一、jupyter的基本使用

二、Numpy
2.1 numpy的创建

#使用array()创建一个多维数组
import numpy as np
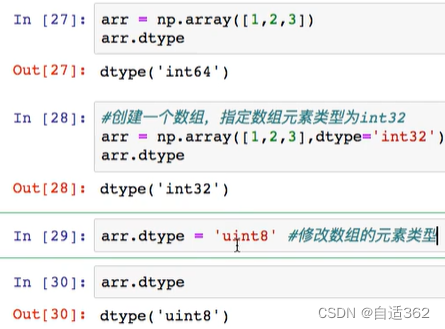
arr=np.array([1,2,3])
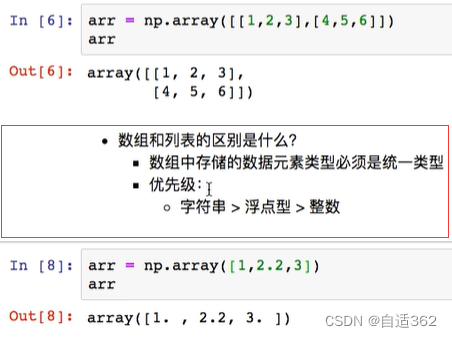
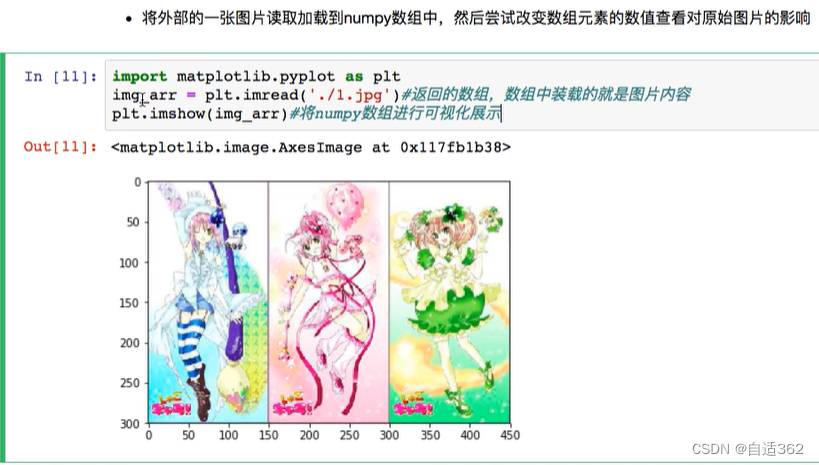

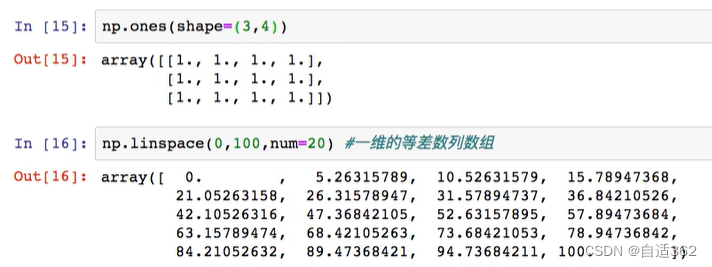
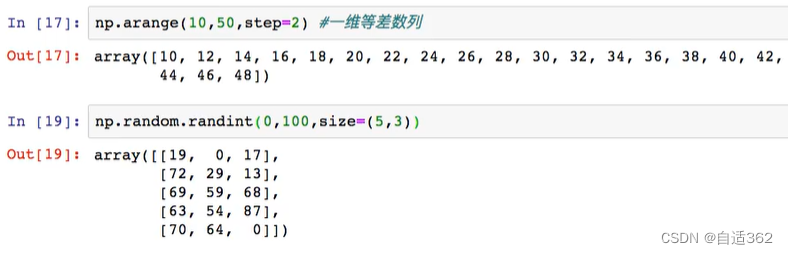
2.2 numpy的属性

修改数组的元素类型
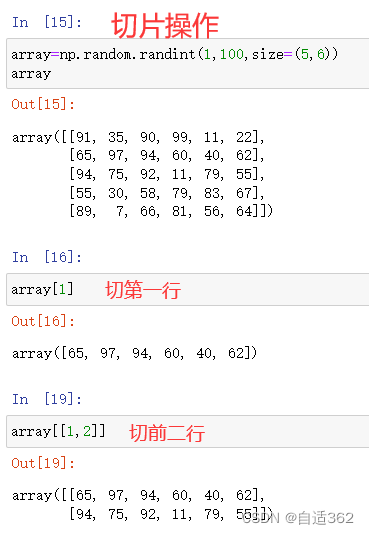
2.3 索引和切片
(1)行切片
(2)列切片

注意列切片

(3)综合切片


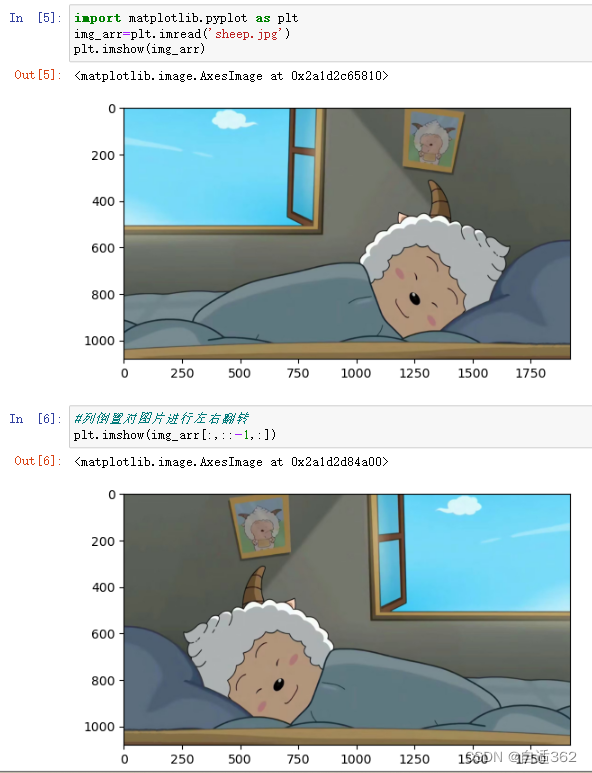
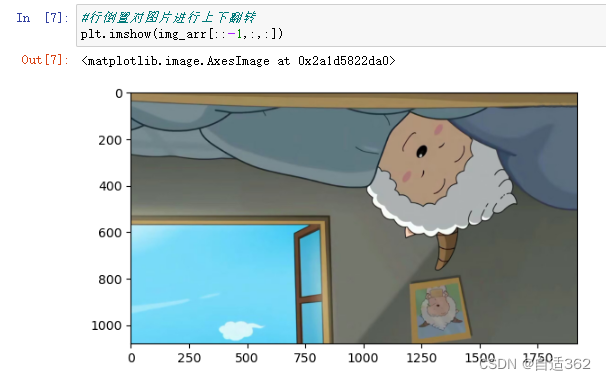
(4)倒置


* 将图片进行翻转
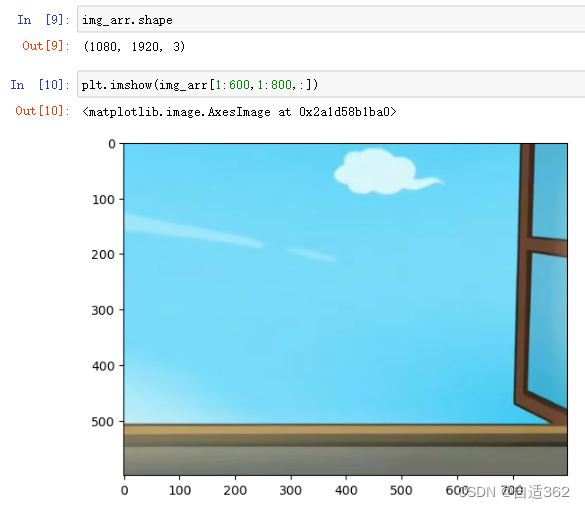
* 裁剪图片
(5)变形
多维变成一维数组
一维变多维


(6)级联操作
只能维度相同的级联


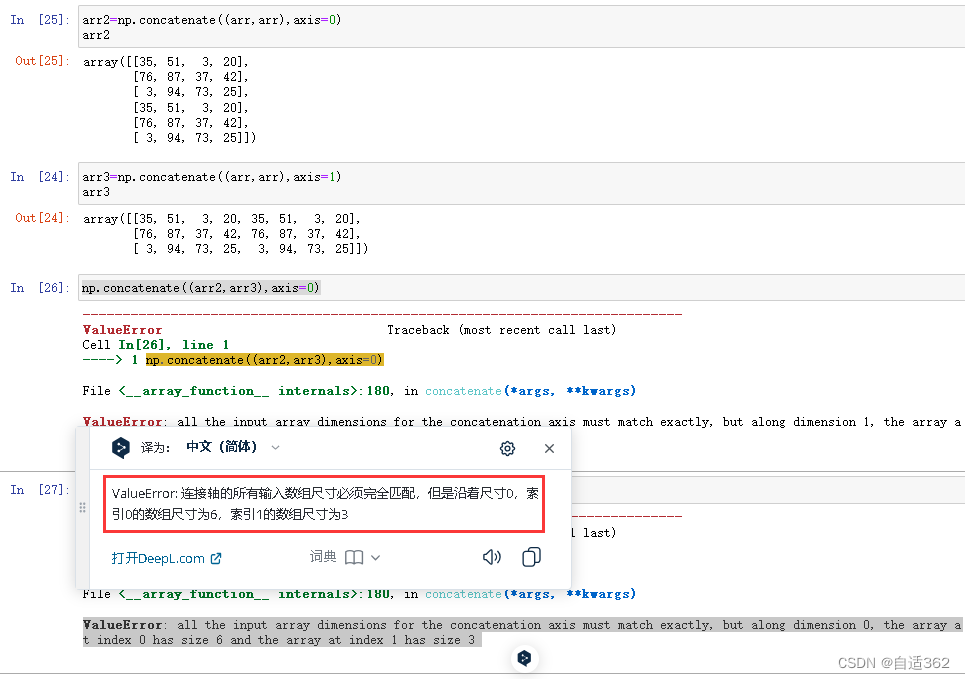
* 拼图操作

(7)聚合操作

数学相关
常用数学函数


方差是标准差的平方

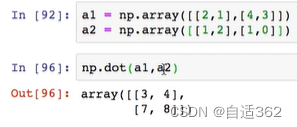
矩阵相关

转置

相乘
三、Pandas
主要用于 存储非数值的数据类型

这是两种不同的数据结构

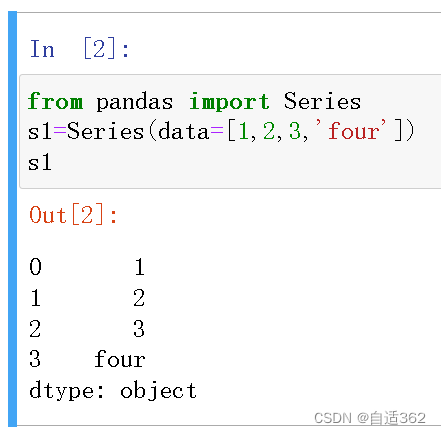
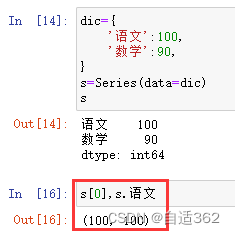
3.1 Series

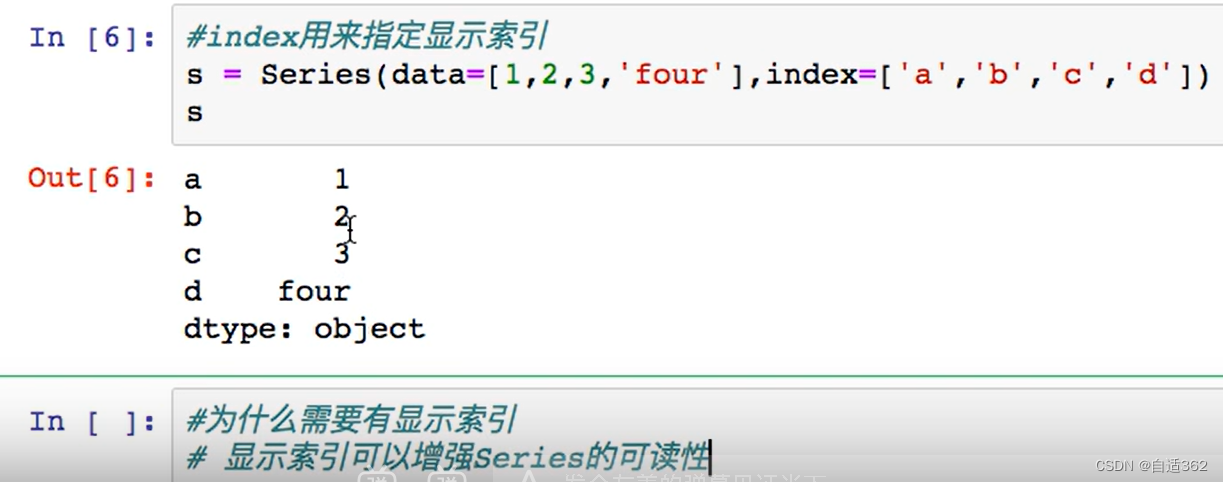
索引值变为a,b,c,d。
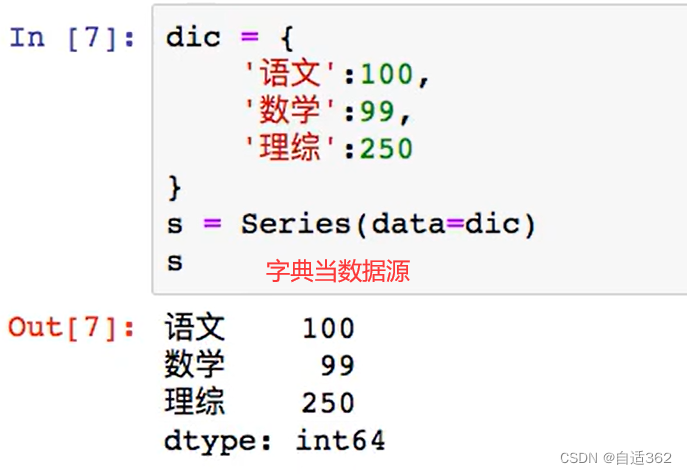
3.2 索引和切片

