PG中cluster的作用是根据表的索引重新构建一张表,并且表根据该索引进行排序,索引必须提前建好。
注意:cluster操作加ACCESS EXCLUSIVE锁,会阻塞其它任何操作。
我们为什么要运行cluster?
PG中的表是堆表,表中行的顺序可能是乱的,为了加快SQL的查询速度,我们一般会建一个Btree索引,但是如下图所示,可能会造成IO放大,因为要从不同的数据块中取数据,扫描更多的块。
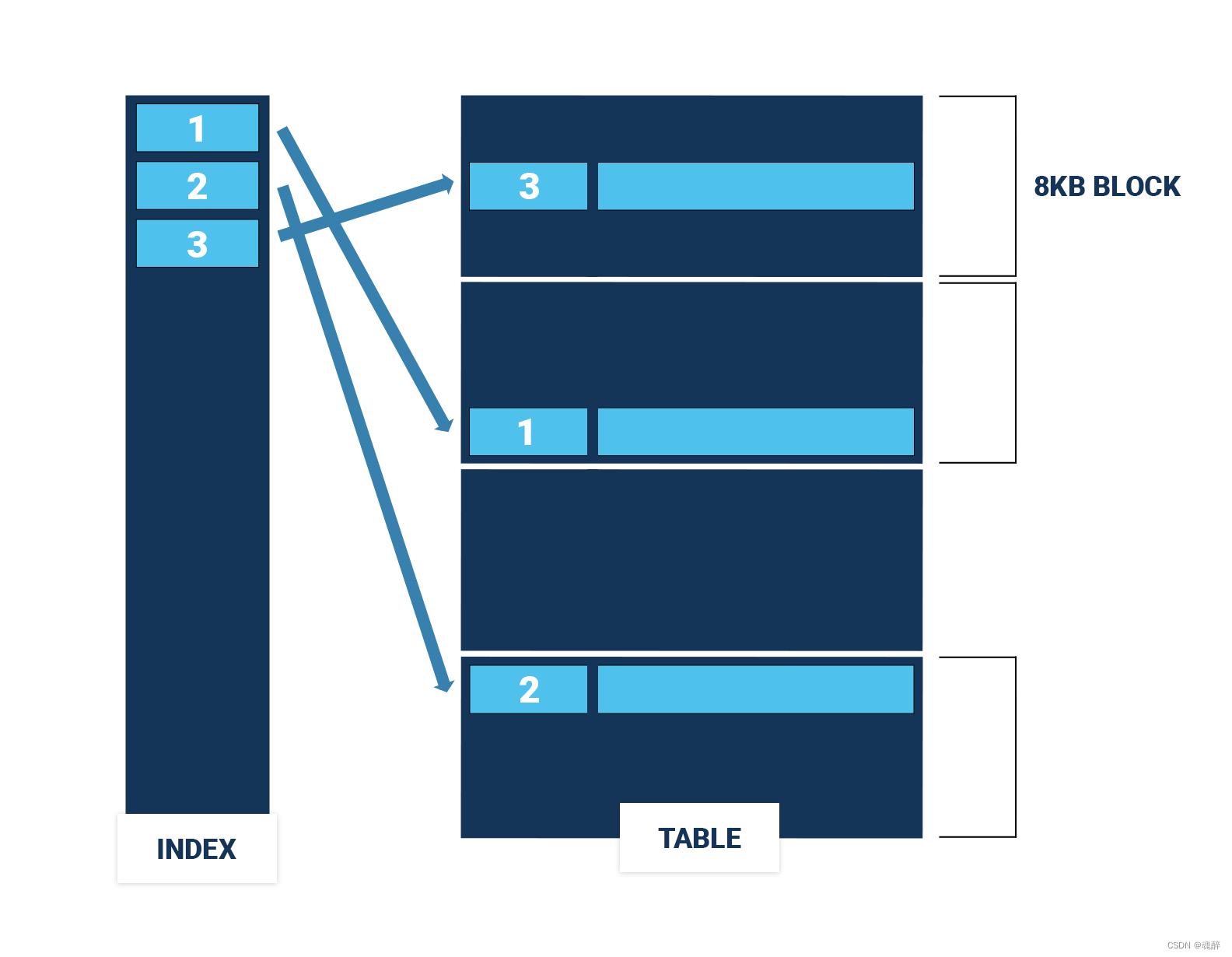
如何提高范围扫描的效率呢?这里我们就可以考虑使用cluster命令,按索引顺序排列行,这样范围扫描的效率就会高很多,如下,同样扫描三行,只需要扫描一个块。
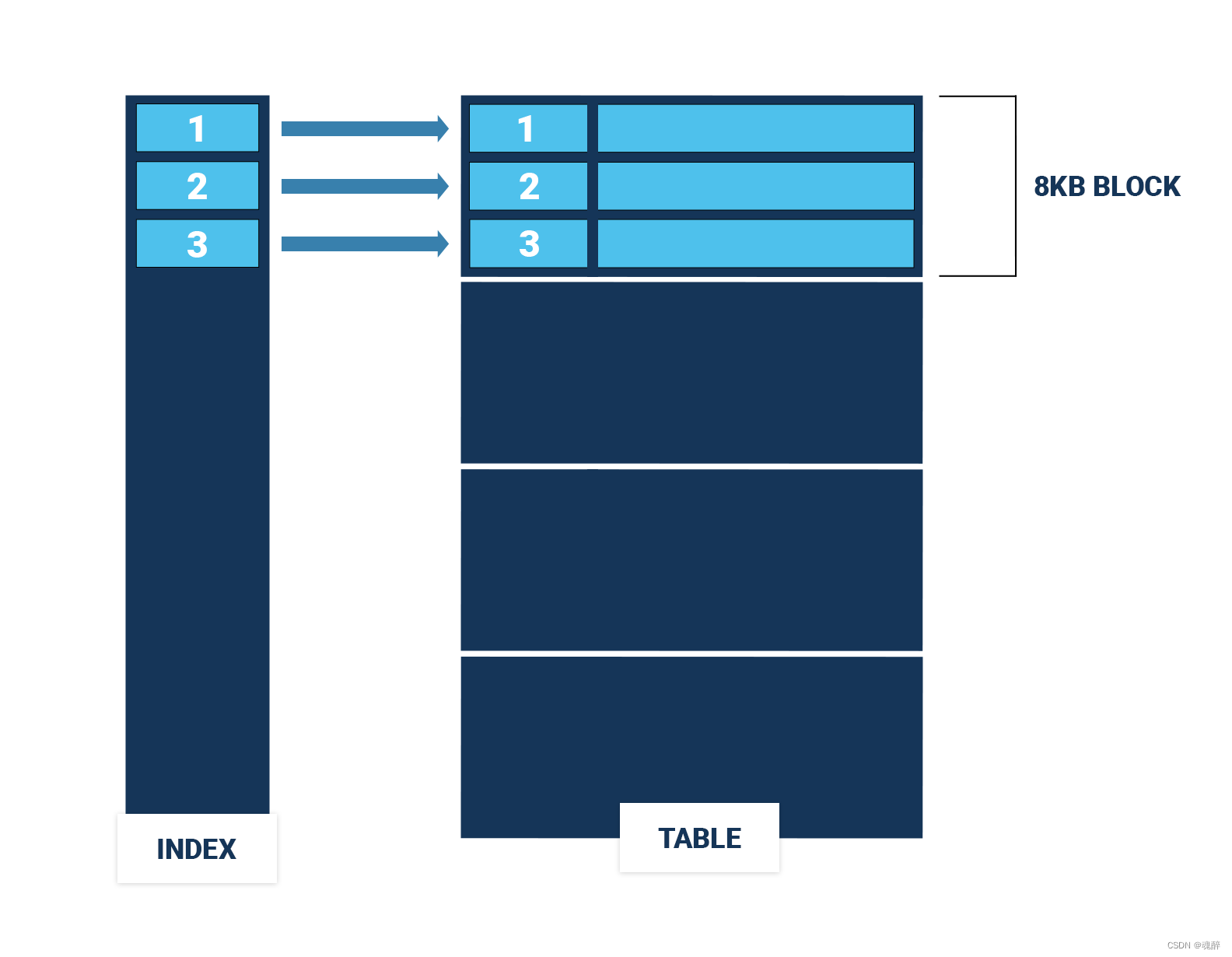
显然,一个表只能有一个物理排序,因此只能在表上的一个索引上加速范围扫描。但是,如果两个索引共享前导列,那么将表聚类到其中一个索引上也会在一定程度上加快对另一个索引的范围扫描。
ANALYZE为每列收集的统计数据的时候,列值与行的物理顺序之间也存在相关性。这是一个介于-1和1之间的数。如果相关性为1,则按值的升序排列行。如果相关性为-1,则按值降序对表进行物理排序。在0附近的相关性意味着物理顺序和逻辑顺序之间没有联系。PostgreSQL优化器使用这种相关性来估计索引范围扫描的成本。
cluster的一些缺点
CLUSTER背后的代码与VACUUM (FULL)相同,只是增加了一个排序。因此,CLUSTER存在和VACUUM (FULL)一样的问题:
- CLUSTER以ACCESS EXCLUSIVE模式锁定表,锁定期间阻塞所有操作
- 需要二倍于表的空间进行操作
此外,CLUSTER建立的顺序不会持续保持:随后的insert和update不会遵守这个顺序,并且相关性会随着时间的推移而“失效”。因此,如果希望索引范围扫描保持快速,就必须定期对表进行cluster操作。
HOT updates可以保持cluster顺序
