我们需要Age特征,它可能与Survived相关。
- 我们需要Fare特征,它可能与Survived相关。
- 我们需要Embarked特征,因为它可能与Survived或其他重要特征相关。
- 数据修正
- Ticket/船票号码特征有可能会被删掉,因为它有22%的比例为重复值,它可能和Survival之间不相关。
- Cabin/客舱号码特征有可能会被删掉,因为它在训练集和测试集的缺失值都很多。
- PassengerId特征有可能删除,有可能和Survival无关。
- Name特征是一个不太能够标准化的特征,它可能和Survival没有直接关系,可能会被删掉。
- 特征提取
- 基于Parch和SibSp创造一个新特征Family,表示登船的家庭成员的数量。
- 基于Name,提取出新特征Title。
- Age离散化处理:基于Age,新建Ageband,将Age转变为分类特征。
- Fare离散化处理:基于Fare,新建FareBand,将Fare转变成分类特征。
- 猜想
- 女性(Sex=female)有更大可能性获救。
- 儿童(Age<?)有更大可能性获救。
- 上等舱位乘客更有可能获救。
- 船票价格高的乘客更有可能获救。
【描述性统计分析】部分提供的信息,只是帮助我们对数据集的总体情况有一个初步的了解,但是对于最终建模和预测结果的帮助非常有限。接下来让我们从其他唯独来详细分析一下数据,探索每个/多个特征与Survived之间的关系,进一步验证自己提出的假设。
关联性分析与数据可视化
接下来,我们将通过关联性分析和数据可视化的方法开始验证以上相关假设。
Survived与每个特征
没有缺失值的特征
Ticket是船票编号,PassengerId是乘客ID和Survived没有太大的关系,不纳入我们的考虑范围。
Sex,Pclass,SibSp和Parch这四个特征没有缺失值,并且对于他们的探索不需要对数据进行处理,所以我们首先来探索这四个特征与Survived之间的关系。
结论:
- Pclass=1和Survived显著相关(>0.5) ==> 猜想#3 ==> Pclass特征将被保留。
- Sex=female的存活率在74% ==> 猜想#1
- SibSp和Parch特征中有些值和Survived无关 ==> 我们可能需要利用这两个特征构造出一个新特征 ==> 特征提取#1
# Pclass与Survived
train_df[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| Pclass | Survived | |
|---|---|---|
| 0 | 1 | 0.629630 |
| 1 | 2 | 0.472826 |
| 2 | 3 | 0.242363 |
# Sex与Survived
train_df[["Sex", "Survived"]].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| Sex | Survived | |
|---|---|---|
| 0 | female | 0.742038 |
| 1 | male | 0.188908 |
# SibSp与Survived
train_df[["SibSp", "Survived"]].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| SibSp | Survived | |
|---|---|---|
| 1 | 1 | 0.535885 |
| 2 | 2 | 0.464286 |
| 0 | 0 | 0.345395 |
| 3 | 3 | 0.250000 |
| 4 | 4 | 0.166667 |
| 5 | 5 | 0.000000 |
| 6 | 8 | 0.000000 |
# Parch与Survived
train_df[["Parch", "Survived"]].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| Parch | Survived | |
|---|---|---|
| 3 | 3 | 0.600000 |
| 1 | 1 | 0.550847 |
| 2 | 2 | 0.500000 |
| 0 | 0 | 0.343658 |
| 5 | 5 | 0.200000 |
| 4 | 4 | 0.000000 |
| 6 | 6 | 0.000000 |
有缺失值的特征
Age与Survived
直方图对于分析连续型特征是非常有帮助的:
- 发现特征变化的特点或模式。
我们可以通过将Age特征的取值分割成多个等长度的连续区间,来观察Age的变化特点或模式。 - 可以使用自定义的宽度相等的条纹来说明样本的分布。
可以帮助我们回答需要自定义特定条纹宽度才能确定的问题。例如,针对这个数据集,我们可以自定义宽度来回答是否幼儿更容易获救这个问题。
备注: Y轴表示乘客的人数
问题7:关于Age特征,你有什么发现或结论?
观察发现:
- 婴儿(Age<=4)的存活率较高
- 老人(Age=80)都存活下来了
- 大部分15-25岁的人没有存活
- 大多数乘客的年龄在15-35岁
结论:
- 我们应该把Age特征放到训练模型中 ==> 猜想#2
- 需要给Age进行缺失值填充处理 ==> 处理缺失值#1
- 应该对Age进行分组处理 ==> 特征提取#3
# Age与Survived
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20) # 年龄每4岁进行分割

Fare与Survived
问题8:关于Fare特征,你有什么发现或结论?
观察发现:
- 票价更高的人更有可能生存(Fare>50区间尤其明显)
结论:
- 我们应该把Fare特征放到训练模型中 ==> 猜想#4
# Fare与Survived
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Fare', bins=30)

Survived与多个特征
数值型特征、定序特征与Survived之间的关系——Pclass、Age&Survived
我们可以通过一幅图来探索多个特征之间的相关性,但是不管是数值特征还是分类特征,它们的取值必须都是数值,不能是字符串。
问题9:Pclass、Age和Survived之间,你有什么发现或结论?
观察发现:
- Pclass=3的乘客最多,但是大部分都是没有获救 ==> 猜想#3
- Pclass=2和Pclass=3中的幼儿大部分都获救了==> 进一步验证了猜想#2
- Pclass=1中的大部分乘客都获救了 ==> 证实猜想#3
- Pclass因乘客的年龄分布而变化。
结论:
考虑将Pclass放入模型训练。
# grid = sns.FacetGrid(train_df, col='Pclass', hue='Survived')
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend();

多个分类特征与Survived之间的关系——Sex、Embarked、Pclass&Survived
接下来,我们来探索多个分类特征与Survived之间的关系。
问题10:Sex、Embarked、Pclass和Survived之间,你有什么发现或结论?
观察发现:
- 女性乘客的获救的可能性高于男性 ==> 猜想#1
- 只有Embarked=C时,男性获救的可能性高于女性。 ==> 这可能是因为Embarked与Pclass相关,进而Pclass与Survived相关,即Embarked与Survived之间不直接相关。
- 与Pclass=2,Embarked为C和Q的情况相比,Pclass=3中,男性存活率更高。 ==> 处理缺失值#2
- 登船港口的不同对Pclass=3和男乘客的存活率有影响。
结论:
- Sex放入模型训练。
- 修正Embarked特征,并将其放入模型训练。
# grid = sns.FacetGrid(train_df, col='Embarked')
grid = sns.FacetGrid(train_df, row='Embarked', size=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()

多个分类特征和数值特征与Survived之间的关系——Sex, Fare,Embarked&Survived
问题11:Sex, Fare,Embarked和Survived之间,你有什么发现或结论?
观察发现:
- 购买票价贵的乘客更有可能获救 ==> 特征提取#4
- 登船港口不同与存活率有关 ==> 处理缺失值#2
结论:后续需要对Fare进行离散化处理。
# grid = sns.FacetGrid(train_df, col='Embarked', hue='Survived', palette={0: 'k', 1: 'w'})
grid = sns.FacetGrid(train_df, row='Embarked', col='Survived', size=2.2, aspect=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()

总结
通过关联性分析和数据可视化的方式对数据进行分析,验证了我们最初提出的假设,这些结论将作为我们下一步工作流程的起点。
数据预处理
基于关联性分析和数据可视化为我们提供的信息,下一步,我们将对特征进行处理相应的处理,最终将每个特征符合放入逻辑回归中特征的要求。
注意:
- 我们要对训练集和测试集进行相同的处理,以保持数据一致性。
在这个参考代码中,我们将测试集和训练集同时进行处理,也可以先处理训练集,然后再处理测试集。 - 如果同学们对这个课件中的不同特征的处理方法有自己的看法,可以按照自己的想法处理。我们只是提供整体思路,希望同学们可以得到更好的预测结果。
删除特征
基于最初的假设,我们将删掉Ticket和Cabin特征。
# 删除前的每个df的结构
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
train_df = train_df.drop(['Ticket','Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
# 删除后的每个df的结构
print("After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
Before (891, 12) (418, 11) (891, 12) (418, 11)
('After', (891, 10), (418, 9), (891, 10), (418, 9))
填补缺失值
通常遇到缺值的情况,我们会有几种常见的处理方式:
- 如果缺失值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了。
- 如果缺失值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中。
- 如果缺失值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个步长(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
- 有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
连续型数值特征
Age
针对这个数据集,第3和4中处理方式应该都是可行的。我们先尝试拟合补全缺失值,虽然这可能并不是一个很好的选择,因为没有太多背景信息来支持拟合,我们只好先试试看。同学们可以自行尝试使用第3种方法来实现对缺失值的处理,并带入模型对比不同方法对模型的影响。
针对拟合补全Age缺失值的处理方法,我们提供两种思路。
思路1:利用需要填补缺失值的特征和其他与之存在相关关系的特征这一特点来填补缺失值。
在这个数据集中,我们已经发现Age,Sex和Pclass三个特征之间是相关的。因此,我们可以利用Sex和Pclass的组合特征来找到这个组合特征下Age上午中位数,用这个中位数来填补缺失值。即我们需要找到Pclass=1和Sex=0时Age的中位数,用这个中位数去填补Pclass=1和Sex=0时,有缺失值的Age。Sex和Pclass共有6中组合,因此,我们需要找到6个中位数去分别填补对应情况下Age的缺失值。
# 建立一个空的数组来存放基于Pclass和Gender组合信息来猜测Age的值
guess_ages = np.zeros((2,3))
guess_ages
array([[0., 0., 0.],
[0., 0., 0.]])