3.3 属性
表示一维数组



series也只能存储同类型数据
3.4 常用方法
(1)取数据


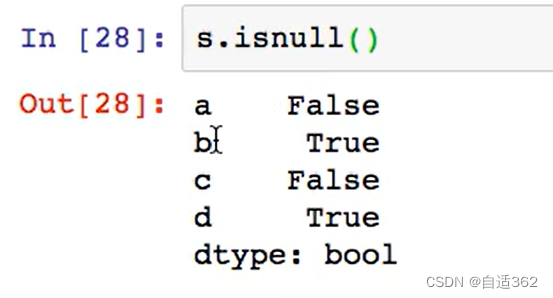
(2)对元素进行判断

并且每个数组的数据类型为布尔值

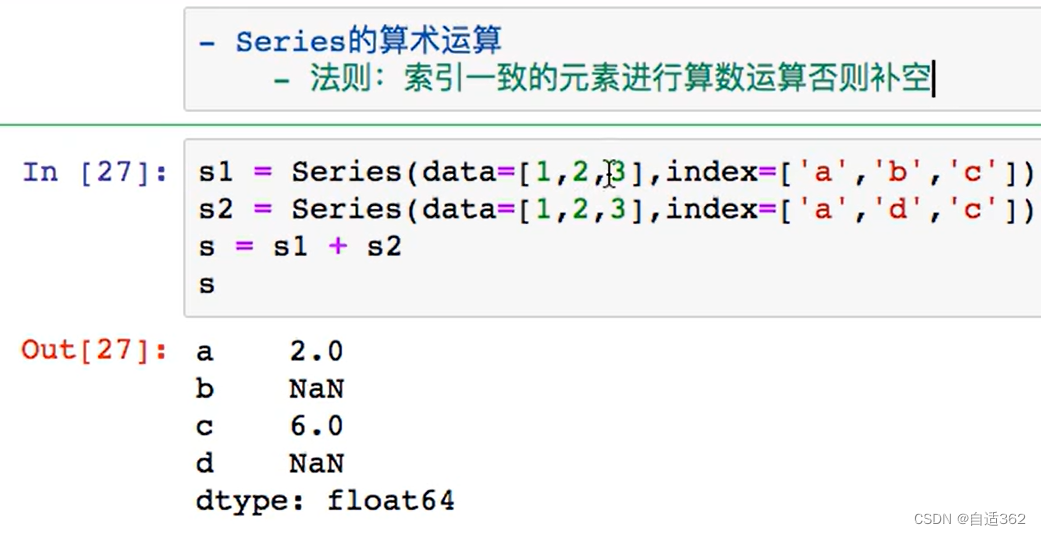
(3)算数运算

3.2 Dataframe
(1)创建
由多个Series组成,是个二维数据。



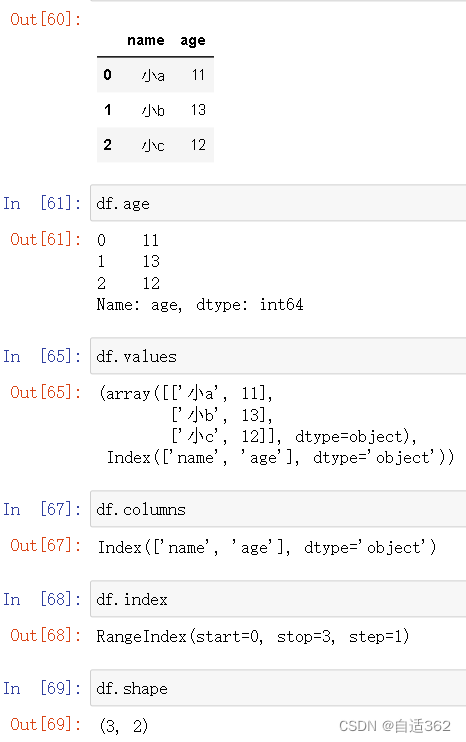
(2)属性

* 练习

dic={
'张三':[150,150,150,300],
'李四':[0,0,0,0]
}
df=DataFrame(data=dic,index=['语文','数学','英语','理综'])
df

