报错信息不清不楚的。
报错信息不清不楚的。
经过几个周的排查,有以下原因:
- 自定义的trainer里面的
predict函数没有返回有效的返回值。 - 也有可能是自定义的网络没有使用softmax结尾。(若没有,加上即可)
应该是二者满足其一就可以。。因为有很多网络并不是分类任务,那个在predict里面写好应该也不会出现这个错误。
应当是这样的,可以参考FedAvgTrainer的代码:
def _predict(self, dataset: Dataset):
pred_result = []
# switch eval mode
dataset.eval()
self.model.eval()
labels = []
length=len(dataset.get_sample_ids())
ret_rs = torch.rand(length,1)
ret_label = torch.rand(length, 1).int()
return dataset.get_sample_ids(), ret_rs, ret_label
我这是随便写的废函数,里面的东西是没有意义的,但是符合FATE框架的接口,加入这些后,get out put data就能够在Fateboard中显示:
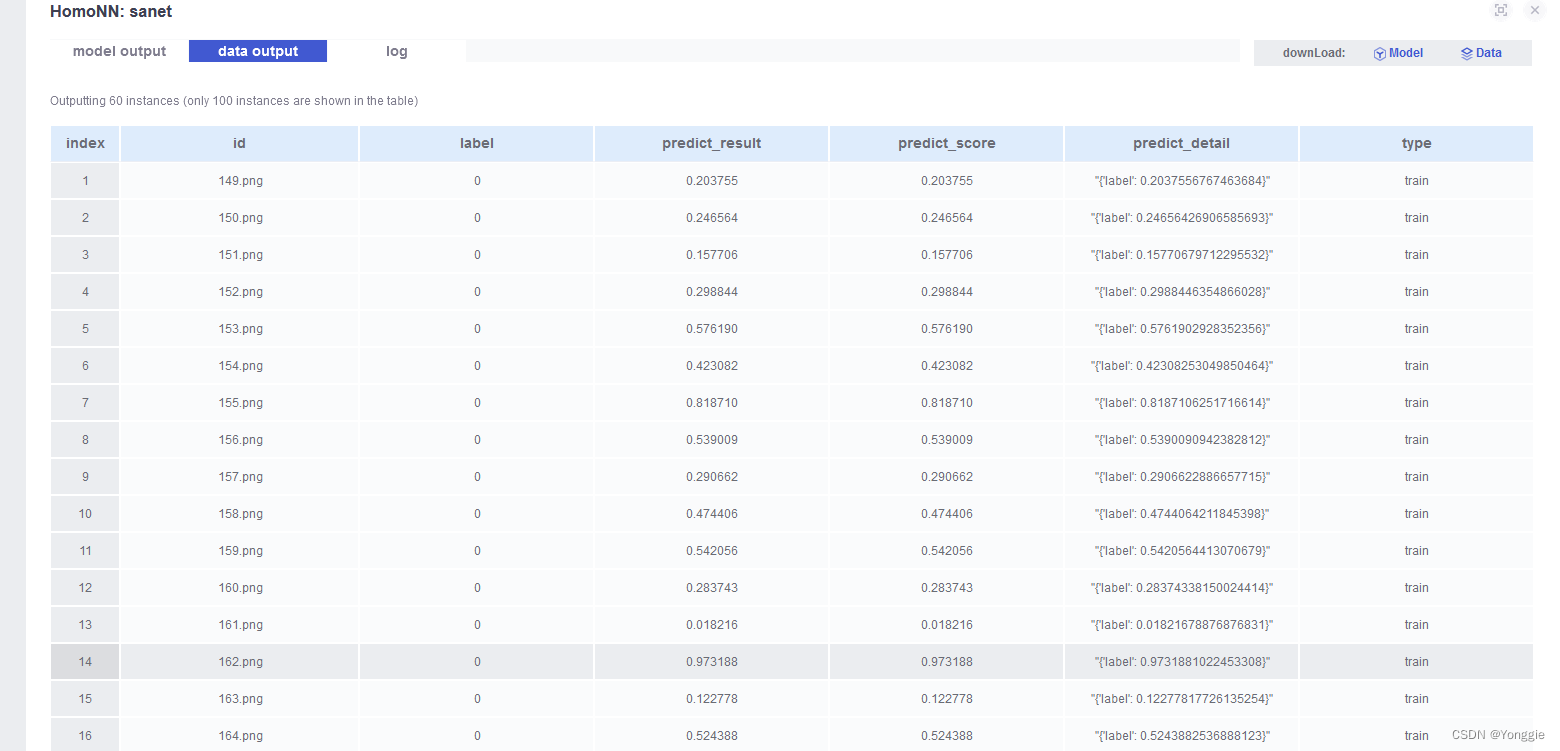 可见
可见_predict函数会在我们没看见(或者说人工找不着)的地方被调用,并且要按照一定的格式返回数据才行。
最后我贴一下我自定义的SATrainer,可以看见我全城是没有调用predict函数的。
import pandas as pd
from federatedml.model_base import Metric, MetricMeta
import torch.distributed as dist
from federatedml.nn.backend.utils import distributed_util
from federatedml.nn.backend.utils import deepspeed_util
import apex
import torch
import torch as t
import tqdm
import torch.nn.functional as F
import numpy as np
from torch.utils.data import DataLoader
from federatedml.framework.homo.aggregator.secure_aggregator import SecureAggregatorClient as SecureAggClient
from federatedml.framework.homo.aggregator.secure_aggregator import SecureAggregatorServer as SecureAggServer
from federatedml.nn.dataset.base import Dataset
from federatedml.nn.homo.trainer.trainer_base import TrainerBase
from federatedml.util import LOGGER, consts
from federatedml.optim.convergence import converge_func_factory
class SATrainer(TrainerBase):
"""
Parameters
----------
epochs: int >0, epochs to train
batch_size: int, -1 means full batch
secure_aggregate: bool, default is True, whether to use secure aggregation. if enabled, will add random number