# 将Sex转变值为0,1的变量。
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
# 循环Sex(0, 1)和Pclass(1, 2, 3)来猜测Age的值,共有6中组合
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i) & \
(dataset['Pclass'] == j+1)]['Age'].dropna()
# age_mean = guess_df.mean()
# age_std = guess_df.std()
# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)
age_guess = guess_df.median()
# 将age_guess的值近似为最近的整数
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\
'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
train_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 0 | 22 | 1 | 0 | 7.2500 | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 1 | 38 | 1 | 0 | 71.2833 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 1 | 26 | 0 | 0 | 7.9250 | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 1 | 35 | 1 | 0 | 53.1000 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | 0 | 35 | 0 | 0 | 8.0500 | S |
连续型数值特征常常需要被离散化或面元(bin)划分,使用pandas库中的cut函数实现。
说明:详见5.5.3 连续特征离散化
# 创建AgeBand
train_df['AgeBand'] = pd.cut(train_df['Age'], 5)
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)
| AgeBand | Survived | |
|---|---|---|
| 0 | (-0.08, 16.0] | 0.550000 |
| 1 | (16.0, 32.0] | 0.337374 |
| 2 | (32.0, 48.0] | 0.412037 |
| 3 | (48.0, 64.0] | 0.434783 |
| 4 | (64.0, 80.0] | 0.090909 |
# 根据AgeBand提供的区间切分信息,对Age进行分组处理
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age'] = 4
train_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | AgeBand | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 0 | 1 | 1 | 0 | 7.2500 | S | (16.0, 32.0] |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 1 | 2 | 1 | 0 | 71.2833 | C | (32.0, 48.0] |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 1 | 1 | 0 | 0 | 7.9250 | S | (16.0, 32.0] |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 1 | 2 | 1 | 0 | 53.1000 | S | (32.0, 48.0] |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | 0 | 2 | 0 | 0 | 8.0500 | S | (32.0, 48.0] |
# 删掉AgeBand,更新combine
train_df = train_df.drop(['AgeBand'], axis=1)
combine = [train_df, test_df]
train_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 0 | 1 | 1 | 0 | 7.2500 | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 1 | 2 | 1 | 0 | 71.2833 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 1 | 1 | 0 | 0 | 7.9250 | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 1 | 2 | 1 | 0 | 53.1000 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | 0 | 2 | 0 | 0 | 8.0500 | S |
思路2:使用scikit-learn中的RandomForest来拟合Age的缺失值。
注意:使用思路1方法处理完数据后,不能直接使用下面的代码会报错误,因为:
- Parch和SibSp特征已经被删除。
- Age特征已经被思路1的方法修改了,原始值已经被改变。
# # 使用RandomForestClassifier填补年龄的缺失值
# from sklearn.ensemble import RandomForestRegressor
# def set_missing_ages(df):
# # 把已有的数值型特征取出来丢进Random Forest Regressor中
# age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# # 乘客分成已知年龄和未知年龄两部分
# known_age = age_df[age_df.Age.notnull()].values
# unknown_age = age_df[age_df.Age.isnull()].values
# print(unknown_age)
# # y即目标年龄
# y = known_age[:, 0]
# # X即特征属性值
# X = known_age[:, 1:]
# # fit到RandomForestRegressor之中
# rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
# rfr.fit(X, y)
# # 用得到的模型进行未知年龄结果预测
# predictedAges = rfr.predict(unknown_age[:, 1::])
# # 用得到的预测结果填补原缺失数据
# df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges
# return df, rfr
# # 处理训练集Age特征
# train_df, rfr = set_missing_ages(train_df)
# train_df.head(10)
Fare
对测试集中的Fare特征进行处理。
处理步骤:
- 填补缺失值:使用Fare的中位数去填补缺失值。
- 离散化
- 保留两位小数,因为Fare代表货币。
# 使用中位数测试集中的Fare的空值进行填充
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
test_df.head()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | 0 | 2 | 0 | 0 | 7.8292 | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | 1 | 2 | 1 | 0 | 7.0000 | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | 0 | 3 | 0 | 0 | 9.6875 | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | 0 | 1 | 0 | 0 | 8.6625 | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | 1 | 1 | 1 | 1 | 12.2875 | S |
# 创造FareBand特征
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4) # 分成4份
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)
| FareBand | Survived | |
|---|---|---|
| 0 | (-0.001, 7.91] | 0.197309 |
| 1 | (7.91, 14.454] | 0.303571 |
| 2 | (14.454, 31.0] | 0.454955 |
| 3 | (31.0, 512.329] | 0.581081 |
# 基于FareBand将Fare转变为定序特征
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
# 删掉FareBand
train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]
train_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 0 | 1 | 1 | 0 | 0 | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 1 | 2 | 1 | 0 | 3 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 1 | 1 | 0 | 0 | 1 | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 1 | 2 | 1 | 0 | 3 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | 0 | 2 | 0 | 0 | 1 | S |
分类特征——Embarked
训练集中Embarked特征有两个缺失值,我们现在用Embarked的众数去填补缺失值。
# 查看非空Embarked特征的众数
freq_port = train_df.Embarked.dropna().mode()[0]
freq_port
'S'
# 将使用众数对Embarked的空值进行填充
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| Embarked | Survived | |
|---|---|---|
| 0 | C | 0.553571 |
| 1 | Q | 0.389610 |
| 2 | S | 0.339009 |
# 转变成数值特征
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
train_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 0 | 1 | 1 | 0 | 0 | 0 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 1 | 2 | 1 | 0 | 3 | 1 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 1 | 1 | 0 | 0 | 1 | 0 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 1 | 2 | 1 | 0 | 3 | 0 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | 0 | 2 | 0 | 0 | 1 | 0 |