(3)索引

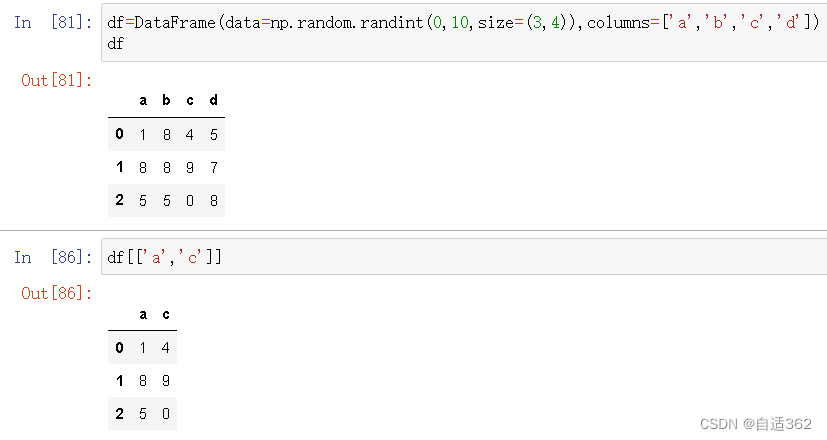
取列
- 取单列

- 取a,c两列
取行、单个元素
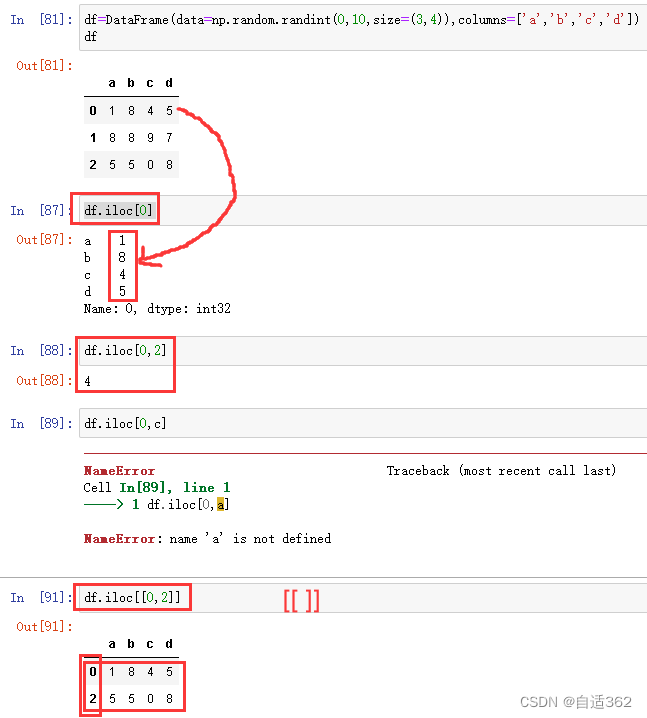
iloc和loc


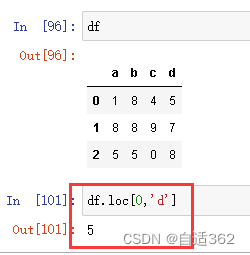

(4)切片

* 应用
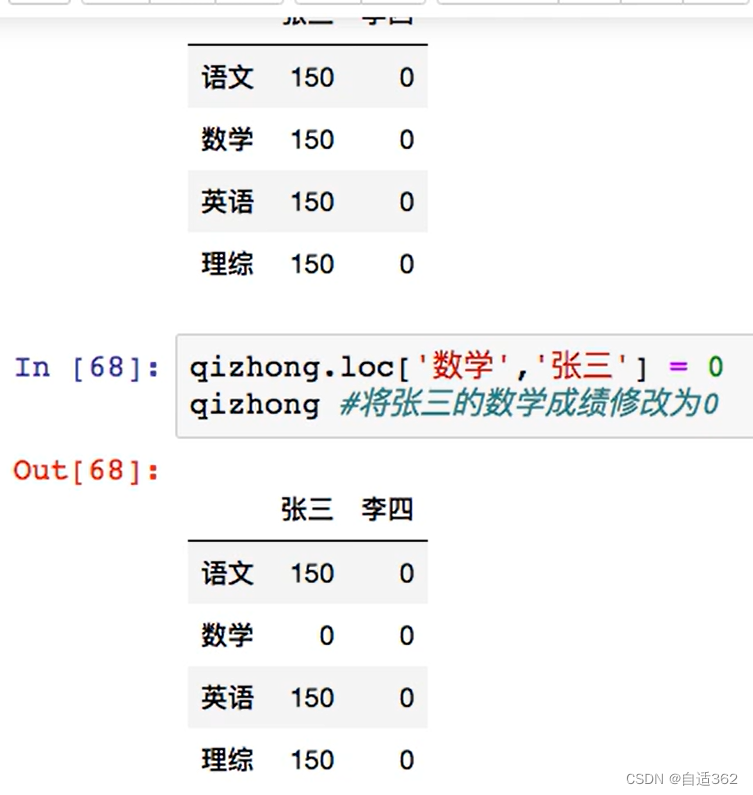



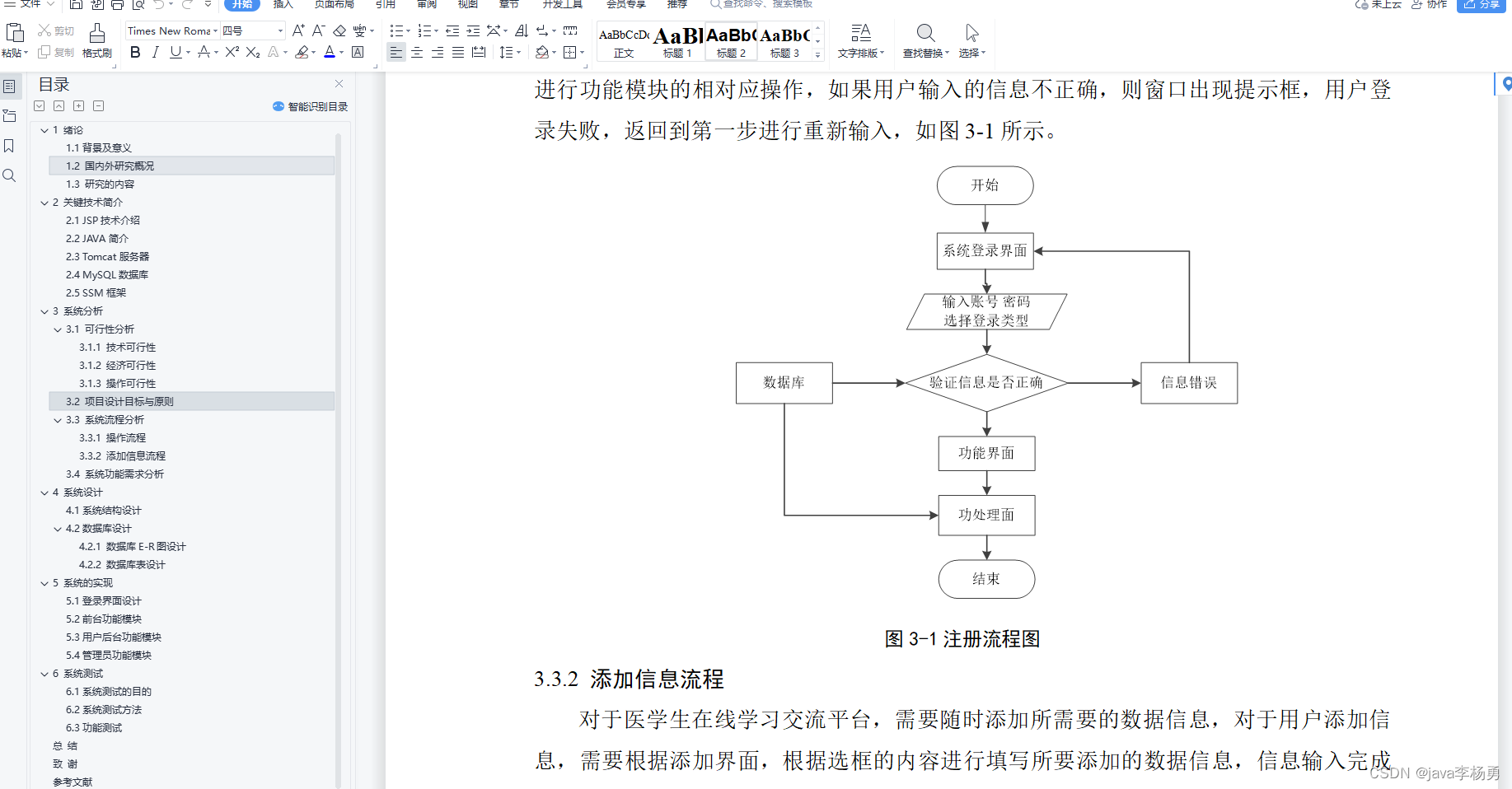
3.3 股票小项目

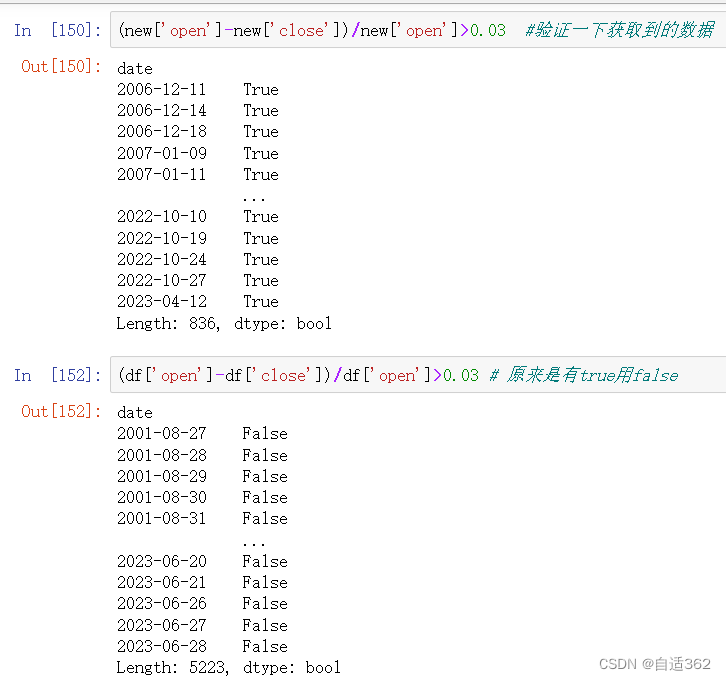
(1)需求1:输出所有 收盘比开盘上涨3%的日期
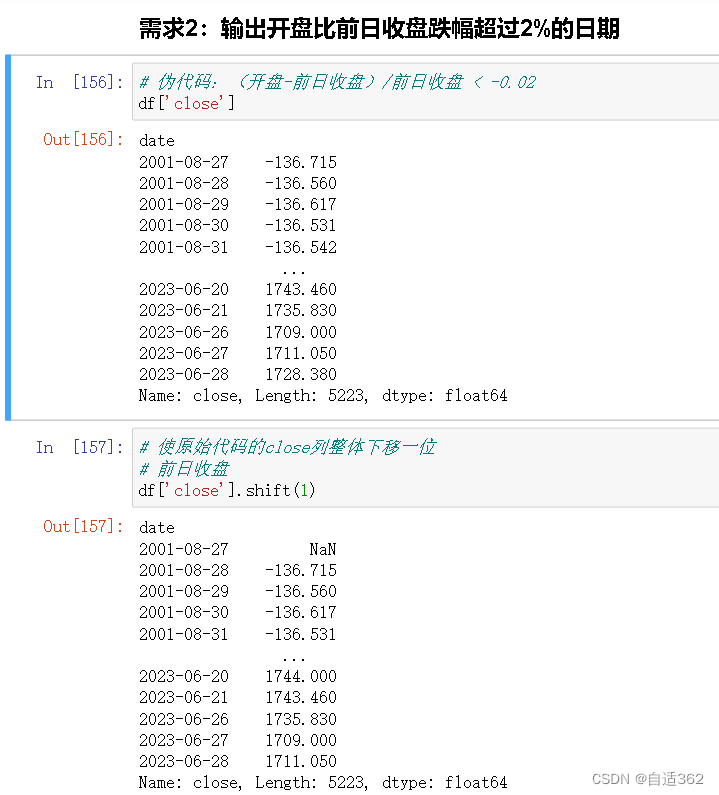
(2)需求2:输出开盘比前日收盘跌幅超过2%的日期
import tushare as ts
import pandas as pd
from pandas import DataFrame,Series
import numpy as np
# 获取某只股票的历史行情数据
df=ts.get_k_data(code='600519',start='2000-01-01')
df
# 将互联网上获取的股票数据存储到本地
df.to_csv('./maotai.csv')
# 将本地存储的数据读入到df中
pd.read_csv('./maotai.csv')
df.head()
# 对读取出的数据进行相关处理
# 查看每一列的数据类型
df['date'].dtype
# 另一种方法
df.info()
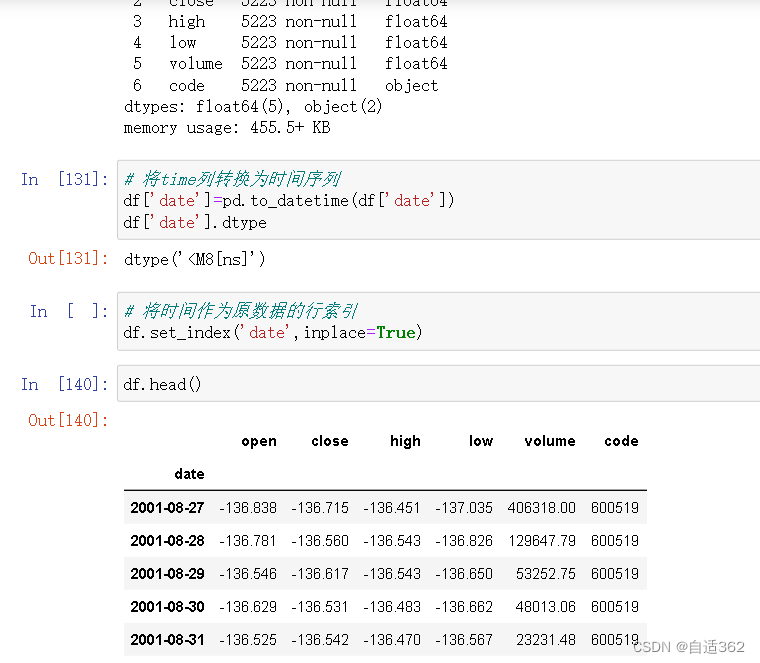
# 将time列转换为时间序列
df['date']=pd.to_datetime(df['date'])
df['date'].dtype
# 将时间作为原数据的行索引
df.set_index('date',inplace=True)
df.head()
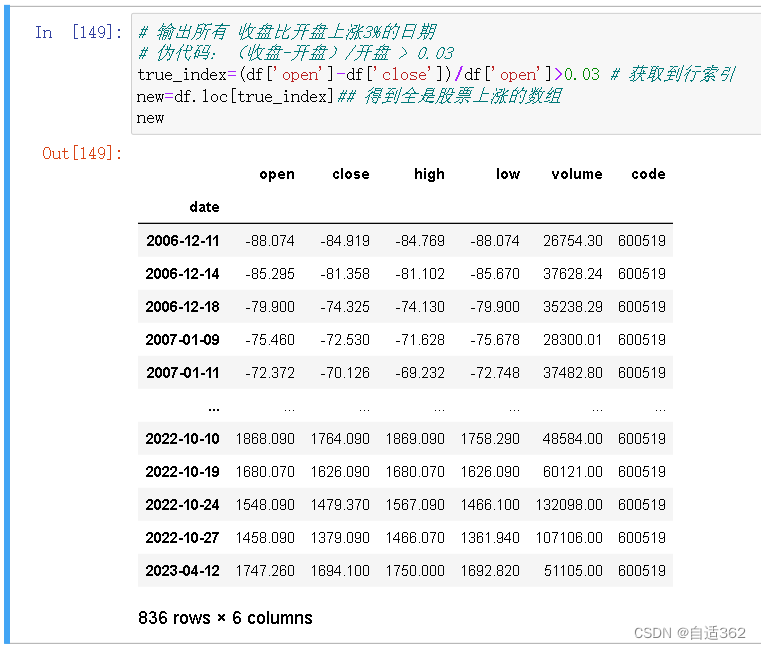
### 需求1:输出所有 收盘比开盘上涨3%的日期
# 伪代码:(收盘-开盘)/开盘 > 0.03
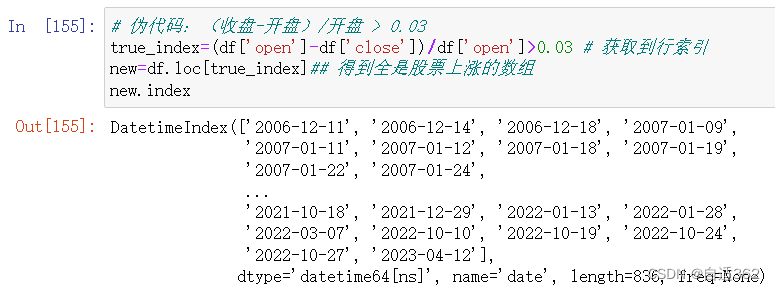
true_index=(df['open']-df['close'])/df['open']>0.03 # 获取到行索引
new=df.loc[true_index]## 得到全是股票上涨的数组
new.index
(new['open']-new['close'])/new['open']>0.03 #验证一下获取到的数据
(df['open']-df['close'])/df['open']>0.03 # 原来是有true用false
### 需求2:输出开盘比前日收盘跌幅超过2%的日期
# 伪代码:(开盘-前日收盘)/前日收盘 < -0.02
df['close']
# 使原始代码的close列整体下移一位
# 前日收盘
df['close'].shift(1)
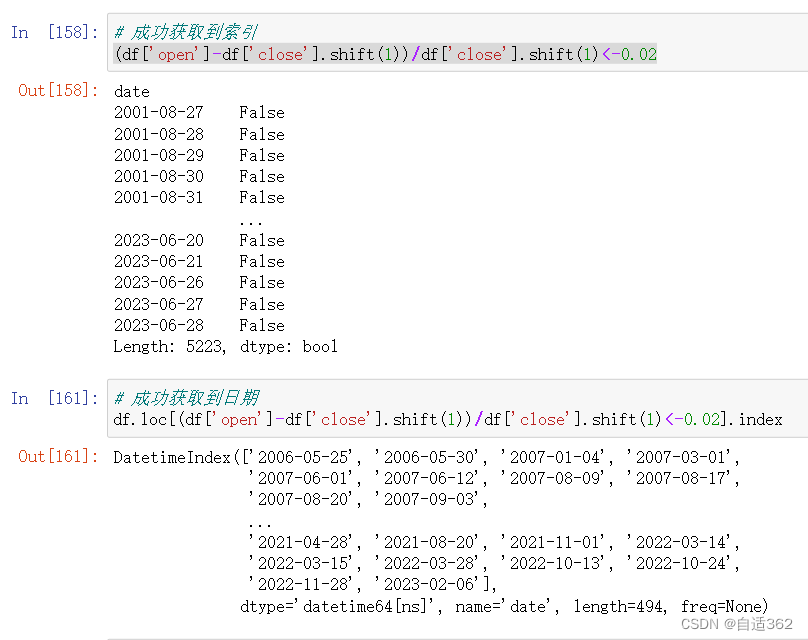
# 成功获取到索引
(df['open']-df['close'].shift(1))/df['close'].shift(1)<-0.02
# 成功获取到日期
df.loc[(df['open']-df['close'].shift(1))/df['close'].shift(1)<-0.02].index
### 需求3: 
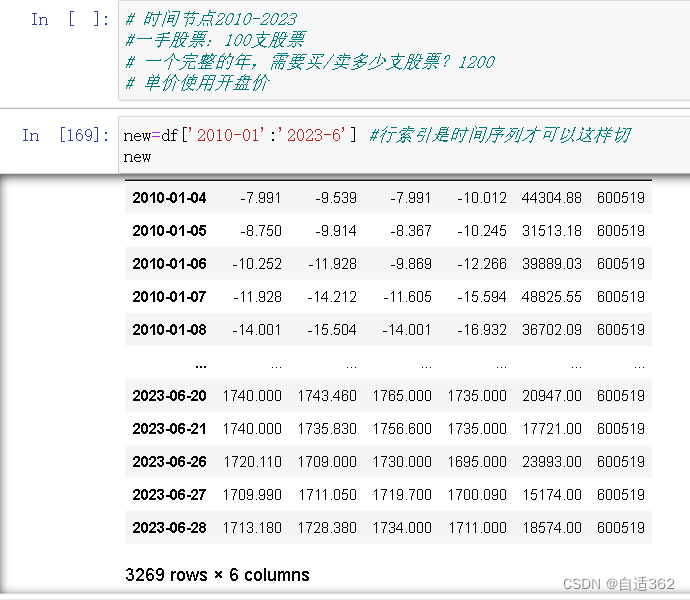
# 时间节点2010-2023
#一手股票:100支股票
# 一个完整的年,需要买/卖多少支股票?1200
# 单价使用开盘价
new=df['2010-01':'2023-6'] #行索引是时间序列才可以这样切
new
# 获取每个月的第一个交易日——使用 数据的重新取样技术
# 根据月份从原始数据中提取每月第一个交易日
the_first=new.resample('M').first()
the_first
the_first['open']
3.4 DataFrame 数据清洗
出现的情况
(1)丢失的数据
有两种丢失数据
None对象类型
np.nan浮点类型

