文章目录
- 摘要
- 下载chatglm-6b
- 下载模型文件
- 推理
- 代码调用
- 网页版的Demo
- 网页版的Demo2
- 命令行 Demo
- 部署
- API部署
- 低成本部署
- 模型量化
- CPU 部署
- Mac 部署
- 多卡部署
- 训练与微调
- 软件依赖
- 下载数据集
- 训练
- P-Tuning v2
- 评估P-Tuning v2训练的模型
- 部署P-Tuning v2训练的模型
- 量化
- 全参数Finetune
- 训练自己的数据集
- 对话数据集
- 优点与缺点
摘要
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
主页:https://huggingface.co/THUDM/chatglm-6b
gitcode链接:https://gitcode.net/mirrors/THUDM/chatglm-6b
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
模型连接:
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/
下载chatglm-6b
gitcode链接:https://gitcode.net/mirrors/THUDM/chatglm-6b
或者
github链接:https://github.com/THUDM/ChatGLM-6B
然后,进入根目录执行下面的命令:
pip install -r requirements.txt
pip install accelerate
pip install streamlit streamlit_chat
其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。
此外,如果需要在 cpu 上运行量化后的模型,还需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 TDM-GCC 时勾选 openmp。 Windows 测试环境 gcc 版本为 TDM-GCC 10.3.0, Linux 为 gcc 11.3.0。
下载模型文件
链接:https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/
这2个文件夹,分别存放16位、int4和int8的模型文件。在ChatGLM-6B中,新建THUDM文件夹。然后,将上面链接的文件夹下载下来,放到THUDM文件夹中,如下图:
我选用的是16位的模型文件,比较大!如果显存不足可以选用int8或者int4的。
推理
代码调用
新建’test.py`脚本,写入下面的代码:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
运行结果:
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
如果晚上睡不着,可以尝试以下方法:
1. 保持舒适的睡眠环境:确保卧室安静、黑暗、凉爽,并尽可能减少噪音和光线干扰。
2. 建立规律的睡眠时间:尽量在同一时间上床,保持规律的睡眠时间表,帮助身体建立睡眠节律。
3. 放松身心:在上床睡觉前,尝试进行一些放松的活动,如深呼吸、冥想、泡热水澡或听轻柔的音乐。
4. 避免刺激性物质:避免饮用咖啡、茶、可乐等含有咖啡因的饮料,以及食用辛辣、油腻、刺激性食物。
5. 避免在床上工作或娱乐:避免在床上工作或娱乐,尤其是在晚上。
6. 避免使用电子产品:避免在床上使用电子产品,如手机、电脑等,这些设备会刺激大脑,难以入睡。
如果以上方法不能帮助入睡,可以考虑咨询医生或睡眠专家,获取更专业的建议。
网页版的Demo
首先安装 Gradio:pip install gradio,然后运行仓库中的 web_demo.py:
python web_demo.py
如果想要部署到公网上,可以将最后一句的share改为True。
demo.queue().launch(share=True, inbrowser=True)
Could not create share link. Please check your internet connection or our status page: https://status.gradio.app
将最后一句改为:
demo.launch(server_name='0.0.0.0', share=True, enable_queue=True)

两个链接,上面的本地链接,下面的公网链接!点开链接,我们就可以测试了
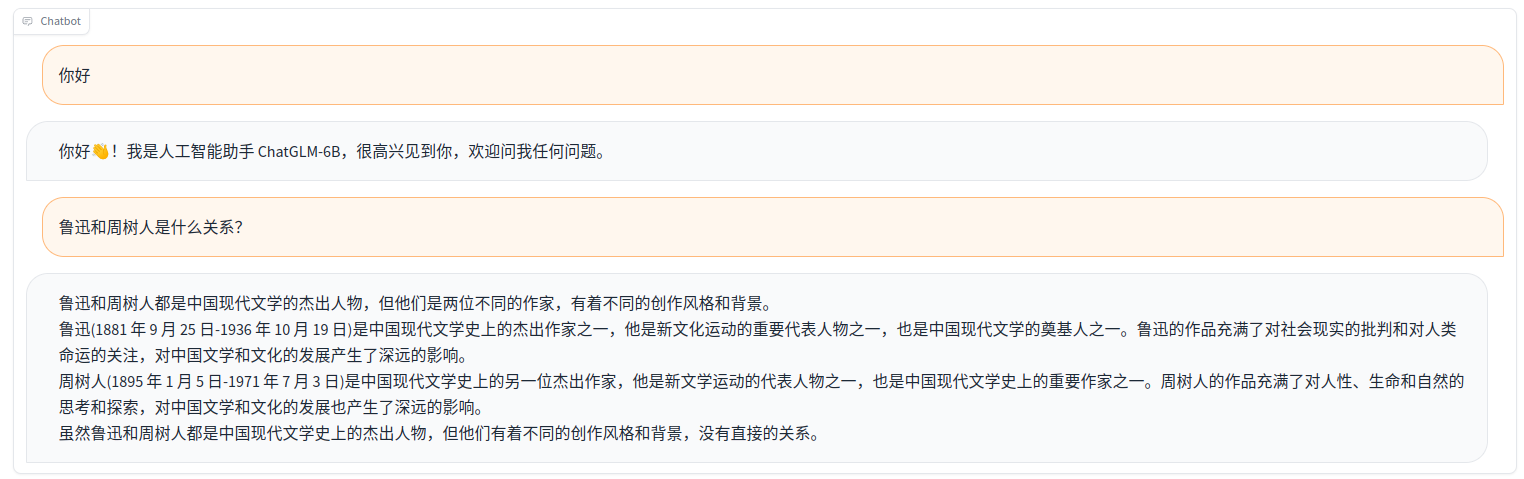
面对这道送命题,ChatGLM-6b差的离谱!
