系列文章目录
Linux 内核设计与实现
深入理解 Linux 内核
Linux 设备驱动程序
Linux设备驱动开发详解
深入理解Linux虚拟内存管理
Linux 内核源代码情景分析(一)
Linux 内核源代码情景分析(二)
文章目录
- 系列文章目录
- 第 4 章 进程与进程调度
- 1、进程四要素
- (1)运行状态
- 2、进程三部曲:创建、执行与消亡
- 3、系统调用fork()、vfork()、与clone()
- (1)do_fork()
- (2)clone_flags
- (3)user_struct
- (4)exec_domain
- (5)get_pid
- To be continued
第 4 章 进程与进程调度
1、进程四要素
要给“进程”下一个确切的定义不是件容易的事。不过,一般来说 Linux 系统中的进程都具备下列诸要素:
- 有一段程序供其执行,就好像一场戏要有个剧本一样。这段程序不一定是进程所专有,可以与其他进程共用,就好像不同剧团的许多场演出可以共用一个剧本一样。
- 有起码的 “秘行财产” ,这就是进程专用的系统堆栈空间。
- 有 “户口 ” ,这就是在内核中的一个 task_struct 数据结构,操作系统教科书中常称为“进程控制块”。有了这个数据结构,进程才能成为内核调度的一个基本单位接受内核的调度。同时, 这个结构又是进程的“财产登记卡”,记录着进程所占用的各项资源。
- 有独立的存储空间,意味着拥行专有的用户空间;进一步,还意味着除前述的系统空间堆栈外还有其专用的用户空间堆栈。注意,系统空间是不能独立的,任何进程都不可能直接 (不通过系统调用) 改变系统空间的内容 (除其本身的系统空间堆栈以外) 。
这四条都是必要条件,缺了其中任何一条就不称其为“进程”。如果只具备了前面三条而缺第四条, 那就称为 “线程” 。特别地,如果完全没有用户空间,就称为“内核线程” (kernel thread) ;而如果共享用户空间则就称为 “用户线程” 。在不致引起混淆的场合,二者也都往往简称为“线程”。读者在第 2 章中看到过的 kswapd ,就是一个内核线程。读者要注意,不要把这里的“线程”与有些系统中在用户空间的同一进程内实现的 “线程” 相混淆。那种线程显然不拥有独立、专用的系统堆栈,也不作为一个调度单位直接受内核调度。而且,既然 Linux 内核提供了对线程的支持,一般也就没有必要再在进程内部,即用户空间中自行实现线程。
另一方面,进程与线程的区分也不是十分严格的,一般在讲到进程时常常也包括了线程。事实上, 在 Linux (以及Unix) 系统中,许多进程在“诞生”之初都与其父进程共用同一个存储空间,所以严格说来还是线程;但是子进程可以建立其自己的存储空间,并与父迸程分道扬镳,成为真止意义上的进程。再说,线程也有 “pid",也有 task_struct 结构,所以这两个词在使用中有时候并不严格加以区分, 要根据上下文理解其含意。
还有,在 Linux 系统中“进程” (process) 和“任务” (task) 是同一个意思,在内核的代码中也常常混用这两个名词和概念。例如,每一个进程都要有一个 task_struct 数据结构,而其号码却又是 pid; 唤醒一个睡眠进程的函数名为 wake_up_process() 。之所以有这样的情况是因为 Linux 源自 Unix 和 i386 系统结构,而 Unix 中的进程在 Intel 的技术资料中则称为“任务”(严格说来有点差别,但是对 Linux 和 Unix 的实现来说是一码事)。
Linux 系统运行时的第一个进程是在初始化阶段“捏造”出来的。而此后的进程或线程则都是由一个业已存在的进程像细胞分裂那样通过系统调用复制出来的,称为 “fork"(分叉)或“clone”(克隆)。
除上述最起码的“财产”,即 task_struct 数据结构和系统堆栈之外,一个进程还要有些附加的资源。 例如,上面说过,“独立”的存储空问意味着进程拥有用户空间,因此就要有用于虚存管理的 mm_struct 数据结构以及下属的 vm_area 数据结构,以及相应的页面目录项和页面表。但那些都是第二位的,从属于 task_struct 的资源,而 task_struct 数据结构则在这方面起着登记卡的作用。至于进程的具体实现, 则在相当程度上取决于宿主 CPU 的系统结构。
在转入详细介绍进程的各个要素之前,我们先讲一下 i386 系统结构所提供的进程管理机制以及 Linux 内核对这种机制的特殊运用和处理。读者可以结合第2章中的有关内容阅读。
