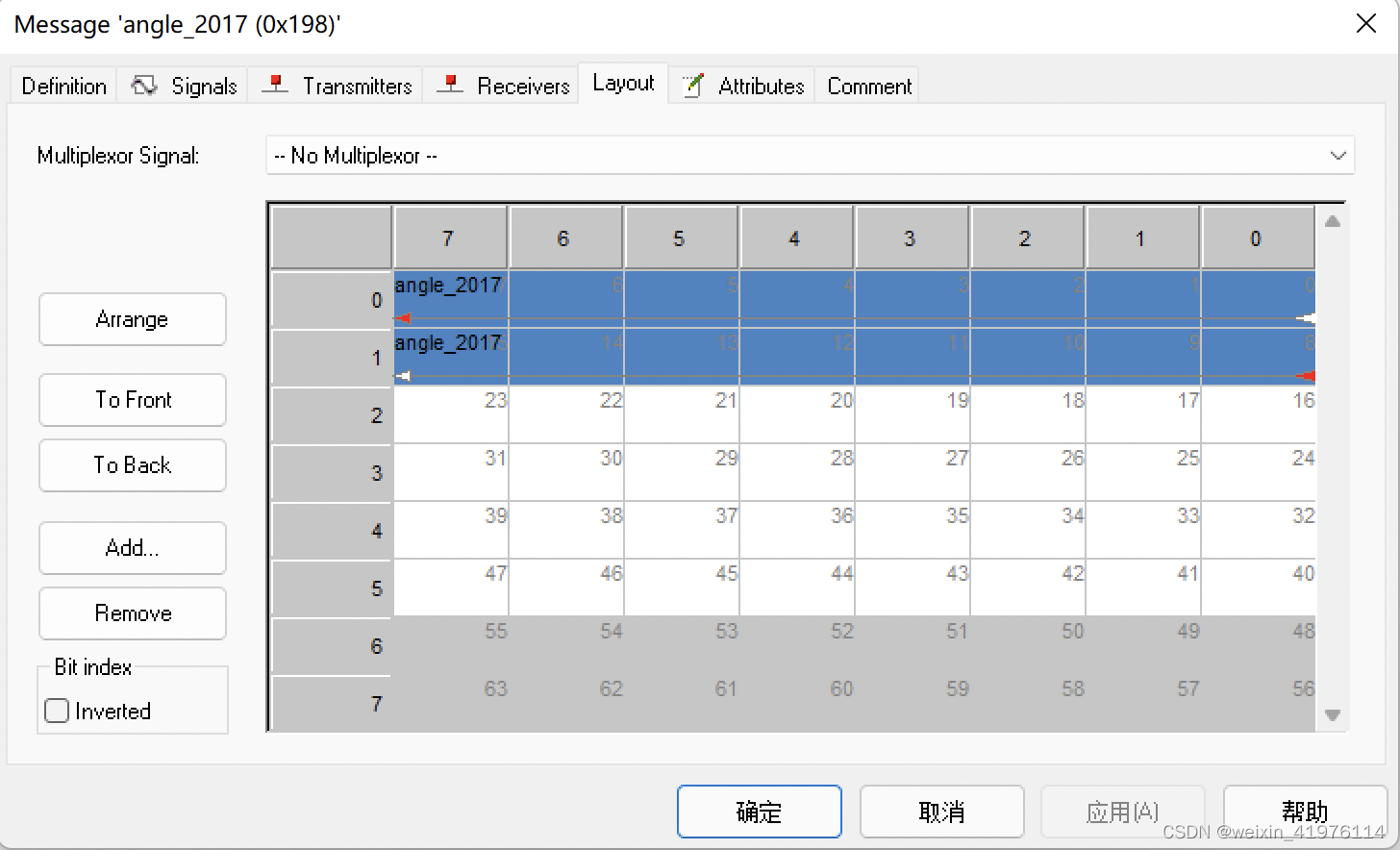
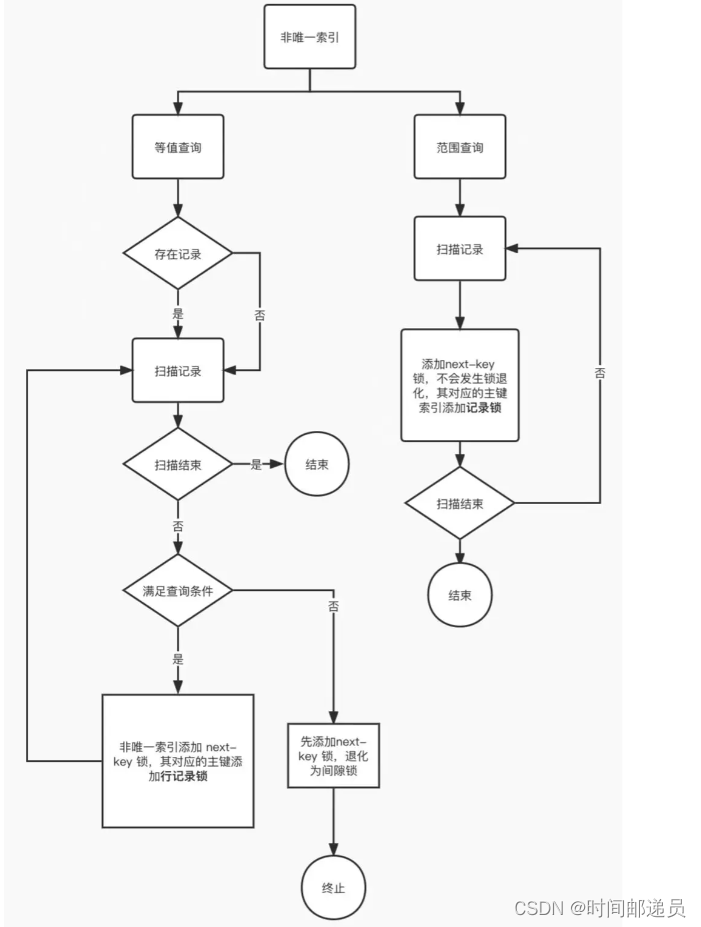
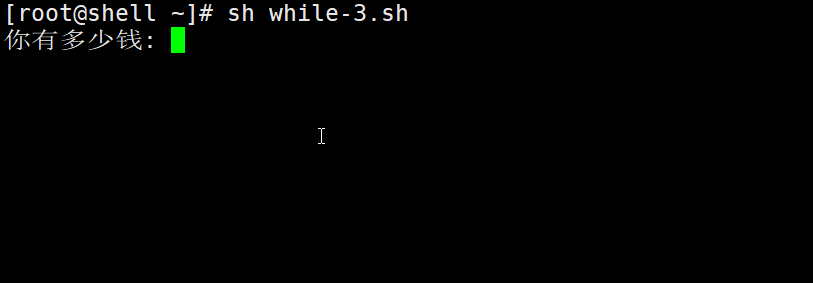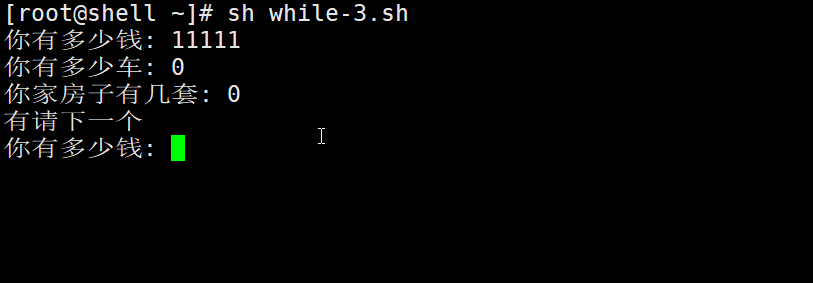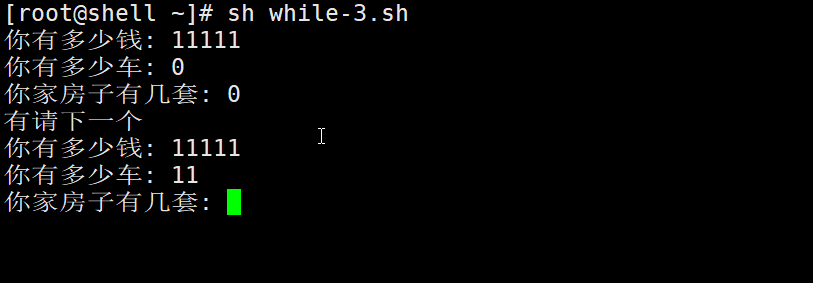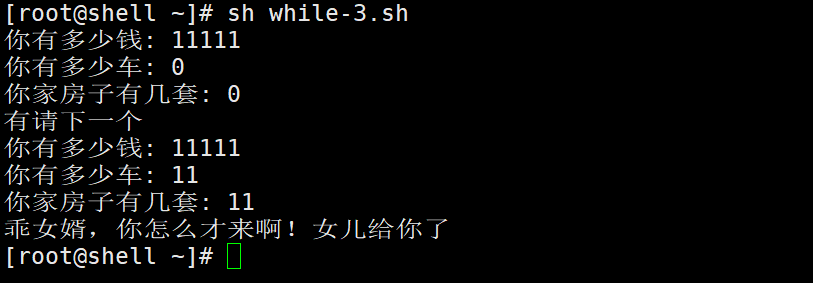
更新Block(bneck倒残差结构)
1.加入SE(自注意力模块squeeze-and-excite bottleneck)模块。当stride==1(高和宽是不会变化的)且inputc == outputc才有shortcut连接。
相反,我们将它们全部替换为扩展层中通道数量的1/4。我们发现,在参数数量适度增加的情况下,这样做可以提高准确性,并且没有明显的延迟成本。
2.更新了激活函数

NL:非线性激活函数
使用NAS搜索参数 (Neural Architecture Search)
重新设计耗时层结构 Redesigning Expensive Layers
 原始最后阶段和有效最后阶段的比较。这个更有效的最后阶段能够在不损失精度的情况下在网络末端丢弃三个昂贵的层。
原始最后阶段和有效最后阶段的比较。这个更有效的最后阶段能够在不损失精度的情况下在网络末端丢弃三个昂贵的层。
一旦通过架构搜索找到了模型,我们就会发现最后的一些层以及早期的一些层比其他层更昂贵。我们建议对架构进行一些修改,以减少这些慢层的延迟,同时保持准确性。这些修改超出了当前搜索空间的范围。
第一个修改重新设计了网络的最后几层如何交互,以便更有效地生成最终特征。基于Mo bileNetV2的反向瓶颈结构和变体的当前模型使用1x1卷积作为最终层,以便扩展到更高维度的特征空间。为了具有丰富的预测特征,该层非常重要。然而,这是以额外的延迟为代价的。
为了减少延迟并保留高维特性,我们将此层移过最终平均池。这最后一组特征现在以1x1空间分辨率而不是7x7空间分辨率计算。这种设计选择的结果是,在计算和延迟方面,特征的计算变得几乎免费。
1.减少第一个卷积层的卷积核的个数(32-16)
2.精简Last Stage