特征提取
从已有特征中提取新特征——Name提取Title
我们想分析Name特征是否能够提取title信息,并验证title与Survived之间的相关性。
观察发现:
当我们绘制称呼、年龄和Survived时,我们注意到以下几点:
- 多数称呼与年龄段相对应,例如:称呼为master的人,平均年龄为5岁。
- 称呼年龄段的存活率略有差别。
- 称呼为Mme,Lady和Sir的人更有可能获救,称呼为Don,Rev和Jonkheer的人获救的可能性很低。
结论: 保留Title特征,放入模型进行训练。
# 通过正则表达式提取所有title字符串
# ([A-Za-z]+)\. 匹配符号“.”之前第一个单词
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.', expand=False) # expand=False返回一个DataFrame
# 交叉表查看提取出的title与sex关系
pd.crosstab(train_df['Title'], train_df['Sex'])
| Sex | 0 | 1 |
|---|---|---|
| Title | ||
| Capt | 1 | 0 |
| Col | 2 | 0 |
| Countess | 0 | 1 |
| Don | 1 | 0 |
| Dr | 6 | 1 |
| Jonkheer | 1 | 0 |
| Lady | 0 | 1 |
| Major | 2 | 0 |
| Master | 40 | 0 |
| Miss | 0 | 182 |
| Mlle | 0 | 2 |
| Mme | 0 | 1 |
| Mr | 517 | 0 |
| Mrs | 0 | 125 |
| Ms | 0 | 1 |
| Rev | 6 | 0 |
| Sir | 1 | 0 |
# 交叉表查看提取出的title与Survived关系
pd.crosstab(train_df['Title'], train_df['Survived'])
| Survived | 0 | 1 |
|---|---|---|
| Title | ||
| Capt | 1 | 0 |
| Col | 1 | 1 |
| Countess | 0 | 1 |
| Don | 1 | 0 |
| Dr | 4 | 3 |
| Jonkheer | 1 | 0 |
| Lady | 0 | 1 |
| Major | 1 | 1 |
| Master | 17 | 23 |
| Miss | 55 | 127 |
| Mlle | 0 | 2 |
| Mme | 0 | 1 |
| Mr | 436 | 81 |
| Mrs | 26 | 99 |
| Ms | 0 | 1 |
| Rev | 6 | 0 |
| Sir | 0 | 1 |
# 将有相同title的文本进行替换,或者归为Rare类
# 对于当时外国称呼的说明,可以参考:https://zhidao.baidu.com/question/591037721.html
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady' ,'Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace(['Mlle', 'Ms'], 'Miss')
dataset['Title'] = dataset['Title'].replace(['Mme','Countess'], 'Mrs')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()
| Title | Survived | |
|---|---|---|
| 0 | Master | 0.575000 |
| 1 | Miss | 0.702703 |
| 2 | Mr | 0.156673 |
| 3 | Mrs | 0.795276 |
| 4 | Rare | 0.318182 |
# 对应分类
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 1 | 2 | 1 | 0 | 3 | 1 | 3 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 1 | 1 | 0 | 0 | 1 | 0 | 2 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 1 | 2 | 1 | 0 | 3 | 0 | 3 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | 0 | 2 | 0 | 0 | 1 | 0 | 1 |
# 在训练集和测试集中都删除Name,把PassengerId从训练集中删除
train_df = train_df.drop(['Name'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
train_df.shape, test_df.shape
((891, 10), (418, 9))
特征组合创建新特征
我们可以将Parch和SibSp组合获得新特征FamilySize,我们发现FamilySize中有两个取值Survived取值为零。进而创建新特征IsAlone,判断乘客是否是一个登船。
# 组合Parch和SibSp特征创建FamilySize
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| FamilySize | Survived | |
|---|---|---|
| 3 | 4 | 0.724138 |
| 2 | 3 | 0.578431 |
| 1 | 2 | 0.552795 |
| 6 | 7 | 0.333333 |
| 0 | 1 | 0.303538 |
| 4 | 5 | 0.200000 |
| 5 | 6 | 0.136364 |
| 7 | 8 | 0.000000 |
| 8 | 11 | 0.000000 |
# 创建IsAlone特征
for dataset in combine:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()
| IsAlone | Survived | |
|---|---|---|
| 0 | 0 | 0.505650 |
| 1 | 1 | 0.303538 |
# 在train_df,test_df删掉Parch,SibSp和FamilySize
train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]
train_df.head()
| PassengerId | Survived | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 0 | 1 | 0 | 0 | 1 | 0 |
| 1 | 2 | 1 | 1 | 1 | 2 | 3 | 1 | 3 | 0 |
| 2 | 3 | 1 | 3 | 1 | 1 | 1 | 0 | 2 | 1 |
| 3 | 4 | 1 | 1 | 1 | 2 | 3 | 0 | 3 | 0 |
| 4 | 5 | 0 | 3 | 0 | 2 | 1 | 0 | 1 | 1 |
交叉特征
交叉特征指的是将两个或更多的类别属性组合成一个新特征。值得注意的是,当数据量较大时,或者暴力进行特征交叉时,交叉后的新特征容易产生数据稀疏问题,同学们在未来应用这个方法的时,需要特别去处理数据稀疏问题。
针对这个数据集,我们已经在5.2.1.1 Age部分对Age特征按照区间定义了不同类别。在这个Age类别和Pclass类别的基础上,通过特征交叉的方法,建立新特征Age*PClass。
如果同学们认为,在这个数据集中,还有其他分类特征的交叉能够对模型预测有帮助,也可以尝试。
# 创建交叉特征Age*Class
for dataset in combine:
dataset['Age*Class'] = dataset.Age * dataset.Pclass
train_df.loc[:, ['Age*Class', 'Age', 'Pclass']].head(10)
| Age*Class | Age | Pclass | |
|---|---|---|---|
| 0 | 3 | 1 | 3 |
| 1 | 2 | 2 | 1 |
| 2 | 3 | 1 | 3 |
| 3 | 2 | 2 | 1 |
| 4 | 6 | 2 | 3 |
| 5 | 3 | 1 | 3 |
| 6 | 3 | 3 | 1 |
| 7 | 0 | 0 | 3 |
| 8 | 3 | 1 | 3 |
| 9 | 0 | 0 | 2 |
特征缩放
# 将一些变化幅度较大的特征化到[-1,1]之内,这样可以加速logistic regression的收敛
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(train_df['Age'].values.reshape(-1, 1))
train_df['Age_scaled'] = scaler.fit_transform(train_df['Age'].values.reshape(-1, 1), age_scale_param)
fare_scale_param = scaler.fit(train_df['Fare'].values.reshape(-1, 1))
train_df['Fare_scaled'] = scaler.fit_transform(train_df['Fare'].values.reshape(-1, 1), fare_scale_param)
train_df
| PassengerId | Survived | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | Age_scaled | Fare_scaled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 0 | 1 | 0 | 0 | 1 | 0 | 3 | -0.392999 | -1.346777 |
| 1 | 2 | 1 | 1 | 1 | 2 | 3 | 1 | 3 | 0 | 2 | 0.827078 | 1.337738 |
| 2 | 3 | 1 | 3 | 1 | 1 | 1 | 0 | 2 | 1 | 3 | -0.392999 | -0.451938 |
| 3 | 4 | 1 | 1 | 1 | 2 | 3 | 0 | 3 | 0 | 2 | 0.827078 | 1.337738 |
| 4 | 5 | 0 | 3 | 0 | 2 | 1 | 0 | 1 | 1 | 6 | 0.827078 | -0.451938 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | 0 | 1 | 1 | 0 | 5 | 1 | 2 | -0.392999 | -0.451938 |
| 887 | 888 | 1 | 1 | 1 | 1 | 2 | 0 | 2 | 1 | 1 | -0.392999 | 0.442900 |
| 888 | 889 | 0 | 3 | 1 | 1 | 2 | 0 | 2 | 0 | 3 | -0.392999 | 0.442900 |
| 889 | 890 | 1 | 1 | 0 | 1 | 2 | 1 | 1 | 1 | 1 | -0.392999 | 0.442900 |
| 890 | 891 | 0 | 3 | 0 | 1 | 0 | 2 | 1 | 1 | 3 | -0.392999 | -1.346777 |
891 rows × 12 columns
问题12:如果直接将Age和Fare的连续数值特征放入逻辑回归模型中,其他特征不变的情况,最终预测结果会有怎样的变化?为什么会有这种变化?
有的时候,特征与Survived小幅相关,并不意味着这个特征作用不大,有可能是我们细化的程度还不够,举个例子,Fare特征如果对它离散化,再分至各个乘客等级上会有更高的权重?