两者 的区别

(2)处理空值的操作
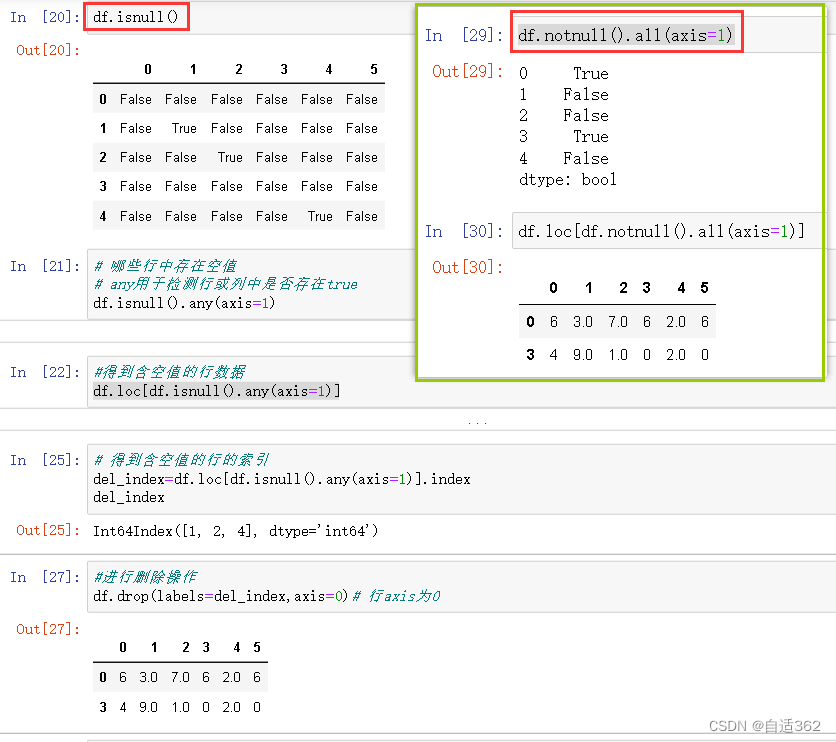
删除空值所在的行
不能删除列,只能删除行。
需使用到isnull ,notnull ,any ,all
df.drop()dd的使用>


dropna一步到位

对缺失值(空值)进行覆盖
当删除的成本过高时,选择覆盖

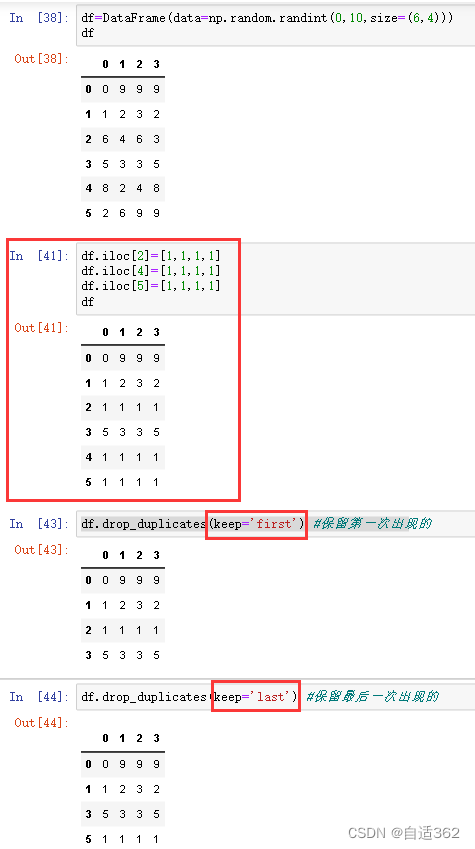
(3)处理重复数据drop_duplicates
(4)处理异常数据

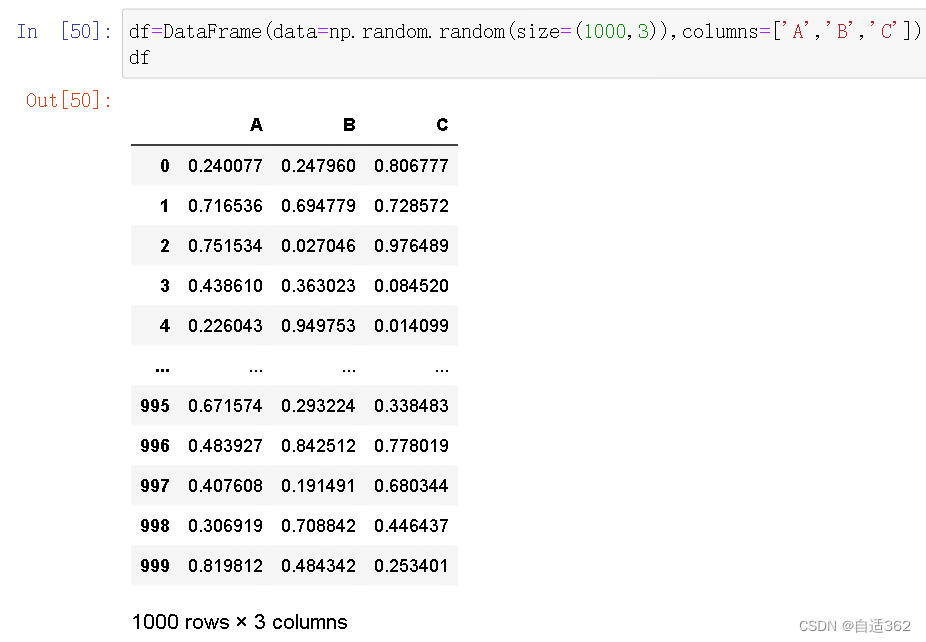
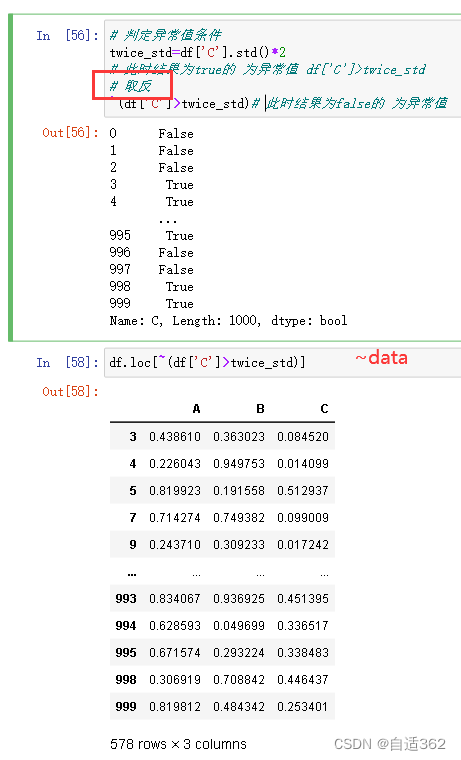
(5)级联操作
不匹配级联时,若想保留数据的完整性,必须使用outer(外级联)

进行横向或纵向拼接
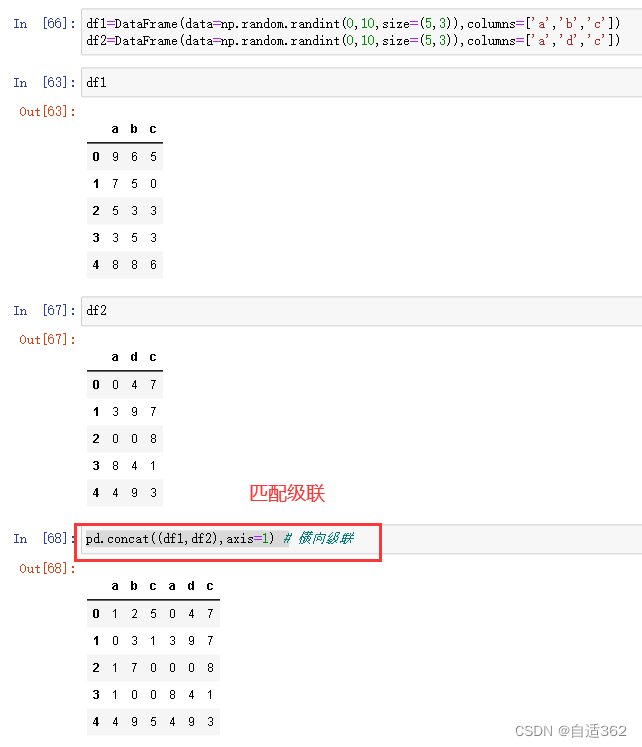

append 只能是外级联
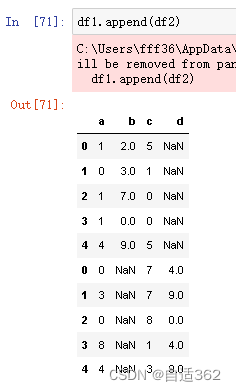

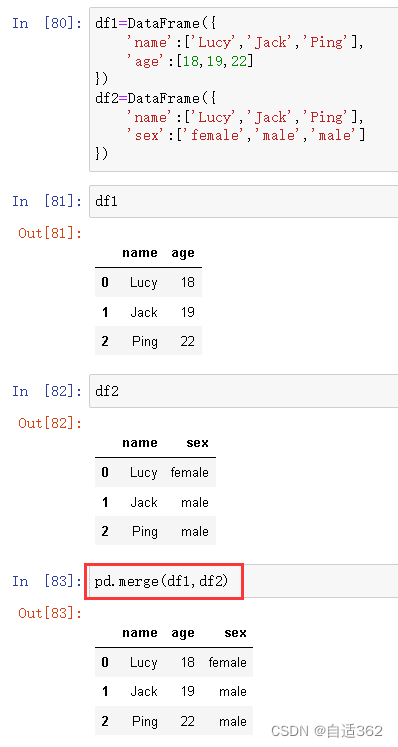
(6)合并!!
是对数据的合并
级联就只是做拼接
级联可以拼接多张表,合并只能对两个表进行操作

上方红圈处,与下方相同
on='name'默认就是相同列

3.5人口分析小项目~

3.6 替换操作


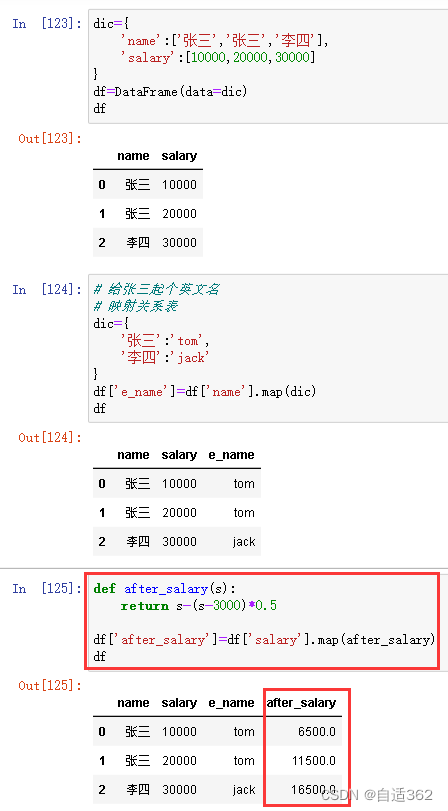
3.7 map——映射&运算工具

注意!!!
map是Series的方法,只能被它调用。
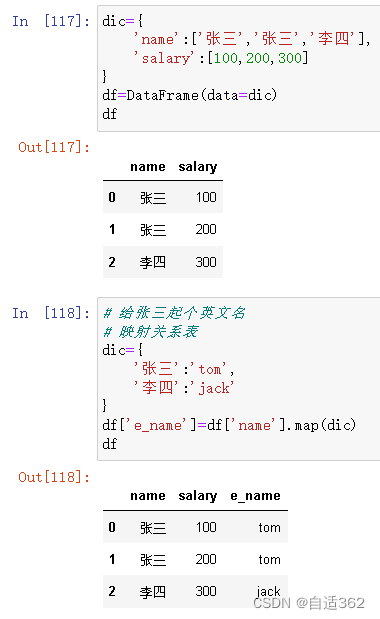
map充当运算工具
3.8 随机抽样

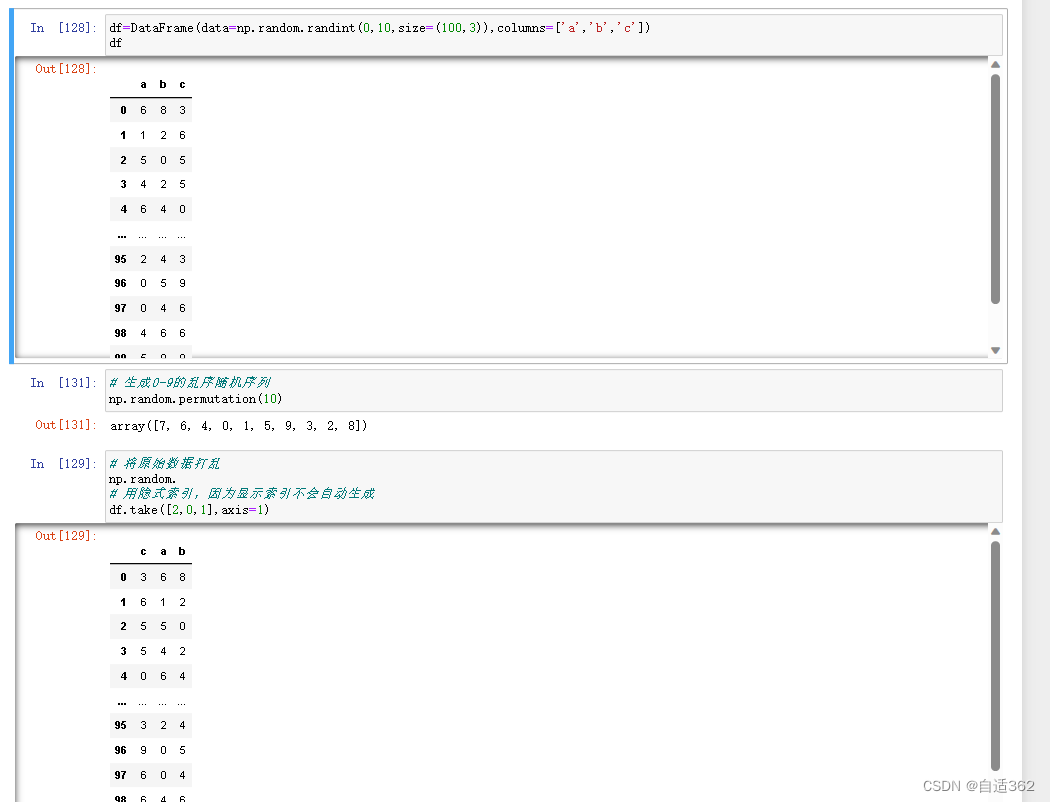
将原始数据随机打乱(按列打乱)

