highlight: arduino-light
消息重复的场景
发送消息异常,重试发送导致消息重复★
当一条消息已被成功发送到服务端并完成持久化。此时出现网络闪断或者客户端宕机,导致服务端对生产者的确认应答失败。生产者发送消息到mq时发送成功未获取到响应,然后生产者进行消息发送重试,导致消息发送多次。
生产者重试发送的操作比较简单,就是选择另一台机器的Queue来发送。
虽然重试操作可以很大程度保证消息能够发送成功,但是同时也会带来消息重复发送的问题。
举个例子,假设生产者向A机器发送消息,发生了异常,响应超时了,但是就一定代表消息没发成功么?
不一定,有可能会出现服务端的确接收到并处理了消息,但是由于网络波动等等,导致生产者接收不到服务端响应的情况,此时消息处理成功了,但是生成者还是以为发生了异常
此时如果发生重试操作,那么势必会导致消息被发送了两次甚至更多次,导致服务端存了多条相同的消息,那么就一定会导致消费者重复消费消息 。
集群模式批量消费消息抛出异常
批量消费中,若某条消息消费失败,则重试会将整批消息重发。
批量消费是一次取一批消息,等这一批消息都成功,再提交最后一条消息的位置,作为新的消费位置。若其中任一条失败,则认为整批都失败。
在RocketMQ的集群消费消息的模式下,需要用户实现MessageListenerConcurrently来处理消息。
java public interface MessageListenerConcurrently extends MessageListener { ConsumeConcurrentlyStatus consumeMessage(final List<MessageExt> msgs, final ConsumeConcurrentlyContext context); }
当消费者获取到消息之后会调用MessageListenerConcurrently的实现,传入需要消费的消息集合 msgs,这里提到的msgs很重要.
```java public class DefaultMessageListenerConcurrently implements MessageListenerConcurrently {
@SuppressWarnings("unchecked")
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt messageExt : msgs) {
log.debug("received msg: {}", messageExt);
try {
long now = System.currentTimeMillis();
handleMessage(messageExt);
long costTime = System.currentTimeMillis() - now;
log.debug("consume {} cost: {} ms", messageExt.getMsgId(), costTime);
} catch (Exception e) {
log.warn("consume message failed. messageId:{}, topic:{}, reconsumeTimes:{}", messageExt.getMsgId(), messageExt.getTopic(), messageExt.getReconsumeTimes(), e);
context.setDelayLevelWhenNextConsume(delayLevelWhenNextConsume);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}} ```
如上代码,当消息消费出现异常的时候,status就会为null,后面就会将status设置成为RECONSUME_LATER。
RECONSUME_LATER翻译成功中文就是稍后重新消费的意思
所以从这可以看出,一旦抛出异常,那么消息之后就可以被重复消息。
到这其实可能有小伙伴觉得消息消费失败重新消费很正常,保证消息尽可能消费成功。
对,这句话不错,的确可以在一定程度上保证消费异常的消息可以消费成功。
但是坑不在这,而是前面提到的消费时传入的整个集合 中的消息都需要被重新消费。
具体的原因我们接着往下看
当消息处理之后,不论是成功还是异常,都需要对结果进行处理,代码如下
代码位置:ConsumeMessageConcurrentlyService#processConsumeResult
```java switch (status) { case CONSUMESUCCESS: if (ackIndex >= consumeRequest.getMsgs().size()) { ackIndex = consumeRequest.getMsgs().size() - 1; } int ok = ackIndex + 1; int failed = consumeRequest.getMsgs().size() - ok; this.getConsumerStatsManager().incConsumeOKTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), ok); this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), failed); break; case RECONSUMELATER: //重点代码1 ackIndex = -1; this.getConsumerStatsManager().incConsumeFailedTPS(consumerGroup, consumeRequest.getMessageQueue().getTopic(), consumeRequest.getMsgs().size()); break; default: break; } switch (this.defaultMQPushConsumer.getMessageModel()) { case BROADCASTING: for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) { MessageExt msg = consumeRequest.getMsgs().get(i); log.warn("BROADCASTING, the message consume failed, drop it, {}", msg.toString()); } break; case CLUSTERING: //重点代码2 List msgBackFailed = new ArrayList (consumeRequest.getMsgs().size()); for (int i = ackIndex + 1; i < consumeRequest.getMsgs().size(); i++) { MessageExt msg = consumeRequest.getMsgs().get(i); boolean result = this.sendMessageBack(msg, context); if (!result) { msg.setReconsumeTimes(msg.getReconsumeTimes() + 1); msgBackFailed.add(msg); } }
if (!msgBackFailed.isEmpty()) {
consumeRequest.getMsgs().removeAll(msgBackFailed);
this.submitConsumeRequestLater(msgBackFailed, consumeRequest.getProcessQueue(), consumeRequest.getMessageQueue());
}
break;
default:
break;} ``` 可以看到当处理结果为RECONSUMELATER的时候(异常会设置为RECONSUMELATER),此时ackIndex会设置成-1。 然后如果是集群模式首先会遍历到这一批消费的消息,然后依次调用sendMessageBack方法,sendMessageBack顾名思义就是把消息重新发回broker呗。
```java public void sendMessageBack(MessageExt msg, int delayLevel, final String brokerName) throws RemotingException, MQBrokerException, InterruptedException, MQClientException { try { String brokerAddr = (null != brokerName) ? this.mQClientFactory.findBrokerAddressInPublish(brokerName) : RemotingHelper.parseSocketAddressAddr(msg.getStoreHost()); //重点代码1
this.mQClientFactory.getMQClientAPIImpl().consumerSendMessageBack(brokerAddr, msg, this.defaultMQPushConsumer.getConsumerGroup(), delayLevel, 5000, getMaxReconsumeTimes()); } catch (Exception e) { log.error("sendMessageBack Exception, " + this.defaultMQPushConsumer.getConsumerGroup(), e);
Message newMsg = new Message(MixAll.getRetryTopic(this.defaultMQPushConsumer.getConsumerGroup()), msg.getBody());
String originMsgId = MessageAccessor.getOriginMessageId(msg);
MessageAccessor.setOriginMessageId(newMsg, UtilAll.isBlank(originMsgId) ? msg.getMsgId() : originMsgId);
newMsg.setFlag(msg.getFlag());
MessageAccessor.setProperties(newMsg, msg.getProperties());
MessageAccessor.putProperty(newMsg, MessageConst.PROPERTY_RETRY_TOPIC, msg.getTopic());
MessageAccessor.setReconsumeTime(newMsg, String.valueOf(msg.getReconsumeTimes() + 1));
MessageAccessor.setMaxReconsumeTimes(newMsg, String.valueOf(getMaxReconsumeTimes()));
MessageAccessor.clearProperty(newMsg, MessageConst.PROPERTY_TRANSACTION_PREPARED);
newMsg.setDelayTimeLevel(3 + msg.getReconsumeTimes());
this.mQClientFactory.getDefaultMQProducer().send(newMsg);
} finally {
