机器学习优化器和SGD和SGDM实验对比
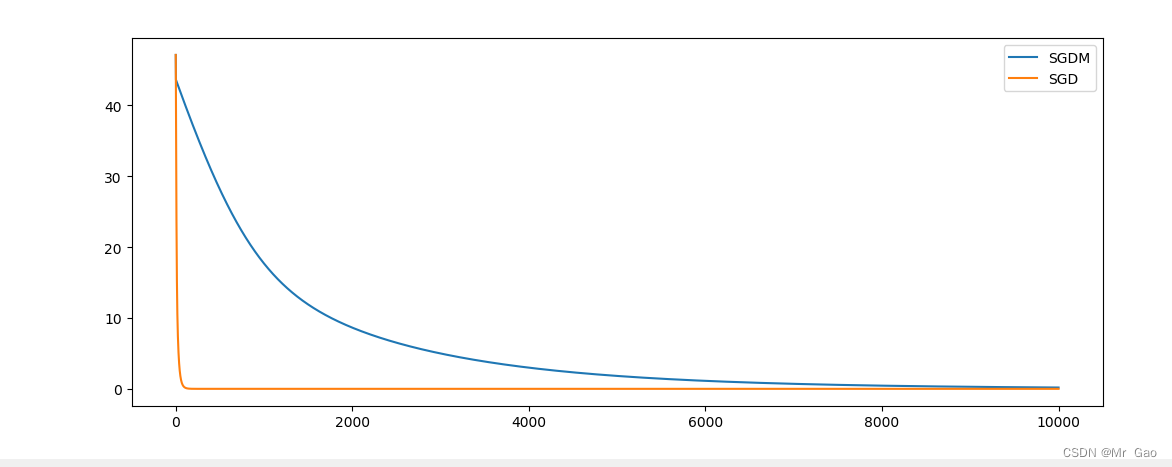
博主最近在学习优化器,于是呢,就做了一个SGD和SGDM的实验对比,可谓是不做不知道,一做吓一跳,这两个算法最终对结果的影响还是挺大的,在实验中SGDM明星要比SGD效果好太多了,SGD很容易陷入局部最优,而且非常容易发生梯度爆炸的情况,而SGDM做的实验当中还未出现这些情况。
在这次实验中博主发现了很多很多的特点对于SGDM和SGDM,下面博主列出这次实验的收获。
(1)SGDM相比SGD当拥有同样的学习率,SGDM更不容易发生梯度爆炸,SGD对于学习率的要求很高,大了,就会梯度爆炸,小了迭代特别慢。
(2)在本次此实验中,我们可以发现,小批量梯度下降比单个样本进行梯度下降区别极为大,单个样本做梯度下降时,特别容易发生梯度爆炸,模型不易收敛。
(3)SGDM相比SGD,loss下降曲线更加平稳,也不易陷入局部最优,但是他的训练较慢,可以说是非常慢了。
(4)超参数的设置对于这两个模型的影响都是很大的,要小心处理。
(5)数据集对于模型迭代也有很大影响,注意要对数据集进行适当的处理。
(6)随着训练轮次的增多,SGDM相比SGD更有可能取得更好的效果。
下面让我们看一看代码:
#coding=gbk
import torch
from torch.autograd import Variable
from torch.utils import data
import matplotlib.pyplot as plt
X =torch.randn(100,4)
w=torch.tensor([1,2,3,4])
Y =torch.matmul(X, w.type(dtype=torch.float)) + torch.normal(0, 0.1, (100, ))+6.5
print(Y)
Y=Y.reshape((-1, 1))
#将X,Y转成200 batch大小,1维度的数据
def loss_function(w,x,y,choice,b):
if choice==1:
return torch.abs(torch.sum(w@x)+b-y)
else:
# print("fdasf:",torch.sum(w@x),y)
# print(torch.pow(torch.sum(w@x)-y,2))
return torch.pow(torch.sum(w@x)-y+b,2)
index=0
batch=32
learning_rating=0.03
def SGDM(batch,step,beta,grad_s,grad_b_s):
if step==0:
grad=Variable(torch.tensor([0.0]),requires_grad=True)
grad_b=Variable(torch.tensor([0.0]),requires_grad=True)
loss=Variable(torch.tensor([0.0]),requires_grad=True)
for j in range(batch):
try:
# print(w,X[index],Y[index],b,)
# print(loss_function(w,X[index],Y[index],b,2))
# print(torch.sum(w@X[index]),Y[index])
grad=(torch.sum(w@X[index])-Y[index]+b)*(-1)*X[index]+grad
grad_b=(torch.sum(w@X[index])-Y[index]+b)*(-1)+grad_b
# print(loss_function(w,X[index],Y[index],2,b))
loss=loss_function(w,X[index],Y[index],2,b)+loss
index=index+1
except:
index=0
return grad/batch,loss/batch,grad_b/batch
else:
grad=Variable(torch.tensor([0.0]),requires_grad=True)
grad_b=Variable(torch.tensor([0.0]),requires_grad=True)
loss=Variable(torch.tensor([0.0]),requires_grad=True)
for j in range(batch):
try:
# print(w,X[index],Y[index],b,)
# print(loss_function(w,X[index],Y[index],b,2))
# print(torch.sum(w@X[index]),Y[index])
grad=(torch.sum(w@X[index])-Y[index]+b)*(-1)*X[index]+grad
grad_b=(torch.sum(w@X[index])-Y[index]+b)*(-1)+grad_b
