R语言学习笔记——入门篇:第五章-高级数据管理
文章目录
R语言 一、数值与字符处理函数 1.1、数学函数 1.2、统计函数 1.3、概率函数 1.4、字符处理函数 1.5、其他实用函数 1.6、将函数应用于矩阵与数据框 二、控制流 2.1、循环(for,while)
2.2、条件执行(if-else,ifelse,switch) 2.2.1、if-else语句 2.2.2、ifelse语句 2.2.3、switch语句 三、自编函数 四、整合与重构 4.1、转置 4.2、整合数据 4.3、reshape2包
函数 功能 示例 abs(x) 绝对值 abs(-4) 返回值为4 sqrt(x) 平方根 sqrt(16) 返回值为4 ceiling(x) 向上取整 ceiling(3.456) 返回值为4 floor(x) 向下取整 floor(3.456) 返回值为3 trunc(x) 向0的方向取整 trunc(3.456) 返回值为3 round(x,digits = n) 确认小数 round(3.456,digits=2) 返回值为3.45 signif(x,digits = n) 确认有效数字 signif(3.456,digits = 2) 返回值为3.4 cos(x),sin(x),tan(x) 余弦,正弦和正切 aces(x),asin(x),atan(x) 反余弦,反正弦和反正切 cosh(x),sinh(x),tanh(x) 双曲余弦,双曲正弦和双曲正切 acosh(x),asinh(x),atanh(x) 反双曲余弦,反双曲正弦和反双曲正切 log (x,base = n) 对数函数,底数为n log(x) 自然对数 log(10) 返回值为2.3026 log10(x) 常用对数 log10(10) 返回值为1 exp(x) 指数函数,y=e^x (x∈R) exp(2.3026) 返回值为10
函数 功能 示例 mean(x) 平均数 mean(c(1,2,4,7)) 返回值为3.5 median(x) 中位数 median(c(1,2,4,7)) 返回值为3,median(c(1,2,4,7,3)) 返回值为3 sd(x) 标准差(可以直观展现数据的离散度) sd(c(1,2,3)) 返回值为1 var(x) 方差(标准差的平方) var(c(1,2,3)) 返回值为1 mad(x) 绝对中位差:原数据减去中位数后得到的新数据的绝对值的中位数,常用来估计标准差 mad(c(1,2,3)) 返回值为1.4826 quantile(x,probs) 求分位数,x为待求分位的数值型向量,probs为一个由[0,1]之间概率组成的数值向量 quantile(c(1,2,3),c(.3,.84)) 返回值为 30% 位点1.60 84% 位点2.68 range(x) 求值域,diff(range(x))为求极差 range(c(1,2,3)) 返回值为1,3 sum(x) 求和 sum(c(1,2,3)) 返回值为6 diff(x,lag = a) 滞后差分,lag用以指定滞后几项,默认为1 diff(c(2,4,6,8),lag = 2) 返回值为4,4 min(x) 求最小值 min(c(1,2,3)) 返回值为1 max(x) 求最大值 max(c(1,2,3)) 返回值为3 scale(x,center = TRUE,scale = TRUE) 为数据对象x按列进行中心化(center=TRUE,改均值)或标准化(center=TRUE,scale = TRUE,改标准差) 详见数据的标准化示例
x <- c( 1 , 10 , 6 )
x1 <- scale( c( 1 , 10 , 6 ) )
> mean( x)
[ 1 ] 5.666667
> sd( x)
[ 1 ] 4.50925
> mean( x1)
[ 1 ] - 3.237473e-17
> sd( x1)
[ 1 ] 1
> x1
[ , 1 ]
[ 1 , ] - 1.03490978
[ 2 , ] 0.96098765
[ 3 , ] 0.07392213
attr( , "scaled:center" )
[ 1 ] 5.666667
attr( , "scaled:scale" )
[ 1 ] 4.50925
x2 <- scale( x) * SD+ M
x3 <- transform( mydata, myvar = scale( myvar) * SD+ M)
概率函数也属于统计函数一类,由于其特殊性,这边单独开一节来记录 R中概率函数形如 :[dpqr]distribution_abbreviation()
d = 密度函数(density) p = 分布函数(distribution function) q = 分位数函数(quantile function) r = 生成随机数(随机偏差) distribution_abbreviation(),常见的概率函数 函数 功能 beta Beta分布 binom 二项分布 cauchy 柯西分布 chisq (非中心)卡方分布 exp 指数分布 f F分布 gamma Gamma分布 geom 几何分布 hyper 超几何分布 lnorm 对数正态分布 logis Logistic分布 multinom 多项分布 nbinom 负二项分布 norm 正态分布 pois 泊松分布 signrank Wilcoxon符号秩分布 t t分布 unif 均匀分布 weibull Weibull分布 wilcox Wilcoxon秩和分布