msg.setTopic(NamespaceUtil.withoutNamespace(msg.getTopic(), this.defaultMQPushConsumer.getNamespace()));
}} ``` 简单看一下sendMessageBack的逻辑。重点代码有2行
1.在try中调用了this.mQClientFactory.getMQClientAPIImpl().consumerSendMessageBack() 2.在catch中调用了this.mQClientFactory.getDefaultMQProducer().send(newMsg);
consumerSendMessageBack的方法中发送给broker的请求是ConsumerSendMsgBackRequestHeader,请求类型是RequestCode.CONSUMERSENDMSG_BACK,在这个请求中包含了consumerGroup、消息原始的topic、消息的commitlog offset、消息的延迟级别、消息原来的msgId和消息最大重新消费次数。
broker处理RequestCode.CONSUMERSENDMSG_BACK类型的请求逻辑大致如下:
1.创建重试主题%RETRY%+消费组名称
2.将消息的重试topic存入消息的扩展属性中
3.如果消息的消费重试次数大于最大重新消费次数或则延迟级别小于0,修改消息的topic名称为%DLQ%,设置该主题的权限为只写,说明消息进入死信队列后将不再被消费;如果消息的延迟级别为0则将消息的延迟级别设置为3与重新消费次数的和
4.根据原来的消息创建一个新的消息对象,该重试消息会拥有与原来消息不一样且唯一的msgId,将重试消息存储在commitlog中
5.将重试消息存入commitlog中时会将重试消息的topic和queueId备份到其扩展属性中,属性名称分别是REALTOPIC和REALQID,然后将其topic重置为SCHEDULETOPICXXXX,queueId重置为消息延迟级别减一。
这里很有意思,上面我们提到如果消息的延迟级别为0则将消息的延迟级别设置为3与重新消费次数的和,这里是将queueId重置为消息延迟级别减一。也就是如果消息的延迟级别为0则将消息的延迟级别设置为3与重新消费次数1的和减去1作为queueId也就是3+1-1=3,也就是默认的延迟级别从3开始。和我们在第16篇文章中讲的重试次数对上了。 [https://juejin.cn/post/7248995705292865593]
6.等待延迟队列将消息重新发回重试队列消费即可。
send的方法逻辑 主要代码是:newMsg.setDelayTimeLevel(3 + msg.getReconsumeTimes());也就是设置延迟级别。 原理和上面大同小异,也是根据延迟级别发送到对应的延迟主题,等待延迟主题重发消息到重试主题。
```java Message newMsg = new Message(MixAll.getRetryTopic(this.defaultMQPushConsumer.getConsumerGroup()), msg.getBody());
String originMsgId = MessageAccessor.getOriginMessageId(msg); MessageAccessor.setOriginMessageId(newMsg, UtilAll.isBlank(originMsgId) ? msg.getMsgId() : originMsgId);
newMsg.setFlag(msg.getFlag()); MessageAccessor.setProperties(newMsg, msg.getProperties()); MessageAccessor.putProperty(newMsg, MessageConst.PROPERTYRETRYTOPIC, msg.getTopic()); MessageAccessor.setReconsumeTime(newMsg, String.valueOf(msg.getReconsumeTimes() + 1)); MessageAccessor.setMaxReconsumeTimes(newMsg, String.valueOf(getMaxReconsumeTimes())); MessageAccessor.clearProperty(newMsg, MessageConst.PROPERTYTRANSACTIONPREPARED); newMsg.setDelayTimeLevel(3 + msg.getReconsumeTimes()); ```
所以,一旦被消费的一批消息中出现一个消费异常的情况,那么就会导致整批消息被重新消费,从而会导致在出现异常之前的成功处理的消息都会被重复消费 ,非常坑。
不过好在消费时传入的消息集合中的消息数量是可以设置的,并且consumeMessageBatchMaxSize默认就是1。
参考: https://blog.csdn.net/qq_25145759/article/details/112344855
也就说默认情况下那个集合中就一条消息,所以默认情况下不会出现消费成功的消息被重复消费的情况。
所以这个参数不要轻易设置,一旦设置大了,就可能导致消息被重新消费。
除了并发消费消息的模式以外,RocketMQ还支持顺序消费消息的模式,也会造成重复消费,逻辑其实差不多,但是在实现消息重新消费的逻辑不一样。
所以不如果介意批量消费消息带来的无效重试,可以将consumeMessageBatchMaxSize设置大一点提高消费速率。
offset上报持久化★
正常使用的前提下重复消费的原因一定跟offset上报,持久化有关系。因为是5秒持久化一次消费进度。