Intel 在 i386 系统结构的设计中考虑到了进程(任务)的管理和调度,并从硬件上支持任务间的切换。为此目的,Intel 在 i386 系统结构中增设了另一种新的段,叫做“任务状态段” TSS。 一个 TSS 虽说像代码段、数据段等一样,也是一个"段”,实际上却只是一个 104 字节的数据结构、或曰控制块, 用以记录一个任务的关键性的状态信息,包括:
- 任务切换前夕(也就是切入点上)该任务各通用寄存器的内容。
- 任务切换前夕(切入点上)该任务各个段寄存器(包括ES、CS、SS、DS、FS和ES)的内容。
- 任务切换前夕(切入点上)该任务EFLAGS寄存器的内容。
- 任务切换前夕(切入点上)该任务指令地址寄存器EIP的内容。
- 指向前一个任务的 TSS 结构的段选择码。当前任务执行 IRET 指令时,就返回到由这个段选择码所指的(TSS所代表的)任务(返回地址则由堆栈决定)。
- 该任务的 LDT 段选择码,它指向任务的 LDT。
- 控制寄存器 CR3 的内容,它指向任务的页面目录。
- 二个堆栈指针,分别为当任务运行于0级、1级和2级时的堆栈指针,包括堆栈段寄存器SS0、 SS1和SS2,以及ESP0、ESP1和ESP2的内容。注意,在CPU中只有一个SS和一个ESP 寄存器,但是 CPU 在进入新的运行级别时会自动从当前任务的TSS中装入相应SS和ESP 的内容,实现堆栈的切换。
- 一个用于程序跟踪的标志位 T 。当T标志位为 1 时,CPU就会在切入该进程时产生一次 debug 异常,这样就可以在 debug 异常的服务程序中安排所需的操作,如加以记录、显示、等等。
- 在一个 TSS 段中,除了基本的104字节的TSS结构以外,还可以有一些附加的信息。其中之一是表示I/O权限的位图。i386系统结构允许 I/O 指令在比0级为低的状态下执行,也就是说可以将外设驱动实现于一个既非内核(0级)也非用户(3级)的空间中,这个位图就是用于这个目的。另一个是“中断重定向位图”,用于 vm86 模式。
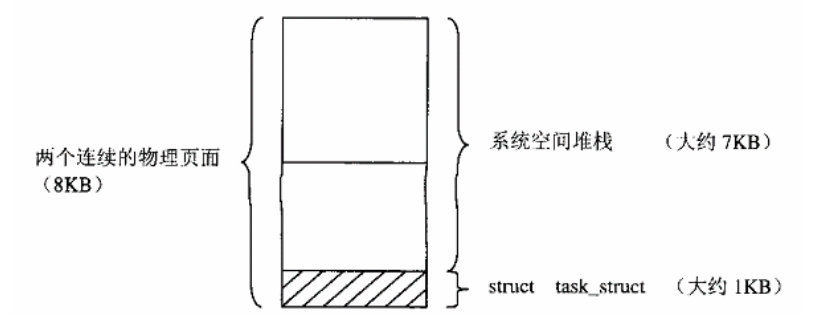
前面讲过,每个进程都有一个 task_struct 数据结构和一片用作系统空间堆栈的存储空间。这二者缺一不可,又有紧密的联系,所以在物理存储空间中也连在一起。内核在为每个进程分配一个 task_struct 结构时,实际上分配两个连续的物理页面 (共8192字节) 。这两个页面的底部用作进程的 task_struct 结构,而在结构的上面就用作进程的系统空间堆栈。下图为进程系统堆栈示意图:
(1)运行状态
// include/linux/sched.h
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_ZOMBIE 4
#define TASK_STOPPED 8
状态 TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE 均表示进程处于速眠状态。但是, TASK_UNINTERRUPTIBLE 表示进程处于 “深度睡眠” 而不受 “信号” ( signal,也称 “软中断” ) 的打扰,而 TASK_INTERRUPTIBLE 则可以因 “信号” 的到来而被唤醒。内核中提供了不同的函数,让一个进程进入不同深度的睡眠或将进程从睡眠中唤醒。具体地说,函数 sleep_on() 和 wake_up() 用于深度睡眠,而 interruptible_sleep_on() 和wake_up_interruptible() 则用于浅度睡眠。深度睡眠一般只用于临界区和关键性的部位,而 “可中断” 的睡眠那就是通用的了。特别,当进程在 “阻塞性”(blocking) 的系统调用中等将某一事件发生时,应该进入“可中断” 睡眠间不应深度睡眠。例如,当进程等待操作人员按某个键的时候,就不应该进入深度睡眠,否则就不能对别的事件作出反应,别的进程就不能通过发一个信号来 “杀” 掉这个进程了。还应该注意,这里的 INTERRUPTIBLE 或 UNINTERRUPTIBLE 跟 “中断” 毫无关系,而只是说睡眠能否因其他事件而中断,即唤醒。不过,所谓其他事件主要是 “信号”,而信号的概念实际上与中断的概念是相同的,所以这里所谓 INTERRUPTIBLE 也是指这种 “软中断” 而言。
TASK_RUNNING 状态并不是表示一个进程止在执行中,或者说这个进程就是 “当前进程”,而是表示这个进程可以被调度执行而成为当前进程。当进程处于这样的可执行(或就绪)状态时,内核就将该进程的 task_struct 结构通过其队列头 run_list (见309行)挂入一个 “运行队列”。
