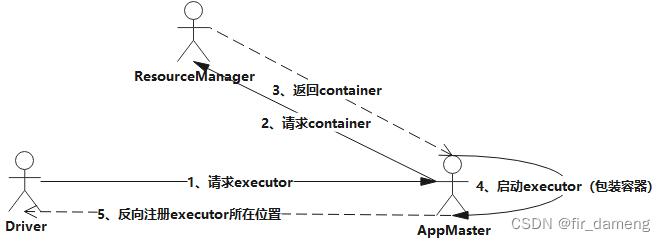
jieba库的安装见上篇:Python学习-8.库(第三方库介绍与下载安装)
jieba库概述

由于中文文本中的单词不像英文那样,并不是根据空格或者标点符号进行分割的,而是存在一个重要的分词问题。因此引入了jieba库。
- 分词原理:利用一个中文词库,将待分的内容与分词词库进行对比,通过图结构和动态规划方法找到最大概率的词组。除了分词,jieba还提供增加自定义中文单词的功能。
jieba库的使用
和标准库一样,第三方库jieba需要import使用。当在解释器中输入import 库名时,解释器会自动在该项目目录下寻找库名.py文件,若找不到,会在安装目录下指定的第三方库目录内寻找。
jieba库提供了三种分词模式
①精确模式:jieba.lcut(s),最常用的中文分词函数,可以将句子最精确地分开,即将字符串分割成等量的中文词组,返回结果是列表类型,适合文本分析。
精确模式是根据每个词组组合的概率进行返回,只返回概率最大的词组。
import jieba
print(jieba.lcut('由于中文文本中的单词不像英文那样,不是根据空格或者标点符号进行分割的'))
--输出
['由于', '中文', '文本', '中', '的', '单词', '不像', '英文', '那样', ',', '不是', '根据', '空格', '或者', '标点符号', '进行', '分割', '的']
②全模式:jieba.lcut(s,cut_all=True),与精准模式命名一样,多了一个cut_all参数。可以将句子中所有可以成词的语句都扫描出来,速度非常快,但是不能够解决歧义问题。
全模式会返回字符串的所有分词结果,返回结果是列表型,冗余最大。
import jieba
print(jieba.lcut('由于中文文本中的单词不像英文那样,不是根据空格或者标点符号进行分割的',cut_all=True))
--输出
['由于', '中文', '文文', '文本', '中', '的', '单词', '不', '像', '英文', '那样', ',', '不是', '根据', '空格', '或者', '标点', '标点符号', '符号', '进行', '分割', '的']#返回了“文文”这种词组
③搜索引擎模式:jieba.lcut_for_search(s),该模式首先执行精确模式,然后对其中长词进一步切分获得最终结果,提高召回率,适合用于搜索引擎分词。
import jieba
print(jieba.lcut_for_search('由于中文文本中的单词不像英文那样,不是根据空格或者标点符号进行分割的'))
--输出
['由于', '中文', '文本', '中', '的', '单词', '不像', '英文', '那样', ',', '不是', '根据', '空格', '或者', '标点', '符号', '标点符号', '进行', '分割', '的']#标点符号为长词,进一步拆分
jieba词库内容的自定义
使用add_word(s)函数可添加自定义内容
import jieba
print(jieba.lcut('利用厌疾医生',cut_all=True))
--输出
['利用', '厌', '疾', '医生']#“厌”“疾”为两个词
#添加词汇
import jieba
jieba.add_word('厌疾')
print(jieba.lcut('利用厌疾医生',cut_all=True))
--输出
['利用', '厌疾', '医生']#“厌疾”识别为一个词


![[附源码]计算机毕业设计酒店客房管理信息系统Springboot程序](https://img-blog.csdnimg.cn/cb452dccce504d7fa28fabb5430afc13.png)