- 集群消费过程中Consumer意外宕机,offset没有上报导致重复消费
- 集群消费过程中Broker意外宕机,offset没有将最新的偏移量持久化导致重复消费
- 广播消费过程Consumer意外宕机,offset没有持久化到本地文件导致重复消费
- offset.json文件意外损坏或删除,进度丢失导致重复消费
- offset.json文件被篡改,进度不准确导致重复消费
首先来讲一讲什么是offset。
前面说过,消息在发送的时候需要指定发送到,消息最后会被放到Queue中,其实真正的消息不是在Queue中,Queue存的是每个消息的位置,但是你可以理解为Queue存的是消息。
而消息在Queue中是有序号的,这个序号就被称为offset,从0开始,单调递增1
这个offset的一个作用就是用来管理消费者的消费进度。
当消费者在成功消费消息之后,需要将所消费的消息的offset提交给RocketMQ服务端,告诉RocketMQ,这个Queue的消息我已经消费到了这个位置了。
提交offset的代码
java public void updateConsumeOffset(MessageQueue mq, long offset) { //顺带提一句 //集群消费模式:offsetStore是RemoteOffsetStore //广播消费模式:offsetStore是LocalOffsetStore this.offsetStore.updateOffset(mq, offset, false); }
这样有一个好处,那么一旦消费者重启了或者其它啥的要从这个Queue拉取消息的时候,此时他只需要问问RocketMQ服务端上次这个Queue消息消费到哪个位置了,之后消费者只需要从这个位置开始消费消息就行了,这样就解决了接着消费的问题。
但是RocketMQ在设计的时候,当消费完消息的时候并不是同步告诉RocketMQ服务端offset,而是定时发送。在消费者启动的时候会开启一个定时任务,默认是5s一次,会通过网络请求将内存中的每个Queue的消费进度offset发送给RocketMQ服务端。
由于是定时任务,所以就可能出现服务器一旦宕机,导致最新消费的offset没有成功告诉RocketMQ服务端的情况
此时,消费进度offset就丢了,那么消费者重启的时候只能从RocketMQ中获取到上一次提交的offset,从这里开始消费,而不是最新的offset,出现明明消费到了第8个消息,RocketMQ却告诉他只消费到了第5个消息的情况,此时必然会导致消息又出现重复消费 的情况。
RocketMQ是以consumer group+queue为单位是管理消费进度的,以一个consumer offset标记这个这个消费组在这条queue上的消费进度。
如果某已存在的消费组出现了新消费实例的时候,依靠这个组的消费进度,就可以判断第一次是从哪里开始拉取的。
每次消息成功后,本地的消费进度会被更新,然后由定时器定时同步到broker,以此持久化消费进度。
但是每次记录消费进度的时候,只会把一批消息中最小的offset值为消费进度值,如下图:
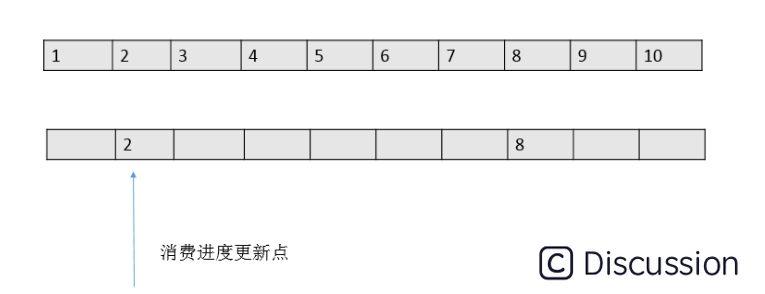
这钟方式和传统的一条message单独ack的方式有本质的区别。在性能上提升的同时,会带来一个潜在的重复问题——由于消费进度只是记录了一个下标,就可能出现拉取了100条消息如 2101-2200的消息,后面99条都消费结束了,只有2101消费一直没有结束的情况。在这种情况下,RocketMQ为了保证消息肯定被消费成功,消费进度只能维持在2101,直到2101也消费结束了,本地的消费进度才会一下子更新到2200。
在这种设计下,就有消费大量重复的风险。如2101在还没有消费完成的时候消费实例突然退出(机器断电,或者被kill)。这条queue的消费进度还是维持在2101,当queue重新分配给新的实例的时候,新的实例从broker上拿到的消费进度还是维持在2101,这时候就会又从2101开始消费,2102-2200这批消息实际上已经被消费过还是会投递一次。
服务端持久化offset失败
消费者会有一个每隔5s钟的定时任务将每个队列的消费进度offset提交到RocketMQ服务端,当RocketMQ服务端接收到提交请求之后,会将这个消费进度offset保存到内存中,同时为了保证RocketMQ服务端重启消费进度不会丢失,也会开启一个定时任务,默认也是5s一次,将内存中的消费进度持久化到磁盘文件中
当RocketMQ服务端重启之后,会从磁盘中读取文件的数据加载到内存中。
跟消费者产生的问题一样,一旦RocketMQ发生宕机,那么offset就有可能丢失5s钟的数据,RocketMQ服务端一旦重启,消费者从RocketMQ服务端获取到的消息消费进度就比实际消费的进度低,同样也会导致消息重复消费。
主从同步offset失败
在RocketMQ的高可用模式中,有一种名叫主从同步的模式,当主节点挂了之后,从节点可以手动升级为主节点对外提供访问,保证高可用。
在主从同步模式下,从节点默认每隔10s会向主节点发送请求,同步一些元数据,这些元数据就包括消费进度。
当从节点获取到主节点的消费进度之后,会将主节点的消费进度设置到自己的内存中,同时也会持久化到磁盘。
同样,由于也是定时任务,那么一旦主节点挂了,从节点就会丢10s钟的消费进度,此时如果从节点升级为主节点对外提供访问,就会出现跟上面提到的一样的情况,消费者从这个新的主节点中拿到的消费进度比实际的低,自然而然就会重复消费消息。
所以,总的来说,在消费进度数据流转的过程中,只要某个环节出现了问题,都有很有可能会导致消息重复消费。
负载均衡时消息重复★
包括但不限于网络抖动、Broker 重启以及消费者应用重启。当消息队列 RocketMQ 的 Broker 或客户端重启、扩容或缩容时,会触发 Rebalance?,此时消费者可能会收到重复消息。
什么是Rebalance?