TASK_ZOMBIE 状态表示进程已经 “去世”(exit)而 “户口” 尚未注销。
TASK_STOPPED 主要用于调试目的。进程接收到一个 SIGSTOP 信号后就将运行状态改成 TASK_STOPPED 而进入“挂起”状态,然后在接收到一个 SIGCONT 信号时又恢复继续运行。
2、进程三部曲:创建、执行与消亡
就像世上万物都有产生、发展与消亡的过程一样,每个进程也有被创建、执行某段程序以及最后消亡的过程。在 Linux 系统中,第一个进程是系统固有的、与生俱来的或者说是由内核的设计者安排好了的。内核在引导并完成了基本的初始化以后,就有了系统的第一进程(实际上是内核线程)。除此之外,所有其他的进程和内核线程都这个原始进程或其子孙进程所创建,都是这个原始进程的 “后代” 。在 Linux 系统中,一个新的进程一定要由一个已经存在的进程“复制”出来,而不是“创造”出来(而所谓“创建”实际就是复制)。所以,Linux 系统(Unix也一样)并不向用户(即进程)提供类似这样的系统调用:
int creat_proc(int (*fn)(void*), void *arg, unsigned long options);
可是在很多操作系统(包括一些Unix的变种)中都采用了 “一揽子” 的方法。它“创造”出一个进程,并使该进程从函数指针 fn 所指的地方开始执行。根据不同的情况和设计,参数 fn 也可以换成一个可执行程序的文件名。这里所谓“创造”,包括为进程分配所需的资源、包括属于最低限度的 task_struct 数据结构和系统空间堆栈,并初始化这些资源;还要设置其系统空间堆栈,使得这个新进程看起来就好像是一个本来就已经存在而正在唾眠的进程。当这个进程被调度运行的时候,其“返回地址”,也就是“恢复”运行时的下一条指令,则就在 fn 所指的地方。这个“子进程” 生下来时两手空空,却可以完全独立,并不与其父进程共享资源。
但是,Linux (以及Unix)采用的方法却不同。
Linux 将进程的创建与目标程序的执行分成两步。第一步是从已经存在的“父进程”中像细胞分裂一样地复制出一个 “子进程” 。这里所谓像“细胞分裂一样”,只是打个比方,实际上,复制出来的子进程有自己的 task_struct 结构和系统空间堆栈,但与父进程共享其他所有的资源。例如,要是父进程打开了五个文件,那么子进程也有五个打开的文件,而且这些文件的当前读写指针也停在相同的地方。 所以,这一步所做的是“复制”。Linux 为此提供了两个系统调用,一个是 fork(),另一个是 clone() 。 两者的区别在于 fork() 是全部复制,父进程所有的资源全都通过数据结构的复制“遗传”给步进程。 而 clone() 则可以将资源有选择地复制给厂进程,而没有复制的数据结构则通过指针的复制让子进程共享。在极端的情况下,一个进程可以 clone() 出一个线程。所以,系统调用 fork() 是无参数的,而 clone() 则带有参数。读者也许已经意识到,fork() 其实比clone() 更接近本来意义上的“克隆”。确实是这样, 原因在于 fork() 从 Unix 的初期即已存在,那时候“克隆”这个词还不像现在这么流行,而既然业已存在,就不宜更改了。否则,也许应该互换一下名字。后来,又增设了一个系统调用 vfork() ,也不带参数,但是除 task_struct 结构和系统空间堆栈以外的资源全都通过数据结构指针的复制“遗传”,所以 vfork() 出来的是线程而不是进程。读者将会看到,vfork() 主要是出于效率的考虑而设计并提供的。
第二步是目标程序的执行。一般来说,创建一个新的进程是因为有不同的目标程序要让新的程序去执行 (但也不一定),所以,复制完成以后,子进程通常要与父进程分道扬镳,走自己的路。Linux 为此提供了一个系统调用 execve(),让一个进程执行以文件形式存在的一个可执行程序的映象。
读者也许要问:这两种方案到底哪一种好?应该说是各有利弊。但是更应该说,Linux从Unix继承下来的这种分两步走,并且在第一步中采取复制方式的方案,利远大于弊。从效率的角度看,分两步走很行好处。所谓复制,只是进程的基本资源的复制,如 task_struct 数据结构、系统空间堆栈、页面表等等,对父进程的代码及全局变量则并不需要复制,而只是通过只读访问的形式实现共享,仅在需要写的时候才通过 copy_on_write 的手段为所涉及的页面建立个新的副本。所以,总的来说复制的代价是很低的,但是通过复制而继承下来的资源则往往对子进程很有用。读者以后会看到,在计算机网络的实现中,以及在 client/server 系统中的 server 一方的实现中,fork() 或 clone() 常常是最自然、最有效、最适宜的手段。笔者有时候简直怀疑,到底足先有 fork() 还是先有 client/server,因为 fork() 似乎就是专门为此而设计的。更重要的好处是,这样有利于父、子进程间通过 pipe 来建立起一种简单有效的进程间通信管道,并且从而产生了操作系统的用户界面即 shell 的 “管道” 机制。这一点,对于 Unix 的发展和推广应用,对于Unix程序设计环境的形成,对于Unix程序设计风格的形成,都有着非常深远的影响。可以说,这是一项天才的发明,它在很大程度上改变了操作系统的发展方向。
