欢迎关注公众号 – AICV与前沿
欢迎关注公众号 – AICV与前沿

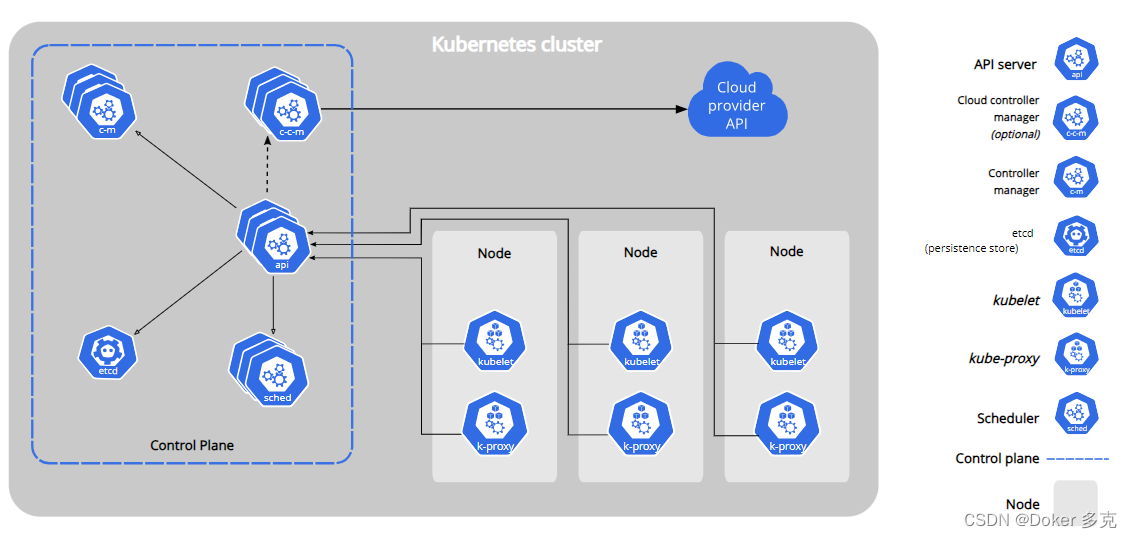
回顾
(1)Depthwise与Pointwise卷积
DW卷积的一个卷积核负责一个通道,例如对一个3×5×5的图片,输出通道数要与输入通道数相同,则普通卷积操作需要3×3×3×3的卷积核,但DW卷积操作只需要3×3×3的卷积核。
PW卷积相反,是一个1×1×C的卷积核,对每个通道的相同位置进行加权和,C为输入特征图的通道数,若输出通道数为5,则卷积核shape为C×1×1×5。
用DW+PW代替普通卷积,可以减小计算量。
(2)GhostNet
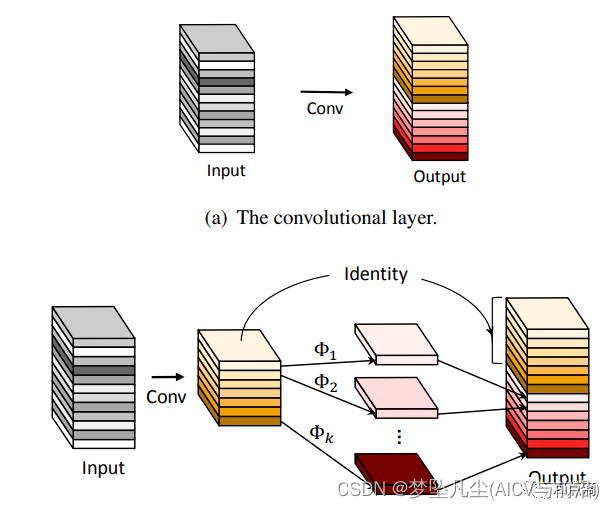
Ghost 模块:普通的卷积过程