消费者是从队列中获取消息的,在RocketMQ中,有个消费者组的概念,一个消费者组中可以有多个消费者,不同消费者组之间消费消息是互不干扰的,所以前面提到的消费者其实都在消费组下在同一个消费者组中,消息消费有两种模式: 集群消费模式和广播消费模式,由于RocketMQ默认 是集群消费模式,并且绝大多数业务场景都是使用集群消费模式,所以这里就不讨论广播消费模式了。
集群消费模式 是指同一条消息只能被这个消费者组消费一次,这就叫集群消费。
并且前面提到提交消费进度给RocketMQ服务端的情况只会集群消费模式下才会有,在广播消费模式不会提给到RocketMQ服务端,仅仅持久化到本地磁盘
同时前面说的消费者提交消费进度真正提交的是消费者组对于这个Queue的消费进度,而不是指具体的某个消费者对于Queue消费进度。集群消费的实现就是将队列按照一定的[算法]分配给消费者,默认是按照平均分配的。
假设TopicX一共有8个队列。
消费者A先启动订阅了TopicX的所有的8个queue。
然后过了半小时消费者B启动,此时会触发Rebalance,消费者B会订阅TopicX的后4个queue。
除了新增消费者会导致重平衡之外,消费者数量减少,队列的数量增加或者减少都会触发重平衡。
在了解了重平衡概念之后,接下来分析一下为什么重平衡会导致消息的重复消费。
假设在进行重平衡时,还未重平衡完之前,消费者A此时还是会按照上面第二节提到的消费消息的逻辑来消费Queue4的消息
当消费者A已经重平衡完成了,发现Queue4自己已经不能消费了,那么此时就会把这个Queue4设置为dropped,就是丢弃的意思。
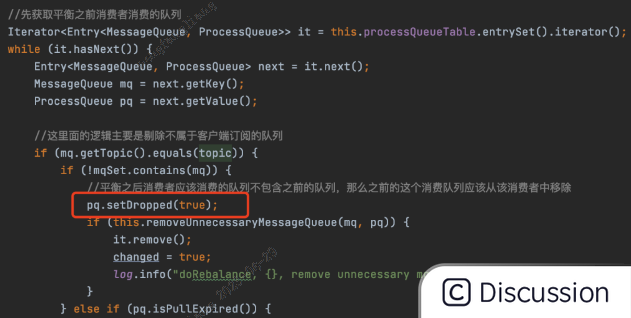
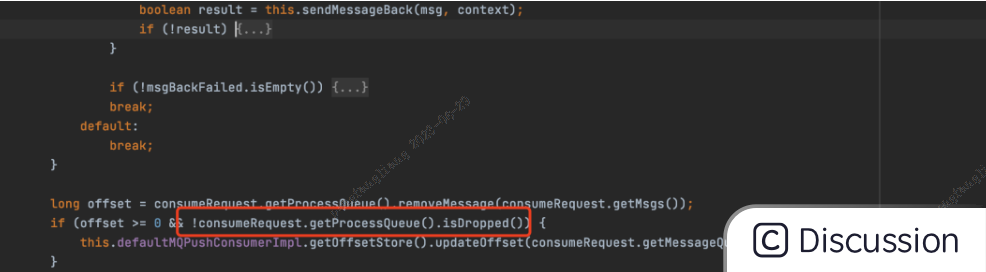
但是由于重平衡进行时消费者2仍然在消费Queue4的消息,但是当消费完之后,发现队列被设置成dropped,那么此时被消费者2消费消息的offset就不会被提交 ,原因如下代码
这段代码前面已经出现过,一旦dropped被设置成true,这个if条件就通不过,消费进度就不会被提交。
成功消费消息了,但是却不提交消费进度,这就非常坑了。。
于是当消费者3开始消费Queue4的消息的时候,他就会问问RocketMQ服务端,我消费者3所在的消费者组对于Queue4这个队列消费到哪了,我接着消费就行了。
此时由于没有提交消费进度,RocketMQ服务端告诉消费者3的消费进度就会比实际的低,这就造成了消息重复消费的情况。
解决Ack卡进度:清理长时间消费的消息
在RocketMQ中有这么一个机制,会定时清理长时间正在消费的消息
[消息1,消息2,消息3,消息4,消息5]
假设有5条消息现在正在被消费者处理,这5条消息会被存在一个集合中,并且是按照offset的大小排序,消息1的offset最小,消息5的offset最大。
RocketMQ消费者启动时会开启一个默认15分钟执行一次的定时任务
java // private long consumeTimeout = 15 分钟 // 15分钟执行一次清理过期消息任务 public void start() { this.cleanExpireMsgExecutors.scheduleAtFixedRate(new Runnable() { @Override public void run() { cleanExpireMsg(); } }, this.defaultMQPushConsumer.getConsumeTimeout(), this.defaultMQPushConsumer.getConsumeTimeout(), TimeUnit.MINUTES); }
这个定时任务会去检查正在处理的消息的第一条消息,也就是消息1,一旦发现消息1已经处理了超过15分钟了,那么此时就会将消息1从集合中移除,之后会隔一定时间再次消费消息1。