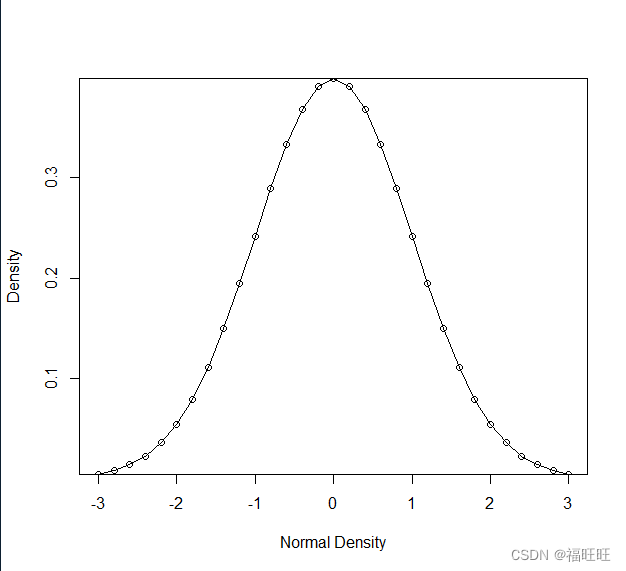
x <- pretty( c( - 3 , 3 ) , 30 )
y <- dnorm( x)
plot( x, y, type= "o" , xlab = "Normal Density" , ylab = "Density" , yaxs= "i" )
pnorm( 3 )
[ 1 ] 0.9986501
qnorm( .8 , mean = 10 , sd = 50 )
[ 1 ] 52.08106
rnorm( 50 , mean = 10 , sd = 50 )
[ 1 ] 28.981974 - 15.116173 - 6.660369 - 40.928769 - 43.589561 25.176432 32.410489
[ 8 ] 12.650211 56.113373 112.504234 - 14.551558 - 105.458444 60.286926 - 25.460038
[ 15 ] - 24.400431 61.278568 - 4.238650 - 51.035886 19.065174 3.055432 10.288209
[ 22 ] 29.264020 - 8.533002 42.218827 - 1.024328 26.589098 64.841951 31.759075
[ 29 ] - 6.296579 67.440381 59.675193 37.419848 21.936587 - 21.395304 78.032622
[ 36 ] - 20.012979 119.366650 86.630531 - 1.785018 - 41.321045 - 25.520328 22.844185
[ 43 ] - 2.334594 - 7.377130 - 37.580928 7.748614 - 29.245223 - 73.397097 - 9.011326
[ 50 ] 55.949830
在R中存在着生成伪随机数的函数 ,例如:
runif(n) 函数:生成n个0到1区间上服从均匀分布(unif)的伪随机数MASS包中的 mvrnorm(n,mean,signma) 函数生成n个,均值为mean,方差-协方差矩阵为signma的多元正态分布的数据 重现伪随机数 :每次调用上述函数生成的数据都不同,通过设定随机数种子 ,可以重现伪随机数。
> runif( 3 )
[ 1 ] 0.2825283 0.9611048 0.7283944
> set.seed( 1 )
> runif( 3 )
[ 1 ] 0.2655087 0.3721239 0.5728534
> set.seed( 1 )
> runif( 3 )
[ 1 ] 0.2655087 0.3721239 0.5728534
前面介绍的函数都是对数值型变量进行操作的,下面介绍字符处理函数。
函数 功能 示例 nchar(x) 计算x中的字符数 x <- c(“a”,“bc”,“defgh”) length(x)返回值为3 nchar(x[3])返回值为5 substr(x,start,stop) 提取或替换一个字符向量中的子串 x <- “abcdef” substr(x,2,4) 返回值为"bcd" substr(x,2,4) <- “11111"返回值为"a111ef” grep(pattern,x,ignore.case = F,fixed = F) 在x中搜索pattern。若fixed=F则pattern为正则表达式,若fixed=T则pattern为文本字符串。 grep(“a”,x <- c(“a”,“bab”,“b”),fixed = T)返回值为1,2 sub(pattern,replacement,x,ignore.case = F,fixed = F) 在x中搜索pattern,以replacement替换。若fixed=F则pattern为正则表达式,若fixed=T则pattern为文本字符串。 sub(“\s” ,“-”,“Hello World”)返回值为Hello-World .其中\s是查找空白的正则表达式,\是R中的转义字符,为了区分写作\s strsplit(x,split,fixed = F) 在split处分割字符向量x中的元素。若fixed=F则pattern为正则表达式,若fixed=T则pattern为文本字符串。 strsplit(“abc”,“”)返回值为 “a” “b” “c"strsplit(“a,bc”,”,")返回值为 “a” “bc” paste(… ,sep = “”) 连接字符串,以sep为连接符 paste(“x”,1:3,sep = “”)返回值为"x1" “x2” “x3” toupper(x) 大写转换 toupper(“abc”)返回值为"ABC" tolower(x) 小写转换 tolower(“ABC”)返回值为"abc"
正则表达式 :针对函数grep(),sub(),strsplit()可以搜索正则表达式,其为文本模式的匹配提供了一套匹配的语法
^ [ hc] ?at
