原子指令
RV32A 是 RISCV 支持原子操作的扩展。主要有两种实现方式:内存原子操作(AMO),加载保留/条件存储(load reserved / store conditional)
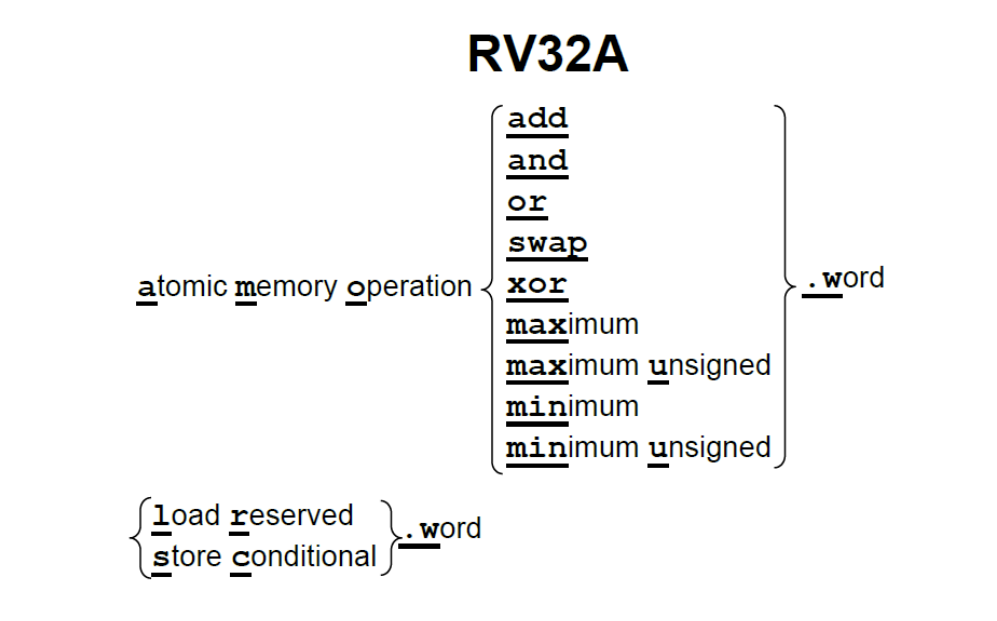
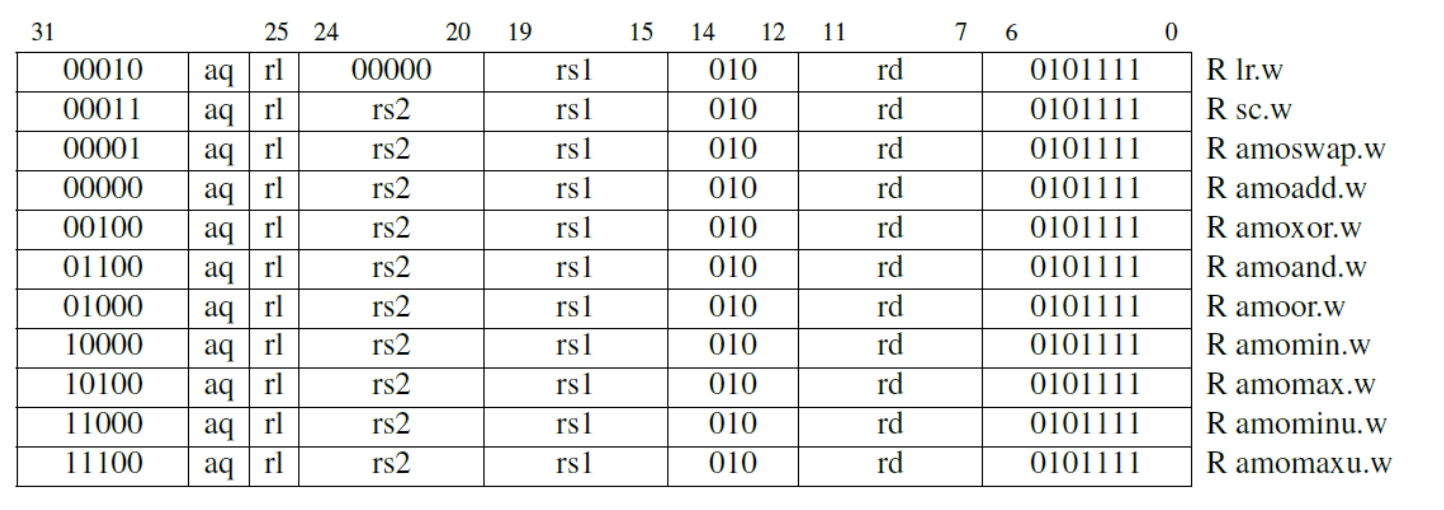
AMO:一个处理器对内存的操作不会被打断,其值也不会被其他处理器修改。
load reserved / store conditional:保证了这两条指令的原子性,一个是读取一个值存入目标寄存器,并保存这一记录;一个是如果目标地址存在保留记录,则写入值,并向目标寄存器中写入0的flag,否则保存失败写非0.
lr sc 的应用场景:体系结构常有一个(compare-and-swap)原子比较交换操作。比较寄存器1 2的值,如果相等则把内存中的值写入寄存器3,否则不写入。
这个操作我们需要3个源寄存器,1个目标寄存器。而 lr sc 可以把其拆成两部分。