DELETE不会破坏行顺序,但是也无法阻止insert打乱相关性。然而,PostgreSQL有一个特性可以防止UPDATE破坏表顺序:HOT更新。
HOT更新将新版本的行放在与旧版本相同的8kB块中,并且它不修改任何索引列,因此它极小干扰索引列的相关性。因此,在HOT更新之后,索引列上的索引范围扫描将保持高效!
如前所述,HOT可以在更新期间保持相关性,但它根本不能帮助INSERT。此外,必须将填充因子设置为低于100才能获得大多数HOT更新,这会人为地使表膨胀。因此,它减慢了顺序扫描并降低了缓存的效率。
下面通过实际例子看下效果:
#创建表,然后设置不同的fillfactor进行测试
CREATE UNLOGGED TABLE clu (
id bigint NOT NULL,
key integer NOT NULL,
val integer NOT NULL
) WITH (
autovacuum_vacuum_cost_delay = 0,
fillfactor = ???
);
然后尝试不同的填充因子。我将使用pgbench对表进行更新,因此我将autovacuum调整为尽快执行,以便它能够应付工作负载。
插入数据,创建索引,收集统计信息
INSERT INTO clu (id, key, val)
SELECT i, hashint4(i), 0
FROM generate_series(1, 10000000) AS i;
#创建索引
CREATE INDEX clu_idx ON clu(key);
CLUSTER clu USING clu_idx;
#收集统计信息
ALTER TABLE clu ADD PRIMARY KEY (id);
/* set hint bits and gather statistics */
VACUUM (ANALYZE) clu;
使用pgbench进行测试
\set i random(1, 10000000)
UPDATE clu SET val = val + 1 WHERE id = :i;
#6个client,更新60 million次