特征因子化/one-hot编码
因为逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化/one-hot编码。
对于连续特征,如年龄、薪水、阅读数、身高等特征,如果需要放入逻辑回归模型中,则最好先进行离散处理,也叫 one-hot 编码;离散化处理的方式有几种,
什么是one-hot编码
一些属性是类别型而不是数值型,拿这个数据集中的Embarked来举例说明。Embarked由{S,C,Q}三个类别组成,最常用的方式是把每个类别属性转换成二元属性,即从{0,1}取一个值。因此基本上增加的属性等于相应数目的类别,并且对于你数据集中的每个实例,只有一个是1(其他的为0),这也就是独热(one-hot)编码方式。
以Embarked为例,原本一个属性维度,因为其取值可以是[‘S’,’C’,’Q‘],one-hot编码后将其平展开为’Embarked_C’,’Embarked_S’, ‘Embarked_Q’三个属性。
- 原本Embarked取值为S的,在此处的”Embarked_S”下取值为1,在’Embarked_C’, ‘Embarked_Q’下取值为0
- 原本Embarked取值为C的,在此处的”Embarked_C”下取值为1,在’Embarked_S’, ‘Embarked_Q’下取值为0
- 原本Embarked取值为Q的,在此处的”Embarked_Q”下取值为1,在’Embarked_C’, ‘Embarked_S’下取值为0
即{1,0,0}表示Embarked取值为S,{0,1,0}表示Embarked取值为C,{0,0,1}表示Embarked取值为Q。
one-hot编码必要性
如果你不了解这个编码的话,你可能会觉得分解会增加没必要的麻烦,因为独热编码大量地增加了数据集的维度。相反,你可能会尝试将类别属性转换成一个标量值,例如Embarked可能会用{1,2,3}表示{S,C,Q}。这里存在两个问题:
- 对于一个数学模型,这意味着某种意义上S和C比和Q更“相似”(因为|1-3| > |1-2|)。除非你的类别拥有排序的属性(比如铁路线上的站),这样可能会误导你的模型。
- 可能会导致统计指标(比如均值)无意义,更糟糕的情况是会误导你的模型。例如颜色属性可能会用{1,2,3}表示{红,绿,蓝},假如你的数据集包含相同数量的红色和蓝色的实例,但是没有绿色的,那么颜色的均值可能还是得到2,也就是绿色的意思。
连续特征离散化
实际上,针对这个数据集中的Age和Fare特征,我们已经在5.2.1 连续型数值特征进行了等值分桶处理,将两个特征转变为分类特征。
在这里,我们系统的说明一下对连续特征进行one-hot编码常用的三种方法:
- 等值分桶
等值分桶是指每个区间同样大小,比如年龄特征区间为0-80岁。我们可以设定为每隔4岁为一个桶,则年龄特征被切分为20个区间,26岁对应的独热编码对应的应该就是{0,0,0,0,0,0,1,0…}。 - 等频分桶
等频分桶是指每个区间里的人数分布基本持平。因此,需要先对样本进行一个分布的统计。仍然以年龄为例,我们首先要制作一个年龄分布的直方图,了解年龄特征的总体分布。一般这类特征都会大致符合正太分布。这就需要对中间较为集中的区间拆分出跟多的桶。比如年龄特征分布的两边边缘区域,我们设定为0-18一个区间,50-80一个区间;在特征分布的集中区域,我们设定为每2岁一个区间,即18-20一个区间,20-22一个区间,以此类推。最终达到使得每个桶的人数基本相等。
如 0-18一个区间,18-20一个区间,20-22一个区间,20-30 一个区间。 - 根据对业务的理解分桶
例如对于电商类,可能22岁以下的没有什么经济能力,22-40的经济能力差不多,这时候可以人工根据业务需求划分。
总结:
对于连续型数值特征,我们有两种处理方法,一种是离散化,如5.2.1连续型数值特征部分处理过程,另一种是5.4 特征缩放将连续之缩放到符合模型要求的区间内。
# 对train_df和test_df中需要进行one-hot编码的进行处理
train_df = pd.get_dummies(train_df,columns=['Pclass', 'Sex', 'Embarked','Title','IsAlone','Age','Fare'])
test_df = pd.get_dummies(test_df,columns=['Pclass', 'Sex', 'Embarked','Title','IsAlone','Age','Fare'])
combine = [train_df, test_df]
# 查看one-hot编码数据结果
train_df.head()
| PassengerId | Survived | Age*Class | Age_scaled | Fare_scaled | Pclass_1 | Pclass_2 | Pclass_3 | Sex_0 | Sex_1 | ... | IsAlone_1 | Age_0 | Age_1 | Age_2 | Age_3 | Age_4 | Fare_0 | Fare_1 | Fare_2 | Fare_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | -0.392999 | -1.346777 | 0 | 0 | 1 | 1 | 0 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 2 | 1 | 2 | 0.827078 | 1.337738 | 1 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 3 | 1 | 3 | -0.392999 | -0.451938 | 0 | 0 | 1 | 0 | 1 | ... | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 4 | 1 | 2 | 0.827078 | 1.337738 | 1 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 5 | 0 | 6 | 0.827078 | -0.451938 | 0 | 0 | 1 | 1 | 0 | ... | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
5 rows × 29 columns
# 确认是否分类特征全部进行one-hot编码
train_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 29 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Age*Class 891 non-null int64
3 Age_scaled 891 non-null float64
4 Fare_scaled 891 non-null float64
5 Pclass_1 891 non-null uint8
6 Pclass_2 891 non-null uint8
7 Pclass_3 891 non-null uint8
8 Sex_0 891 non-null uint8
9 Sex_1 891 non-null uint8
10 Embarked_0 891 non-null uint8
11 Embarked_1 891 non-null uint8
12 Embarked_2 891 non-null uint8
13 Title_1 891 non-null uint8
14 Title_2 891 non-null uint8
15 Title_3 891 non-null uint8
16 Title_4 891 non-null uint8
17 Title_5 891 non-null uint8
18 IsAlone_0 891 non-null uint8
19 IsAlone_1 891 non-null uint8
20 Age_0 891 non-null uint8
21 Age_1 891 non-null uint8
22 Age_2 891 non-null uint8
23 Age_3 891 non-null uint8
24 Age_4 891 non-null uint8
25 Fare_0 891 non-null uint8
26 Fare_1 891 non-null uint8
27 Fare_2 891 non-null uint8
28 Fare_3 891 non-null uint8
dtypes: float64(2), int64(3), uint8(24)
memory usage: 55.8 KB
逻辑回归
我们终于可以建模了!
# 准备放入模型中的最终训练数据和测试数据
X_train = train_df.drop(["Survived","PassengerId"], axis=1)
Y_train = train_df["Survived"]
X_test = test_df.drop("PassengerId", axis=1).copy()
X_train.shape, Y_train.shape, X_test.shape
((891, 27), (891,), (418, 25))
x_1=X_train.columns
x_2=X_test.columns
[x for x in x_1 if x in x_1 and not x in x_2]
['Age_scaled', 'Fare_scaled']
del X_train["Age_scaled"]
del X_train["Fare_scaled"]
# Logistic Regression
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_test)
acc_log = round(logreg.score(X_train, Y_train) * 100, 2)
acc_log
81.71
# 输出预测结果
lr_result = pd.DataFrame({"PassengerId": test_df["PassengerId"],"Survived": Y_pred})
lr_result.to_csv('../input/logistic_regression_bagging_predictions.csv', index=False)
from sklearn.ensemble import BaggingRegressor
# fit到BaggingRegressor之中
logreg = LogisticRegression()
bagging_clf = BaggingRegressor(logreg, n_estimators=25, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
ensemble = bagging_clf.fit(X_train, Y_train)
predictions = bagging_clf.predict(X_test)
acc_bagging = round(ensemble.score(X_train, Y_train) * 100, 2)
acc_bagging
34.39
模型系数分析
我们可以通过每个特征的相关系数的值来判断每个特征对于最终预测结果的影响程度。
- 相关系数绝对值大小:相关系数的绝对值越大,即越接近1,关系越强;相关系数的绝对值越小,即越接近0,关系越弱。
- 相关系数正负号:相关系数为正数,则正相关;相关系数为负数,则减负相关。
coeff_df = pd.DataFrame(train_df.columns.delete(0))
coeff_df.columns = ['Feature']
coeff_df["Correlation"] = pd.Series(logreg.coef_[0]) # 获得特征的相关系数
coeff_df
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Input In [68], in <cell line: 3>()
1 coeff_df = pd.DataFrame(train_df.columns.delete(0))
2 coeff_df.columns = ['Feature']
----> 3 coeff_df["Correlation"] = pd.Series(logreg.coef_[0]) # 获得特征的相关系数
4 coeff_df
AttributeError: 'LogisticRegression' object has no attribute 'coef_'
# 根据相关系数的大小从高到底排序
coeff_df.sort_values(by='Correlation', ascending=False)
问题13:如何解释特征权重?从特征工程的角度,还有什么可以优化?
- Sex:female会极大提高最后获救的概率,male会很大程度拉低这个概率。
- Pclass:1等舱乘客最后获救的概率会上升,而乘客等级为3会极大地拉低这个概率。
- Age:是一个负相关,意味着在我们的模型里,年龄越小,越有获救的优先权(还得回原数据看看这个是否合理)
- Embarked:登船港口S会很拉低获救的概率,另外俩港口提高获救的概率。
- Fare:船票价格低会拉高获救的概率,船票价格高的会拉低获救的概率(这个和我们对Fare分布的判断结果不太符合,需要对这个变量进一步进行细化处理)。
- Title:Mrs和Master会提高获救的概率,Mr,Miss和Rare会拉低获救的概率。
- IsAlone:独自一人登船的人会拉低获救的概率,有家人同行的人会提高获救的概率。
- Age*Class是一个不错的特征,它的相关系数的绝对值没有很低。
到目前为止,总算是把模型建完,得到了一个baseline的预测结果了!有没有尝试把自己跑出来的预测结果提交到Kaggle上去看看自己的名次?
难道你真的以为只要完成数据预处理,再用sklearn跑完所有可能的算法,挑选一个预测效果最好的结果提交,这样就大功告成了嘛?
看到自己现在的排名,没有想过进一步优化嘛?
万里长征才刚刚开始,我们还是继续干活儿吧!