mask to local models. These random number masks will eventually cancel out to get 0.
weighted_aggregation: bool, whether add weight to each local model when doing aggregation.
if True, According to origin paper, weight of a client is: n_local / n_global, where n_local
is the sample number locally and n_global is the sample number of all clients.
if False, simply averaging these models.
early_stop: None, 'diff' or 'abs'. if None, disable early stop; if 'diff', use the loss difference between
two epochs as early stop condition, if differences < tol, stop training ; if 'abs', if loss < tol,
stop training
tol: float, tol value for early stop
aggregate_every_n_epoch: None or int. if None, aggregate model on the end of every epoch, if int, aggregate
every n epochs.
cuda: bool, use cuda or not
pin_memory: bool, for pytorch DataLoader
shuffle: bool, for pytorch DataLoader
data_loader_worker: int, for pytorch DataLoader, number of workers when loading data
validation_freqs: None or int. if int, validate your model and send validate results to fate-board every n epoch.
if is binary classification task, will use metrics 'auc', 'ks', 'gain', 'lift', 'precision'
if is multi classification task, will use metrics 'precision', 'recall', 'accuracy'
if is regression task, will use metrics 'mse', 'mae', 'rmse', 'explained_variance', 'r2_score'
checkpoint_save_freqs: save model every n epoch, if None, will not save checkpoint.
task_type: str, 'auto', 'binary', 'multi', 'regression'
this option decides the return format of this trainer, and the evaluation type when running validation.
if auto, will automatically infer your task type from labels and predict results.