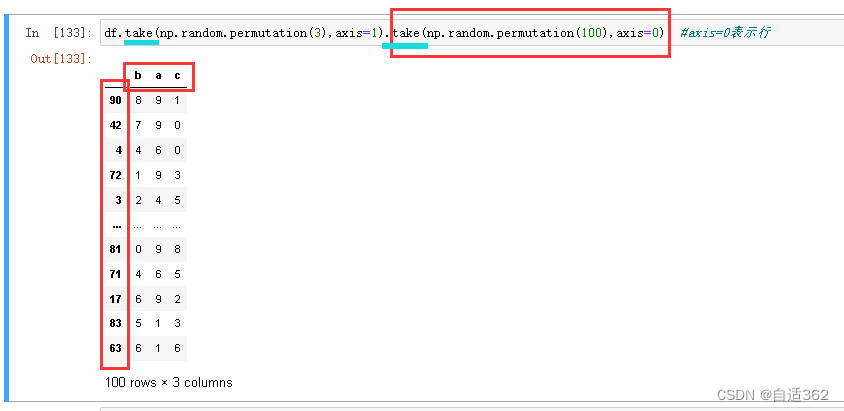
随机抽样

3.9 分组聚合
分组
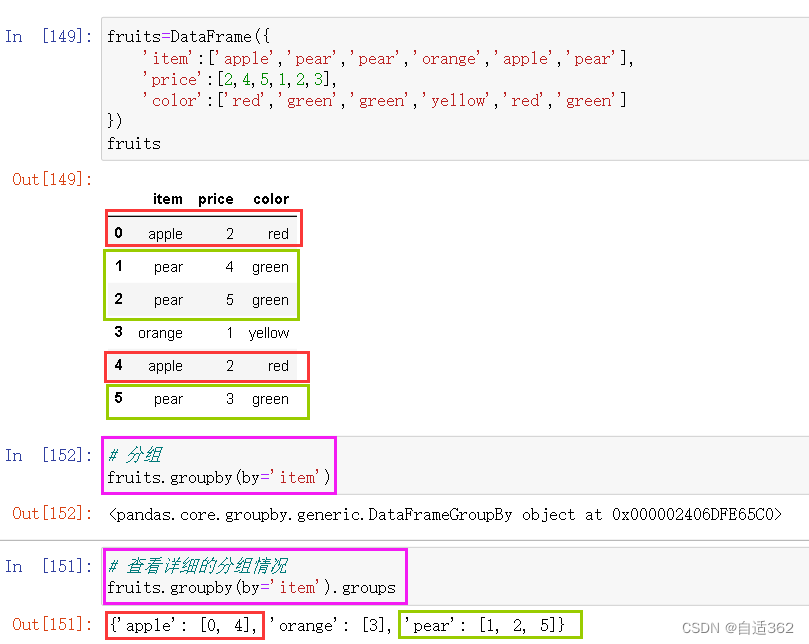
分组聚合

!!!!!!
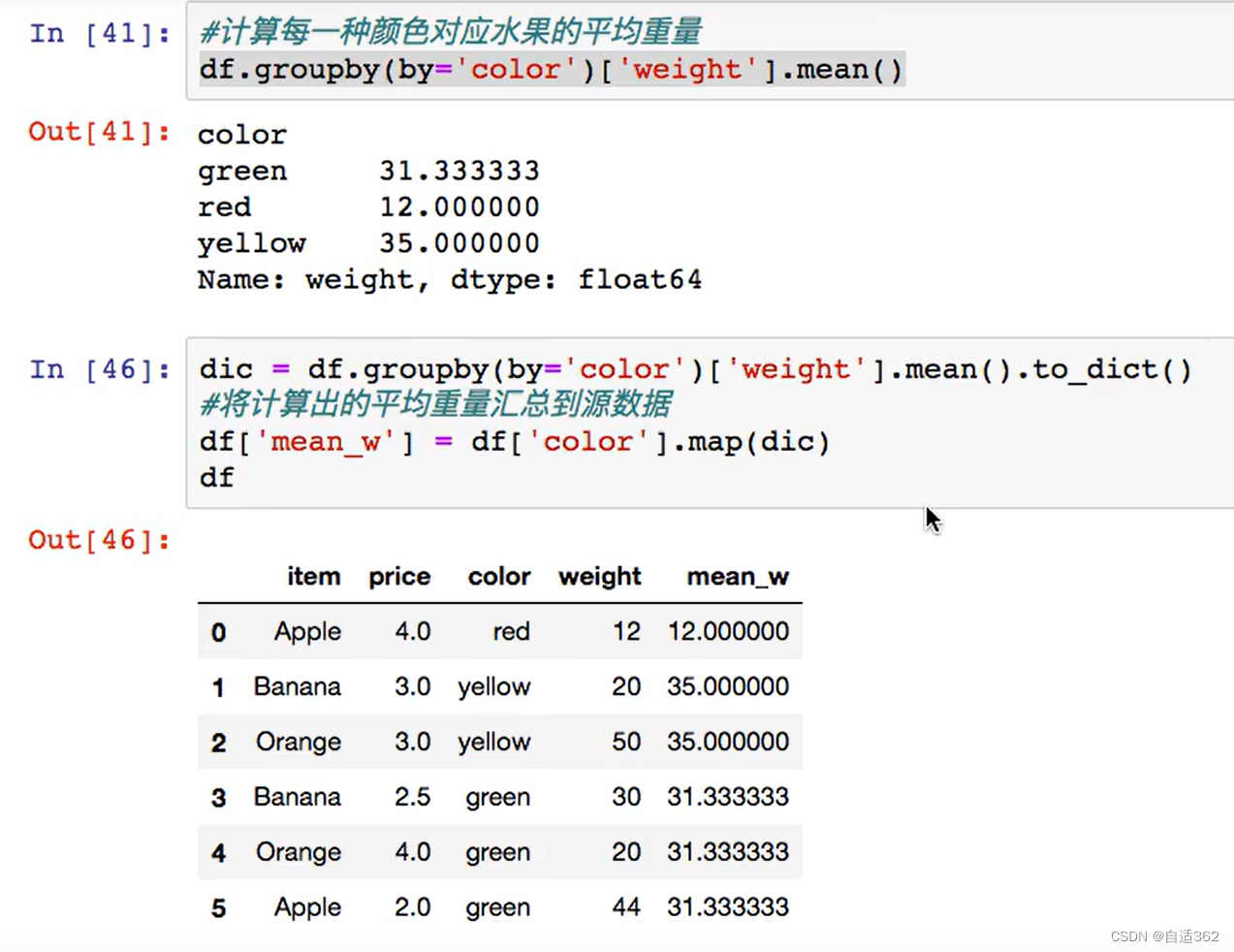
高级数据聚合
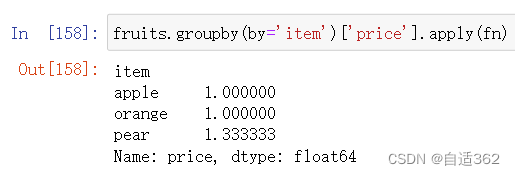
分组聚合后,根据自定义函数(方法),完成特地功能。

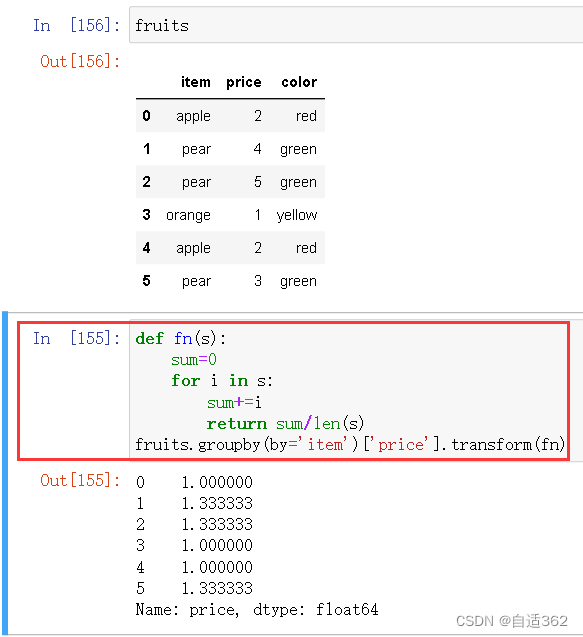
3.10 !!透视表和交叉表——26集

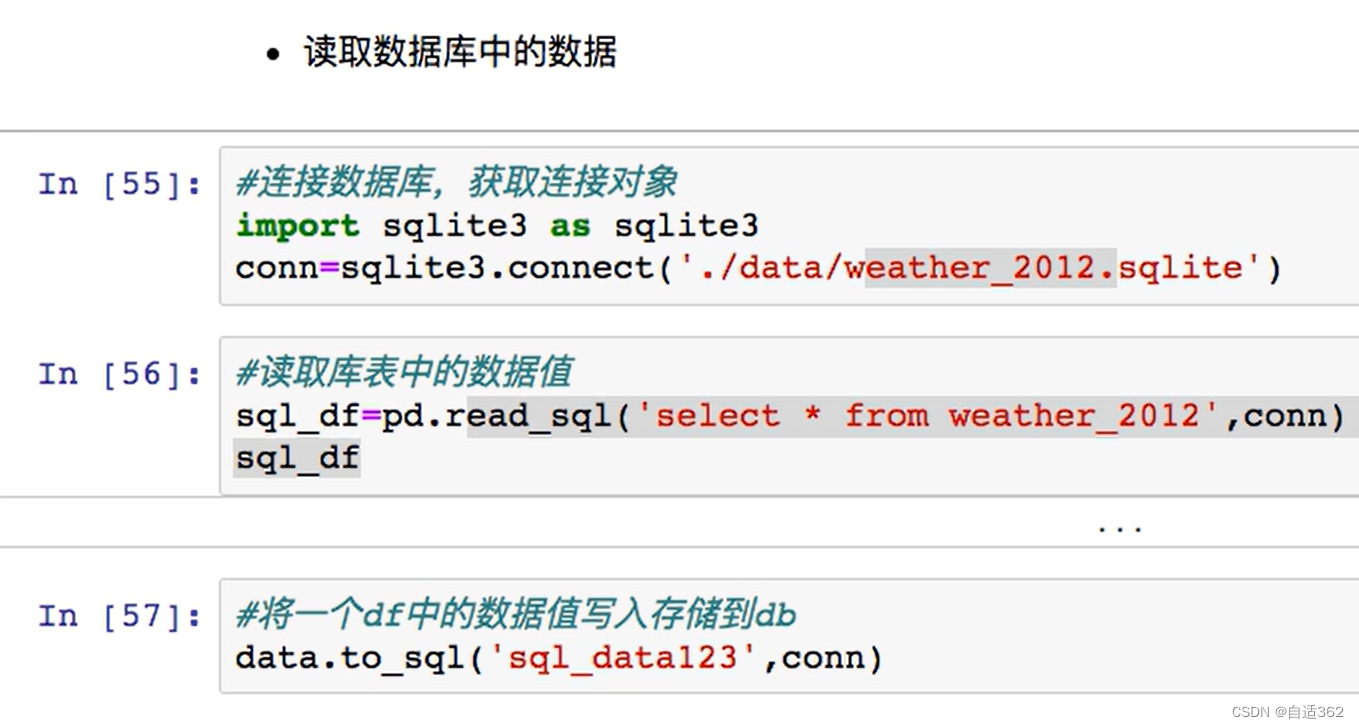
读取数据库中的数据
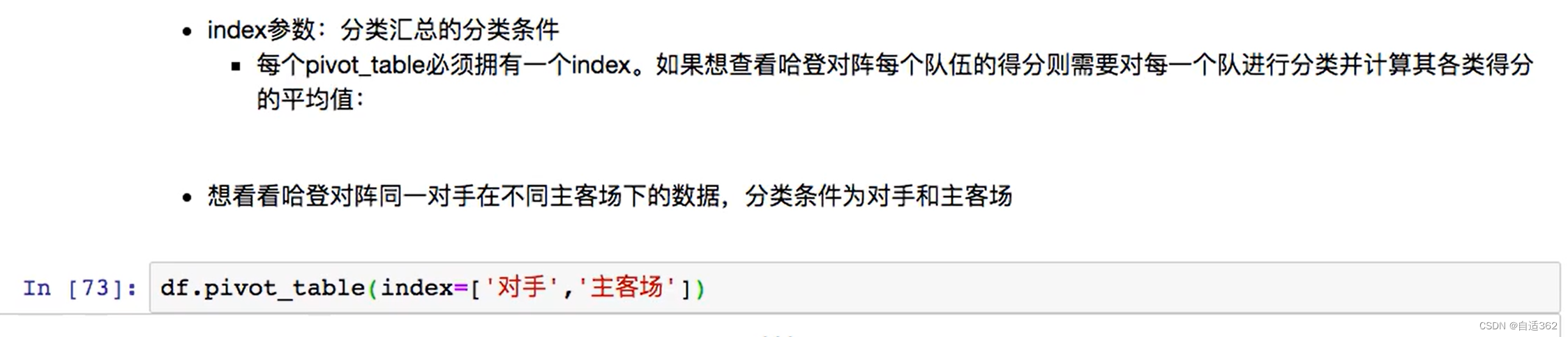
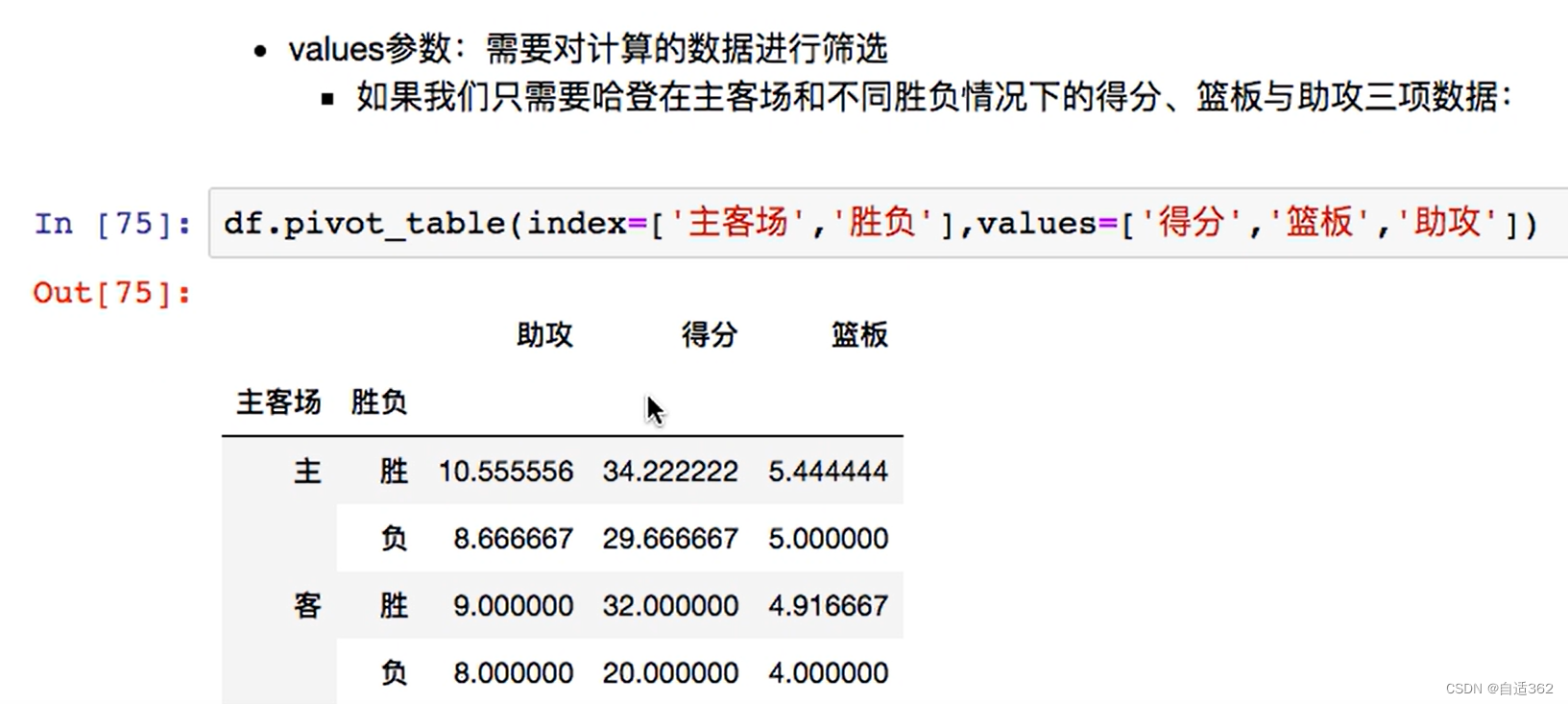
(1)透视表
 主要做分类汇总
主要做分类汇总