逻辑回归优化
交叉验证
交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。
也就是说,我们把题目中所给的训练集当成一个原始数据,将这个数据切分成训练集和测试集。利用切分出的训练集进行训练,切分出的测试集进行验证。
常见类型的交叉验证
1. 重复随机子抽样验证
将数据集随机的划分为训练集和测试集。对每一个划分,用训练集训练分类器或模型,用测试集评估预测的精确度。进行多次划分,用均值来表示效能。
优点:与k倍交叉验证相比,这种方法的与k无关。
缺点:有些数据可能从未做过训练或测试数据;而有些数据不止一次选为训练或测试数据。
2. K倍交叉验证(K>=2)
将样本数据集随机划分为K个子集(一般是均分),将一个子集数据作为测试集,其余的K-1组子集作为训练集;将K个子集轮流作为测试集,重复上述过程,这样得到了K个分类器或模型,并利用测试集得到了K个分类器或模型的分类准确率。用K个分类准确率的平均值作为分类器或模型的性能指标。10-倍交叉证实是比较常用的。
优点:每一个样本数据都即被用作训练数据,也被用作测试数据。避免的过度学习和欠学习状态的发生,得到的结果比较具有说服力。
3. 留一法交叉验证
假设样本数据集中有N个样本数据。将每个样本单独作为测试集,其余N-1个样本作为训练集,这样得到了N个分类器或模型,用这N个分类器或模型的分类准确率的平均数作为此分类器的性能指标。
优点:每一个分类器或模型都是用几乎所有的样本来训练模型,最接近样本,这样评估所得的结果比较可靠。实验没有随机因素,整个过程是可重复的。
缺点:计算成本高,当N非常大时,计算耗时。
训练集和测试集的选取
- 训练集中样本数量要足够多,一般至少大于总样本数的50%。
- 训练集和测试集必须从完整的数据集中均匀取样。均匀取样的目的是希望减少训练集、测试集与原数据集之间的偏差。当样本数量足够多时,通过随机取样,便可以实现均匀取样的效果。(随机取样,可重复性差)
from sklearn.model_selection import cross_val_score
from sklearn import linear_model
#简单看看打分情况
clf = linear_model.LogisticRegression(C=1.0, penalty='l2', tol=1e-6)
X = train_df.values[:,1:]
y = train_df.values[:,0]
# 交叉验证的结果
cross_val_score(clf, X_train, Y_train, cv=5) # cv=5,5倍交叉验证
array([0.79888268, 0.80337079, 0.81460674, 0.78651685, 0.83146067])
我们已经进行了交叉验证,其实我们可以把交叉验证里预测错误的记录拿出来,通过人工审核,去帮助我们发现新的优化方向,继续探索。
对于以下方法对应的参数不了解的,可以参考官方文档说明:
linear_model.LogisticRegression官方文档说明
cross_validation.cross_val_score官方文档说明
cross_validation.train_test_split官方文档说明
from sklearn.model_selection import train_test_split
# 分割数据,按照 训练数据:cv数据 = 7:3的比例
split_train, split_cv = train_test_split(train_df, test_size=0.3, random_state=0) # test_size测试集占数据的比例
train_df = split_train
# 生成模型
clf = linear_model.LogisticRegression(C=1.0, penalty='l2', tol=1e-6)
clf.fit(train_df.values[:,1:], train_df.values[:,0])
# 对cross validation数据进行预测
cv_df = split_cv
predictions = clf.predict(cv_df.values[:,1:])
origin_data_train = pd.read_csv("../input/train.csv")
# 交叉验证没有预测对的记录
bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.values[:,0]]['PassengerId'].values)]
bad_cases
D:\Anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 32 | 33 | 1 | 3 | Glynn, Miss. Mary Agatha | female | NaN | 0 | 0 | 335677 | 7.7500 | NaN | Q |
| 67 | 68 | 0 | 3 | Crease, Mr. Ernest James | male | 19.0 | 0 | 0 | S.P. 3464 | 8.1583 | NaN | S |
| 87 | 88 | 0 | 3 | Slocovski, Mr. Selman Francis | male | NaN | 0 | 0 | SOTON/OQ 392086 | 8.0500 | NaN | S |
| 88 | 89 | 1 | 1 | Fortune, Miss. Mabel Helen | female | 23.0 | 3 | 2 | 19950 | 263.0000 | C23 C25 C27 | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 858 | 859 | 1 | 3 | Baclini, Mrs. Solomon (Latifa Qurban) | female | 24.0 | 0 | 3 | 2666 | 19.2583 | NaN | C |
| 861 | 862 | 0 | 2 | Giles, Mr. Frederick Edward | male | 21.0 | 1 | 0 | 28134 | 11.5000 | NaN | S |
| 866 | 867 | 1 | 2 | Duran y More, Miss. Asuncion | female | 27.0 | 1 | 0 | SC/PARIS 2149 | 13.8583 | NaN | C |
| 879 | 880 | 1 | 1 | Potter, Mrs. Thomas Jr (Lily Alexenia Wilson) | female | 56.0 | 0 | 1 | 11767 | 83.1583 | C50 | C |
| 881 | 882 | 0 | 3 | Markun, Mr. Johann | male | 33.0 | 0 | 0 | 349257 | 7.8958 | NaN | S |
64 rows × 12 columns
观察这些预测错误的记录,提出新的优化方向,继续尝试挖掘,可能还可以想到更多可以细挖的部分。将新的特征和已有特征组合在一起,查看模型预测准确度是否有所提升。继续迭代下去。
问题14:观察这些预测错误的记录,你还能想到什么优化的方向?
仅供参考:
- Fare细化处理,可能可以考虑将Fare与乘客等级Pclass相关连。
- 可以考虑将除Age*Class之外的分类特征进行特征交叉。
- 可能考虑加入Cabin特征,并进一步对其进行细化研究。
模型状态判断(欠拟合or过拟合)
当我们不断地丰富特征时,模型对训练集拟合越来越好,有可能同时在丧失泛华能力,对测试集变现不佳,存在过拟合问题。而我们最终的目的是希望我们训练的出来的模型,不仅能对训练数据集有很好的预测效果,更希望它对测试数据集也有很好的预测效果。过拟合问题是机器学习建模过程中常见的问题。
实际上,如果模型在测试集上表现不佳,除了过拟合问题,也有可能出现欠拟合问题,也就是说在训练集上,其实拟合的也不是那么好。
什么是欠拟合/过拟合
举个来说:
过拟合就像是你班那个学数学比较刻板的同学,老师讲过的题目,一字不漏全记下来了,于是老师再出一样的题目,分分钟精确出结果。but数学考试,因为总是碰到新题目,所以成绩不咋地。
欠拟合就像是连老师讲的练习题也记不住的同学,于是连老师出一样题目复习的周测都做不好,考试更是可想而知了。
经典解释
解释1
解释2

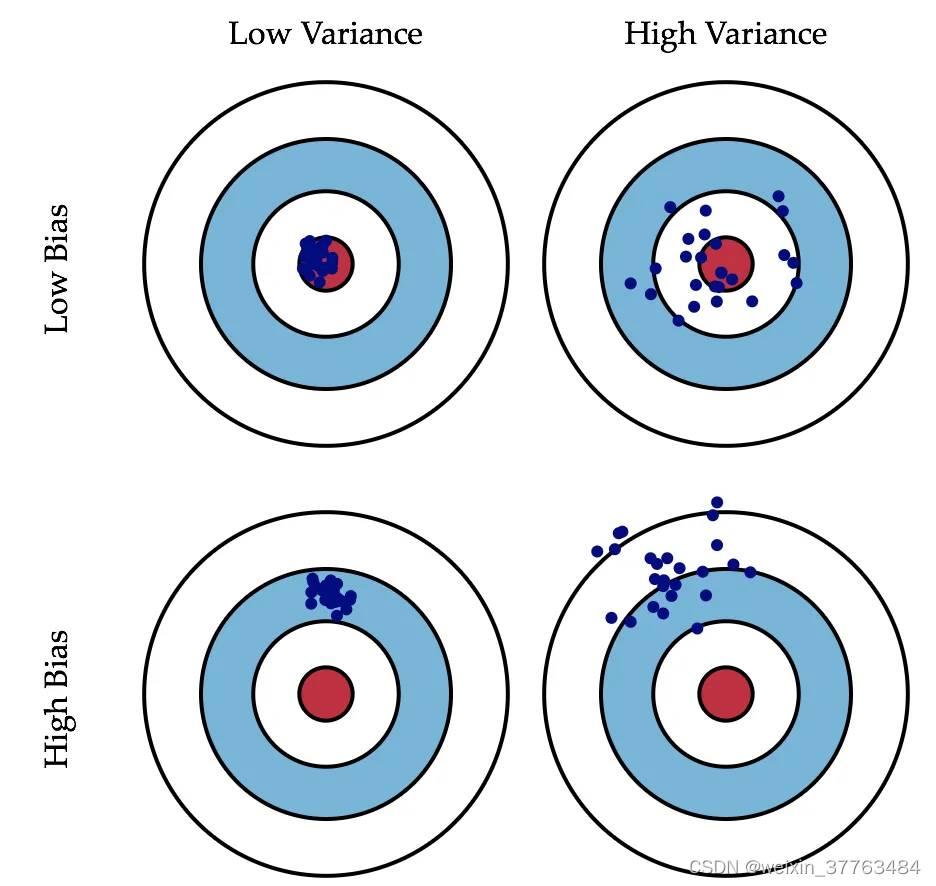
在机器学习的问题上,对于过拟合和欠拟合两种情形。我们优化的方式是不同的。
如何处理过拟合
对过拟合而言,通常以下策略对结果优化是有用的:
- 进行特征选择,挑出较好的特征的子集进行训练。
- 提供更多的数据,从而弥补原始数据的bias问题,学习到的模型也会更准确。
如何处理欠拟合
通常需要增加更多的特征,使模型变得更复杂来提高准确度。
如何判断模型状态
著名的learning curve可以帮我们判定我们的模型现在所处的状态。
我们以样本数为横坐标,训练和交叉验证集上的错误率作为纵坐标,我们也可以把错误率替换成准确率(得分),得到另一种形式的learning curve(sklearn 里面是这么做的)。