这里的线性变换是通过DW实现的,上面的两步过程就是先利用PW进行卷积操作,再利用DW进行卷积操作。
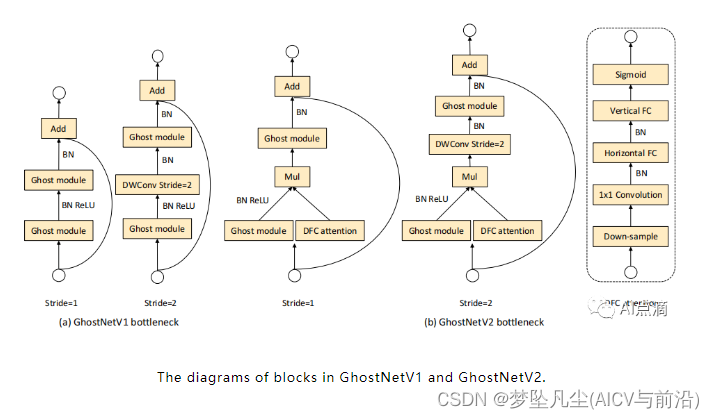
GhostNetV2
GhostV2的主要工作就是在Ghost module的基础上,添加了一个改进的注意力块。文中称为解耦全连接注意力机制DFC(Decouplod fully connected)。
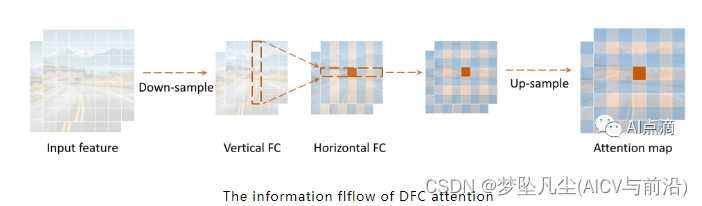
对图片进行HW次element-wise操作,改为分成列和行,分别对列进行W次对行进行H次操作。则计算量就从H×W×H×W变为H×W×H+W×H×W次。论文中FC操作通过DW卷积实现。
在原始的 Self-attention 中,每个 patch 的注意力值的计算涉及所有 patch。而在 DFC 中,每个 patch 的注意力值的计算直接与它水平或垂直位置的 patch 有关,而这些水平或垂直位置的 patch 的计算又与它们水平或垂直位置的 patch 有关。因此每个patch的注意力值的计算也一样涉及到所有 patch。
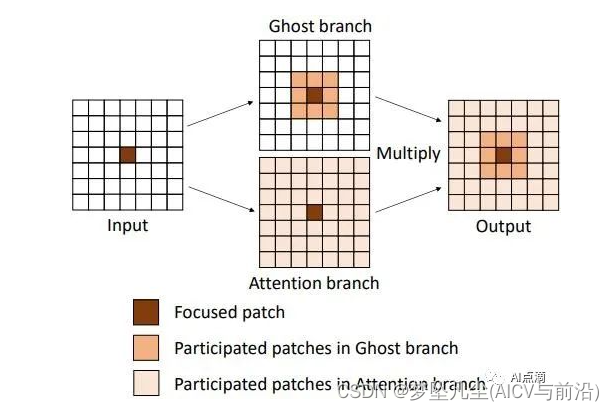
DFC attention 实现的 GhostNet 称之为 GhostNetV2。DFC attention 是为了配合 Ghost 模块使用, 以捕捉长距离空间位置的依赖关系。具体而言, 对于输入特征 X, 它被送到2个分支里面, 一个是 Ghost 分支, 得到输出特征 Y, 一个是 DFC 分支, 得到注意力矩阵A
, 在典型的 Self-attention 中, 常用到 linear transformation。所以作者在这里也使用1 × 1卷积, 将模块的输入X转化成 DFC 的输入Z。最终输出是将两个分支的结果进行点乘。即:

Sigmoid的目的是将注意力矩阵的输出结果标准化到(0, 1)之间, 信息的流动过程如下。
GhostV2 bottleneck 的示意图如下,DFC 注意力分支与第一个 Ghost 模块并行,通过点积合并,以增强扩展的特征。然后,增强后的特征被输入到第二个 Ghost 模块,以产生输出特征。它捕捉到了不同空间位置的像素之间的长距离依赖性,增强了模型的表达能力。
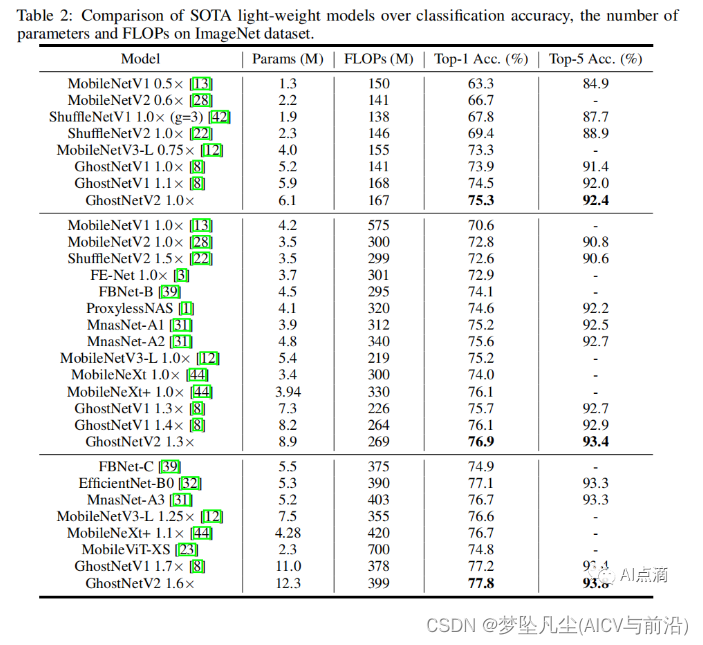
实验结果