目录
- ColorCamera节点
- EdgeDetector节点
- FeatureTracker 节点
- ImageManip节点
- IMU 节点
- MobileNetDetectionNetwork节点
- MobileNetSpatialDetectionNetwork节点
- MonoCamera节点
- NeuralNetwork节点
- ObjectTracker节点
- Script节点
- SpatialLocationCalculator节点
- SPIIn节点
- SPIOut节点
- StereoDepth节点
- SystemLogger节点
- VideoEncoder节点
- Warp节点
- XLinkIn节点
- XLinkOut节点
- YoloDetectionNetwork节点
- YoloSpatialDetectionNetwork节点
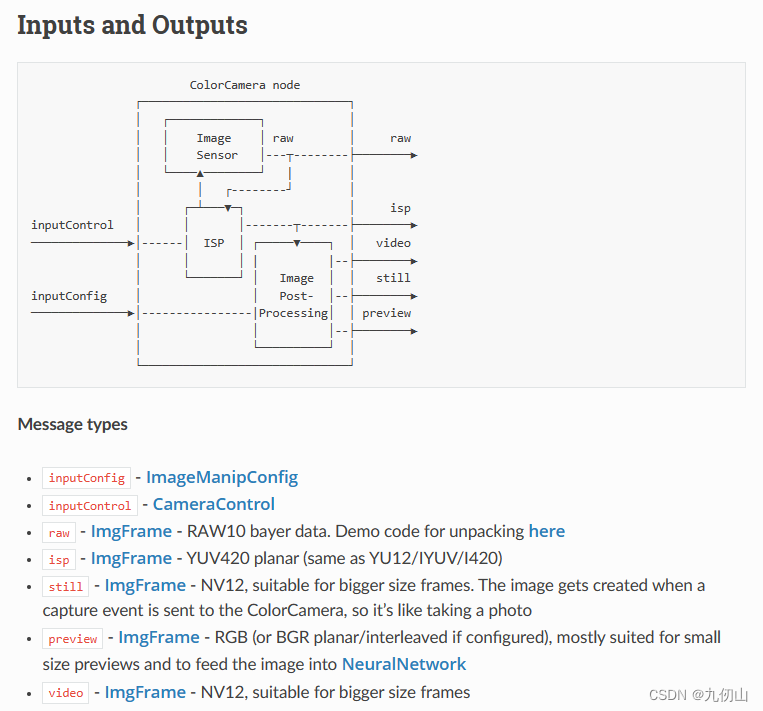
ColorCamera节点
ColorCamera节点是DepthAI API中用于处理彩色相机输入的节点。它用于捕获彩色图像和元数据,并提供对触发、自动曝光、自动白平衡等相机功能的控制。
在DepthAI中,ColorCamera节点可以与其他节点(如ImageManip节点和NeuralNetwork节点)连接,用于实时处理彩色图像,并在计算视觉或深度信息时提供输入。
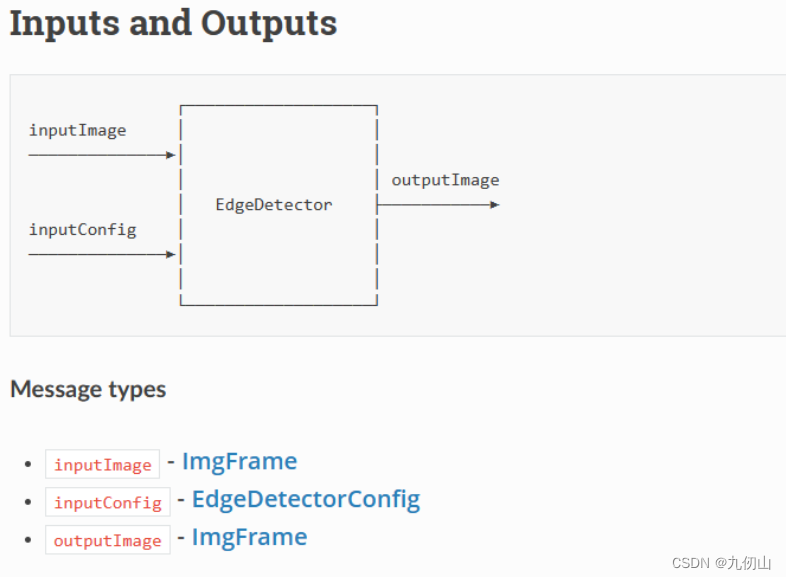
EdgeDetector节点
EdgeDetector节点,用于检测图像中的边缘。它能够对图像应用Canny边缘检测算法,并输出检测到的边缘信息。
以下是EdgeDetector节点的一些主要配置和功能:
-
输入图像:EdgeDetector节点接收彩色图像作为输入。可以将ColorCamera节点的输出连接到EdgeDetector节点,以便对彩色图像进行边缘检测。
-
边缘检测算法:EdgeDetector节点使用Canny边缘检测算法来检测图像中的边缘。Canny算法是一种经典的边缘检测算法,它通过计算图像中像素的梯度来确定边缘位置。
-
算法参数:EdgeDetector节点允许对Canny算法的参数进行调整,以达到最佳的边缘检测效果。一些常见的参数包括阈值范围、高斯平滑参数等。可以通过设置EdgeDetectorProperties中的相关参数来调整这些参数。
-
输出边缘图像:EdgeDetector节点的主要输出是边缘图像,其中将检测到的边缘以白色(255)表示,背景以黑色(0)表示。边缘图像以Numpy数组的形式表示,可以进一步进行处理或可视化。
-
边缘信息:EdgeDetector节点还可以提供关于检测到的边缘的附加信息。例如,有关每个边缘的像素坐标、强度等信息。可以通过检查EdgeDetectorResults中的相关属性来获取这些信息。
FeatureTracker 节点
FeatureTracker节点,主要用于在图像序列中跟踪特征点。它可以检测并跟踪图像中的关键点,以了解它们在连续帧之间的移动情况。
以下是FeatureTracker节点的一些主要配置和功能:
-
输入图像:FeatureTracker节点接收彩色图像作为输入。通常可以将ColorCamera节点的输出连接到FeatureTracker节点,以便对彩色图像进行特征点跟踪。
-
关键点检测算法:FeatureTracker节点使用一种特征点检测算法(如FAST、ORB等)来检测图像中的关键点。这些算法通过分析图像中像素的强度和纹理等特征来确定关键点的位置。
-
关键点跟踪:FeatureTracker节点不仅能够检测关键点,还可以跟踪这些关键点在连续帧之间的移动情况。它使用光流算法(如Lucas-Kanade、Farneback等)来估计关键点的移动向量,从而跟踪它们的轨迹。
-
算法参数:FeatureTracker节点允许对特征检测和光流估计算法的参数进行调整,以优化特征点检测和跟踪的质量和性能。可以通过设置FeatureTrackerProperties中的相关参数来进行调整。
-
输出特征点和光流:FeatureTracker节点的主要输出是特征点和光流数据。特征点以Numpy数组的形式表示,每个特征点包含其位置、尺寸、角度等信息。光流是一组向量,表示特征点在连续帧之间的移动向量。
通过使用FeatureTracker节点,可以在DepthAI中实现对图像序列中特征点的检测和跟踪功能。这在许多计算机视觉应用中非常有用,如视觉里程计、目标跟踪、运动分析等。

ImageManip节点