当然,从另一角度,也就是从程序设计界面的角度来看,则“一揽子”的方案更为简洁。不过 fork() 加 execve() 的方案也并不复杂很多。进一步说,这也像练武或演戏一样有个固定的“招式”,一一掌握了以后就不觉得复杂,也很少变化了。再说,如果有必要也可以通过程序库提供一个 “一揽子” 的库函数,将这两步包装在一起。
创建了子进程以后,父进程有二个选择。第一是继续走自己的路,与父进程分道扬镳。只是如果子进程先于父进程“去世”,则由内核给父进程发一个报丧的信号。第二是停下来,也就是进入睡眠状态,等待了一进程完成其使命而最终去世,然后父进程再继续运行。Linux为此提供了两个系统调用, wait4() 和 wait3()。两个系统调用基本相同,wait4() 等行某个特定的子进程去世,而 wait3() 则等待任何一个子进程去世。第三个选择是“自行退出历史舞台”,结束自己的生命。Linux 为此设置了一个系统调用 exit() 。这里的第三个选择其实不过是第一个选择的一种特例,所以从本质上说是两种选择:一种是父进程不受阻的 (non_blocking) 方式,也称为“异步”的方式;另一种是父进程受阻的 (blocking) 方式,或者也称为 “同步” 的方式。
3、系统调用fork()、vfork()、与clone()
前面已经简要地介绍过 fork() 与 clone() 二者的作用和区别。这里先来看一下二者在程序设计接口上的不同:
#include <unistd.h>
pid_t fork(void);
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
系统调用 __clone() 的主要用途是创建一个线程,这个线程可以是内核线程,也可以是用户线程。 创建用户空间线程时,可以给定子线程用户空间堆栈的位置,还可以指定子进程运行的起点。同时, 也可以用 __clone() 创建进程,有选择地复制父进程的资源。而 fork() ,则是全面地复制。还有一个系统调用 vfork() ,其作用也是创建一个线程,但主要只是作为创建进程的中间步骤,目的在于提高创建时的效率,减少系统开销,其程序设计接口则与fork相同。
这几个系统调用的代码都在 arch/i386/kernel/process.c 中:
// arch/i386/kernel/process.c
asmlinkage int sys_fork(struct pt_regs regs)
{
return do_fork(SIGCHLD, regs.esp, ®s, 0);
}
asmlinkage int sys_clone(struct pt_regs regs)
{
unsigned long clone_flags;
unsigned long newsp;
clone_flags = regs.ebx;
newsp = regs.ecx;
if (!newsp)
newsp = regs.esp;
return do_fork(clone_flags, newsp, ®s, 0);
}
/*
* This is trivial, and on the face of it looks like it
* could equally well be done in user mode.
*
* Not so, for quite unobvious reasons - register pressure.
* In user mode vfork() cannot have a stack frame, and if
* done by calling the "clone()" system call directly, you
* do not have enough call-clobbered registers to hold all
* the information you need.
