文章目录
- 一、索引
- 1.索引构成
- 2.如何查找
- 3.最左匹配原则
- 4.覆盖索引
- 5.减少冗余索引和重复索引
- 1.冗余索引
- 2.重复索引
- 6.索引适用情况和注意事项
- 1.适用情况
- 2.注意事项
- 二、Explain执行计划
- 1.Explain语句
- 三、隔离级别与MVCC
- 1.事前准备
- 2.四个事务并发的问题
- 1.脏写
- 2.脏读
- 3.不可重复读
- 4.幻读
- 3.MVCC原理
- 1.版本链
- 2.关于脏写
- 3.ReadView
- 判断方法
- 4.MVCC小结
- 四、锁
- 1.解决并发问题的两种方式
- 解决方案
- 1.MVCC进行控制
- 2.读写操作都加锁
- 2.一致性读
- 3.锁定读
- 1.共享锁和排他锁
- 2.锁定读
一、索引
1.索引构成
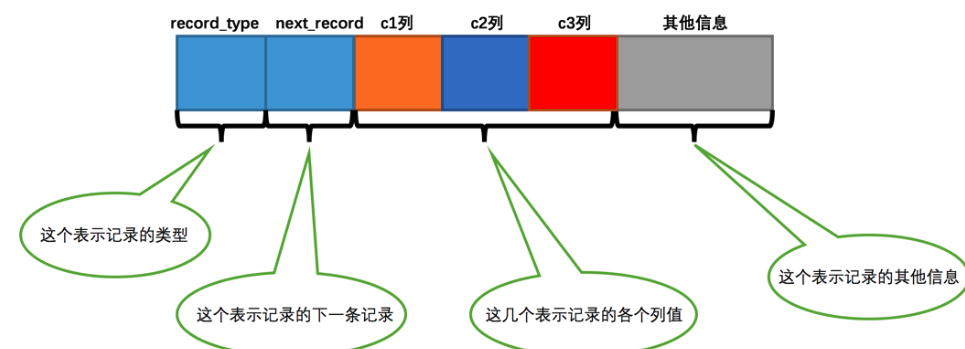
索引构成分为五部分
- record_type:类型,0,1,2,3分别代表普通记录,目录项纪录,最小纪录,最大纪录
- next_record:记录偏移量
- 列的值
- 其他信息
如图所示:
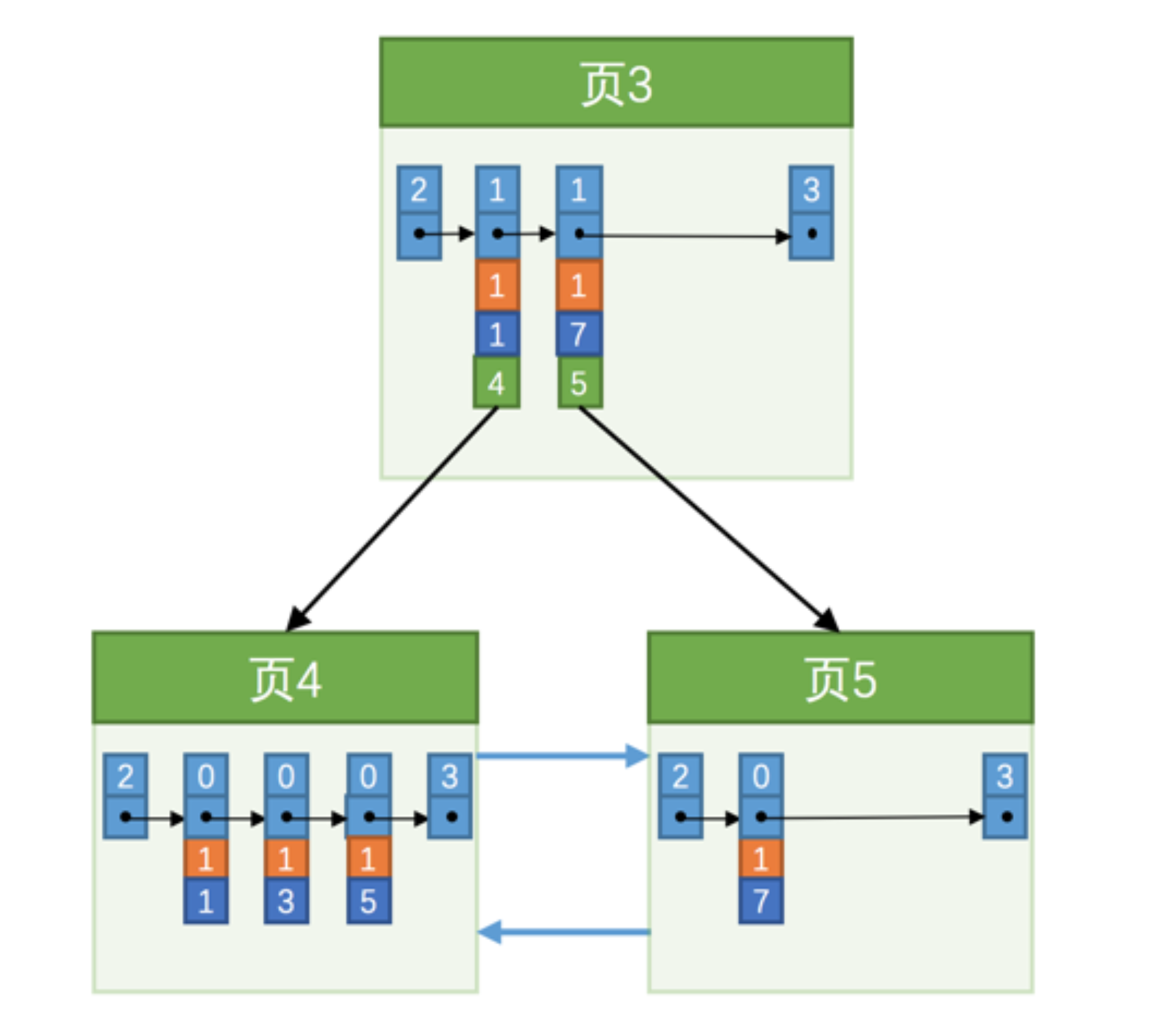
2.如何查找
1.先二分查找目录项,比如要查找的纪录是20,(那么这个纪录就在页9)
2.再二分查找这些纪录,进而找到对应的值