ImageManip节点,用于对图像进行各种图像处理操作。它可以应用多种滤波器、增强和变换等技术,以改变图像的外观和特征。
以下是ImageManip节点的一些主要配置和功能:
-
输入图像:ImageManip节点接收彩色图像作为输入。通常可以将ColorCamera节点的输出连接到ImageManip节点,以便对彩色图像进行处理。
-
图像处理操作:ImageManip节点支持多种图像处理操作,包括滤波器、增强和变换等。滤波器可以应用于图像以去除噪声或模糊图像。增强操作可以改善图像的对比度、亮度和色彩饱和度等。变换操作可以对图像进行旋转、缩放和裁剪等。
-
算法参数:ImageManip节点允许对图像处理操作的参数进行调整,以达到所需的处理效果。例如,可以调整滤波器的内核大小、增强操作的参数和变换操作的尺度等。
-
输出图像:ImageManip节点的主要输出是经过处理后的图像。处理后的图像可以以Numpy数组的形式表示,可以进一步进行处理或可视化。
通过使用ImageManip节点,可以在DepthAI中实现对图像的各种处理操作。这对于许多计算机视觉和图像处理应用非常有用,如图像增强、特征提取、前景提取等。可以根据具体需求选择适当的处理操作和参数。
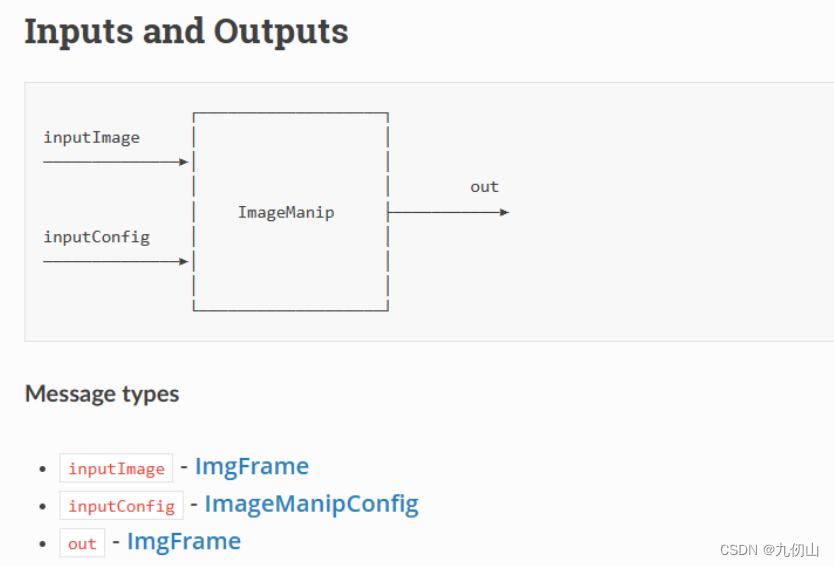
IMU 节点
DepthAI API中的IMU(Inertial Measurement Unit)节点是用于接收和处理来自DepthAI设备上的惯性测量数据的节点。IMU节点提供了物体的加速度、角速度和磁场等信息,可以用于姿态估计、运动检测和导航等应用。
IMU节点的主要功能和特点如下:
-
数据读取:IMU节点从DepthAI设备上获取原始的惯性测量数据。这些数据包括加速度、角速度和磁场等各个轴向的数值。
-
轴变换:IMU节点提供了轴变换功能,可以将惯性测量数据从设备本地坐标系转换到世界坐标系或其他自定义坐标系中。这有助于在不同的应用场景中对数据进行正确的解释和分析。
-
数据处理:IMU节点可以对从设备获取的原始测量数据进行一些基本的数据处理和滤波操作,以提高数据的质量和准确性。例如,可以应用低通滤波器来去除高频噪声。
-
数据输出:IMU节点的输出是经过处理后的惯性测量数据。可以获取加速度、角速度和磁场等各个轴向的数值。这些数据可以通过DepthAI API进行读取和使用。
IMU节点以惯性测量单位(如g、rad/s)为单位提供测量结果。通过使用IMU节点,开发者可以方便地利用DepthAI设备上的惯性测量功能,实现姿态估计、运动检测和导航等应用。
需要注意的是,IMU节点需要与DepthAI设备上的相关硬件配合使用,以确保惯性测量数据的精确性和准确性。
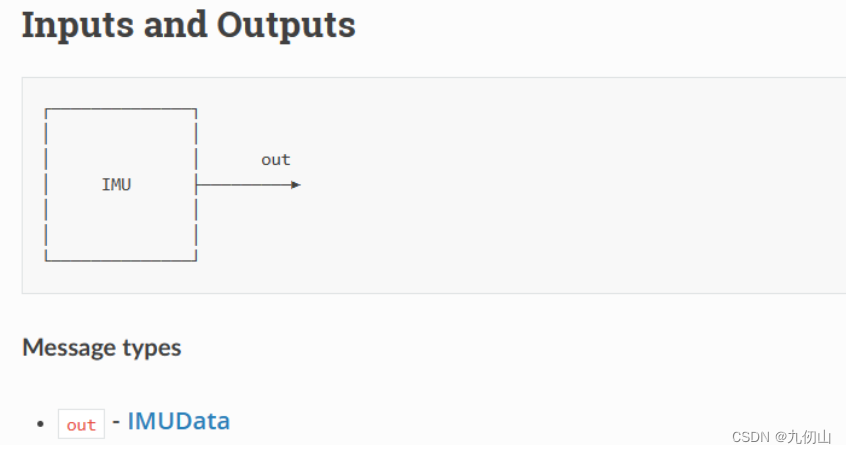
MobileNetDetectionNetwork节点
MobileNetDetectionNetwork是一个基于MobileNet架构的目标检测模型,用于在图像或视频中实时检测和定位多个物体。它是DepthAI的一个节点,用于进行目标检测任务。
MobileNetDetectionNetwork使用了MobileNet的轻量级架构,这使得它在嵌入式设备和移动平台上能够以高效的方式运行。MobileNet基于深度卷积神经网络(CNN),具有较少的参数和计算量,但能够保持较高的准确性。
MobileNetDetectionNetwork的主要配置和功能如下:
-
输入图像:MobileNetDetectionNetwork节点接收彩色图像作为输入。通常可以将ColorCamera节点的输出连接到MobileNetDetectionNetwork节点,以便对彩色图像进行目标检测。
-
目标检测:MobileNetDetectionNetwork使用训练好的目标检测模型,在输入图像中检测和定位多个物体。它可以识别多个常见的物体类别,如人、车辆、动物等。每个检测到的物体都将被标记为一个边界框,并估计其类别和置信度。
-
模型参数:MobileNetDetectionNetwork节点允许调整模型的参数,以优化目标检测性能。例如,可以设置置信度阈值、NMS(非极大值抑制)阈值等,以过滤低置信度的检测结果以及降低冗余的重叠边界框。
-
输出结果:MobileNetDetectionNetwork的主要输出是检测到的物体边界框的信息。每个边界框通常包括物体的类别、位置(左上角和右下角坐标)和置信度等。这些信息可以用于进一步的应用,如跟踪、计数和分类等。