网页版的Demo2
streamlit run web_demo2.py
命令行 Demo
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TIxvCUAM-1687940667081)(resources/cli-demo.png)]
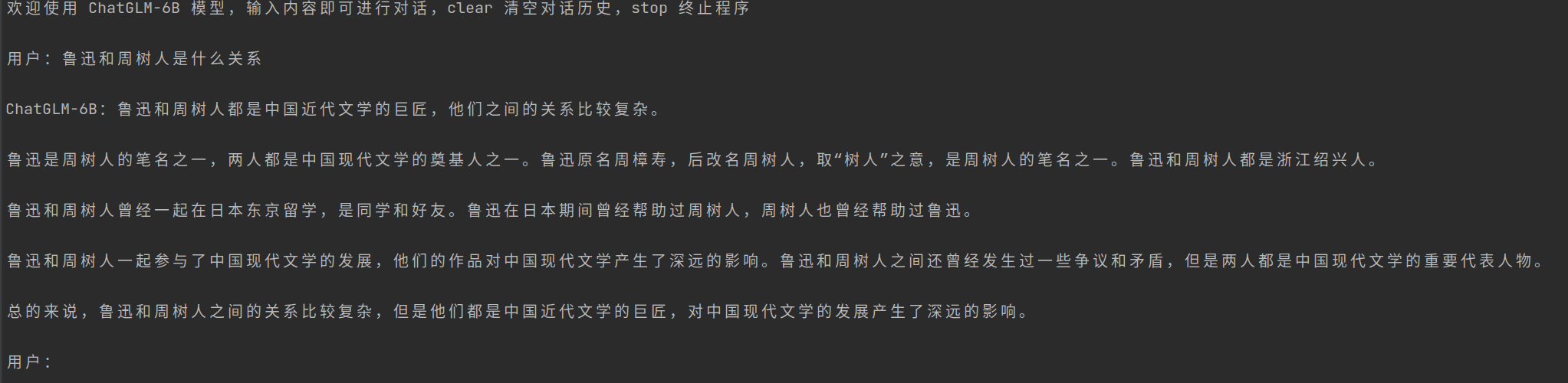
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
部署
API部署
首先需要安装额外的依赖 pip install fastapi uvicorn,然后运行仓库中的 api.py:
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
得到的返回值为
{
"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。",
"history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],
"status":200,
"time":"2023-03-23 21:38:40"
}
低成本部署
模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
# 按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).quantize(8).half().cuda()
进行 2 至 3 轮对话后,8-bit 量化下 GPU 显存占用约为 10GB,4-bit 量化下仅需 6GB 占用。随着对话轮数的增多,对应消耗显存也随之增长,由于采用了相对位置编码,理论上 ChatGLM-6B 支持无限长的 context-length,但总长度超过 2048(训练长度)后性能会逐渐下降。
模型量化会带来一定的性能损失,经过测试,ChatGLM-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
量化过程需要在内存中首先加载 FP16 格式的模型,消耗大概 13GB 的内存。如果你的内存不足的话,可以直接加载量化后的模型,INT4 量化后的模型仅需大概 5.2GB 的内存:
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
量化模型的参数文件也可以从https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/下载。
CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
如果你的内存不足,可以直接加载量化后的模型:
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()
如果遇到了报错 Could not find module 'nvcuda.dll' 或者 RuntimeError: Unknown platform: darwin (MacOS) ,请从本地加载模型
Mac 部署
对于搭载了 Apple Silicon 或者 AMD GPU 的Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM-6B。需要参考 Apple 的 官方说明 安装 PyTorch-Nightly(正确的版本号应该是2.1.0.dev2023xxxx,而不是2.0.0)。
目前在 MacOS 上只支持从本地加载模型。将代码中的模型加载改为从本地加载,并使用 mps 后端:
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).half().to('mps')