"""
def __init__(self, epochs=10, batch_size=512, # training parameter
early_stop=None, tol=0.0001, # early stop parameters
secure_aggregate=True, weighted_aggregation=True, aggregate_every_n_epoch=None, # federation
cuda=True, pin_memory=True, shuffle=True, data_loader_worker=0, # GPU & dataloader
validation_freqs=None, # validation configuration
checkpoint_save_freqs=None, # checkpoint configuration
task_type='auto'
):
super(SATrainer, self).__init__()
# training parameters
self.epochs = epochs
self.tol = tol
self.validation_freq = validation_freqs
self.save_freq = checkpoint_save_freqs
self.task_type = task_type
task_type_allow = [
consts.BINARY,
consts.REGRESSION,
consts.MULTY,
'auto']
assert self.task_type in task_type_allow, 'task type must in {}'.format(
task_type_allow)
# aggregation param
self.secure_aggregate = secure_aggregate
self.weighted_aggregation = weighted_aggregation
self.aggregate_every_n_epoch = aggregate_every_n_epoch
# GPU
self.cuda = cuda
if not torch.cuda.is_available() and self.cuda:
raise ValueError('Cuda is not available on this machine')
# data loader
self.batch_size = batch_size
self.pin_memory = pin_memory
self.shuffle = shuffle
self.data_loader_worker = data_loader_worker
self.early_stop = early_stop
early_stop_type = ['diff', 'abs']
if early_stop is not None:
assert early_stop in early_stop_type, 'early stop type must be in {}, bug got {}' \
.format(early_stop_type, early_stop)
# communicate suffix
self.comm_suffix = 'fedavg'
# check param correctness
self.check_trainer_param([self.epochs,
self.validation_freq,
self.save_freq,
self.aggregate_every_n_epoch],
['epochs',
'validation_freq',
'save_freq',
'aggregate_every_n_epoch'],
self.is_pos_int,
'{} is not a positive int')
self.check_trainer_param([self.secure_aggregate, self.weighted_aggregation, self.pin_memory], [
'secure_aggregate', 'weighted_aggregation', 'pin_memory,'], self.is_bool, '{} is not a bool')
self.check_trainer_param(
[self.tol], ['tol'], self.is_float, '{} is not a float')
def _init_aggregator(self, train_set):
# compute round to aggregate
cur_agg_round = 0
if self.aggregate_every_n_epoch is not None:
aggregate_round = self.epochs // self.aggregate_every_n_epoch
else:
aggregate_round = self.epochs
# initialize fed avg client
if self.fed_mode:
if self.weighted_aggregation:
sample_num = len(train_set)
else:
sample_num = 1.0
if not distributed_util.is_distributed() or distributed_util.is_rank_0():
client_agg = SecureAggClient(
True, aggregate_weight=sample_num, communicate_match_suffix=self.comm_suffix)
else:
client_agg = None
else:
client_agg = None
return client_agg, aggregate_round
def set_model(self, model: t.nn.Module):
self.model = model
if self.cuda:
self.model = self.model.cuda()
def train(
self,
train_set: Dataset,
validate_set: Dataset = None,
optimizer: t.optim.Optimizer = None,
loss=None,
extra_dict={}):
if self.cuda:
self.model = self.model.cuda()
if optimizer is None or loss is None:
raise ValueError(
'optimizer or loss is None')
self.model, optimizer = apex.amp.initialize(self.model, optimizer, opt_level='O2')
if self.batch_size > len(train_set) or self.batch_size == -1:
self.batch_size = len(train_set)
dl = DataLoader(
train_set,
batch_size=self.batch_size,
pin_memory=self.pin_memory,
shuffle=self.shuffle,
num_workers=self.data_loader_worker)
# compute round to aggregate
cur_agg_round = 0
client_agg, aggregate_round = self._init_aggregator(train_set)
# running var
cur_epoch = 0
loss_history = []
need_stop = False
evaluation_summary = {}
# training process
for i in range(self.epochs):
if i+1 in [64, 96]:
optimizer.param_groups[0]['lr'] *= 0.5
optimizer.param_groups[1]['lr'] *= 0.5
cur_epoch = i
LOGGER.info('epoch is {}'.format(i))
epoch_loss = 0.0
ce_epoch=0.0
dice_epoch=0.0
dice_loss_epoch=0.0
batch_idx = 0
# for better user interface
if not self.fed_mode:
to_iterate = tqdm.tqdm(dl)
else:
to_iterate = dl
for image, mask in to_iterate:
if self.cuda:
image, mask = self.to_cuda(
image), self.to_cuda(mask)
self.model.cuda()
image,mask=image.float(),mask.float()
rand = np.random.choice([256, 288, 320, 352], p=[0.1, 0.2, 0.3, 0.4])
image = F.interpolate(image, size=(rand, rand), mode='bilinear')
mask = F.interpolate(mask.unsqueeze(1), size=(rand, rand), mode='nearest').squeeze(1)
pred = self.model(image)
pred = F.interpolate(pred, size=mask.shape[1:], mode='bilinear', align_corners=True)[:,0,:,:]
# LOGGER.info(f'pred {pred.shape}, mask {mask.shape}')
loss_ce, loss_dice = loss(pred, mask)
dice_epoch=dice_epoch+1-loss_dice
ce_epoch=ce_epoch+loss_ce
dice_loss_epoch=dice_loss_epoch+loss_dice
optimizer.zero_grad()
# apex loss加速
with apex.amp.scale_loss(loss_ce+loss_dice, optimizer) as scale_loss:
scale_loss.backward()
# 打印/Log用
# epoch_loss=loss_ce+loss_dice
cur_loss=scale_loss
epoch_loss+=cur_loss
# 普通
# epoch_loss=loss_ce+loss_dice
# epoch_loss.backward()
optimizer.step()
if self.fed_mode:
LOGGER.debug(
'epoch {} batch {} finished'.format(
i, batch_idx))
# loss compute
epoch_loss = epoch_loss / len(train_set)
ce_epoch=ce_epoch/len(train_set)
dice_epoch=dice_epoch/len(train_set)
dice_loss_epoch=dice_loss_epoch/len(train_set)
if not distributed_util.is_distributed() or distributed_util.is_rank_0():
self.callback_loss(epoch_loss.item(),i)
# self._tracker.log_metric_data(
# metric_name="loss",
# metric_namespace="train",
# metrics=[Metric(epoch_idx, loss)],
# )
self.callback_metric('Dice',dice_epoch.item(),'train',i)
self.callback_metric('Dice Loss',dice_loss_epoch.item(),'train',i)
self.callback_metric('CE',ce_epoch.item(),'train',i)
self.callback_metric('LR',optimizer.param_groups[0]['lr'],'train',i)
loss_history.append(float(epoch_loss))
LOGGER.info('epoch loss is {}'.format(epoch_loss.item()))
# federation process, if running local mode, cancel federation
if client_agg is not None or distributed_util.is_distributed():
if not (self.aggregate_every_n_epoch is not None and (i + 1) % self.aggregate_every_n_epoch != 0):
# model averaging, only aggregate trainable param
if self._deepspeed_zero_3:
deepspeed_util.gather_model(self.model)
if not distributed_util.is_distributed() or distributed_util.is_rank_0():
self.model = client_agg.model_aggregation(self.model)
if distributed_util.is_distributed() and distributed_util.get_num_workers() > 1:
self._share_model()
else:
self._share_model()
# agg loss and get converge status
if not distributed_util.is_distributed() or distributed_util.is_rank_0():
converge_status = client_agg.loss_aggregation(epoch_loss.item())
cur_agg_round += 1
if distributed_util.is_distributed() and distributed_util.get_num_workers() > 1:
self._sync_converge_status(converge_status)
else:
converge_status = self._sync_converge_status()
if not distributed_util.is_distributed() or distributed_util.is_rank_0():
LOGGER.info(
'model averaging finished, aggregate round {}/{}'.format(
cur_agg_round, aggregate_round))
if converge_status:
LOGGER.info('early stop triggered, stop training')
need_stop = True