3.11 !!美国大选献金项目数据分析

四、Matplotlib
4.1 绘制线形图

绘制多条线形图(两种方法)
(1)设置坐标系比例
figure的调用一定要放在绘图之前,否无效果
坐标轴刻度不发生改变
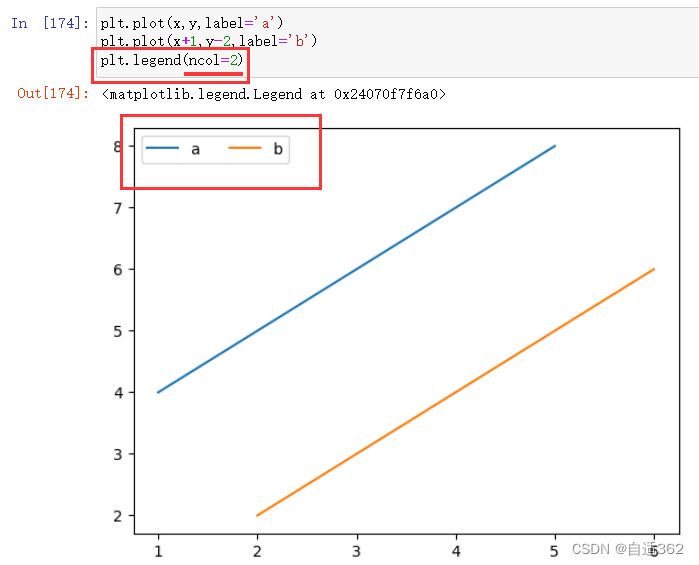
(2)设置图例
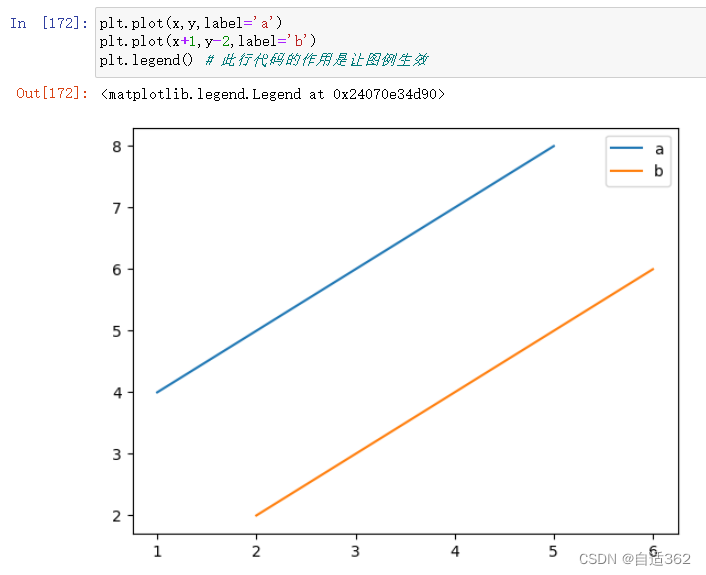
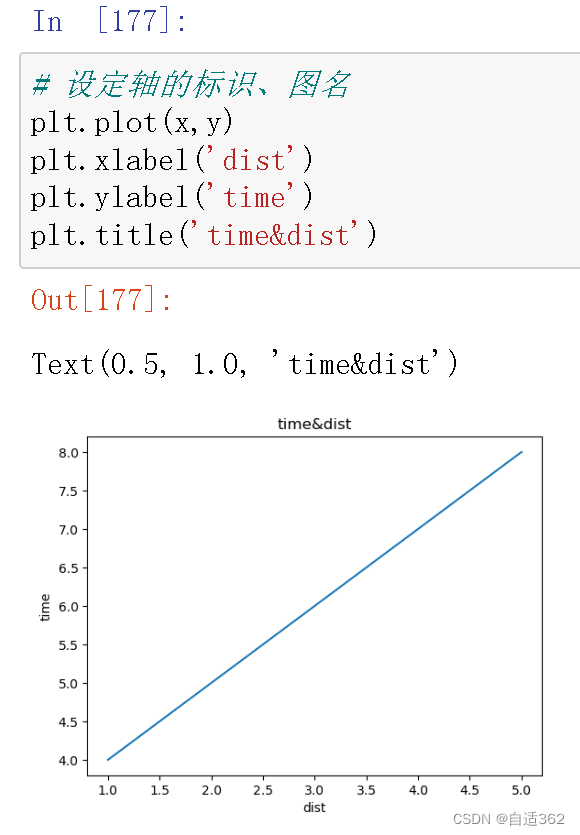
(3) 设定 轴名、图名
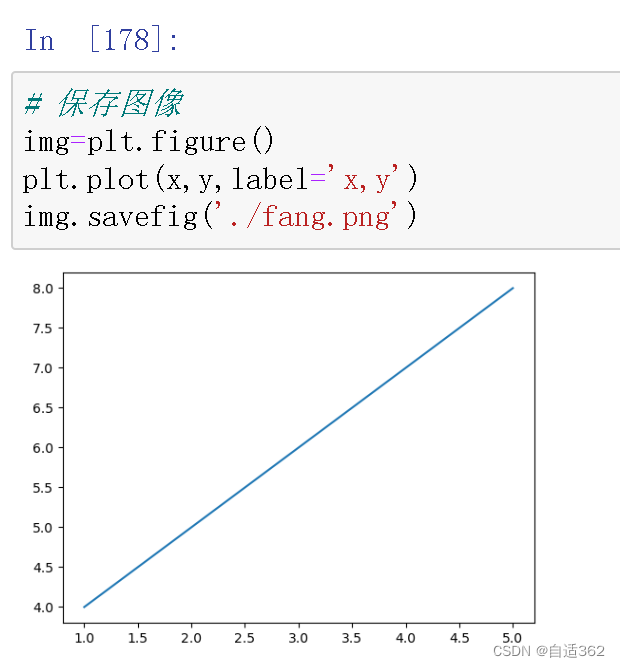
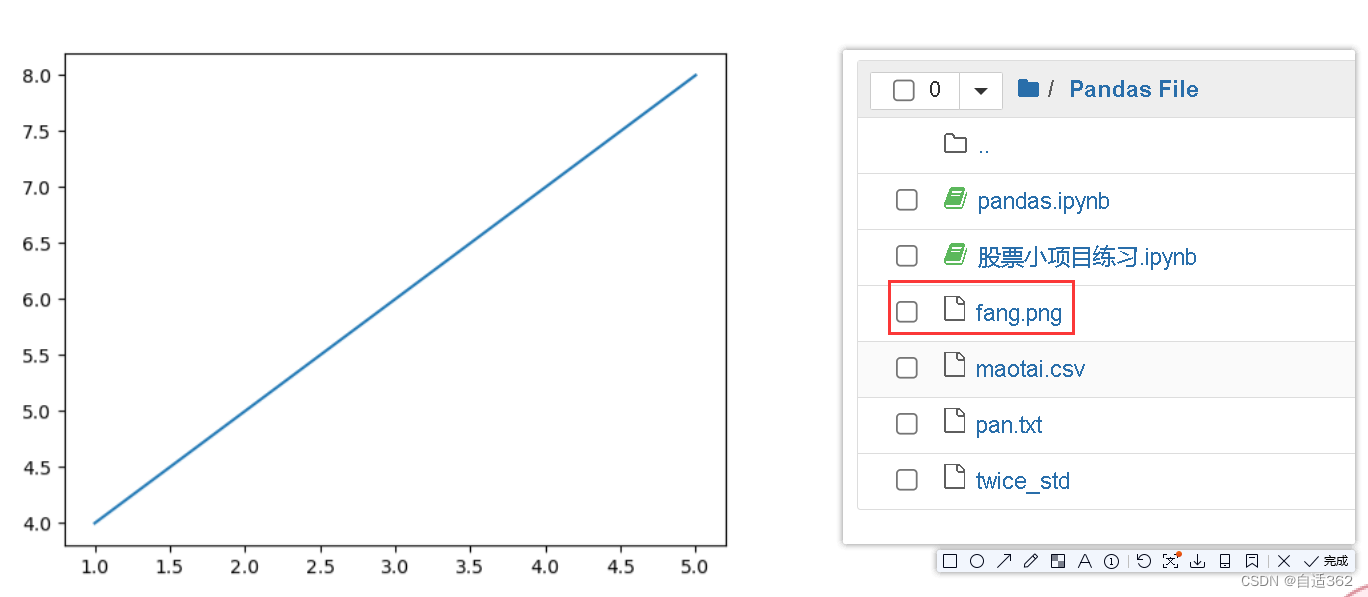
(4) 图像的保存
(5) 曲线的风格和样式
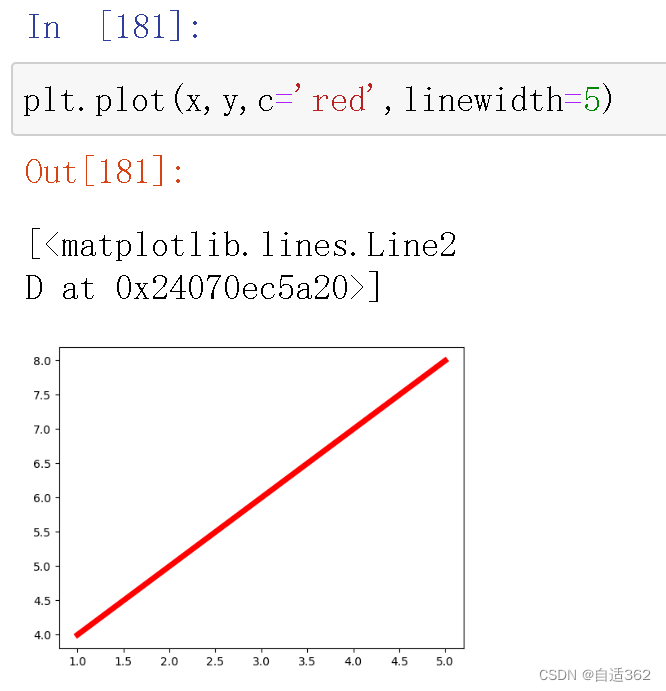
4.2 柱状图
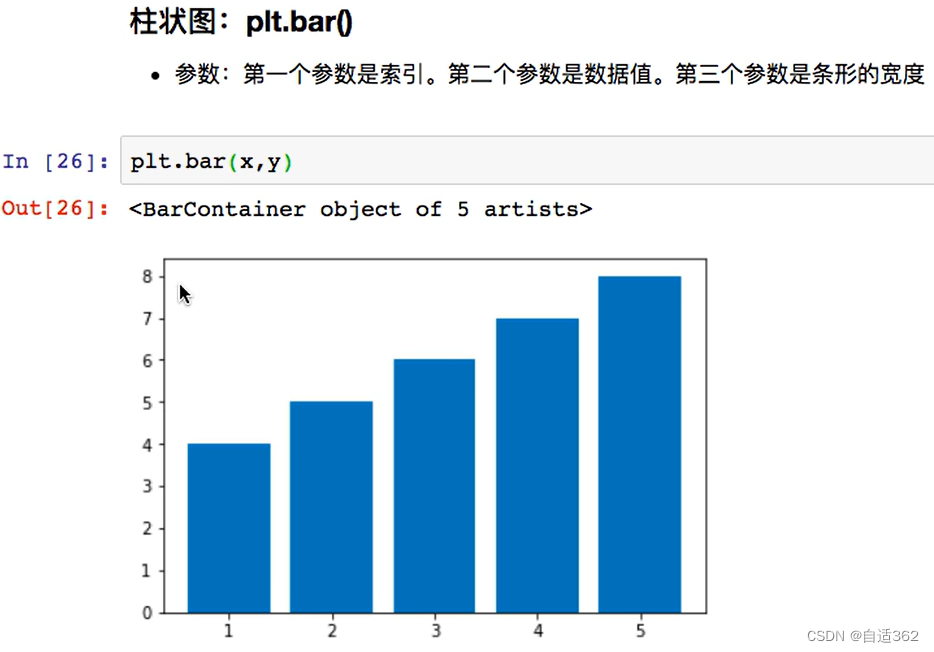
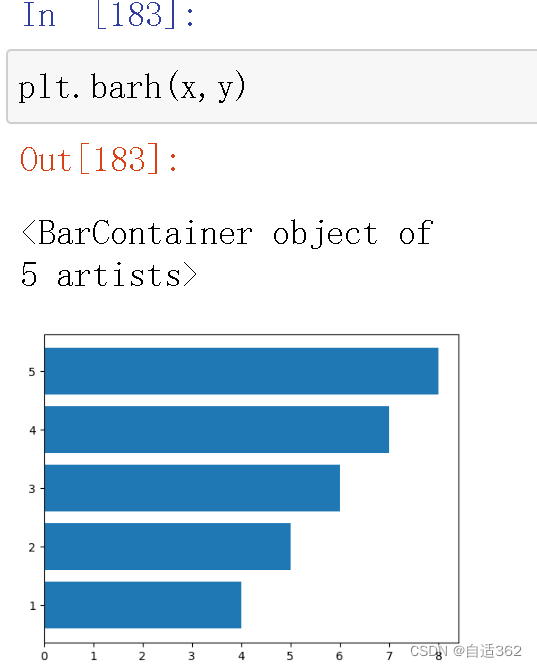
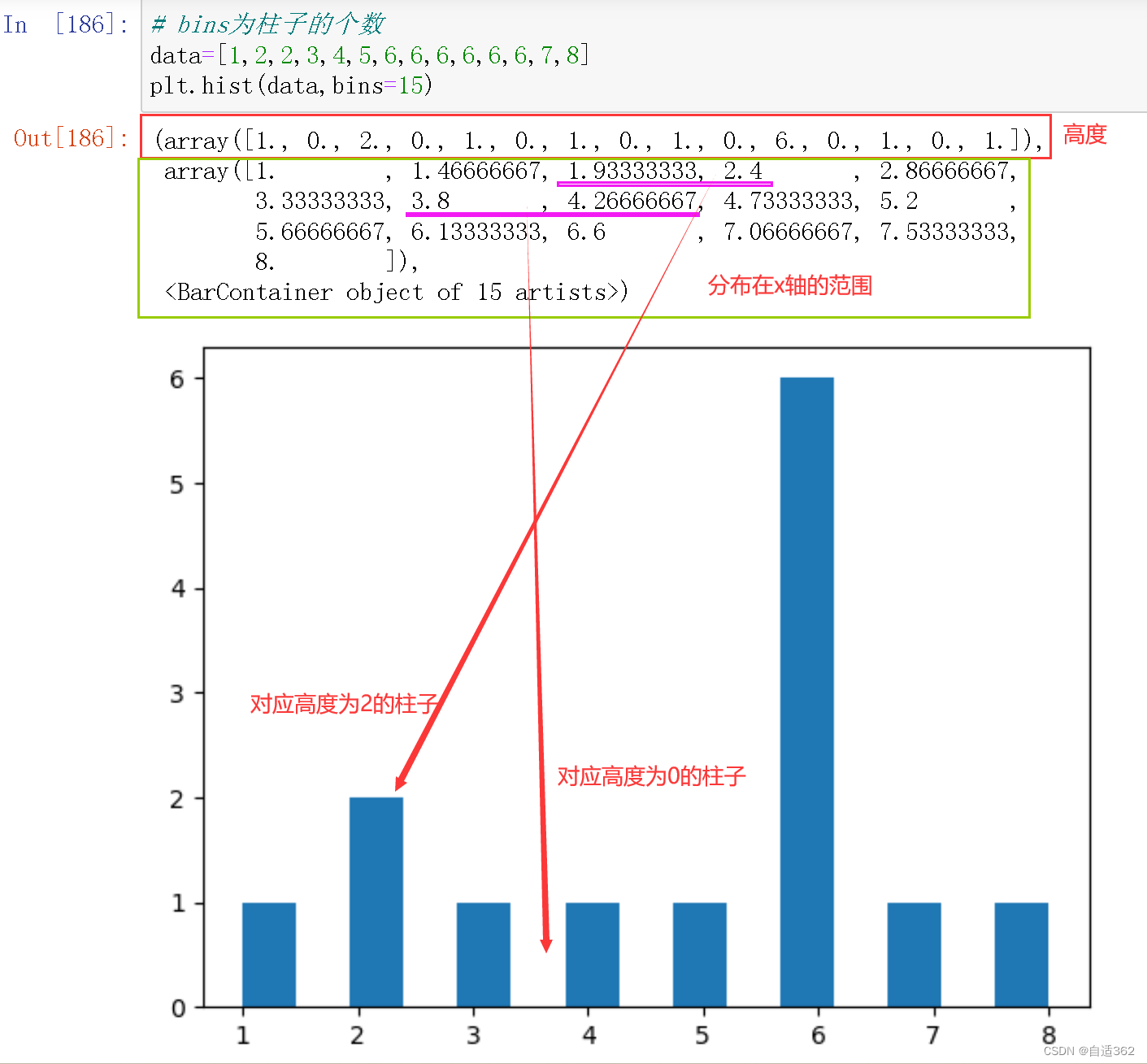
4.3 直方图