通过使用MobileNetDetectionNetwork节点,可以在DepthAI中实现实时的目标检测和定位。它适用于许多计算机视觉和物体识别应用,如智能监控、自动驾驶、机器人导航等。可以根据具体需求选择适当的模型参数和阈值值,以达到所需的目标检测性能。
MobileNetSpatialDetectionNetwork节点
MobileNetSpatialDetectionNetwork节点,用于实时目标检测和定位任务。该节点使用MobileNet神经网络架构进行目标检测,借助DepthAI硬件进行高效处理。
MobileNetSpatialDetectionNetwork主要具有以下特点和功能:
-
轻量级架构:MobileNetSpatialDetectionNetwork使用MobileNet架构,这是一种轻量级的卷积神经网络(CNN)。相比其他复杂的网络,MobileNet具有较少的参数和计算量,适合在嵌入式设备和移动平台上进行实时目标检测。
-
目标检测:该节点通过训练好的模型,在输入的图像中检测和定位多个目标。它可以识别多个常见的物体类别,如行人、汽车、动物等。检测到的目标将被标记为边界框,并估计其类别和置信度。
-
高效处理:MobileNetSpatialDetectionNetwork借助DepthAI硬件进行加速处理,实现高效的目标检测。DepthAI设备配备了AI加速器、图像传感器和深度感知模块等组件,能够在边缘设备上实现实时的目标检测和定位。
-
灵活的配置:MobileNetSpatialDetectionNetwork节点允许开发者通过API进行配置,以满足不同应用的需求。可以调整置信度阈值和非极大值抑制(NMS)阈值等参数,以过滤低置信度的检测结果和降低冗余的重叠边界框。
-
输出结果:该节点主要输出是检测到的目标边界框的信息。每个边界框通常包括目标的类别、位置(左上角和右下角的坐标)和置信度等。这些信息可以用于后续的应用,如目标跟踪、目标计数和目标分类等。

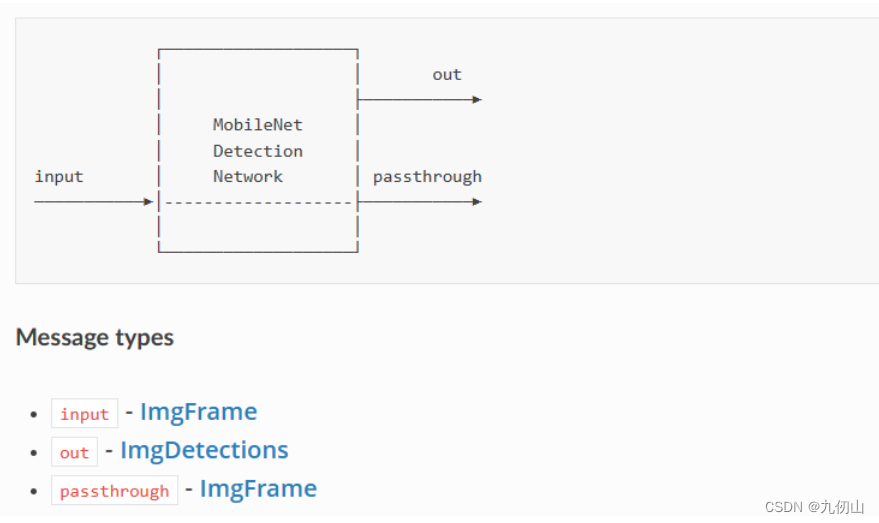
MonoCamera节点
MonoCamera节点,用于从DepthAI设备的单目摄像头获取图像数据并进行处理。该节点提供了实时的图像采集、校正和处理功能,可以应用于多种计算机视觉任务。
MonoCamera节点的主要功能和特点如下:
-
图像采集:MonoCamera节点从DepthAI设备的单目摄像头中获取图像数据。它能够以固定的帧率从摄像头读取图像,并将其传输给后续的节点进行处理。
-
图像校正:MonoCamera节点使用内置的图像校正功能,将从单目摄像头获取的图像进行校正,以消除图像畸变和失真。这有助于提高图像质量和准确性,特别是在进行精确测量或定位任务时。
-
数据处理:MonoCamera节点提供了一系列的图像处理功能,例如图像分辨率调整、图像裁剪、亮度对比度调整等。通过这些功能,可以根据具体需求对图像进行预处理,以优化后续任务的结果。
-
可配置性:MonoCamera节点具有高度可配置的参数,可以通过DepthAI API进行设置。这些参数包括图像的宽度、高度、帧率、曝光时间、增益等。开发者可以根据具体应用场景和需求来选择合适的参数配置。
-
数据输出:MonoCamera节点输出经过处理后的图像。开发者可以从节点获取图像数据,然后将其用于后续的图像处理、目标检测、目标跟踪等任务中。
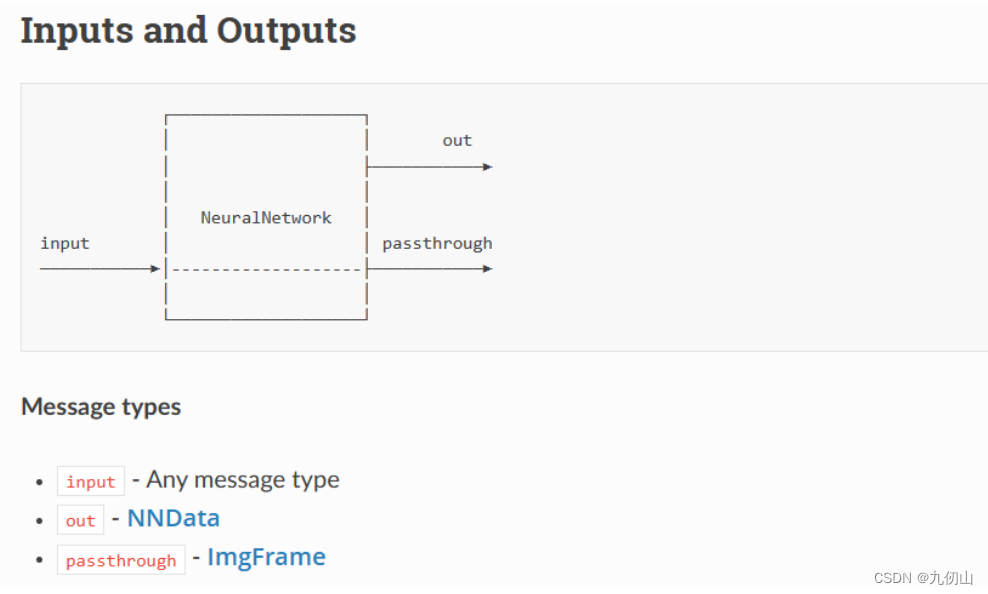
NeuralNetwork节点
NeuralNetwork节点(神经网络节点)是DepthAI API中的一个关键节点,用于加载和运行深度学习模型进行推理。该节点通过硬件加速器(如MyriadX)对模型进行高效的推理,适用于各种计算机视觉和人工智能任务。
NeuralNetwork节点的主要功能和特点如下:
-
模型加载:NeuralNetwork节点支持加载多种深度学习模型,包括常见的神经网络架构,如CNN、RNN和Transformer等。开发者可以通过指定模型文件路径或从内存中加载模型参数来进行模型加载。
-
模型推理:NeuralNetwork节点利用硬件加速器,在DepthAI设备上进行高效的模型推理。通过充分利用硬件加速器的并行计算能力,节点可以在实时场景中实现快速的推理速度,适用于对延迟敏感的应用。
-
输入输出处理:NeuralNetwork节点提供了对输入数据和输出结果的灵活处理能力。开发者可以根据模型的输入要求,对输入数据进行预处理,例如图像尺寸调整、归一化等。同样,输出结果也可以根据具体任务进行后续处理,例如目标检测框的解码和后处理。
-
多模型支持:NeuralNetwork节点支持同时加载和运行多个模型。这意味着开发者可以构建更复杂的计算图,利用多个模型实现更丰富的功能。每个模型可以有不同的输入和输出节点,以适应不同任务的需求。
-
配置和优化:NeuralNetwork节点具有丰富的配置选项,可以通过API进行设置。开发者可以调整节点的参数,以优化推理速度和准确性。例如,可以设置计算精度(FP16或INT8)、推理引擎(OpenVINO或TensorFlow)、推理批大小等。
NeuralNetwork节点为DepthAI设备提供了强大的深度学习推理能力。通过合理配置和优化,可以在边缘设备上实现高效的模型推理,开展各种计算机视觉和人工智能任务,如目标检测、图像分类、人脸识别、姿态估计等。
ObjectTracker节点
ObjectTracker节点,用于在实时视频流中对目标进行跟踪和定位。该节点结合了深度感知和计算机视觉技术,可以实现高精度的目标跟踪,并输出目标的位置、边界框以及其他相关信息。
ObjectTracker节点的主要功能和特点如下:
-
目标检测:ObjectTracker节点使用神经网络模型对输入的视频帧进行目标检测。它能够实时识别图像中的不同目标,并确定每个目标的位置和边界框。
-
目标跟踪:通过分析目标的轨迹和运动状态,ObjectTracker节点可以在连续的视频帧中跟踪目标的位置和运动。它利用目标的特征和历史信息,进行目标ID的匹配和更新,以实现稳定和连续的目标跟踪。
-
多目标支持:ObjectTracker节点支持同时跟踪多个目标。它可以在一个视频帧中检测到多个目标,并为每个目标分配唯一的ID。这样,开发者可以同时追踪多个目标并获取每个目标的位置和状态信息。
-
配置和参数调整:ObjectTracker节点具有可调整的参数,可以通过DepthAI API进行设置。开发者可以根据具体应用场景和需求,调整目标跟踪的灵敏度、最大追踪距离、最小检测置信度等参数,以优化目标跟踪的性能。
-
输出结果:ObjectTracker节点输出目标的位置信息、边界框和其他相关信息。开发者可以从节点获取跟踪结果,并将其用于后续的应用,如自主导航、智能安防、姿态分析等。
ObjectTracker节点可以与其他节点结合使用,例如MonoCamera节点和NeuralNetwork节点,以构建一个完整的目标检测和跟踪系统。

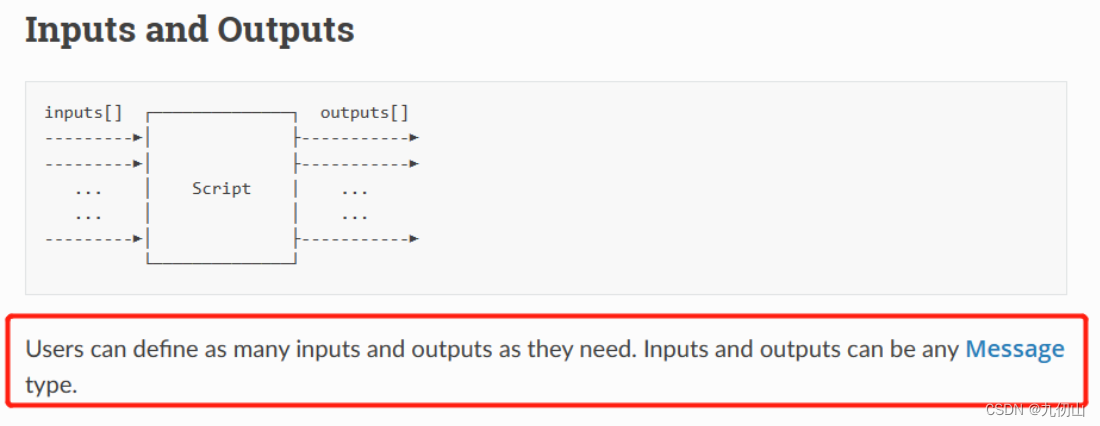
Script节点
Script节点,用于在深度AI设备上执行自定义的Python脚本。它提供了一个自由度很高的节点,可以在DepthAI设备上编写和运行各种功能丰富的Python脚本,从而实现高度定制化的计算机视觉和人工智能应用。
Script节点的主要功能和特点如下:
-
自定义脚本:Script节点允许开发者编写自己的Python脚本,并在DepthAI设备上运行。开发者可以利用Python的强大功能,根据具体需求编写各种计算机视觉和人工智能算法,比如图像处理、目标检测、姿态估计等。
-
灵活性和定制化:通过Script节点,开发者可以完全控制算法的实现和流程。这意味着可以根据具体应用场景和需求,自由选择和组合各种图像处理、深度学习和机器学习算法,并将其集成到一个脚本中。
-
快速迭代和调试:Script节点支持实时的脚本修改和热加载功能,使开发者可以在设计和开发过程中进行快速迭代和调试。通过实时反馈和调试工具,可以及时检测和修复脚本中的错误,提高开发效率。
-
与其他节点的集成:Script节点可以与其他的DepthAI节点相结合,实现更复杂的应用。例如,可以与NeuralNetwork节点结合,实现自定义的后处理算法;或者与ObjectTracker节点结合,实现自定义的目标跟踪算法。
-
应用范围广泛:Script节点适用于各种计算机视觉和人工智能应用场景。无论是在边缘设备上进行实时的图像处理和分析,还是在机器人、自动驾驶车辆等应用中进行高级视觉算法的实现,Script节点都提供了灵活且强大的功能。
Script节点通过自定义Python脚本的方式,使开发者可以灵活地实现各种定制化的计算机视觉和人工智能应用。它提供了与DepthAI设备的紧密集成,为开发者提供了一个强大的开发工具,用于构建和部署复杂的视觉算法。
SpatialLocationCalculator节点
SpatialLocationCalculator节点,用于计算物体在三维空间中的位置和姿态信息。该节点能够利用深度图像和相机的内参,将物体的二维图像坐标转换为物体在三维空间中的位置坐标和姿态信息。
SpatialLocationCalculator节点的主要功能和特点如下:
-
三维定位:通过利用深度图像和相机的内参,SpatialLocationCalculator节点可以将物体在二维图像中的位置信息映射到三维空间中。通过计算相机到物体的距离,以及物体在图像中的位置,节点可以估计物体在三维空间中的位置坐标。