pgbench --random-seed=42 --no-vacuum --file=updates --transactions=10000000 --client=6
然后查看相关性,以及有多少HOT更新,以及autovacuum是否被触发
ANALYZE clu;
SELECT correlation
FROM pg_stats
WHERE tablename = 'clu' AND attname = 'key';
SELECT n_tup_hot_upd, autovacuum_count
FROM pg_stat_user_tables
WHERE relname = 'clu';
只要所有的更新都是HOT,再降低填充系数就没什么不同了。
查看一下表膨胀了多少
SELECT pg_size_pretty(
pg_table_size('clu')
) AS tab_size,
pg_size_pretty(
pg_total_relation_size('clu')
- pg_table_size('clu')
) AS ind_size;
在PostgreSQL 15.2中进行不同的fillfactor设置,进行测试后,表和索引膨胀是相对于使用默认填充因子新创建的表和索引的大小来测量的(表占用422 MB,两个索引总共占用428 MB)。

总结:
如果一个表没有insert操作,那么我们可以设置fillfactor,以便所有或大部分更新都是HOT,那么该表可以在很长的时间内或永远保持在CLUSTER建立的顺序。通过这种方式,我们可以获得快速的索引范围扫描,而不需要或减少定期重新cluster的需要。
参考:
https://www.postgresql.org/docs/current/sql-cluster.html
https://www.cybertec-postgresql.com/en/use-hot-so-cluster-wont-rot-postgresql/
https://dazuiba008.blog.csdn.net/article/details/90749905?spm=1001.2014.3001.5502