回到我们的问题,我们用scikit-learn里面的learning_curve来帮我们分辨我们模型的状态。
举个例子,这里我们一起画一下我们最先得到的baseline model的learning curve。
# import numpy as np
# import matplotlib.pyplot as plt
# from sklearn.model_selection import learning_curve
# # 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
# def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
# train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True): # train_sizes训练集占数据的比例
# """
# 画出data在某模型上的learning curve.
# 参数解释
# ----------
# estimator : 你用的分类器。
# title : 表格的标题。
# X : 输入的feature,numpy类型
# y : 输入的target vector
# ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
# cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
# n_jobs : 并行的的任务数(默认1)
# """
# train_sizes, train_scores, test_scores = learning_curve(
# estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
# train_scores_mean = np.mean(train_scores, axis=1)
# train_scores_std = np.std(train_scores, axis=1)
# test_scores_mean = np.mean(test_scores, axis=1)
# test_scores_std = np.std(test_scores, axis=1)
# if plot:
# plt.figure()
# plt.title(title)
# if ylim is not None:
# plt.ylim(*ylim)
# plt.xlabel(u"training_sample")
# plt.ylabel(u"cv_sample")
# plt.gca().invert_yaxis()
# plt.grid()
# plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
# alpha=0.1, color="b")
# plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
# alpha=0.1, color="r")
# plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"train_scores")
# plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"cv_scores")
# plt.legend(loc="best")
# plt.draw()
# plt.show()
# plt.gca().invert_yaxis()
# midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
# diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
# return midpoint, diff
# plot_learning_curve(clf, u"learning curve", X, y)
在实际数据上看,我们得到的learning curve没有理论推导的那么光滑哈,但是可以大致看出来,训练集和交叉验证集上的得分曲线走势还是符合预期的。
目前的曲线看来,我们的model并不处于overfitting的状态(overfitting的表现一般是训练集上得分高,而交叉验证集上要低很多,中间的gap比较大)。因此我们可以再做些feature engineering的工作,添加一些新产出的特征或者组合特征到模型中。
模型融合
什么是模型融合
模型融合是机器学习/数据挖掘中经常使用到的一个利器,它通常可以在各种不同的机器学习任务中使结果获得提升。顾名思义,模型融合就是综合考虑不同模型的情况,并将它们的结果融合到一起。
举个例子来说,你和你班某数学大神关系好,每次作业都『模仿』他的,于是绝大多数情况下,他做对了,你也对了。突然某一天大神脑子犯糊涂,手一抖,写错了一个数,于是…恩,你也只能跟着错了。
我们再来看看另外一个场景,你和你班5个数学大神关系都很好,每次都把他们作业拿过来,对比一下,再『自己做』,那你想想,如果哪天某大神犯糊涂了,写错了,but另外四个写对了啊,那你肯定相信另外4人的是正确答案吧?
最简单的模型融合大概就是这么个意思,比如分类问题,当我们手头上有一堆在同一份数据集上训练得到的分类器(比如logistic regression,SVM,KNN,random forest,神经网络),那我们让他们都分别去做判定,然后对结果做投票统计,取票数最多的结果为最后结果。
模型融合的作用
模型融合可以比较好地缓解,训练过程中产生的过拟合问题,从而对于结果的准确度提升有一定的帮助。
问题15:模型融合实现:将逻辑回归和随机森林进行模型融合
思考题:
到目前为止,我们只实现了逻辑回归一个模型,这是时候如果我们想利用模型融合的思路提高模型的预测准确率,我们应该怎么做呢?
思路:
如果模型出现过拟合,一定是在我们的训练上出现拟合过度造成的对吧。
那我们干脆就不要用全部的训练集,每次取训练集的一个subset,做训练,这样,我们虽然用的是同一个机器学习算法,但是得到的模型却是不一样的;同时,因为我们没有任何一份子数据集是全的,因此即使出现过拟合,也是在子训练集上出现过拟合,而不是全体数据上,这样做一个融合,可能对最后的结果有一定的帮助。这就是常用的方法之一Bagging。
Bagging:
Bagging的特点在于随机采样,随机采样(bootsrap)就是从我们的训练集里面采集固定个数的样本,每采集一个样本后,都将样本放回,是有放回的随机抽样。
sklearn.ensemble.BaggingRegressor官方文档说明 回归器组合
sklearn.ensemble.BaggingClassifier官方文档说明 用于分类器组合
两个结果预测准确性效果差别很大,BaggingClassifier的结果更好一些,比最初的81.71提高了0.33.
代码参考如下:
from sklearn.ensemble import BaggingRegressor
# fit到BaggingRegressor之中
logreg = LogisticRegression() # 基于baseline逻辑回归的结果
bagging_clf = BaggingRegressor(logreg, n_estimators=25, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
ensemble = bagging_clf.fit(X_train, Y_train)
predictions = bagging_clf.predict(X_test)
acc_BaggingRegressor = round(ensemble.score(X_train, Y_train) * 100, 2)
acc_BaggingRegressor
35.25
from sklearn.ensemble import BaggingClassifier
# fit到BaggingClassifier之中
logreg = LogisticRegression() # 基于baseline逻辑回归的结果
bagging_clf = BaggingClassifier(logreg, n_estimators=25, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
ensemble = bagging_clf.fit(X_train, Y_train)
predictions = bagging_clf.predict(X_test)
acc_BaggingClassifier = round(ensemble.score(X_train, Y_train) * 100, 2)
acc_BaggingClassifier
81.03
# 保存预测结果
bagging_result = pd.DataFrame({"PassengerId": test_df["PassengerId"],"Survived": predictions})
bagging_result.to_csv('../input/logistic_regression_baggingRegressor_predictions.csv', index=False)
bagging_result.to_csv('../input/logistic_regression_baggingClassifier_predictions.csv', index=False)
其他算法实现
实际上,除逻辑回归算法外,我们有60多个算法供我们选择。然而我们应该如何思考,今儿选择合适的算法进行尝试呢?