-
姿态估计:除了位置信息,SpatialLocationCalculator节点还可以估计物体的姿态信息。它可以计算物体的旋转矩阵、欧拉角、四元数等姿态参数,以描述物体在三维空间中的方向和姿态。
-
多物体支持:SpatialLocationCalculator节点支持同时计算多个物体的位置和姿态信息。通过相机和深度图像提供的多视角信息,节点可以对多个物体进行独立的定位和姿态估计,从而实现多物体的三维空间定位。
-
参数调整:SpatialLocationCalculator节点具有可调整的参数,可以根据实际需求进行配置。例如,可以设置深度图像的单位,并根据物体的尺寸进行尺度估计,以提高定位和姿态估计的精度。
-
输出结果:SpatialLocationCalculator节点输出物体的三维位置坐标和姿态信息。开发者可以从节点获取这些信息,并将其用于后续的应用,如虚拟增强现实、机器人导航、姿态分析等。
通过SpatialLocationCalculator节点,开发者可以将DepthAI设备的深度感知能力与计算机视觉技术相结合,实现精确的物体定位和姿态估计。这为各种应用场景,如室内导航、物体检测和识别、增强现实等,提供了重要的三维空间信息。

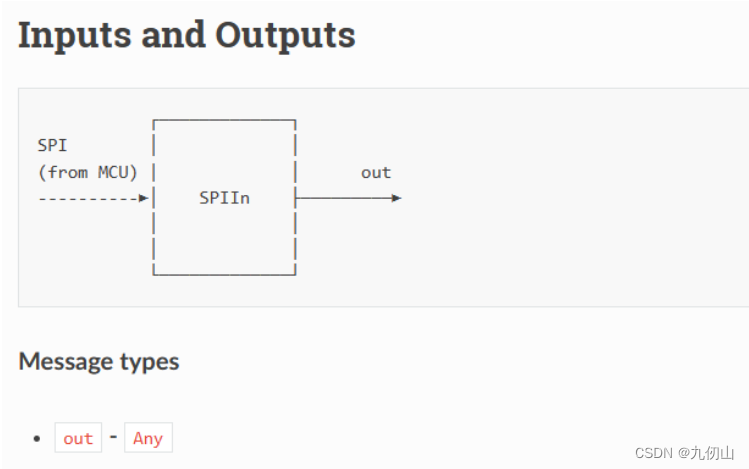
SPIIn节点
SPIIn节点,用于在DepthAI设备上接收SPI总线上的数据。SPI(Serial Peripheral Interface)是一种同步的串行通信协议,常用于连接外部设备和嵌入式系统之间进行数据交换。
SPIIn节点的主要功能和特点如下:
-
数据接收:SPIIn节点可以配置为监听SPI总线上的数据,并在DepthAI设备上接收这些数据。它支持高速的数据传输,能够接收来自外部设备的实时数据流。
-
灵活的配置:SPIIn节点提供了灵活的配置选项,可以根据具体应用需求进行参数设置。开发者可以指定SPI总线的通信速率、数据位宽、传输模式等,以适应各种外设和数据传输需求。
-
数据格式转换:SPIIn节点可以将接收到的原始数据进行格式转换,以便后续的处理和分析。例如,可以将二进制数据转换为图像、音频、加速度等其他类型的数据,便于进一步的算法处理和应用。
-
与其他节点的集成:SPIIn节点可以与其他节点相结合,实现更复杂的应用。例如,可以将SPIIn节点与NeuralNetwork节点结合,实现深度学习模型对实时SPI数据的分析和处理;或者与Script节点结合,实现自定义的数据解析和算法处理。
-
广泛应用:SPIIn节点适用于各种应用场景,如图像采集、传感器数据接收、外设通信等。通过SPIIn节点,DepthAI设备可以灵活地与外部设备进行数据交换,实现更丰富和复杂的应用。
SPIIn节点提供了一个方便的接口,使得DepthAI设备可以与外部设备进行数据交互。它可以将SPI总线上的数据传输到DepthAI设备上,并通过其他节点的处理和分析,实现各种应用需求,如图像处理、数据采集、物联网等。
SPIOut节点
SPIOut节点,用于向外部设备发送数据,通过SPI(Serial Peripheral Interface)总线进行通信。
SPIOut节点的主要功能和特点如下:
-
数据发送:SPIOut节点可以配置为向外部设备发送数据。它支持高速的数据传输,可以将数据流通过SPI总线发送给外部设备。
-
灵活的配置:SPIOut节点提供了灵活的配置选项,可以根据具体应用需求进行参数设置。开发者可以指定SPI总线的通信速率、数据位宽、传输模式等,以适应各种外设和数据传输需求。
-
数据格式转换:SPIOut节点可以将要发送的数据进行格式转换,以适应外部设备的接口和要求。例如,可以将图像数据转换为适当的位宽和格式,以便外部设备能够正确解析和处理。
-
与其他节点的集成:SPIOut节点可以与其他节点相结合,实现更复杂的应用。例如,可以将SPIOut节点与Script节点结合,实现自定义的数据处理和发送逻辑;或者与NeuralNetwork节点结合,实现与深度学习模型的数据交互。
-
广泛应用:SPIOut节点适用于各种应用场景,如与外部传感器通信、控制外部设备等。通过SPIOut节点,DepthAI设备可以向外部设备发送数据流,实现与外部系统的数据交互和控制。
SPIOut节点提供了一个方便的接口,使得DepthAI设备可以与外部设备进行数据交互。它可以根据配置参数将数据通过SPI总线发送给外部设备,实现数据交换和控制操作。通过SPIOut节点,DepthAI设备可以灵活地与外部设备进行数据通信,适应各种应用需求。