这也会有坑,虽然消息1从集合中被移除了,但是消息1并没有消失,仍然被消费者继续处理,但是消息1隔一定时间就会再次被消费,就会出现消息1被重复消费的情况。
这就是清理长时间消费的消息导致重复消费的原因。
但此时又会引出一个新的疑问,为什么要移除这个处理超过15分钟的消息呢?
这就又跟前面提到的消费进度 提交有关,主要是为了防止某些消息消费过慢卡消费进度!
前面说过消息被消费完成之后会提交消费进度,提交的消费进度实际会有两种情况:
第一种 就是某个线程消费了所有的消息,当把所有的消息都消费完成之后,就会把消息从集合中全部移除,此时提交的消费进度offset就是消息5的offset+1
加1的操作是为了保证如果发生重启,那么消费者下次消费的起始位置就是消息5后面的消息,保证消息5不被重复消费
第二种 情况就不太一样了
假设现在有两个线程来处理这5条消息,线程1处理前2条,线程2处理后3条
线程1处理[消息1,消息2] 线程2处理[消息3,消息4,消息5]
现在线程1出现了长时间处理消息的情况。
此时线程2处理完消息之后,移除后面三条消息,准备提交offset的时候发现集合中还有元素,就是线程1正在处理的前两条消息,此时线程2提交的offset并不是消息5对应的offset,而是消息1的offset,代码如下
ConsumeMessageConcurrentlyService.cleanExpireMsg
java private void cleanExpireMsg() { Iterator<Map.Entry<MessageQueue, ProcessQueue>> it = this.defaultMQPushConsumerImpl .getRebalanceImpl() .getProcessQueueTable() .entrySet() .iterator(); //遍历ProcessQueue while (it.hasNext()) { Map.Entry<MessageQueue, ProcessQueue> next = it.next(); ProcessQueue pq = next.getValue(); //清理ProcessQueue中的过期数据 pq.cleanExpiredMsg(this.defaultMQPushConsumer); } } public void cleanExpiredMsg(DefaultMQPushConsumer pushConsumer) { //如果是顺序消费直接返回 不需要清理卡住进度的消息 //这里的值是在start方法中判断ConsumeMessageOrderlyService后设置为true if (pushConsumer.getDefaultMQPushConsumerImpl().isConsumeOrderly()) { return; } //每次最多取16个消息 int loop = msgTreeMap.size() < 16 ? msgTreeMap.size() : 16; for (int i = 0; i < loop; i++) { MessageExt msg = null; try { this.lockTreeMap.readLock().lockInterruptibly(); try { //如果msgTreeMap中还有元素 //且当前时间减去-第一个消息开始消费的时间大于15分钟 if (!msgTreeMap.isEmpty() && System.currentTimeMillis() - Long.parseLong (MessageAccessor.getConsumeStartTimeStamp (msgTreeMap.firstEntry().getValue()))> pushConsumer.getConsumeTimeout() * 60 * 1000) { msg = msgTreeMap.firstEntry().getValue(); } else { break; } } finally { this.lockTreeMap.readLock().unlock(); } } catch (InterruptedException e) { log.error("getExpiredMsg exception", e); } try { //把消息重新发送给broker,设置延迟级别=3 pushConsumer.sendMessageBack(msg,3); try { this.lockTreeMap.writeLock().lockInterruptibly(); try { if (!msgTreeMap.isEmpty() && msg.getQueueOffset() == msgTreeMap.firstKey()) { try { //移除此消息 removeMessage(Collections.singletonList(msg)); } catch (Exception e) { log.error("send expired msg exception", e); } } } finally { this.lockTreeMap.writeLock().unlock(); } } catch (InterruptedException e) { log.error("getExpiredMsg exception", e); } } catch (Exception e) { log.error("send expired msg exception", e); } } }
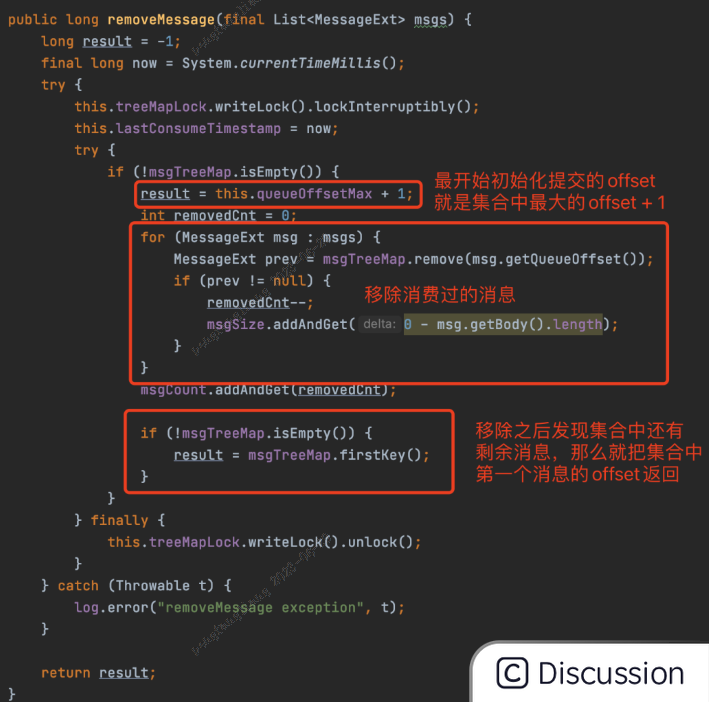
这么做的主要原因就是保证消息1和消息2至少被消费一次。
因为一旦提交了消息5对应的offset,如果消费者重启了,下次消费就会接着从消息5的后面开始消费,而对于消息1和消息2来说,并不知道有没有被消费成功,就有可能出现消息丢失的情况。
所以,一旦集合中最前面的消息长时间处理,那么就会导致后面被消费的消息进度无法提交。
为了解决这个问题,RocketMQ引入了定时清理的机制:
**1.调用sendMessageBack定时将阻塞的消息重发回重试topic
2.清理长时间消费的消息,这样消费进度就可以提交了。

该方法有些难理解,重对于每次消费成功,从pq移除该消息,如果pq还有消息(多个消费线程消费同一个ProcessQueue.msgTreeMap集合上保存的消息),那么返回最小的offset,如果pq上没有待消费的消息了,则返回ProcessQueue.queueOffsetMax(该属性保存的是一次拉取到的消息中的max offset),这样既避免了消息遗漏的情况,最终又保存到了消费最大offset的情况。
因此完美解决了 对于并发消费,消费msg1,msg2,msg3,它们的offset依次是增加的,在消费成功后,msg3先被消费完,继而持久化保存offset的时候还是保存的msg1的offset,而非msg3.offset,这样避免了消费时候消息遗漏问题,但是会导致有重复消费的可能,当然rmq并不保证重复消费,由业务保证。
拉取消息消息重复★
如果本地的偏移量大于服务器的偏移量
boolean brokerBusy = offset < pullRequest.getNextOffset();
重新设置本地的偏移量为从broker拉取的服务器偏移量 这里也会重复消费吧
幂等
总得来说,RocketMQ中还是存在很多种导致消息重读消费的情况,并且官方也说了,只是在大多数情况下消息不会重复
所以如果你的业务场景中需要保证消息不能重复消费,那么就需要根据业务场景合理的设计幂等技术方案。
消费幂等
消息队列 RocketMQ 消费者在接收到消息以后,有必要根据业务上的唯一 Key 对消息做幂等处理的必要性。