在多数实际应用中正则表达式,文本字符串的差异性不大。 函数 功能 示例 length(x) 求x的长度 length(c(“a”,“bc”,“defgh”))返回值为3 seq(from,to,by) 生成一个序列,从from至to,间隔by seq(1,10,2)返回值为1 3 5 7 9 rep(x,n) 将x重复n次 rep(1:2,2)返回值为1 2 1 2 cut(x,n) 将连续型变量x切割为有着n个水平的因子 pretty(x,n) 创建美观分割点。通过选取n+1个等间距的取整值,将一个连续型变量x分为n个区间。绘图中常用。 x <- pretty(c(-3,3),30) y <- dnorm(x) plot(x,y,type=“o”,xlab = “Normal Density”,ylab = “Density”,yaxs=“i”)在区间[-3,3]上绘制标准正态曲线 cat(…,file = “myfile”,append = F) 连接…中的对象,将其输出到屏幕或file中 cat(“Hello”,“World”,“\b.”,“I”,“am”,“fine”,“\b.”)返回值为Hello World.I am fine.
转义字符 :
\n表示换行,\t表示制表符,\b表示退格,'表示单引号 ?Quotes以了解更多 cat()函数的示例解释 :由于cat输出连接对象时,会以空格作为连接符,为了让两个对象中间没有连接符,所以使用了退格转义字符\b函数 :apply() 功能 :将任意函数应用到矩阵,数组,数据框 的任何维度上语法 :apply( x, MARGIN, FUN, ... )
apply( leadership, 2 , max)
函数 :sapply() 功能 :将任意函数应用到列表 的任何维度上语法 :lapply( X, FUN, ... )
Student <- c( "A a" , "B b" , "C c" , "D d" )
name <- strsplit( Student, " " )
Lastname <- sapply( name, "[" , 2 )
Firstname <- sapply( name, "[" , 1 )
> Lastname
[ 1 ] "a" "b" "c" "d"
> Firstname
[ 1 ] "A" "B" "C" "D"
for ( var in seq) statement
i <- 1
for ( i in 1 : 10 )
{ i <- i + 1 ;
print( i) }
[ 1 ] 2
[ 1 ] 3
[ 1 ] 4
[ 1 ] 5
[ 1 ] 6
[ 1 ] 7
[ 1 ] 8
[ 1 ] 9
[ 1 ] 10
[ 1 ] 11
while ( cond) statement
i <- 1
while ( i <= 10 )
{
i <- i+ 1 ;
print( i)
}
[ 1 ] 2
[ 1 ] 3
[ 1 ] 4
[ 1 ] 5
[ 1 ] 6
[ 1 ] 7
[ 1 ] 8
[ 1 ] 9
[ 1 ] 10
[ 1 ] 11
if ( cond) statement
if ( cond) statement1 else statement2
for ( i in 1 : 10 )
{
if ( i > 5 ) print( i) else print( NA )
}
[ 1 ] NA
[ 1 ] NA
[ 1 ] NA
[ 1 ] NA
[ 1 ] NA
[ 1 ] 6
[ 1 ] 7
[ 1 ] 8
[ 1 ] 9
[ 1 ] 10
if-else的简化版本,只能执行二元行为(两个选项) 语法 :ifelse( cond, statement1, statement2)
for ( i in 1 : 10 )
{
ifelse( i > 5 , print( i) , print( NA ) )
}
类似于其他语言中的case函数,遍历所有条件,直至匹配上后返回该条件下操作的运行结果 语法 :switch( expr, ... )
require( stats)
centre <- function ( x, type) {
switch( type,
mean = mean( x) ,
median = median( x) ,
trimmed = mean( x, trim = .1 ) )
}
x <- rcauchy( 10 )
centre( x, "mean" )
centre( x, "median" )
centre( x, "trimmed" )
ccc <- c( "b" , "QQ" , "a" , "A" , "bb" )
for ( ch in ccc)
cat( ch, ":" , switch( EXPR = ch, a = 1 , A = 1 , b = 2 : 3 , "Otherwise: last" ) , "\n" )
b : 2 3
QQ : Otherwise: last
a : 1
A : 1
bb : Otherwise: last
当现有R包无法满足你的需求时,R语言支持自己编写函数。 形如 :myfunction <- function ( arg1, arg2, ... )
{
statements
return( object)
}
编写好的函数,可以通过将其配置入环境变量中,使R在启动时自动读取该函数。 函数 :t() 功能 :对矩阵,数据框 进行转置,对后者行名将变为变量(列)名
t( x)