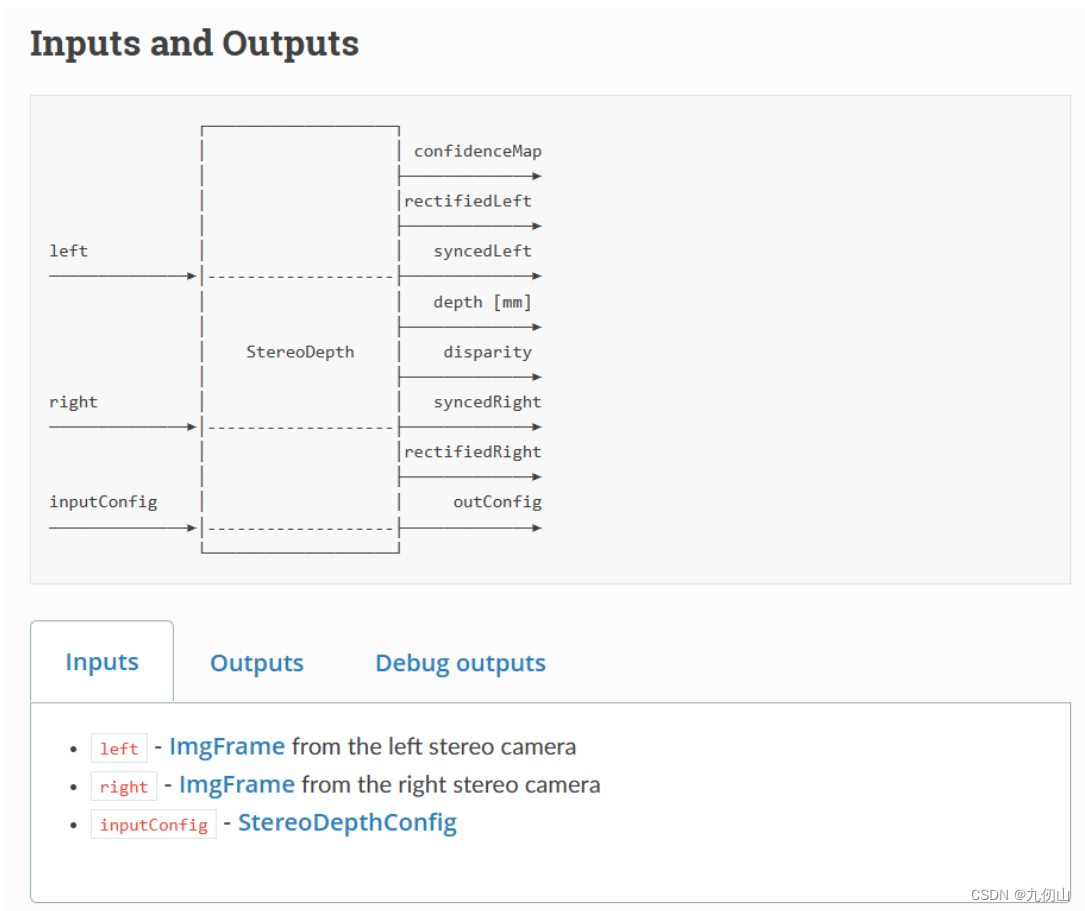
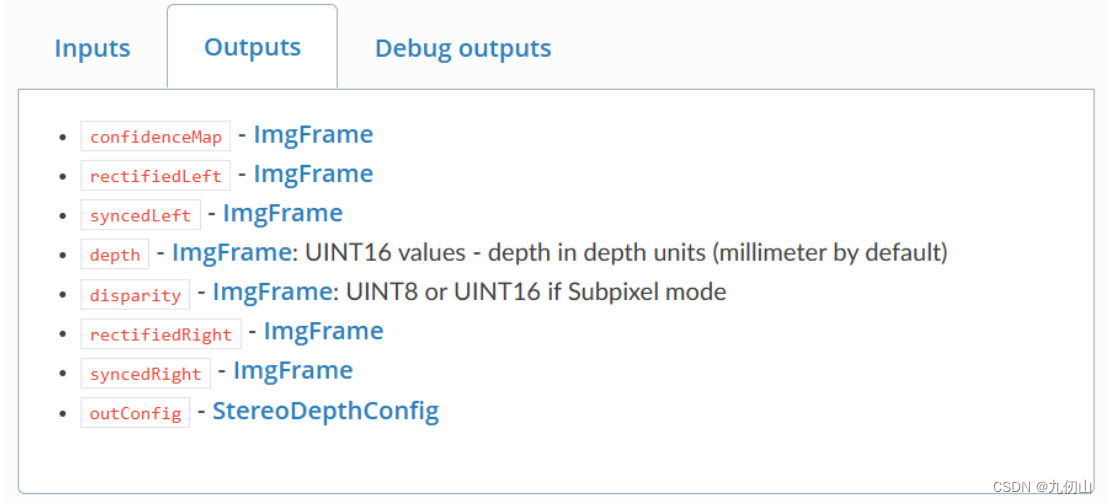
StereoDepth节点
StereoDepth节点,用于在DepthAI设备上进行立体深度感知和视觉深度重建。立体深度感知通过在图像上进行视差分析,从而获取场景中物体的距离信息,并生成对应的深度图。
StereoDepth节点的主要功能和特点如下:
-
双目相机输入:StereoDepth节点接受由双目相机(包括左右两个摄像头)采集到的图像作为输入。这样的双目图像提供了场景在不同视角下的视差信息,用于计算物体的深度。
-
视差计算:StereoDepth节点通过对左右图像的像素进行匹配,计算出视差图。视差值表示了两个相同物体在左右图像上的像素偏移,从而可以得到物体相对于相机的距离。
-
深度图生成:通过视差图,StereoDepth节点可以生成对应的深度图。深度图是由像素表示的物体距离信息,每个像素值代表了相对于相机的距离。
-
立体视觉效果增强:StereoDepth节点还提供了一系列可选的视觉效果增强选项,如视差范围限制、颜色深度映射等。这些选项可以改善生成的深度图的质量和可视化效果。
-
输出数据:StereoDepth节点输出的主要数据是深度图和视差图。这些数据可以用于进一步的计算和分析,如物体检测、三维重建、虚拟现实等应用。
-
与其他节点的集成:StereoDepth节点可以与其他节点相结合,实现更复杂的应用。例如,可以将StereoDepth节点与Script节点结合,实现自定义的深度处理和应用逻辑;或者与NeuralNetwork节点结合,实现基于深度信息的目标检测和分割。
StereoDepth节点通过双目图像的视差计算和深度图生成,实现了DepthAI设备的立体深度感知功能。它是深度感知和视觉深度重建的关键节点,可以为各种应用提供准确的场景深度信息。
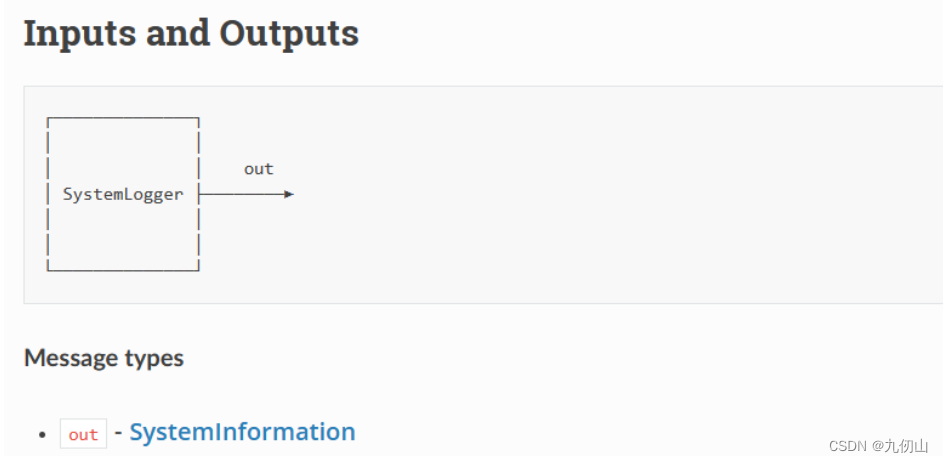
SystemLogger节点
SystemLogger节点,用于在DepthAI设备上进行系统日志记录和输出。它提供了一个方便的接口,用于监控和记录DepthAI设备的运行状态、性能指标和错误信息。
SystemLogger节点的主要功能和特点如下:
-
系统日志记录:SystemLogger节点可以记录DepthAI设备的系统日志信息。这些日志信息可以包括设备启动信息、系统状态、异常事件、运行时错误等。通过记录这些日志,可以方便地进行系统故障排查和调试。
-
性能指标:SystemLogger节点可以记录DepthAI设备的性能指标,如帧率、执行时间等。这些指标可以帮助用户了解设备的运行性能,并进行性能优化和调整。
-
日志级别设置:SystemLogger节点支持设置不同的日志级别,如调试、信息、警告、错误等级别。用户可以根据需要选择合适的级别来记录日志,以控制日志的输出量和详细程度。
-
日志输出位置:SystemLogger节点支持将日志输出到不同的位置。可以选择将日志输出到控制台终端,或者通过网络输出到远程监控工具或日志服务器中。这样可以方便地进行日志的远程访问和监控。
-
快速集成:SystemLogger节点的集成非常简单,只需在DepthAI应用中添加该节点并进行适当的配置即可。它提供了一种轻量级和便捷的方式来实现系统日志的记录和输出。
SystemLogger节点是DepthAI设备的一个重要组件,它可以帮助用户监控设备的运行状态和性能,并记录运行时的错误和异常事件。通过SystemLogger节点,用户可以方便地进行系统调试和故障排查,并及时采取适当的措施解决问题。
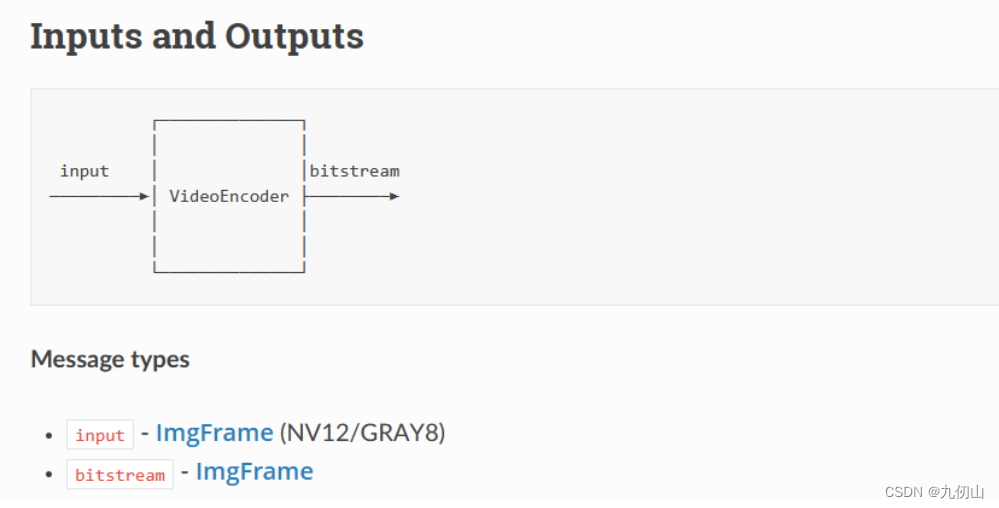
VideoEncoder节点
VideoEncoder节点,用于在DepthAI设备上进行实时视频编码和压缩。它允许将实时视频流转换为常见的视频编码格式,如H.264或H.265,并在设备上进行压缩,以便于传输和存储。
VideoEncoder节点的主要功能和特点如下:
-
实时视频编码:VideoEncoder节点接受来自摄像头或其他视频源的实时视频流作为输入,并将视频流转换为压缩的视频编码格式。这样可以减少视频数据的存储和传输所需的带宽和存储空间。
-
支持多种视频编码格式:VideoEncoder节点支持多种常见的视频编码格式,如H.264和H.265。这些编码格式具有高压缩比和良好的视频质量,可以满足各种应用场景的需求。
-
压缩参数配置:VideoEncoder节点提供了一些可配置的参数,用于调整视频编码的压缩质量和性能。用户可以根据需要选择合适的参数,以平衡视频质量和压缩效率。
-
码率控制:VideoEncoder节点支持码率控制机制,可以根据需求动态调整视频的码率。这使得视频编码可以适应不同的网络带宽和存储条件,确保视频传输的流畅性和存储的有效性。
-
多路编码:VideoEncoder节点支持同时对多个视频流进行编码,即支持多路编码。这样可以实现同时对多个摄像头或视频源的编码和压缩,适用于多路视频监控、视频会议等应用。
-
与其他节点的集成:VideoEncoder节点可以与其他节点相结合,实现更复杂的视频处理和应用。例如,可以将VideoEncoder节点与Script节点结合,实现定制的视频编码逻辑;或者与NeuralNetwork节点结合,实现基于视频流的实时目标检测和分析。
VideoEncoder节点的存在可以实现实时视频的压缩和编码,方便视频的存储和传输。它是DepthAI设备的一个重要组件,在视频监控、视频会议、实时视频流处理等应用中发挥着重要作用。
Warp节点
Warp节点,用于对输入图像进行透视变换(perspective warping)。它可以根据用户定义的四个点的坐标,将输入图像进行透视变换,从而得到输出图像。
Warp节点的主要功能和特点如下:
-
透视变换:Warp节点通过透视变换,将输入图像上的特定区域映射到输出图像上的目标区域,从而改变图像的视角和姿态。透视变换可以用于许多应用场景,如校正图像畸变、纠正投影变形、改变图像视角等。
-
四点坐标定义:Warp节点使用用户提供的四个点的坐标来定义透视变换。这四个点一般对应于输入图像中的四个角点或感兴趣的区域的四个边缘点。根据这四个点的坐标,Warp节点可以计算出透视变换所需的转换矩阵。
-
输出图像尺寸:Warp节点可以指定输出图像的尺寸。用户可以根据需求选择合适的输出图像尺寸,并确保变换后的图像具有所需的分辨率和纵横比。
-
仿射变换:Warp节点在透视变换之前,通常还会进行仿射变换。仿射变换是一种线性变换,可以平移、旋转和缩放输入图像,从而更好地适应透视变换的要求。通过在透视变换之前进行仿射变换,可以得到更准确的结果。
-
图像插值:Warp节点支持不同的图像插值方法,用于在透视变换过程中进行像素值的计算。常用的插值方法包括最近邻插值、双线性插值和三次样条插值。用户可以根据需求选择合适的插值方法,以平衡图像质量和计算效率。
Warp节点可以与其他节点相结合,实现更复杂的图像处理和应用。例如,可以将Warp节点与NeuralNetwork节点结合,将透视变换后的图像输入到神经网络中进行目标检测或分类。通过使用Warp节点,用户可以方便地进行图像的透视变换,从而实现许多图像处理任务。
XLinkIn节点
XLinkIn节点,用于从深度AI设备的XLink输入接口获取数据。它可以接收来自外部主机或其他设备通过XLink接口发送的数据,并将其作为输入流供后续处理节点使用。
XLinkIn节点的主要功能和特点如下:
-
数据接收:XLinkIn节点通过DepthAI设备的XLink输入接口接收数据。XLink是一种高速、可靠的通信接口,用于连接DepthAI设备与其他主机或设备之间进行数据传输。
-
多通道支持:XLinkIn节点支持多通道数据传输,可以接收多个独立的数据流。每个通道都有一个唯一的通道ID,用于区分不同的数据流。这使得XLinkIn节点能够同时接收多个独立的数据源。
-
数据类型:XLinkIn节点可以接收不同类型的数据,如图像、视频流、传感器数据等。通过适当的配置,XLinkIn节点可以处理各种不同类型的数据,并将其传递给后续节点进行进一步处理。
-
数据流控制:XLinkIn节点支持数据流的控制和同步。它可以根据需求控制数据的传输速率和时序,确保数据的及时接收和处理。
-
数据传输模式:XLinkIn节点支持两种数据传输模式:阻塞模式和非阻塞模式。在阻塞模式下,XLinkIn节点会等待并阻塞直到接收到完整的数据包。在非阻塞模式下,XLinkIn节点会在数据包尚未完整到达时立即返回,并稍后再次进行读取。
-
错误处理:XLinkIn节点具有处理错误和异常情况的能力。当发生通信错误或数据传输问题时,XLinkIn节点可以报告错误并采取适当的措施,如重试或重新连接。
通过使用XLinkIn节点,用户可以方便地从外部设备或主机接收数据,并将其用作DepthAI设备的输入。这为实时数据处理、传感器数据采集、数据交互等应用提供了灵活性和可扩展性。
XLinkOut节点
XLinkOut节点,用于将数据从DepthAI设备通过XLink输出接口发送出去。它可以将数据流发送到外部主机或其他设备进行处理或存储。