加载半精度的 ChatGLM-6B 模型需要大概 13GB 内存。内存较小的机器(比如 16GB 内存的 MacBook Pro),在空余内存不足的情况下会使用硬盘上的虚拟内存,导致推理速度严重变慢。此时可以使用量化后的模型如 chatglm-6b-int4。因为 GPU 上量化的 kernel 是使用 CUDA 编写的,因此无法在 MacOS 上使用,只能使用 CPU 进行推理。
# INT8 量化的模型将"THUDM/chatglm-6b-int4"改为"THUDM/chatglm-6b-int8"
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float()
为了充分使用 CPU 并行,还需要单独安装 OpenMP。
多卡部署
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 accelerate: pip install accelerate,然后通过如下方法加载模型:
from utils import load_model_on_gpus
model = load_model_on_gpus("THUDM/chatglm-6b", num_gpus=2)
即可将模型部署到两张 GPU 上进行推理。你可以将 num_gpus 改为你希望使用的 GPU 数。默认是均匀切分的,你也可以传入 device_map 参数来自己指定。
训练与微调
ChatGLM-6B实现了对于 ChatGLM-6B 模型基于 P-Tuning v2 的微调。P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
下面以 ADGEN (广告生成) 数据集为例介绍代码的使用方法。
软件依赖
运行微调需要4.27.1版本的transformers。除 ChatGLM-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets
下载数据集
ADGEN 数据集任务为根据输入(content)生成一段广告词(summary)。
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
从 Google Drive 或者 Tsinghua Cloud 下载处理好的 ADGEN 数据集,将解压后的 AdvertiseGen 目录放到本目录下。
训练
P-Tuning v2
运行以下指令进行训练:
bash train.sh
对train.sh作了修改,将Batch设置为16,显存占用在20G 左右。
PRE_SEQ_LEN=128
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path ../THUDM/chatglm-6b \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \

train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
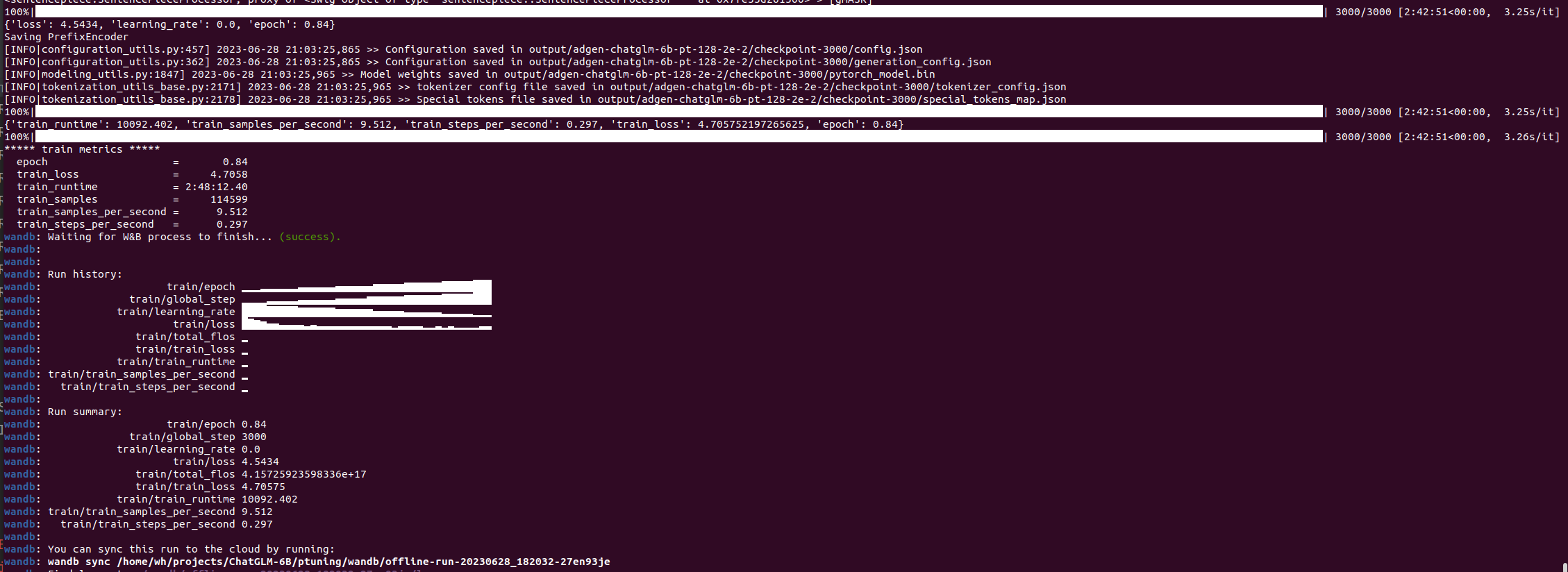
调整序列长度,修train.sh,代码如下:
PRE_SEQ_LEN=512
代价是显存增长明显。
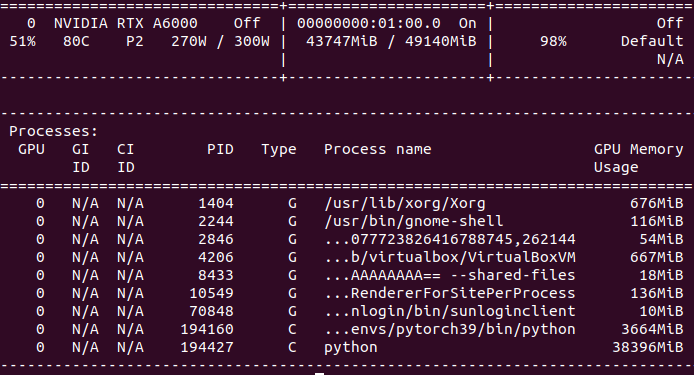
运行结果:
评估P-Tuning v2训练的模型
在 P-tuning v2 训练时模型只保存 PrefixEncoder 部分的参数,所以在推理时需要同时加载原 ChatGLM-6B 模型以及 PrefixEncoder 的权重,所以,还需要同时指定model_name_or_path和ptuning_checkpoint,修改evaluate.sh脚本,代码如下:
PRE_SEQ_LEN=128
CHECKPOINT=adgen-chatglm-6b-pt-128-2e-2
STEP=3000
CUDA_VISIBLE_DEVICES=0 python main.py \
--do_predict \
--validation_file AdvertiseGen/dev.json \
--test_file AdvertiseGen/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path ../THUDM/chatglm-6b \
--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN \
# --quantization_bit 4
预测结果保存在adgen-chatglm-6b-pt-128-2e-2\predict_results.json中。
{
"predict_bleu-4": 8.118742429906543,
"predict_rouge-1": 31.63312252336448,
"predict_rouge-2": 7.304219906542055,
"predict_rouge-l": 25.013636728971964,
"predict_runtime": 1440.6232,
"predict_samples": 1070,
"predict_samples_per_second": 0.743,
"predict_steps_per_second": 0.743
}
部署P-Tuning v2训练的模型
首先载入Tokenizer:
from transformers import AutoConfig, AutoModel, AutoTokenizer
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
- 如果需要加载的是新 Checkpoint(只包含 PrefixEncoder 参数):
config = AutoConfig.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True,config=config).half().cuda()
prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
model = model.eval()
注意你可能需要将 pre_seq_len 改成你训练时的实际值。如果你是本地加载模型]需要将 THUDM/chatglm-6b 改成本地的模型路径。
- 如果需要加载的是旧 Checkpoint(包含 ChatGLM-6B 以及 PrefixEncoder 参数),或者进行的是全参数微调,则直接加载整个 Checkpoint:
model = AutoModel.from_pretrained(model_args.model_name_or_path, config=config, trust_remote_code=True)
量化
可以直接使用:
# Comment out the following line if you don't use quantization
model = model.quantize(4)
model = model.half().cuda()
model.transformer.prefix_encoder.float()
model = model.eval()
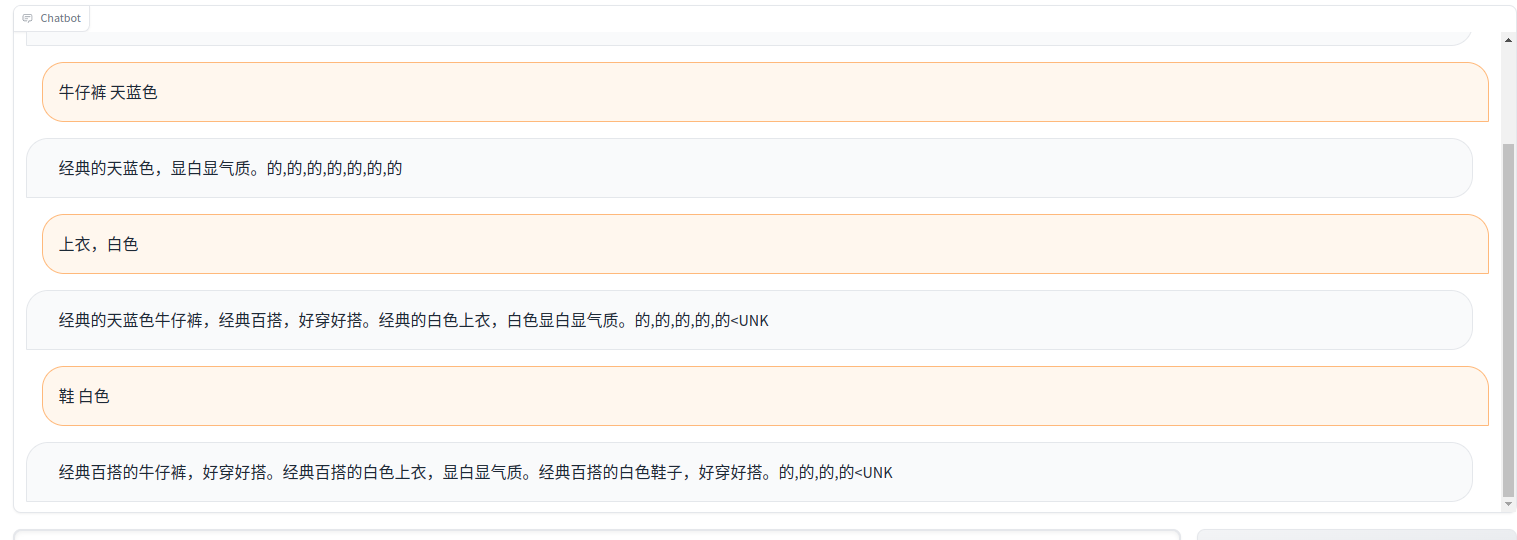
运行结果:
全参数Finetune
如果需要进行全参数的 Finetune,需要安装 Deepspeed,然后运行以下指令:
bash ds_train_finetune.sh
没有试,显存不够!!!!!!!!!!!!!!!!!!!!
训练自己的数据集
修改 train.sh 和 evaluate.sh 中的 train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将 prompt_column 和 response_column 改为 JSON 文件中输入文本和输出文本对应的 KEY。可能还需要增大 max_source_length 和 max_target_length 来匹配你自己的数据集中的最大输入输出长度。
对话数据集
如需要使用多轮对话数据对模型进行微调,可以提供聊天历史,例如以下是一个三轮对话的训练数据:
{"prompt": "长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "response": "用电脑能读数据流吗?水温多少", "history": []}
{"prompt": "95", "response": "上下水管温差怎么样啊?空气是不是都排干净了呢?", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"]]}
{"prompt": "是的。上下水管都好的", "response": "那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"], ["95", "上下水管温差怎么样啊?空气是不是都排干净了呢?"]]}
训练时需要指定 --history_column 为数据中聊天历史的 key(在此例子中是 history),将自动把聊天历史拼接。要注意超过输入长度 max_source_length 的内容会被截断。
可以参考以下指令:
bash train_chat.sh
https://blog.csdn.net/q116975174/article/details/130034839
优点与缺点
ChatGLM-6B 是一个具有62亿参数的中英双语语言模型。通过使用与 ChatGLM(chatglm.cn)相同的技术,ChatGLM-6B 初具中文问答和对话功能,并支持在单张 2080Ti 上进行推理使用。具体来说,ChatGLM-6B 有如下特点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
因此,ChatGLM-6B 具备了一定条件下较好的对话与问答能力。当然,ChatGLM-6B 也有相当多已知的局限和不足:
模型容量较小: 6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;她也不擅长逻辑类问题(如数学、编程)的解答。
- 可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
- 较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
- 英文能力不足:训练时使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示时,回复的质量可能不如中文指示的回复,甚至与中文指示下的回复矛盾。
- 易被误导:ChatGLM-6B 的“自我认知”可能存在问题,很容易被误导并产生错误的言论。例如当前版本模型在被误导的情况下,会在自我认知上发生偏差。即使该模型经过了1万亿标识符(token)左右的双语预训练,并且进行了指令微调和人类反馈强化学习(RLHF),但是因为模型容量较小,所以在某些指示下可能会产生有误导性的内容。
参考文章:
https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning