进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容!
在某些多维分析场景下,数据既没有主键,也没有聚合需求,只需要将数据原封不动的存入表中,数据有主键重复也都要存储。因此,我们引入 Duplicate 数据模型来满足这类需求。Duplicate数据模型只指定排序列,相同的行不会合并,适用于数据无需提前聚合的分析业务。举例说明,有如下表结构数据:

建表语句如下:
CREATE TABLE IF NOT EXISTS example_db.example_duplicate_tbl
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`, `error_code`)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);创建表成功后,向表中插入如下数据:
insert into example_db.example_duplicate_tbl values
("2023-03-01 08:00:00",1,200,"错误200",1001,"2023-03-01 09:00:00"),
("2023-03-02 08:00:00",2,201,"错误201",1002,"2023-03-02 09:00:00"),
("2023-03-03 08:00:00",3,202,"错误202",1003,"2023-03-03 09:00:00"),
("2023-03-04 08:00:00",4,203,"错误203",1004,"2023-03-04 09:00:00"),
("2023-03-04 08:00:00",4,203,"错误203",1004,"2023-03-04 09:00:00"),
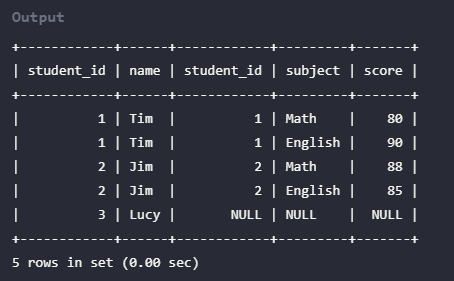
("2023-03-04 08:00:00",4,203,"错误203",1005,"2023-03-05 10:00:00");插入数据后,表example_db.example_duplicate_tbl结果如下:
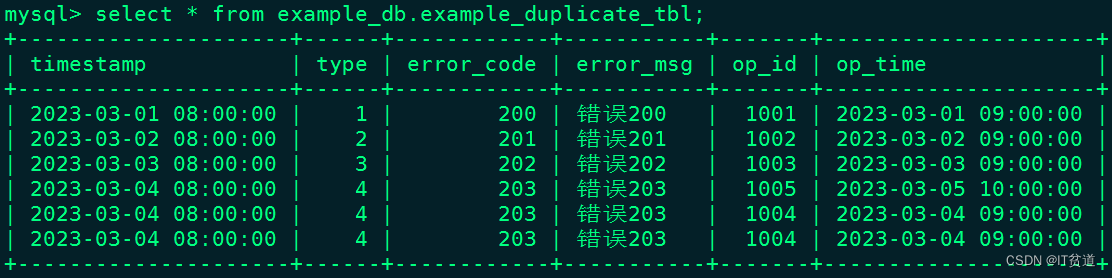
这种数据模型区别于 Aggregate 和 Unique 模型,数据完全按照导入文件/或插入的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序,更贴切的名称应该为 “Sorted Column”,这里取名 “DUPLICATE KEY” 只是用以明确表示所用的数据模型。关于 “Sorted Column”的更多解释,可以参考3.8小节前缀索引。
在 Aggregate、Unique 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQUE KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。在 DUPLICATE KEY 的选择上,我们建议适当的选择前 2-4 列就可以。