为了避免出现多个页列的名称一直,在插入的时候不知道新的数据出现在哪里,我们设置除了二级索引列新增了一个主键作为区别
3.最左匹配原则
比如我们建立复合索引(name,birth,phone),这个索引就是先按照name,再birth再phone
4.覆盖索引
查找的列中只包含索引列,防止回表查询
5.减少冗余索引和重复索引
1.冗余索引
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number),
KEY idx_name (name(10))
);
2.重复索引
CREATE TABLE repeat_index_demo (
c1 INT PRIMARY KEY,
c2 INT,
UNIQUE uidx_c1 (c1),
INDEX idx_c1 (c1)
);
6.索引适用情况和注意事项
1.适用情况
1.全值匹配
2.范围查询
3.精确查询某一行并范围查询另一行
4.模糊查询左边的列
5.用于排序
6.用于分组
2.注意事项
- 用于搜索,排序和分组创建索引
- 为列的基数大的创建索引
- 索引列的类型小
- 索引列如果在表达式单独出现可以创建索引(不要2* index<4这种)
- 避免
聚簇索引页分裂,尽量让索引auto_increment - 删除冗余和重复索引
- 使用覆盖索引
二、Explain执行计划
1.Explain语句

三、隔离级别与MVCC
1.事前准备
CREATE TABLE hero (
number INT,
name VARCHAR(100),
country varchar(100),
PRIMARY KEY (number)
) Engine=InnoDB CHARSET=utf8;
INSERT INTO hero VALUES(1,'刘备','蜀');
2.四个事务并发的问题
1.脏写
事务修改了另外一个事务未提交的数据
2.脏读
事务读到了另外一个事务未提交的数据
3.不可重复读
事务读到了另外一个已经提交的事务修改过的数据,并且其他事务对这个数据修改提交后,该事务都能取到最新的值
对于这个数据被删除被读到的情况也属于不可重复读
4.幻读
事务先根据条件查询出来一些纪录,然后其他事务新增了符合条件的纪录,原来的事务查询该条件,可以把新插入的纪录读出来
如果数据变少了,也就是删除这种情况不是幻读,幻读诗读到了之前没有的值

3.MVCC原理
1.版本链
对于InnoDB来说,聚簇索引需要两个必要隐藏列
trx_id:每次事务对聚簇索引纪录改动,都会被transaction_id赋值给trx_idroll_pointer:每次聚簇索引改动,都会被旧的版本写入undo日志,方便找到修改之前的信息
2.关于脏写

这种情况不就沦为了 脏写了吗,
InnoDB保证不会有脏写的情况发生,也就是trx100更新后,就会给这个事务加锁,知道这个事务commit,把锁释放之后才可以更新
3.ReadView
核心问题: 需要判断版本链的那些版本是当前事务可见的
m_ids:在生成ReadView中活跃读写事务的事务id列表
min_trx_id:生成ReadView中读写事务的最小事务id,也是m_ids的min_id
max_trx_id:生成ReadView时候系统分配下一个事务id
max_trx_id不是m_ids的最大值,比如我们有3个事务1,2,3,事务3已经提交,m_ids=[1,2],但是我们要分配的下一个id是max_trx_id=4
creator_trx_id: 生成这个事务的事务id
对事务改动
insert,delete,update才会分配事务id,只读事务的事务id默认为0
判断方法
1.trx_id = creator_trx_id,表示当前事务访问的是自己修改过的纪录可以正常访问
2.trx_id < min_trx_id, 生成该版本的事务在当前事务生成ReadView之前提交
3.trx_id > max_trx_id,生成该本本的事务在当前事务生成ReadView之后开启
4.min < trx_id < max,需要查看trx_id是否在m_ids列表中,不存在就提交了,可以访问,如果在,说明活跃不可访问
4.MVCC小结
READ COMMITTED和REPEATABLE READ在生成ReadView的时候是不一样的
READ COMMITED是在每次SELECT之前都生成一个ReadViewREPEATABLE READ是在第一次SELECT生成一个ReadView
四、锁
1.解决并发问题的两种方式
锁结构
trx_id:锁是哪个事务产生的is_waiting:当前事务是否在等待
事务T1改动了这个纪录,生成锁结构和这个关联,之前这个锁没有被占用,所以is_waiting=false,这个场景获取锁成功
1.读-读 : 读与读之间是不互斥的
2.写-写:写与写之间出现了脏写,这种情况需要加锁,进行锁的获取和释放
3.读-写,写-读:这种会出现脏读,不可重复读,幻读
解决方案
1.MVCC进行控制
我们通过
ReadView找到适应的版本(历史版本基于undo日志),只能看到在生成ReadView之前已经提交的事务,之后的更改是看不到的
2.读写操作都加锁
让
读-写也像写-写那样排队执行
2.一致性读
事务利用MVCC进行的读操作是一致性读,或者叫快照读
普通SELECT(plain SELECT)在READ COMMMITED,REPEATED READ情况下都算一致性读
3.锁定读
1.共享锁和排他锁
要想读-读不受限,又要让读-写,写-读,写-写相互阻塞,于是就设计了S锁和X锁
- 共享锁:
S锁,事务读取纪录之前,需要获取S锁 - 排他锁:
X锁,事务修改记录前,需要获取纪录的X锁
兼容性:

2.锁定读
我们想在读取纪录的时候获取X锁就需要用到锁定读
对读取纪录加S锁:
SELECT ... LOCK IN SHARE MODE
对读取纪录加X锁
SELECT ... FOR UPDATE