上例:a0 加载到 a3 里,如果 a1 a3 相等且 a0 有保存记录,把 a2 值存入 a0,且设置 a3=0 标志成功写入。否则循环执行。
也就是说只有 a0 被拿出来过,有保存标志的时候才允许写入。否则存入失败。

a0 地址处的值取出来给 t1,t0 处的值给 a0 的地址里临时存储以前的锁状态。
锁 t0 一开始是1未锁定。然后要锁定的时候,把 t0 赋给 a0 (1),并且把之前 a0 的值取出来给 t1 看是不是1.
是1,说明有其他程序把 t0 也就是1赋值给 a0 里了,说明有人在占用。则等待,不断循环这个过程。
是0,说明还没人在用,可以开始临界区代码。
结束的时候把0寄存器 x0 的值赋值给 a0 表示不再访问临界区资源。
AMO 相比比较交换,在多处理器系统中性能更好,也能提供互斥访问 IO 资源的方法。两种方法各有其亮点。
压缩指令
指令集为了压缩,大多会缩减操作数至两个,缩减立即数域等。以往的 arm thumb2 和 microMIPS 等就是一些对原指令集的优化,但是加重了处理器的负担和程序员的理解难度。
为了减轻负担,RV32C 压缩指令要求:压缩的前提下,压缩的每一条16位指令都要和原指令对标。因此架构师们挑选了以下指令:
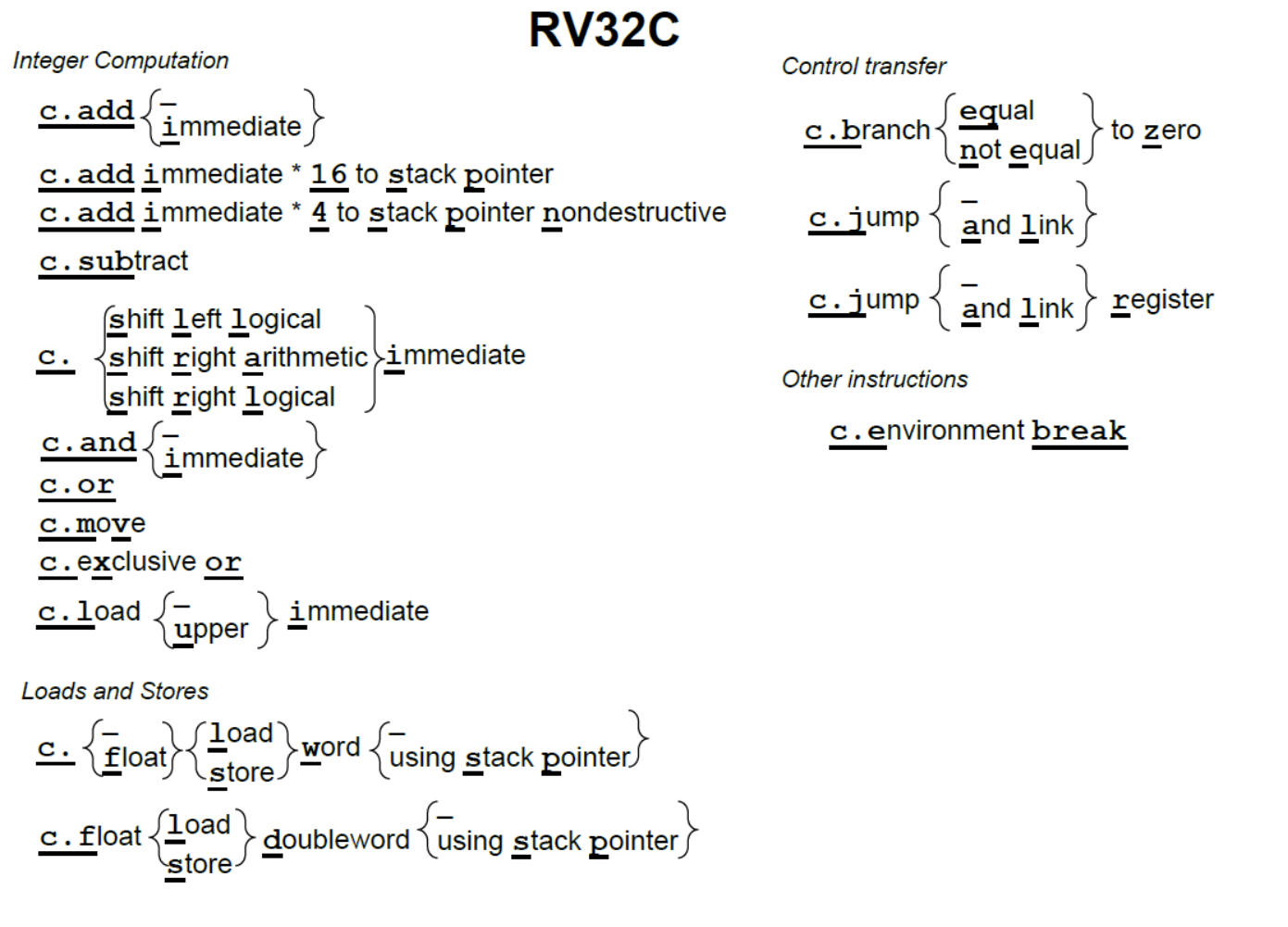
- 常用寄存器不多(a0-a5,s0-s1,sp 以及 ra),因此也不需要太多位存储 rs rt rd 指代哪一个寄存器。
- 立即数往往很小,因此可以缩减立即数位数。
- 很多指令的 rd 是源操作数之一,比如
add r0, r0, r1,可以缩减。 - load store 只采用整数倍操作数长度(word)。
- 用解码器把16位指令全部转化为32位。解码器的电路只占整体的5%,相比起来挺合适的了Thumb2 和 Arm32 这种算两套 ISA,要用两套解码器。
因为要对标原指令,所以有一些指令没有,比如 load and store multiple 这种,因此长度上可能不如 thumb2 等。
不过有些架构师不考虑 RV32C,因为对于一些取指一次能取好几条的处理器系统来说,可能译码阶段是最大的瓶颈,因此16-32转化的解码器阶段会比较大影响性能。