loss=loss_function(w,X[index],Y[index],2,b)+loss
index=index+1
except:
index=0
return (beta*grad_s+(1-beta)*grad)/batch,loss/batch,(beta*grad_b_s+(1-beta)*grad_b)/batch
def train(n):
loss_list=[]
setp=0
global grad,grad_b
grad=0
grad_b=0
while n:
n=n-1
grad,loss,grad_b=SGDM(batch,setp,0.99,grad,grad_b)
setp=setp+1
# print(grad,loss,grad_b)
w.data=w.data+learning_rating*grad*w.data
b.data=b.data+learning_rating*grad_b
# print("b",b)
#print("grad_b",grad_b)
#print("w:",w)
#print("loss:",loss)
#print("b:",b)
loss_list.append(float(loss))
# b.data=b.data-(lear
# ning_rating*b.grad.data)
# print("b",b)
print("w:",w)
print("b:",b)
print("loss:",loss)
return loss_list
def SGD(batch):
grad=Variable(torch.tensor([0.0]),requires_grad=True)
grad_b=Variable(torch.tensor([0.0]),requires_grad=True)
loss=Variable(torch.tensor([0.0]),requires_grad=True)
for j in range(batch):
try:
# print(w,X[index],Y[index],b,)
# print(loss_function(w,X[index],Y[index],b,2))
# print(torch.sum(w@X[index]),Y[index])
grad=(torch.sum(w@X[index])-Y[index]+b)*(-1)*X[index]+grad
grad_b=(torch.sum(w@X[index])-Y[index]+b)*(-1)+grad_b
loss=loss_function(w,X[index],Y[index],2,b)+loss
index=index+1
except:
index=0
return grad/batch,loss/batch,grad_b/batch
def train_s(n):
loss_list=[]
while n:
if n//100==0:
print(n)
n=n-1
grad,loss,grad_b=SGD(batch)
# print(grad,loss,grad_b)
w.data=w.data+learning_rating*grad*w.data
b.data=b.data+learning_rating*grad_b
# print("b",b)
#print("w:",w)
#print("loss:",loss)
#print("b:",b)
# b.data=b.data-(learning_rating*b.grad.data)
# print("b",b)
loss_list.append(float(loss))
print("w:",w)
print("b:",b)
print("loss:",loss)
return loss_list
w=torch.tensor([1,1.0,1,1])
b=torch.tensor([1.0])
w=Variable(w,requires_grad=True)
b=Variable(b,requires_grad=True)
epoch=10000
epoch_list=list(range(1,epoch+1))
loss_list=train(epoch)
plt.plot(epoch_list,loss_list,label='SGDM')
#SGD
w=torch.tensor([1,1.0,1,1])
b=torch.tensor([1.0])
w=Variable(w,requires_grad=True)
b=Variable(b,requires_grad=True)
print(w)
epoch_list=list(range(1,epoch+1))
loss_list=train_s(epoch)
plt.plot(epoch_list,loss_list,label='SGD')
plt.legend()
plt.show()
下面是一张跑出的实验图,事实上,我做了很多很多的实验,这是一件十分有趣的事情,在实验中,你可以看到这些优化器的特点,这很有趣,当然前提是这个优化器是你自己完全编程写的。