我们还可以使用mlxtend中的其他工具进行模型融合。
可以解决问题的算法
需要理解清楚我们正在解决的问题和所需给出的答案要求的类型,然后进一步缩小范围,最终去选择一些算法用于解决问题,并进一步来评估算法的预测结果。
问题界定:
- 分类和回归问题。
我们需要解决的是输入的特征和是否获救这个输出结果之间的关系。 - 监督学习问题。
我们使用一个已经给出是否获救分类结果的数据集来训练模型。
通过以上两点,我们可以确定缩小范围,选择以下算法来预测结果:
- Logistic Regression
- KNN/k-Nearest Neighbors
- Support Vector Machines
- Naive Bayes classifier
- Decision Tree
- Random Forrest
- Perceptron
- RVM or Relevance Vector Machine
- Artificial neural network
根据大家已经学过的知识,不同的模型对放入模型中的特征值要求不同,处理方法不同。那么大家能不能基于上面我们已经完成的特征工程部分的思路,对数据进行相应的处理以适应不同算法,获得以上其他算法的预测结果,并验证是否过拟合进行相应的处理。
随机森林算法的特征工程
实际上,放入随机森林中的特征,只要根据上面特征工程部分进行相同的处理,最后一步不进行one-hot编码即可。在这里我们就不再给出具体代码了。
模型部分的代码实现参考
不同的模型对于放入模型中的特征有不同的要求,我们暂时先不管那么多,先暴力实现其他算法,开心开心。
说明:所得结果,均使用最终放入随机森林算法中的特征处理结果带入,仅供参考。
import sklearn.metrics as sm
# Support Vector Machines
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_train)
# acc_svc = round(svc.score(Y_pred, Y_train) * 100, 2)
# acc_svc
print(sm.classification_report(Y_pred, Y_train))
precision recall f1-score support
0 0.92 0.83 0.87 606
1 0.70 0.84 0.76 285
accuracy 0.83 891
macro avg 0.81 0.83 0.82 891
weighted avg 0.85 0.83 0.84 891
# KNN
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_train)
# acc_knn = round(knn.score(X_train, Y_train) * 100, 2)
# acc_knn
print(sm.classification_report(Y_pred, Y_train))
precision recall f1-score support
0 0.92 0.84 0.88 600
1 0.72 0.85 0.78 291
accuracy 0.84 891
macro avg 0.82 0.85 0.83 891
weighted avg 0.86 0.84 0.85 891
# Gaussian Naive Bayes
gaussian = GaussianNB()
gaussian.fit(X_train, Y_train)
Y_pred = gaussian.predict(X_train)
# acc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)
# acc_gaussian
print(sm.classification_report(Y_pred, Y_train))
precision recall f1-score support
0 0.78 0.85 0.81 504
1 0.78 0.69 0.73 387
accuracy 0.78 891
macro avg 0.78 0.77 0.77 891
weighted avg 0.78 0.78 0.78 891
# Perceptron
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_train)
# acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)
# acc_perceptron
print(sm.classification_report(Y_pred, Y_train,digits=4))
precision recall f1-score support
0 0.8725 0.7983 0.8338 600
1 0.6462 0.7595 0.6983 291
accuracy 0.7856 891
macro avg 0.7593 0.7789 0.7660 891
weighted avg 0.7986 0.7856 0.7895 891
# Linear SVC
linear_svc = LinearSVC()
linear_svc.fit(X_train, Y_train)
Y_pred = linear_svc.predict(X_train)
# acc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)
# acc_linear_svc
print(sm.classification_report(Y_pred, Y_train,digits=4))
precision recall f1-score support
0 0.8743 0.8421 0.8579 570
1 0.7368 0.7850 0.7602 321
accuracy 0.8215 891
macro avg 0.8056 0.8136 0.8090 891
weighted avg 0.8248 0.8215 0.8227 891
D:\Anaconda3\lib\site-packages\sklearn\svm\_base.py:1206: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.
warnings.warn(
# Stochastic Gradient Descent
sgd = SGDClassifier(max_iter=5000)
sgd.fit(X_train, Y_train)
Y_pred = sgd.predict(X_train)
# acc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)
# acc_sgd
print(sm.classification_report(Y_pred, Y_train,digits=4))
precision recall f1-score support
0 0.8871 0.8144 0.8492 598
1 0.6754 0.7884 0.7276 293
accuracy 0.8058 891
macro avg 0.7813 0.8014 0.7884 891
weighted avg 0.8175 0.8058 0.8092 891
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipe_sgd = Pipeline([ ("scaler",StandardScaler() ),('sgd', SGDClassifier(loss="modified_huber",penalty="l1", max_iter=1000))])
pipe_sgd.fit(X_train,Y_train)
y_pre=pipe_sgd.predict(X_train)
y_pre_prob_=pipe_sgd.predict_proba(X_train)
y_pre_prob=[]
for i in range(len(y_pre)):
if y_pre[i]==1:
y_pre_prob.append(y_pre_prob_[i][1])
else:
y_pre_prob.append(1-y_pre_prob_[i][0])
print(sm.classification_report(Y_pred, Y_train,digits=4))
print(sm.mean_absolute_error(Y_pred_prob,Y_train))
precision recall f1-score support
0 0.9290 0.8644 0.8955 590
1 0.7661 0.8704 0.8149 301
accuracy 0.8664 891
macro avg 0.8475 0.8674 0.8552 891
weighted avg 0.8739 0.8664 0.8683 891
0.22110828951156772
# xgb
from xgboost.sklearn import XGBClassifier
from sklearn.model_selection import RandomizedSearchCV
sample_weight=[]
for i in range(len(Y_train)):
if Y_train[i]==0:
sample_weight.append(1)
else:
sample_weight.append(2)
xgb= XGBClassifier(n_estimators=5000,max_depth=10,scale_pos_weight =0.3,learning_rate =0.01,gamma =0.05,subsample=0.7,colsample_bytree=0.4,min_child_weight=0.2)
xgb.fit(X_train,Y_train)
Y_pred=xgb.predict(X_train)
Y_pred_prob_=xgb.predict_proba(X_train)
Y_pred_prob=[]
for i in range(len(Y_pred)):
if Y_pred[i]==1:
Y_pred_prob.append(Y_pred_prob_[i][1])
else:
Y_pred_prob.append(1-Y_pred_prob_[i][0])
print(sm.classification_report(Y_pred, Y_train,digits=4))
print(sm.mean_absolute_error(Y_pred_prob,Y_train))
precision recall f1-score support
0 0.9891 0.7915 0.8794 686
1 0.5819 0.9707 0.7276 205
accuracy 0.8328 891
macro avg 0.7855 0.8811 0.8035 891
weighted avg 0.8954 0.8328 0.8444 891
0.19012825731208963
# Decision Tree
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_train)
Y_pred_prob_=decision_tree.predict_proba(X_train)
Y_pred_prob=[]
for i in range(len(Y_pred)):
if Y_pred[i]==1:
Y_pred_prob.append(Y_pred_prob_[i][1])
else:
Y_pred_prob.append(1-Y_pred_prob_[i][0])
print(sm.classification_report(Y_pred, Y_train,digits=4))
print(sm.mean_absolute_error(Y_pred_prob,Y_train))
precision recall f1-score support
0 0.9344 0.8607 0.8961 596
1 0.7573 0.8780 0.8132 295
accuracy 0.8664 891
macro avg 0.8459 0.8694 0.8546 891
weighted avg 0.8758 0.8664 0.8686 891
0.1870742685334913
# Random Forest
random_forest = RandomForestClassifier(n_estimators=1000) # 定义决策树的个数为100
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_train)
Y_pred_prob_=random_forest.predict_proba(X_train)
Y_pred_prob=[]
for i in range(len(Y_pred)):
if Y_pred[i]==1:
Y_pred_prob.append(Y_pred_prob_[i][1])
else:
Y_pred_prob.append(1-Y_pred_prob_[i][0])
print(sm.classification_report(Y_pred, Y_train,digits=4))
print(sm.mean_absolute_error(Y_pred_prob,Y_train))
precision recall f1-score support
0 0.9253 0.8669 0.8952 586
1 0.7719 0.8656 0.8161 305
accuracy 0.8664 891
macro avg 0.8486 0.8662 0.8556 891
weighted avg 0.8728 0.8664 0.8681 891
0.19873776366870244
from sklearn.ensemble import AdaBoostClassifier,HistGradientBoostingRegressor,GradientBoostingClassifier
# gbdt
gbdt = GradientBoostingClassifier(criterion="friedman_mse",n_estimators=1000,learning_rate=0.05)
gbdt.fit(X_train,Y_train)
Y_pred=gbdt.predict(X_train)
Y_pred_prob_=gbdt.predict_proba(X_train)
Y_pred_prob=[]
for i in range(len(Y_pred)):
if Y_pred[i]==1:
Y_pred_prob.append(Y_pred_prob_[i][1])
else:
Y_pred_prob.append(1-Y_pred_prob_[i][0])
print(sm.classification_report(Y_pred, Y_train,digits=4))
print(sm.mean_absolute_error(Y_pred_prob,Y_train))
precision recall f1-score support
0 0.9199 0.8707 0.8946 580
1 0.7807 0.8585 0.8178 311
accuracy 0.8664 891
macro avg 0.8503 0.8646 0.8562 891
weighted avg 0.8713 0.8664 0.8678 891
0.19961541192640012
#mlp
from sklearn.ensemble import AdaBoostClassifier,HistGradientBoostingRegressor,GradientBoostingClassifier
# mlp
gbdt = MLPClassifier(solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=(32,16,4),learning_rate="invscaling",random_state=1)
gbdt.fit(X_train,Y_train)
Y_pred=gbdt.predict(X_train)
Y_pred_prob_=gbdt.predict_proba(X_train)
Y_pred_prob=[]
for i in range(len(Y_pred)):
if Y_pred[i]==1:
Y_pred_prob.append(Y_pred_prob_[i][1])
else:
Y_pred_prob.append(1-Y_pred_prob_[i][0])
print(sm.classification_report(Y_pred, Y_train,digits=4))
print(sm.mean_absolute_error(Y_pred_prob,Y_train))
precision recall f1-score support
0 0.9162 0.8672 0.8911 580
1 0.7749 0.8521 0.8116 311
accuracy 0.8620 891
macro avg 0.8455 0.8597 0.8513 891
weighted avg 0.8669 0.8620 0.8633 891
0.1949298895378452
问题16:神经网络实现
我们已经尝试使用这么多的算法来尝试解决问题,现在只差一个神经网络了。是时候自己动手,实现你的第一个神经网络了!
