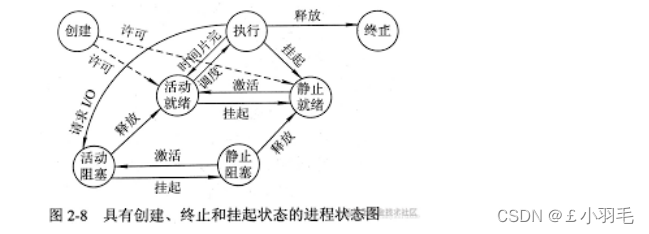
简介
ChatGLM2-6B 是清华大学开源的一款支持中英双语的对话语言模型。经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,具有62 亿参数的 ChatGLM2-6B 已经能生成相当符合人类偏好的回答。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
使用方式
硬件需求
| 量化等级 | 最低GPU(对话) | 最低GPU(微调) |
|---|---|---|
| FP16(标准) | 13GB | 14GB |
| INT8 | 8GB | 9GB |
| INT4 | 6GB | 7GB |
如果没有 GPU 硬件,也可以在 CPU 上进行对话,但是相应速度会更慢。需要大概 32GB 内存。
安装环境
下载仓库
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
创建虚拟环境
python -m venv venv
激活虚拟环境
- Windows 系统
venv\Script\activate
- macOS/Linux 系统
source venv/bin/activate
安装依赖
pip install -r requirements.txt -i https://pypi.douban.com/simple
加载模型
默认情况下,程序会自动下载模型。奈何模型太大,网络不好的情况下花费时间过长。建议提前下载,从本地加载模型。
- 代码地址
- 模型地址
将下载的 THUDM 文件夹放在 ChatGLM2-6B 文件夹下。文件清单如下所示:
ChatGLM2-6B
│
├── THUDM
│ ├── chatglm2-6b
│ │ ├── MODEL_LICENSE
│ │ ├── README.md
│ │ ├── config.json
│ │ ├── configuration_chatglm.py
│ │ ├── modeling_chatglm.py
│ │ ├── pytorch_model-00001-of-00007.bin
│ │ ├── pytorch_model-00002-of-00007.bin
│ │ ├── pytorch_model-00003-of-00007.bin
│ │ ├── pytorch_model-00004-of-00007.bin
│ │ ├── pytorch_model-00005-of-00007.bin
│ │ ├── pytorch_model-00006-of-00007.bin
│ │ ├── pytorch_model-00007-of-00007.bin
│ │ ├── pytorch_model.bin.index.json
│ │ ├── quantization.py
│ │ ├── tokenization_chatglm.py
│ │ ├── tokenizer.model
│ │ └── tokenizer_config.json
│ └── chatglm2-6b-int4
│ ├── MODEL_LICENSE
│ ├── README.md
│ ├── config.json
│ ├── configuration_chatglm.py
│ ├── modeling_chatglm.py
│ ├── pytorch_model.bin
│ ├── quantization.py
│ ├── tokenization_chatglm.py
│ ├── tokenizer.model
│ └── tokenizer_config.json
GPU/CPU部署
GPU部署
默认情况下,程序以基于GPU运行。
- 查看显卡信息
nvidia-smi

上图表示本机显卡的显存为8GB,最高支持CUDA的版本是11.2。
- 下载安装
cuda-toolkit工具
在 这里 选择不高于上述CUDA的版本。


按提示安装 cuda-toolkit 工具。
wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run
sudo sh cuda_11.2.0_460.27.04_linux.run
运行以下命令,查看 cuda 是否可用。
python -c "import torch; print(torch.cuda.is_available());"
返回 True 则表示可用。
在 api.py cli_demo.py web_demo.py web_demo.py 等脚本中,模型默认以 FP16 精度加载,运行模型需要大概 13GB 显存。命令如下:
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
如果 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
# 按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(4).cuda()
模型量化会带来一定的性能损失,经过测试,ChatGLM2-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
如果内存不足,可以直接加载量化后的模型:
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).cuda()
CPU部署
如果没有 GPU 硬件的话,也可以在 CPU 上进行对话,但是对话速度会很慢,需要32GB内存(量化模型需要5GB内存)。使用方法如下:
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
如果内存不足,可以直接加载量化后的模型:
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).float()
在 CPU 上运行量化后的模型,还需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 TDM-GCC 时勾选 openmp。在 MacOS 上请参考 这里。
运行程序
命令行
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。如下所示:

网页版A
python web_demo.py
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。如下所示:

网页版B
安装 streamlit_chat 模块。
pip install streamlit_chat -i https://pypi.douban.com/simple
运行网页。
streamlit run web_demo2.py
如下所示:

API部署
安装 fastapi uvicorn 模块。
pip install fastapi uvicorn -i https://pypi.douban.com/simple
运行API。
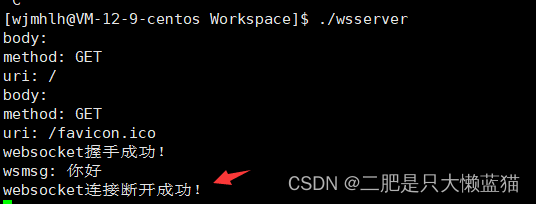
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用。
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
得到返回值为
{
"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。",
"history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],
"status":200,
"time":"2023-06-30 14:51:00"
}


![ELK报错no handler found for uri and method [PUT] 原因](https://img-blog.csdnimg.cn/91172b96c6514866828a3793aee47dcd.png)