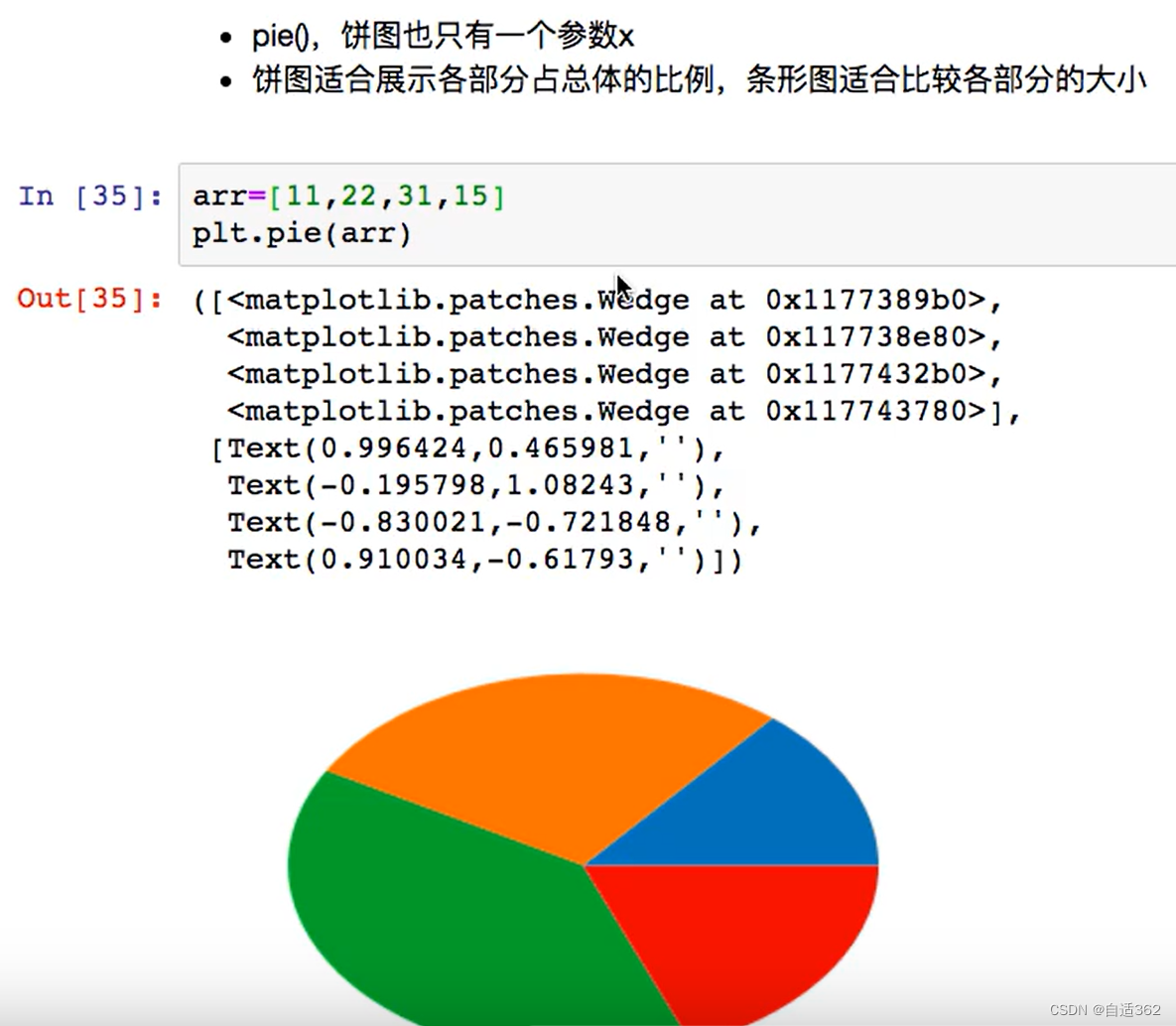
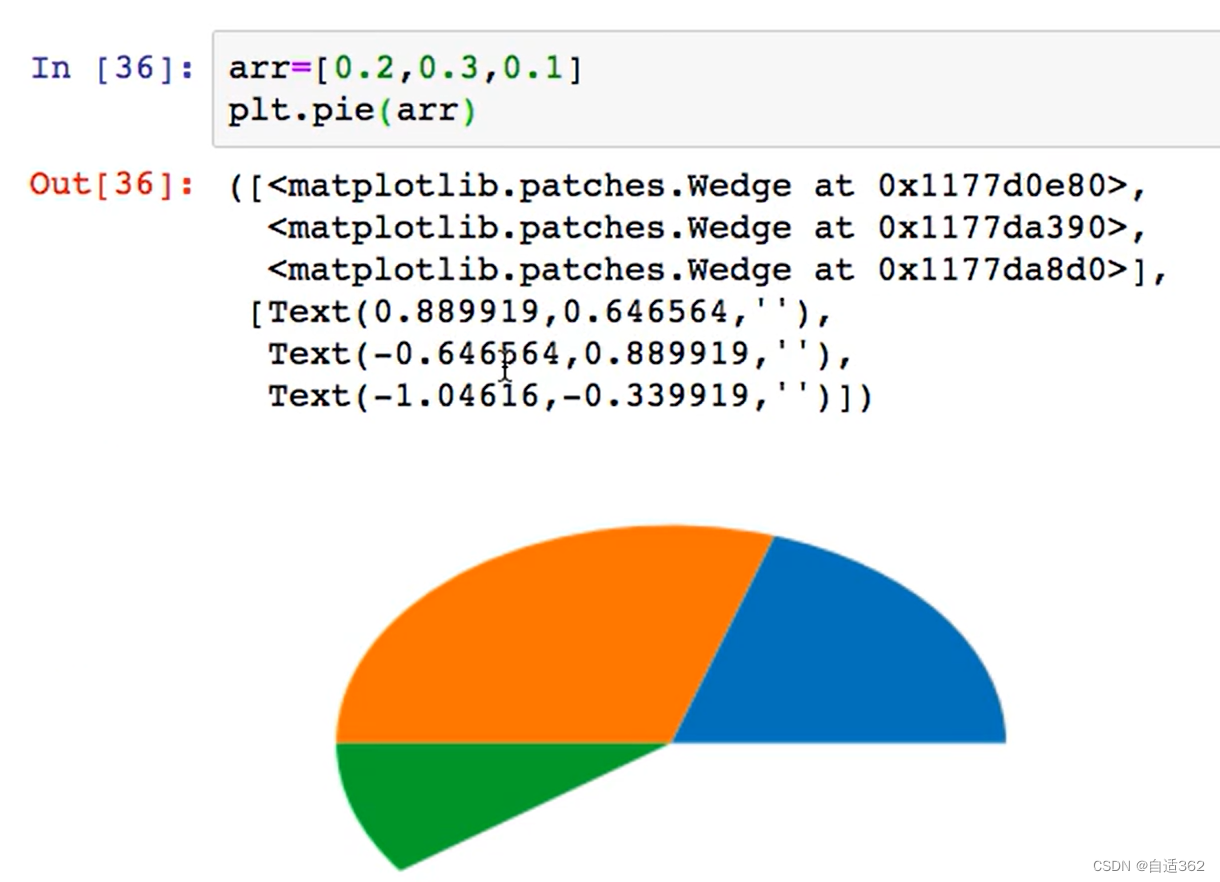
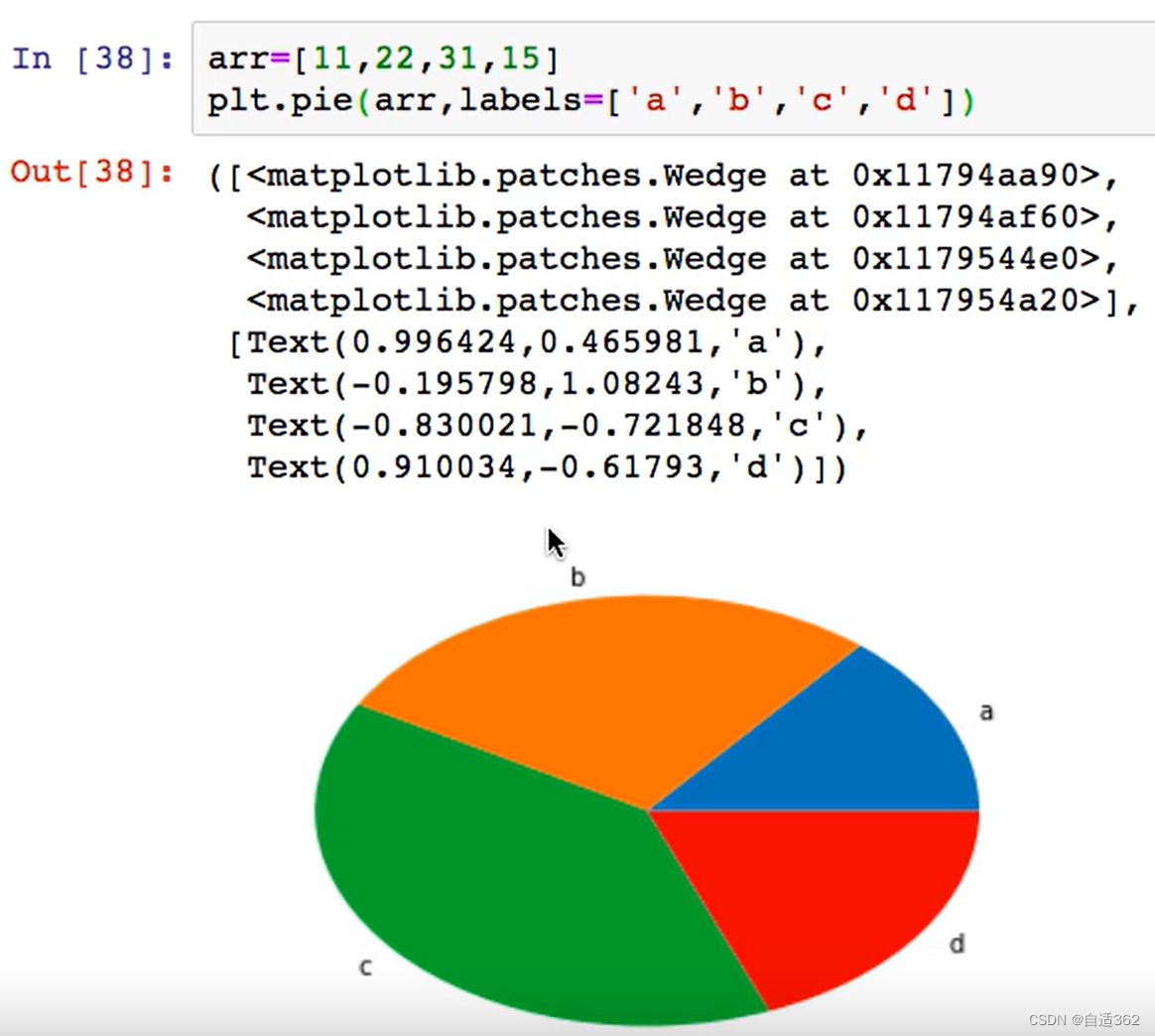
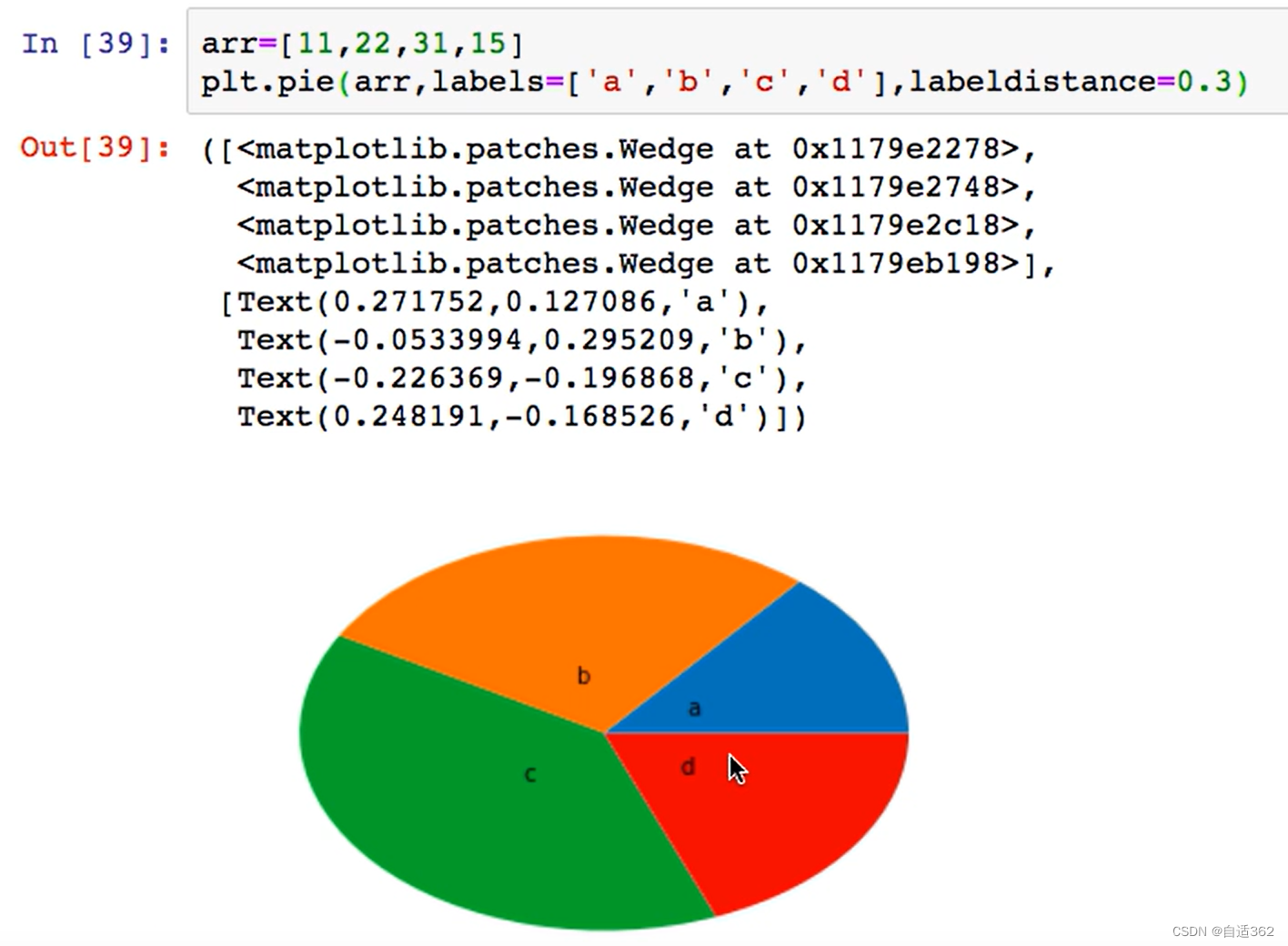
4.4 饼图