# save check point process
# if self.save_freq is not None and ((i + 1) % self.save_freq == 0):
# if self._deepspeed_zero_3:
# deepspeed_util.gather_model(self.model)
# if not distributed_util.is_distributed() or distributed_util.is_rank_0():
# if self.save_freq is not None and ((i + 1) % self.save_freq == 0):
# if self.save_to_local_dir:
# self.local_checkpoint(
# self.model, i, optimizer, converge_status=need_stop, loss_history=loss_history)
# else:
# self.checkpoint(
# self.model, i, optimizer, converge_status=need_stop, loss_history=loss_history)
# LOGGER.info('save checkpoint : epoch {}'.format(i))
# if meet stop condition then stop
if need_stop:
break
# post-process
# if self._deepspeed_zero_3:
# deepspeed_util.gather_model(self.model)
# if not distributed_util.is_distributed() or distributed_util.is_rank_0():
# best_epoch = int(np.array(loss_history).argmin())
# if self.save_to_local_dir:
# self.local_save(model=self.model, optimizer=optimizer, epoch_idx=cur_epoch, loss_history=loss_history,
# converge_status=need_stop, best_epoch=best_epoch)
# else:
# self.save(model=self.model, optimizer=optimizer, epoch_idx=cur_epoch, loss_history=loss_history,
# converge_status=need_stop, best_epoch=best_epoch)
# best_epoch = int(np.array(loss_history).argmin())
# self.summary({
# 'best_epoch': best_epoch,
# 'loss_history': loss_history,
# 'need_stop': need_stop,
# 'metrics_summary': evaluation_summary
# })
def _predict(self, dataset: Dataset):
pred_result = []
# switch eval mode
dataset.eval()
self.model.eval()
labels = []
# with torch.no_grad():
# for images, masks in DataLoader(
# dataset, self.batch_size):
# if self.cuda:
# images,masks = self.to_cuda(images,masks)
# pred = self.model(images)
# pred_result.append(pred)
# # labels.append(batch_label)
# ret_rs = torch.concat(pred_result, axis=0)
# ret_label = torch.concat(labels, axis=0)
# # switch back to train mode
# dataset.train()
# self.model.train()
length=len(dataset.get_sample_ids())
ret_rs = torch.rand(length,1)
ret_label = torch.rand(length, 1).int()
return dataset.get_sample_ids(), ret_rs, ret_label
def predict(self, dataset: Dataset):
ids, ret_rs, ret_label=self._predict(dataset)
if self.fed_mode:
return self.format_predict_result(
ids, ret_rs, ret_label, task_type=self.task_type)
else:
return ret_rs, ret_label
def server_aggregate_procedure(self, extra_data={}):
# converge status
check_converge = False
converge_func = None
if self.early_stop:
check_converge = True
converge_func = converge_func_factory(
self.early_stop, self.tol).is_converge
LOGGER.info(
'check early stop, converge func is {}'.format(converge_func))
LOGGER.info('server running aggregate procedure')
server_agg = SecureAggServer(True, communicate_match_suffix=self.comm_suffix)
# aggregate and broadcast models
for i in range(self.epochs):
if not (self.aggregate_every_n_epoch is not None and (i + 1) % self.aggregate_every_n_epoch != 0):
# model aggregate
server_agg.model_aggregation()
converge_status = False
# loss aggregate
agg_loss, converge_status = server_agg.loss_aggregation(
check_converge=check_converge, converge_func=converge_func)
self.callback_loss(agg_loss, i)
# save check point process
if self.save_freq is not None and ((i + 1) % self.save_freq == 0):
self.checkpoint(epoch_idx=i)
LOGGER.info('save checkpoint : epoch {}'.format(i))
# check stop condition
if converge_status:
LOGGER.debug('stop triggered, stop aggregation')
break
LOGGER.info('server aggregation process done')