*/
asmlinkage int sys_vfork(struct pt_regs regs)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs.esp, ®s, 0);
}
可见,二个系统调用的实现都是通过 do_fork() 来完成的,不同的只是对 do_fork() 的调用参数。关于这些参数所起的作用,读了 do_fork() 的代码以后就会清楚。注意 sys_clone() 中的regs.ecx,就是调用 __clone() 时的参数 child_stack,读者如果还不清楚,可以回到第3章“系统调用” 节顺着代码再走一遍。调用 __clone() 时可以为子进程设置一个独立的用户空间堆栈 (在同一个用户空间中),如果 child_stack 为 0,就表示使用父进程的用户空间堆栈。这三个系统调用的主体部分 do_fork() 是在 kernel/fork.c 中定义的。这个函数比较大,计我们逐段往下看:
(1)do_fork()
// kernel/fork.c
/*
* Ok, this is the main fork-routine. It copies the system process
* information (task[nr]) and sets up the necessary registers. It also
* copies the data segment in its entirety. The "stack_start" and
* "stack_top" arguments are simply passed along to the platform
* specific copy_thread() routine. Most platforms ignore stack_top.
* For an example that's using stack_top, see
* arch/ia64/kernel/process.c.
*/
int do_fork(unsigned long clone_flags, unsigned long stack_start,
struct pt_regs *regs, unsigned long stack_size)
{
int retval = -ENOMEM;
struct task_struct *p;
// 第560行的宏操作DECLARE_MUTEX_LOCKED()定义和创建了一个用于进程间互斥和同步的信
// 号量,其定义和实现见第6章“进程间通信”。
DECLARE_MUTEX_LOCKED(sem);
// 参数 clone_flags 由两部分组成,其最低的字行为信号类型,用以规定子进程去世时应该向父进程
// 发出的信号。我们也经看到,对于fork()和vfork()这个信号就是SIGCHLD,而对__clone()则该位段
// 可由调用者决定。第二部分是一些表示资源和特性的标志位,这些标志位是在
// include/linux/sched.h 中定义的:
// 对于fork(),这一部分为全0,表现对有关的资源都要复制而不是通过指针共享。向对vfbrk(),
// 则为 CLONE_VFORK | CLONE_VM ,表示父、子进程共用(用户)虚存区间,并且当子进程释放其虚
// 存区间时要唤醒父进程。至于__clone(),则这一部分完全由调用者设定而作为参数传递下来。其中标
// 志位CLONE_PID有特殊的作用,当这个标志位为1时,父、子进程(线程)共用同一个进程号,也
// 就是说,子进程虽然有其自己的task_struct数据结构,却使用父进程的pid。但是,只有0号进程,也
// 就是系统中的原始进程(实际上是线程),才允许这样来调用__clone(),所以564行对此加以检查。
if (clone_flags & CLONE_PID) {
/* This is only allowed from the boot up thread */
if (current->pid)
return -EPERM;
}
current->vfork_sem = &sem;
// 接着,通过alloc_task_struct()为子进程分配两个连续的物理页而,低端用作子进程的task_struct
// 结构,高端则用作其系统空间堆栈.
p = alloc_task_struct();
if (!p)
goto fork_out;
// 注意574行的赋值为整个数据结构的赋值。这样,父进程的整个 task_struct 就被复制到了子进程
// 的数据结构中。经编译以后,这样的赋值是用memcpyS实现的,所以效率很高。
*p = *current;
retval = -EAGAIN;
// 在task_struct结构中有个指针user,用来指向一个user_struct结构。一个用户常常有许多个进程,
// 所以有关用户的一些信息并不专属于某一个进程。这样,属于同一用户的进程就可以通过指针user共
// 享这些信息。显然,每个用户有且只有一个user_struct结构。结构中有个计数器count,对属于该用户
// 的进程数量计数。可想而知,内核线程并不属于某个用户,所以其task_struct中的user指针为0。这个
// 数据结构的定义在include/lmux/sched.h中:
//
// 各进程的 task_struct 结构中还有个数组 rlim,对该进程占用各种资源的数量作出限制,而
// rlim[RLIMIT_NPROC] 就规定了该进程所属的用户可以拥有的进程数量。所以,如果当前进程是
// 一个用户进程,并且该用户拥有的进程数量己经达到了规定的限制值,就再不允许它 fork()
// 了。
if (atomic_read(&p->user->processes) >= p->rlim[RLIMIT_NPROC].rlim_cur)
goto bad_fork_free;
atomic_inc(&p->user->__count);
atomic_inc(&p->user->processes);
/*
* Counter increases are protected by
* the kernel lock so nr_threads can't
* increase under us (but it may decrease).
*/
// 那么,对于不属于任何用户的内核线程怎么办呢? 587行中的两个计数器就是为进程的总量而设的。
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
// 一个进程除了属于某一个用户之外,还属于某个“执行域”。总的来说,Linux是Unix的一个变种,
// 并且符合POSIX的规定。但是,有很多版本的操作系统同样是Unix变种,同样符合POSIX规定,互
// 相之间在实现细节上却仍然有明显的不同。例如,AT&T的Sys V和BSD4.2就有相当的不同,而Sun
// 的Solaris又有区别,这就形成了不同的执行域。如果一个进程所执行的程序是为Solaris开发的,那么
// 这个进程就属于Solaris执行域PER_SOLARIS。当然,在Linux上运行的绝大多数程序都属于Linux
// 执行域。在task_struct结构中有一个指针exec_domain,可以指向一个exec_domain数据结构。
// 那是在 include/linux/personality.h 中定义的
get_exec_domain(p->exec_domain);
// 同样的道理,每个进程所执行的程序属于某种可执行映象格式,如a.out格式、elf格式、甚至java
// 虚拟机格式。对这些不同格式的支持通常是通过动态安装的驱动模块来实现的。所以task_struct结构
// 中还有一个指向 linux_binfmt 数据结构的指针binfmt , 而 do_fork()中593行的
// __MOD_INC_USE_COUNT() 就是对有关模块的使用计数器进行操作。
if (p->binfmt && p->binfmt->module)
__MOD_INC_USE_COUNT(p->binfmt->module);
p->did_exec = 0;
p->swappable = 0;
// 为什么要在597行把状态设成TASK_UNINTERRUPTIBLE呢?这是因为在 get_pid()中产生一个
// 新pid的操作必须是独占的,当前进程可能会因为一时进不了临界区而只好暂时进入睡眠状态等待,
// 所以才事先把状态设成 UNINTERRUPTIBLE。
p->state = TASK_UNINTERRUPTIBLE;
// 函数 copy_flags() 将参数clone_flags中的标志位略加补充和变换,然后写入p->flags,
// 这个函数的代码也在fork.c中。读者可以自己阅读。
copy_flags(clone_flags, p);
// 至于600行的 get_pid(),则根据clone_flags中标志位CLONE_PID的值,或返回父进程(当前进
// 程)的pid,或返回一个新的pid放在了进程的task_struct中。函数get_pid()的代码也在fork.c 中
p->pid = get_pid(clone_flags);
p->run_list.next = NULL;
p->run_list.prev = NULL;
if ((clone_flags & CLONE_VFORK) || !(clone_flags & CLONE_PARENT)) {
p->p_opptr = current;
if (!(p->ptrace & PT_PTRACED))
p->p_pptr = current;
}
p->p_cptr = NULL;
// 我们在前一节中提到过 wait4()和wait3(), 一个进程可以停下来等待其子进程完成使命。为此,在
// task_struct 中设置了一个队列头部 wait_chldexit,前面在复制task_struct结构时把这也照抄了
// 过来,而子进程此时尚未“出生”,当然谈不上子进程的等待队列,所以要在611行中加以初始化。
init_waitqueue_head(&p->wait_chldexit);
p->vfork_sem = NULL;
spin_lock_init(&p->alloc_lock);
// 类似地,对各种信息量也要加以初始化。这里615和616行是对子进程的待处理信号队列以及有
// 关结构成分的初始化。对这些与信号有关的结构成分我们将在“进程间通信”的信号一节中详细介绍。
// 接下来是对 task_struct 结构中各种计时变量的初始化,我们将在“进程调度” 一节中介绍这些变量。
// 在这里我们不关心对多处理器SMP结构的特殊考虑,所以也跳过627一637行。
p->sigpending = 0;
init_sigpending(&p->pending);
p->it_real_value = p->it_virt_value = p->it_prof_value = 0;
p->it_real_incr = p->it_virt_incr = p->it_prof_incr = 0;
init_timer(&p->real_timer);
p->real_timer.data = (unsigned long) p;
p->leader = 0; /* session leadership doesn't inherit */
p->tty_old_pgrp = 0;
p->times.tms_utime = p->times.tms_stime = 0;
p->times.tms_cutime = p->times.tms_cstime = 0;
#ifdef CONFIG_SMP
{
int i;
p->has_cpu = 0;
p->processor = current->processor;
/* ?? should we just memset this ?? */
for(i = 0; i < smp_num_cpus; i++)
p->per_cpu_utime[i] = p->per_cpu_stime[i] = 0;
spin_lock_init(&p->sigmask_lock);
}
#endif
p->lock_depth = -1; /* -1 = no lock */
// 最后,task_struct 结构中的 start_time 表示进程创建的时间,向全局变量jiffies的数值就是以时钟
// 中断周期为单位的从系统初始化开始至此时的时间。
// 至此,对 task_struct 数据结构的复制与初始化就基本完成了。下面就轮到其他的资源了:
p->start_time = jiffies;
retval = -ENOMEM;
/* copy all the process information */
// 函数copy_files()有条件地复制已打开文件的控制结构,这种复制只有在clone_flags中
// CLONE_FILES 标志位为 0 时才真正进行,否则就只是共享父进程的已打开文件。当一个进程有己打开
// 文件时,task_struct 结构中的指针files指向一个files_struct数据结构,否则为0。
// 所有与终端设备tty相联系的用户进程的头三个文件,即stdin、stdout、及stderr,都是预先打开的,
// 所以指针一般不会是 0。数据结构 files_struct 是在include/linux/sched.h中定义的
//(详见“文件系统”一章),copy_files() 的代码则还是在fork.c中:
if (copy_files(clone_flags, p))
goto bad_fork_cleanup;
if (copy_fs(clone_flags, p))
goto bad_fork_cleanup_files;
if (copy_sighand(clone_flags, p))
goto bad_fork_cleanup_fs;