定义 :将多组观测替换为根据这些观测计算的描述性统计量(改数据值)函数 :aggregate() 功能 :使用一个或多个by变量和预先定义好的函数来折叠数据语法 :aggregate( x, by, FUN)
by1 <- c( "red" , "blue" , 1 , 2 , NA , "big" , 1 , 2 , "red" , 1 , NA , 12 )
by2 <- c( "wet" , "dry" , 99 , 95 , NA , "damp" , 95 , 99 , "red" , 99 , NA , NA )
testDF <- data.frame( by1, by2, v1 = c( 1 , 3 , 5 , 7 , 8 , 3 , 5 , NA , 4 , 5 , 7 , 9 ) ,
v2 = c( 11 , 33 , 55 , 77 , 88 , 33 , 55 , NA , 44 , 55 , 77 , 99 ) )
aggregate( x = testDF, by = list( Group.by1= by1, Group.by2= by2) , FUN = "mean" , na.rm = F)
by1 by2 v1 v2
1 red wet 1 11
2 blue dry 3 33
3 1 99 5 55
4 2 95 7 77
5 < NA > < NA > 8 88
6 big damp 3 33
7 1 95 5 55
8 2 99 NA NA
9 red red 4 44
10 1 99 5 55
11 < NA > < NA > 7 77
12 12 < NA > 9 99
na.rm = F
Group.by1 Group.by2 by1 by2 v1 v2
1 1 95 1 95 5 55
2 2 95 2 95 7 77
3 1 99 1 99 5 55
4 2 99 2 99 NA NA
5 big damp big damp 3 33
6 blue dry blue dry 3 33
7 red red red red 4 44
8 red wet red wet 1 11
概述 :reshape2包包含了对数据集的重构与整合,功能十分强大操作步骤 :先将数据融合(melt) ,以使每一行都是唯一的标识符-变量组合,然后将数据**重铸(cast)**为你想要的形状安装 :install.packages( "reshape2" )
library( reshape2)
示例 :原始数据集
测量(测试变量)指最后两列的值,在知道ID,Time,变量X1/X2后可以确定测量值 ID Time X1 X2 1 1 5 6 1 2 3 5 2 1 6 1 2 2 2 4
函数 :melt() 功能 :将数据集重构为:每个测试变量独占一行,行中带有要唯一确认这个给测量所需的标识符变量。语法 :melt( data, ... , na.rm = FALSE , value.name = "value" )
ID <- c( 1 , 1 , 2 , 2 )
Time <- c( 1 , 2 , 1 , 2 )
X1 <- c( 5 , 3 , 6 , 2 )
X2 <- c( 6 , 5 , 1 , 4 )
md <- data.frame( ID, Time, X1, X2)
md1 <- melt( md, , id = c( "ID" , "Time" ) )
ID Time variable value
1 1 1 X1 5
2 1 2 X1 3
3 2 1 X1 6
4 2 2 X1 2
5 1 1 X2 6
6 1 2 X2 5
7 2 1 X2 1
8 2 2 X2 4
函数 :dcast() 功能 :读取已融合的数据,并使用你提供的公式和一个(可选)用于整合数据的函数将其重铸。语法 :dcast(
data,
formula,
fun.aggregate = NULL ,
)
rowvar1 + rowvar2 + ... ~ colvar1 + colvar2 + ...
>
> dcast( md1, ID+ Time~ variable)
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
> dcast( md1, ID+ variable~ Time)
ID variable 1 2
1 1 X1 5 3
2 1 X2 6 5
3 2 X1 6 2
4 2 X2 1 4
> dcast( md1, variable~ ID+ Time)
variable 1 _1 1 _2 2 _1 2 _2
1 X1 5 3 6 2
2 X2 6 5 1 4
>
>
> dcast( md1, ID~ variable, mean)
ID X1 X2
1 1 4 5.5
2 2 4 2.5
> dcast( md1, Time~ variable, mean)
Time X1 X2
1 1 5.5 3.5
2 2 2.5 4.5
> dcast( md1, ID~ Time, mean)
ID 1 2
1 1 5.5 4
2 2 3.5 3










![[附源码]Python计算机毕业设计SSM加油站管理信息系统(程序+LW)](https://img-blog.csdnimg.cn/319a77e43e6f47038eade0799a8d8e6b.png)