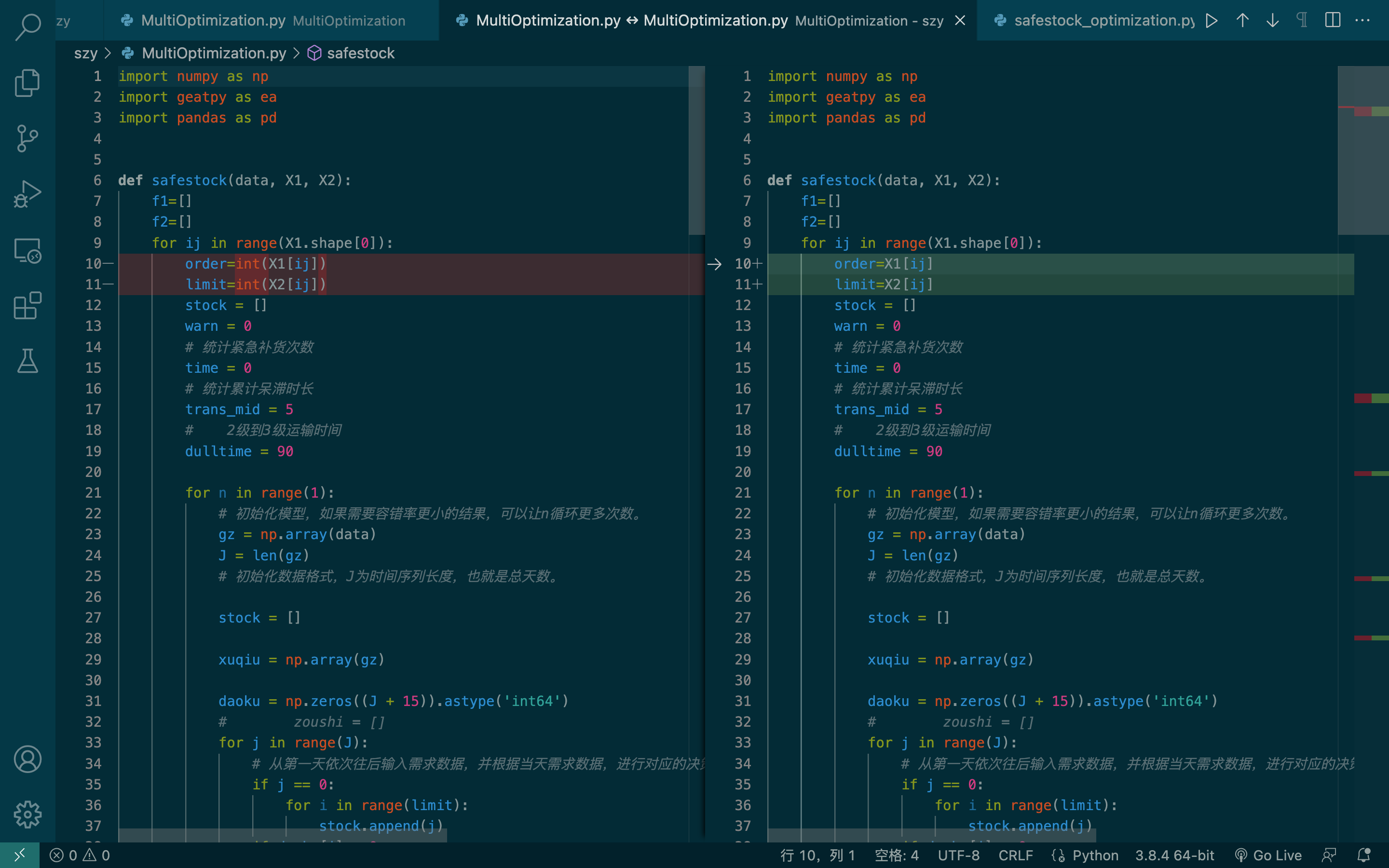
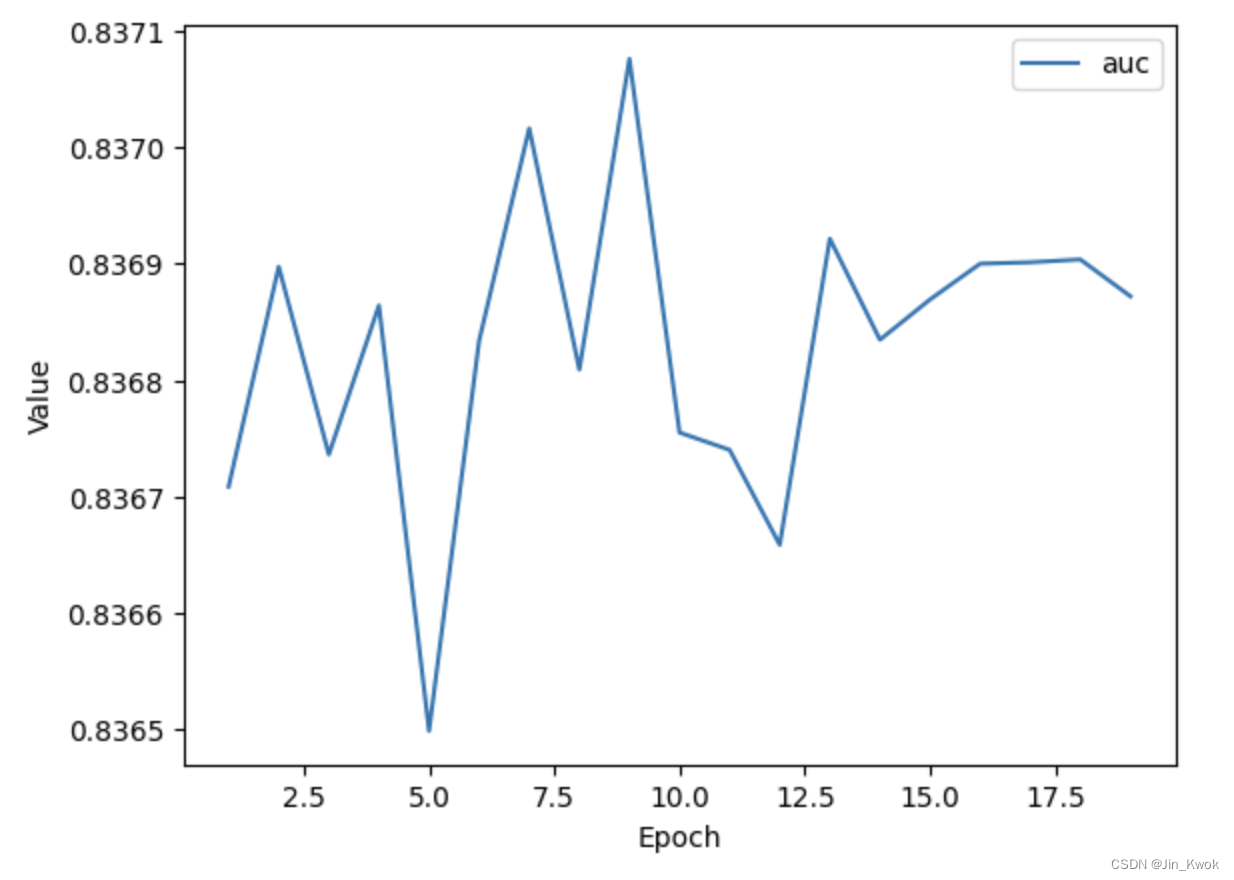
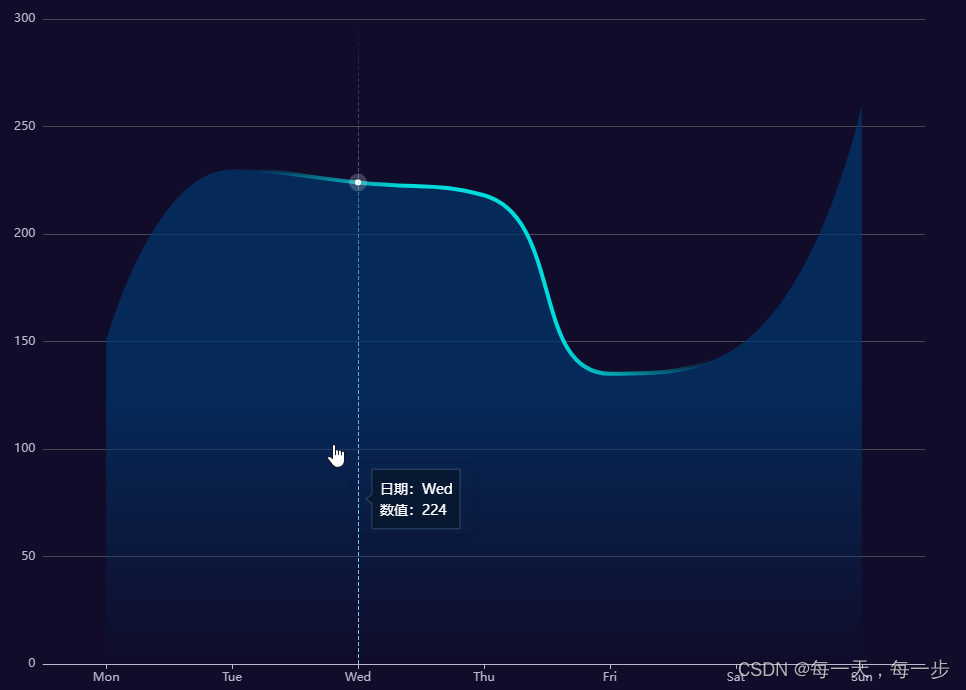
Stratego是一款流行的双人不完美信息棋盘游戏。由于其复杂性源于其巨大的游戏树、在不完善的信息下进行决策以及一开始的分段部署阶段,Stratego对人工智能(AI)构成了挑战。以前的计算机程序充其量只在业余水平上运行。
Perolat等人引入了一种无模型的多代理强化学习方法,并表明它可以在Stratego中实现人类专家级绩效。目前的工作不仅增加了越来越多的游戏,人工智能系统可以玩得和人类一样好,甚至比人类更好,而且还可能促进强化学习方法在现实世界、大规模多代理问题中的进一步应用,这些问题的特点是信息不完善,因此目前无法解决。
我们介绍了DeepNash,一个在人类专家层面玩不完美的信息游戏Stratego的自主代理。Stratego是人工智能(AI)尚未掌握的为数不多的标志性棋盘游戏之一。
这是一个以双重挑战为特征的游戏:它需要像国际象棋一样进行长期的战略思维,但它也需要像扑克一样处理不完美的信息。
支撑DeepNash的技术使用一种游戏理论、无模型的深度强化学习方法,无需搜索,通过从头开始的自我游戏来学习掌握Stratego。DeepNash击败了Stratego中现有的最先进的人工智能方法,并在Gravon游戏平台上实现了年初至今(2022年)和历史前三名,与人类专家玩家竞争。

Stratego是一款流行的双人不完美信息棋盘游戏。由于其复杂性源于其巨大的游戏树、在不完善的信息下进行决策以及一开始的分段部署阶段,Stratego对人工智能(AI)构成了挑战。以前的计算机程序充其量只在业余水平上运行。
Perolat等人引入了一种无模型的多代理强化学习方法,并表明它可以在Stratego中实现人类专家级绩效。目前的工作不仅增加了越来越多的游戏,人工智能系统可以玩得和人类一样好,甚至比人类更好,而且还可能促进强化学习方法在现实世界、大规模多代理问题中的进一步应用,这些问题的特点是信息不完善,因此目前无法解决。
我们介绍了DeepNash,一个在人类专家层面玩不完美的信息游戏Stratego的自主代理。Stratego是人工智能(AI)尚未掌握的为数不多的标志性棋盘游戏之一。
这是一个以双重挑战为特征的游戏:它需要像国际象棋一样进行长期的战略思维,但它也需要像扑克一样处理不完美的信息。
支撑DeepNash的技术使用一种游戏理论、无模型的深度强化学习方法,无需搜索,通过从头开始的自我游戏来学习掌握Stratego。DeepNash击败了Stratego中现有的最先进的人工智能方法,并在Gravon游戏平台上实现了年初至今(2022年)和历史前三名,与人类专家玩家竞争。