if (copy_mm(clone_flags, p))
goto bad_fork_cleanup_sighand;
retval = copy_thread(0, clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_sighand;
p->semundo = NULL;
/* Our parent execution domain becomes current domain
These must match for thread signalling to apply */
p->parent_exec_id = p->self_exec_id;
/* ok, now we should be set up.. */
p->swappable = 1;
p->exit_signal = clone_flags & CSIGNAL;
p->pdeath_signal = 0;
/*
* "share" dynamic priority between parent and child, thus the
* total amount of dynamic priorities in the system doesnt change,
* more scheduling fairness. This is only important in the first
* timeslice, on the long run the scheduling behaviour is unchanged.
*/
p->counter = (current->counter + 1) >> 1;
current->counter >>= 1;
if (!current->counter)
current->need_resched = 1;
/*
* Ok, add it to the run-queues and make it
* visible to the rest of the system.
*
* Let it rip!
*/
retval = p->pid;
p->tgid = retval;
INIT_LIST_HEAD(&p->thread_group);
write_lock_irq(&tasklist_lock);
if (clone_flags & CLONE_THREAD) {
p->tgid = current->tgid;
list_add(&p->thread_group, ¤t->thread_group);
}
SET_LINKS(p);
hash_pid(p);
nr_threads++;
write_unlock_irq(&tasklist_lock);
if (p->ptrace & PT_PTRACED)
send_sig(SIGSTOP, p, 1);
wake_up_process(p); /* do this last */
++total_forks;
fork_out:
if ((clone_flags & CLONE_VFORK) && (retval > 0))
down(&sem);
return retval;
bad_fork_cleanup_sighand:
exit_sighand(p);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup:
put_exec_domain(p->exec_domain);
if (p->binfmt && p->binfmt->module)
__MOD_DEC_USE_COUNT(p->binfmt->module);
bad_fork_cleanup_count:
atomic_dec(&p->user->processes);
free_uid(p->user);
bad_fork_free:
free_task_struct(p);
goto fork_out;
}
(2)clone_flags
// include/linux/sched.h
/*
* cloning flags:
*/
#define CSIGNAL 0x000000ff /* signal mask to be sent at exit */
#define CLONE_VM 0x00000100 /* set if VM shared between processes */
#define CLONE_FS 0x00000200 /* set if fs info shared between processes */
#define CLONE_FILES 0x00000400 /* set if open files shared between processes */
#define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */
#define CLONE_PID 0x00001000 /* set if pid shared */
#define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */
#define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release */
#define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */
#define CLONE_THREAD 0x00010000 /* Same thread group? */
#define CLONE_SIGNAL (CLONE_SIGHAND | CLONE_THREAD)
(3)user_struct
// include/linux/sched.h
/*
* Some day this will be a full-fledged user tracking system..
*/
struct user_struct {
atomic_t __count; /* reference count */
atomic_t processes; /* How many processes does this user have? */
atomic_t files; /* How many open files does this user have? */
/* Hash table maintenance information */
struct user_struct *next, **pprev;
uid_t uid;
};
熟悉Unix内核的读者要注意,不要把Unix的进程控制结构中的 user 区与这里的 user_struct 结构相混淆,二者是截然不同的概念。在 kernel/user.c 中还定义了一个 user_struct 结构指针的数组 uidhash_table:
// kernel/user.c
#define UIDHASH_BITS 8
#define UIDHASH_SZ (1 << UIDHASH_BITS)
static struct user_struct *uidhash_table[UIDHASH_SZ];
这是一个杂凑(hash)表。对用户名施以杂凑运算,就可以计算出一个下标而找到该用户的 user_struct 结构。
(4)exec_domain
// include/linux/personality.h
/* Description of an execution domain - personality range supported,
* lcall7 syscall handler, start up / shut down functions etc.
* N.B. The name and lcall7 handler must be where they are since the
* offset of the handler is hard coded in kernel/sys_call.S.
*/
struct exec_domain {
const char *name;
lcall7_func handler;
unsigned char pers_low, pers_high;
unsigned long * signal_map;
unsigned long * signal_invmap;
struct module * module;
struct exec_domain *next;
};
函数指针 handler,用于通过调用门实现系统调用,我们并不关心。字节 pers_low 为某种域的代码, 有 PER_LINUX、PER_SVR4、PER_BSD 和 PER_SOLARIS 等等。
我们在这里主要关心的结构成分是 module,这是指向某个 module 数据结构的指针。读者在有关文件系统和设备驱动的章节中将会看到,在 Linux 系统中设备驱动程序可以设计并实现成 “动态安装模块” module,使其在运行时动态地安装和拆除。这些“动态安装模块”与运行中的进程的执行域有密切的关系。例如,一个属于 Solaris 执行域的进程算很可能要用到专门为 Solaris 设置的一些模块,只要还有一个这样的进程在运行,这些为 Solaris 所需的模块就不能拆除。所以,在描述每个一安装模块的数据结构中都有一个计数器,表明有几个进程需要使用这个模块。因此,do_fork() 中通过590行的 get_exec_domain() 递增具体模块的数据结构中的计数器 (定义在include/linux/personality.h 中)。
// include/linux/personality.h
#define get_exec_domain(it) \
if (it && it->module) __MOD_INC_USE_COUNT(it->module);
(5)get_pid
// kernel/fork.c
static int get_pid(unsigned long flags)
{
static int next_safe = PID_MAX;
struct task_struct *p;
if (flags & CLONE_PID)
return current->pid;
spin_lock(&lastpid_lock);
if((++last_pid) & 0xffff8000) {
last_pid = 300; /* Skip daemons etc. */
goto inside;
}
if(last_pid >= next_safe) {
inside:
next_safe = PID_MAX;
read_lock(&tasklist_lock);
repeat:
for_each_task(p) {
if(p->pid == last_pid ||
p->pgrp == last_pid ||
p->session == last_pid) {
if(++last_pid >= next_safe) {
if(last_pid & 0xffff8000)
last_pid = 300;
next_safe = PID_MAX;
}
goto repeat;
}
if(p->pid > last_pid && next_safe > p->pid)
next_safe = p->pid;
if(p->pgrp > last_pid && next_safe > p->pgrp)
next_safe = p->pgrp;
if(p->session > last_pid && next_safe > p->session)
next_safe = p->session;
}
read_unlock(&tasklist_lock);
}
spin_unlock(&lastpid_lock);
return last_pid;
}
这里的常数 PID_MAX 定义为 0x8000。可见,进程号的最大值是 0x7fff,即 32767。进程号 0~299 是为系统进程 (包括内核线程) 保留的,主要用于各种 “保护神” 进程。以上这段代码的逻辑并不复杂,我们就不多加解释了。
To be continued
⇐ ⇒ ⇔ ⇆ ⇒ ⟺
①②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳㉑㉒㉓㉔㉕㉖㉗㉘㉙㉚㉛㉜㉝㉞㉟㊱㊲㊳㊴㊵㊶㊷㊸㊹㊺㊻㊼㊽㊾㊿
⑴⑵⑶⑷⑸⑹⑺⑻⑼⑽⑿⒀⒁⒂⒃⒄⒅⒆⒇
➊➋➌➍➎➏➐➑➒➓⓫⓬⓭⓮⓯⓰⓱⓲⓳⓴
⒜⒝⒞⒟⒠⒡⒢⒣⒤⒥⒦⒧⒨⒩⒪⒫⒬⒭⒮⒯⒰⒱⒲⒳⒴⒵
ⓐⓑⓒⓓⓔⓕⓖⓗⓘⓙⓚⓛⓜⓝⓞⓟⓠⓡⓢⓣⓤⓥⓦⓧⓨⓩ
ⒶⒷⒸⒹⒺⒻⒼⒽⒾⒿⓀⓁⓂⓃⓄⓅⓆⓇⓈⓉⓊⓋⓌⓍⓎⓏ
🅐🅑🅒🅓🅔🅕🅖🅗🅘🅙🅚🅛🅜🅝🅞🅟🅠🅡🅢🅣🅤🅥🅦🅧🅨🅩
123
y = x 2 + z 3 y = x^2 + z_3 y=x2+z3
y = x 2 + z 3 + a b + b a y = x^2 + z_3 + \frac {a}{b} + \sqrt[a]{b} y=x2+z3+ba+ab
y = x 2 + z 3 (1) y = x^2 + z^3 \tag{1} y=x2+z3(1)