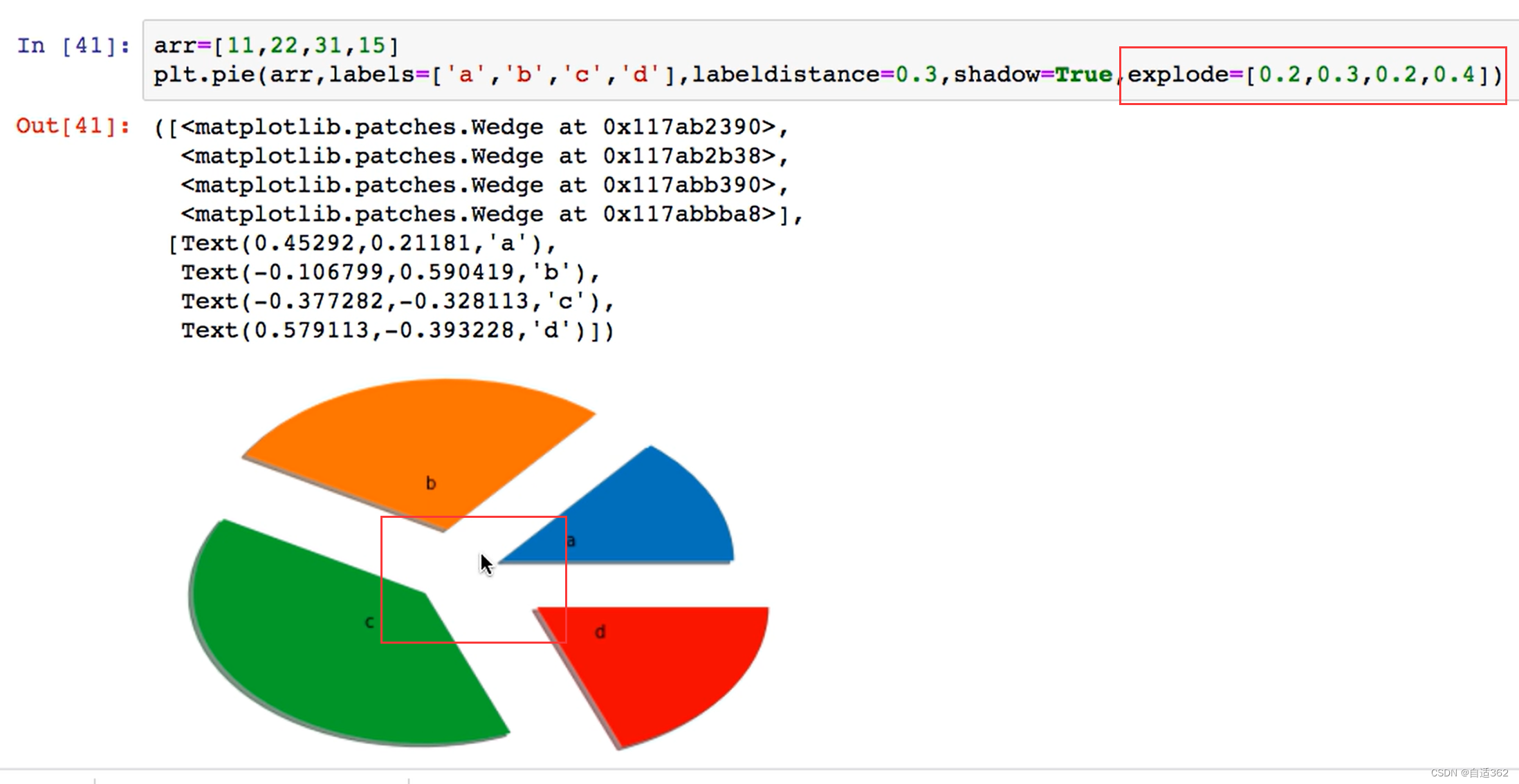
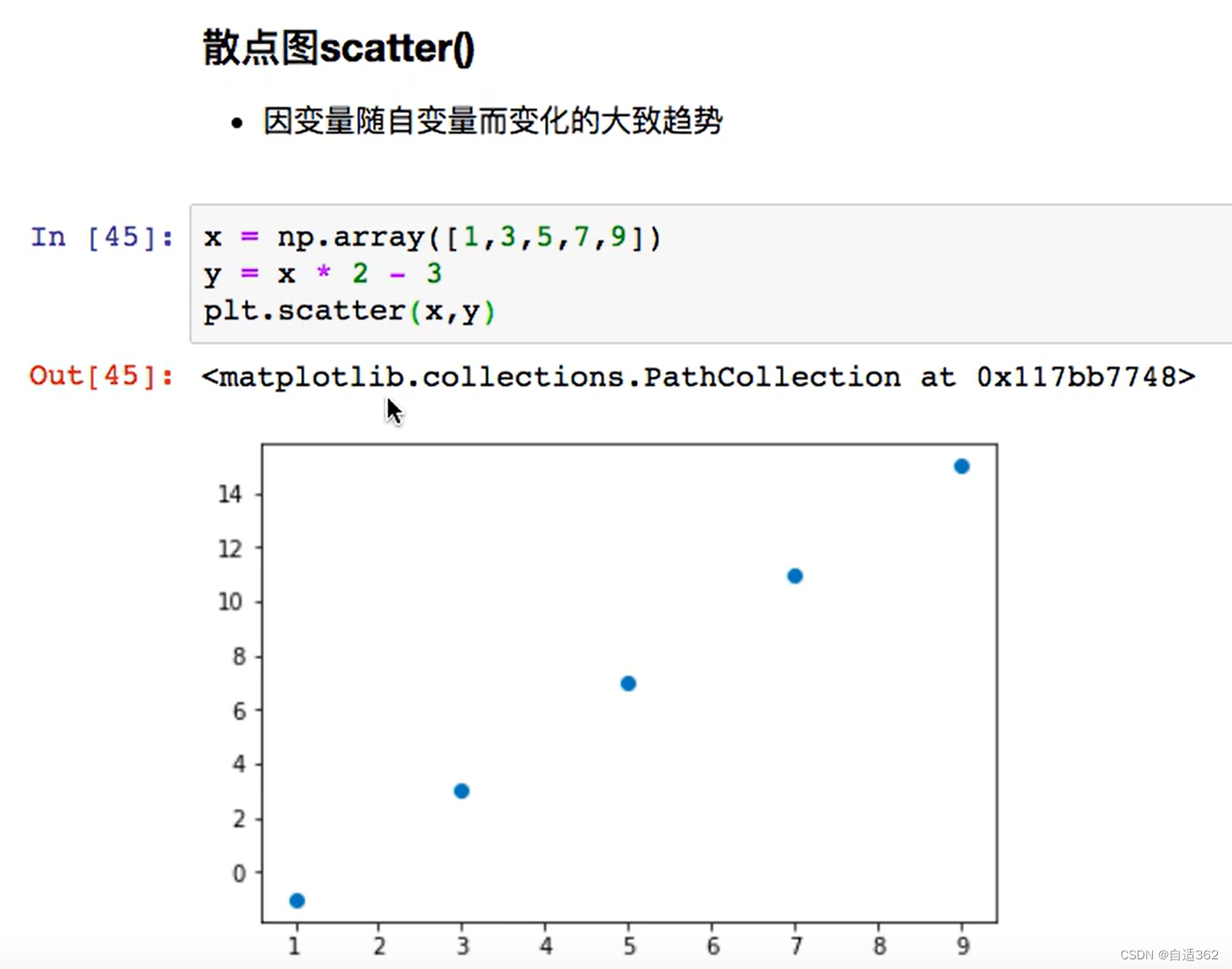
4.5 散点图