消费幂等的必要性
在互联网应用中,尤其在网络不稳定的情况下,消息队列 RocketMQ 的消息有可能会出现重复,这个重复简单可以概括为以下情况:
生产者重发导致相同,发送时消息重复
当一条消息已被成功发送到MQ服务端并完成持久化,此时MQ出现了网络闪断或者客户端宕机,导致MQ服务端对生产者客户端应答失败。 如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
投递时消息重复
消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。 为了保证消息至少被消费一次,消息队列 RocketMQ 的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
上面两条是RocketMQ本身存在的MessageID相同的问题,之前也有人说通过业务key来保证消息是不重复的。
负载均衡时消息重复(包括但不限于网络抖动、Broker 重启以及订阅方应用重启)
当消息队列 RocketMQ 的 Broker 或客户端重启、扩容或缩容时,会触发 Rebalance,此时消费者可能会收到重复消息。
处理方式
因为 Message ID 有可能出现冲突(重复)的情况,所以真正安全的幂等处理,不建议以 Message ID 作为处理依据。 最好的方式是以业务唯一标识作为幂等处理的关键依据,而业务的唯一标识可以通过消息 Key 进行设置:
Message message = new Message(); message.setKey("ORDERID_100"); SendResult sendResult = producer.send(message);
订阅方收到消息时可以根据消息的 Key 进行幂等处理:
consumer.subscribe("ons_test", "*", new MessageListener() { public Action consume(Message message, ConsumeContext context) { String key = message.getKey() // 根据业务唯一标识的 key 做幂等处理 } });
总结
RocketMQ是分布式环境,消息系统自身解决消费重复问题,需要消费者端进行大量的确认。一方面这种确认会导致大量消息阻塞,另一方面分布式环节下需要网络确认,消息在网络传递过程中具有不可靠性。 事实证明消息的传递具有不可靠性;网络不可靠性,只要通过网络传输的消息都具有网络不可靠性;或者说系统受到黑客的恶意篡改,导致的消息完全一致等等。只要消息经过传递,希望在传递层保证消息都无法100%保证消息的可靠性。传递过程无法确保消息不重复,那么消息源也就不需要关注了,因为即使消息源确保唯一,传递过程中还是会产生重复消息。
消息流从五个环节从消息源,消息发送,消息传递,消息消费都无法保证消息不重复,那么我们能做的只有在消息持久化环节保证消息不重复。其实所有的保证消息不重复的策略都需要一个消息持久化的位置供消息重复验证,然而不巧的是除非和消息最本源的位置做验证,其他环节的验证都具有不可靠性。
消息持久层做消息唯一性的策略:
1.持久化过程中业务唯一标识验证,每个消息具有业务唯一标识,在消息最终持久化之前通过验证唯一性标识保证消息的唯一性。消息持久化位置如果出现同样的消息,系统就不做处理,期间无任何传递过程,保证消息的唯一性。
2.使用过程中业务唯一标识验证,使用过程中如果出现同样的消息,系统进行相应的异常处理。
消息的生命周期中只有在消息产生源和消息持久源才是具有意义的,在过程中不必太苛求。
参考:https://blog.csdn.net/mlydaemon/article/details/105893361 参考:https://www.elecfans.com/d/2074549.html