XLinkOut节点的主要功能和特点如下:
-
数据发送:XLinkOut节点通过DepthAI设备的XLink输出接口发送数据。XLink是一种高速、可靠的通信接口,用于连接DepthAI设备与其他主机或设备之间进行数据传输。
-
多通道支持:XLinkOut节点支持多通道数据传输,可以发送多个独立的数据流。每个通道都有一个唯一的通道ID,用于区分不同的数据流。这使得XLinkOut节点能够同时发送多个独立的数据源。
-
数据类型:XLinkOut节点可以发送不同类型的数据,如图像、视频流、传感器数据等。通过适当的配置,XLinkOut节点可以处理各种不同类型的数据,并将其传输到外部设备进行进一步处理。
-
数据流控制:XLinkOut节点支持数据流的控制和同步。它可以根据需求控制数据的传输速率和时序,确保数据的及时发送和接收。
-
数据传输模式:XLinkOut节点支持两种数据传输模式:阻塞模式和非阻塞模式。在阻塞模式下,XLinkOut节点会等待并阻塞直到数据包成功发送。在非阻塞模式下,XLinkOut节点会立即返回,并在后续的传输中继续发送数据。
-
错误处理:XLinkOut节点具有处理错误和异常情况的能力。当发生通信错误或数据传输问题时,XLinkOut节点可以报告错误并采取适当的措施,如重试或重新连接。
通过使用XLinkOut节点,用户可以将DepthAI设备处理的数据方便地发送到外部设备或主机进行进一步处理或存储。

YoloDetectionNetwork节点
YoloDetectionNetwork节点,用于在DepthAI设备上使用Yolo算法进行对象检测。它可以接收来自摄像头或其他数据源的图像或视频流,并通过应用Yolo算法来实时检测场景中的对象。
YoloDetectionNetwork节点的主要功能和特点如下:
-
对象检测:YoloDetectionNetwork节点使用Yolo算法来进行对象检测。Yolo(You only look once)是一种基于深度学习的目标检测算法,能够实时而准确地检测图像或视频中的多个对象。
-
多类别支持:YoloDetectionNetwork节点支持检测多个不同类别的对象。通过适当的配置,用户可以定义需要检测的对象类别,并在结果中获取每个检测到的对象的类别标签。
-
目标框输出:YoloDetectionNetwork节点能够输出每个检测到的对象的位置信息,即目标框(bounding box)。目标框描述了每个对象在图像中的位置和大小,以及其与图像边界的相对位置。
-
可信度输出:YoloDetectionNetwork节点还能输出每个检测到的对象的可信度(confidence)。可信度指示算法对每个检测结果的置信程度,可以用来进行目标筛选或分类。
-
数据流控制:YoloDetectionNetwork节点支持对数据流的控制和同步。用户可以配置节点,以控制输入图像或视频流的帧率和分辨率,以及输出检测结果的速率。
-
高性能推理:YoloDetectionNetwork节点可以在DepthAI设备上进行高效的推理。由于DepthAI设备本身具有专用的硬件加速器,它能够以高效的方式运行深度学习算法,实现实时的对象检测性能。
通过使用YoloDetectionNetwork节点,用户可以在DepthAI设备上实现高性能的对象检测。无论是用于实时监控、智能安防、自动驾驶等应用,还是用于智能辅助、机器人导航等领域,该节点都能提供准确、快速的对象检测功能。
YoloSpatialDetectionNetwork节点
Yolo神经网络的空间检测。它类似于YoloDetectionNetwork和SpatialLocationCalculator的组合。
YoloSpatialDetectionNetwork节点利用了YOLO算法来检测图像或视频中的目标,并提供边界框和类别概率的输出。
YoloSpatialDetectionNetwork节点接受图像或视频帧作为输入,然后使用经过预训练的深度学习模型(如YOLOv3或YOLOv4等)来检测输入数据中的目标。该节点的输出包括每个被检测到的目标的边界框坐标(左上角和右下角),以及该目标属于每个类别的概率。
YoloSpatialDetectionNetwork节点的优点是可以在嵌入式设备上实现实时目标检测,无需依赖网络连接或云服务。这使其非常适用于诸如智能摄像头、无人驾驶、机器人等需要实时目标检测的应用场景。
需要注意的是,使用YoloSpatialDetectionNetwork节点需要预先训练好的深度学习模型,并对其进行部署。在DepthAI平台中,预训练的YOLO模型已经包含在内,用户只需加载模型并配置相关参数即可进行目标检测。