sklearn中已经有了成熟的实现。
模型比较
我们将上面所有的模型结果进行排序,选择一个分数最高的模型作为最终预测结果。
决策树和随机森林的得分一样,我们最终选择随机森林,因为它也刚好修正了决策树对于训练集的过拟合问题。
models = pd.DataFrame({
'Model': ['Support Vector Machines', 'KNN', 'Logistic Regression',
'Random Forest', 'Naive Bayes', 'Perceptron',
'Stochastic Gradient Decent', 'Linear SVC',
'Decision Tree'],
'Score': [acc_svc, acc_knn, acc_log,
acc_random_forest, acc_gaussian, acc_perceptron,
acc_sgd, acc_linear_svc, acc_decision_tree]})
models.sort_values(by='Score', ascending=False)
| Model | Score | |
|---|---|---|
| 3 | Random Forest | 86.64 |
| 8 | Decision Tree | 86.64 |
| 1 | KNN | 84.40 |
| 0 | Support Vector Machines | 83.28 |
| 7 | Linear SVC | 82.15 |
| 2 | Logistic Regression | 81.71 |
| 5 | Perceptron | 78.56 |
| 4 | Naive Bayes | 78.11 |
| 6 | Stochastic Gradient Decent | 76.88 |
问题17:实现逻辑回归以外的其他算法
到这里,我们把解决Titanic数据集问题的思路,全部带领同学们过了一遍。希望大家可以把除了逻辑回归以外的其他模型,都认真地自己动手实现一遍,以更好的理解每一个算法和使用机器学习解决问题中需要应对的问题和处理的方法。
集成学习
sgd作为基学习器
from mlxtend.classifier import StackingClassifier
from sklearn.linear_model import SGDClassifier
sreg = StackingClassifier(verbose=2,classifiers=[xgb,decision_tree,gbdt,random_forest,pipe_sgd],
meta_classifier=SGDClassifier( loss="log",penalty="l1", max_iter=5000)
)
sreg.fit(X_train, Y_train)
Y_pred = sreg.predict(X_train)
Y_pred_prob_= sreg.predict_proba(X_train)
Y_pred_prob=[]
for i in range(len(Y_pred)):
if Y_pred[i]==1:
Y_pred_prob.append(Y_pred_prob_[i][1])
else:
Y_pred_prob.append(1-Y_pred_prob_[i][0])
print(sm.classification_report(Y_pred, Y_train,digits=4))
print(sm.mean_absolute_error(Y_pred_prob,Y_train))
Fitting 5 classifiers...
Fitting classifier1: xgbclassifier (1/5)
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, feature_types=None, gamma=0, gpu_id=-1,
grow_policy='depthwise', importance_type=None,
interaction_constraints='', learning_rate=0.300000012,
max_bin=256, max_cat_threshold=64, max_cat_to_onehot=4,
max_delta_step=0, max_depth=10, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=3000,
n_jobs=0, num_parallel_tree=1, predictor='auto', random_state=0, ...)
Fitting classifier2: decisiontreeclassifier (2/5)
DecisionTreeClassifier()
Fitting classifier3: mlpclassifier (3/5)
MLPClassifier(alpha=1e-05, hidden_layer_sizes=(32, 16, 4),
learning_rate='invscaling', random_state=1, solver='lbfgs')
Fitting classifier4: randomforestclassifier (4/5)
RandomForestClassifier(n_estimators=1000)
Fitting classifier5: pipeline (5/5)
Pipeline(steps=[('scaler', StandardScaler()),
('sgd', SGDClassifier(loss='modified_huber', penalty='l1'))])
precision recall f1-score support
0 0.9217 0.8694 0.8948 582
1 0.7778 0.8608 0.8172 309
accuracy 0.8664 891
macro avg 0.8497 0.8651 0.8560 891
weighted avg 0.8718 0.8664 0.8679 891
0.24045011034849822
神经网络作为基学习器
from sklearn.neural_network import MLPClassifier
sreg = StackingClassifier(verbose=2,classifiers=[xgb,decision_tree,gbdt,random_forest,pipe_sgd],
meta_classifier=MLPClassifier(solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=(8,4,4),learning_rate="invscaling",random_state=1))
sreg.fit(X_train, Y_train)
Y_pred = sreg.predict(X_train)
Y_pred_prob_= sreg.predict_proba(X_train)
Y_pred_prob=[]
for i in range(len(Y_pred)):
if Y_pred[i]==1:
Y_pred_prob.append(Y_pred_prob_[i][1])
else:
Y_pred_prob.append(1-Y_pred_prob_[i][0])
print(sm.classification_report(Y_pred, Y_train,digits=4))
print(sm.mean_absolute_error(Y_pred_prob,Y_train))
Fitting 5 classifiers...
Fitting classifier1: xgbclassifier (1/5)
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, feature_types=None, gamma=0, gpu_id=-1,
grow_policy='depthwise', importance_type=None,
interaction_constraints='', learning_rate=0.300000012,
max_bin=256, max_cat_threshold=64, max_cat_to_onehot=4,
max_delta_step=0, max_depth=5, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=3000,
n_jobs=0, num_parallel_tree=1, predictor='auto', random_state=0, ...)
Fitting classifier2: decisiontreeclassifier (2/5)
DecisionTreeClassifier()
Fitting classifier3: mlpclassifier (3/5)
MLPClassifier(alpha=1e-05, hidden_layer_sizes=(32, 16, 4),
learning_rate='invscaling', random_state=1, solver='lbfgs')
Fitting classifier4: randomforestclassifier (4/5)
RandomForestClassifier(n_estimators=1000)
Fitting classifier5: pipeline (5/5)
Pipeline(steps=[('scaler', StandardScaler()),
('sgd', SGDClassifier(loss='modified_huber', penalty='l1'))])
precision recall f1-score support
0 0.9162 0.8733 0.8942 576
1 0.7865 0.8540 0.8189 315
accuracy 0.8664 891
macro avg 0.8514 0.8636 0.8565 891
weighted avg 0.8704 0.8664 0.8676 891
0.22000066108562064
输出预测结果
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred
})
submission.to_csv('../input/submission.csv', index=False)
总结
在后面的项目作业中,希望大家可以按照这个步骤去处理和分析数据。当然,这个项目不能可能学习所有处理各类问题的技巧和方法,但是最基础最主要的内容都已经通过结构化和流程化的方式放在这里了,希望未来遇到自己无法处理的问题,能够合理使用搜索工具,找到解决方案。当然,在Titanic比赛的Kaggle主页,还介绍了一些其他的更高级的方法。感兴趣的同学可以进一步自行阅读和实践。有一些内容我们没有讲到,或者没有系统的讲完整的(如下),希望大家能够在实践中不断学习,并完善自己的知识体系。
1. 变量选择
2. 模型评估
3. 模型选择
3. 模型选择
通过这个项目,你觉得哪些工作对模型预测准确度的提升有较大影响?
- 对数据的认识很重要
- 数据中的特殊点/离群点的分析和处理很重要
- 特征工程很重要
- 模型融合很重要
参考资料
- A journey through Titanic
- Getting Started with Pandas: Kaggle’s Titanic Competition
- Titanic Best Working Classifier
- Titanic Data Science Solutions
- An Interactive Data Science Tutorial
- 机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾
- 七种常用特征工程
- 知乎-特征工程到底是什么?
- 点击率预测综述(上篇)
- 用简单易懂的语言描述「过拟合 overfitting」?
- Seaborn示例
- 交叉验证(Cross-validation)
- 交叉验证在sklearn中的实现
- 交叉验证和bias-tradeoff的权衡
- Kaggle机器学习之模型融合(stacking)心得
- 逻辑回归(Logistic Regression)
- sklearn官方文档
- 如何在 Kaggle 首战中进入前 10%
- Kaggle Ensembling Guide
- 【机器学习】模型融合方法概述
- 机器学习:聊聊机器学习模型集成学习算法——Bagging
- 机器学习(二) 如何做到Kaggle排名前2%
- Scikit-learn使用总结





![[附源码]计算机毕业设计课程在线测评系统Springboot程序](https://img-blog.csdnimg.cn/3496a2b68220498db23c5ad1e1e64cfb.png)



![[附源码]计算机毕业设计楼盘销售管理系统Springboot程序](https://img-blog.csdnimg.cn/d720357cad964dc5b1165e6fdcf9668c.png)