RDD 是什么?
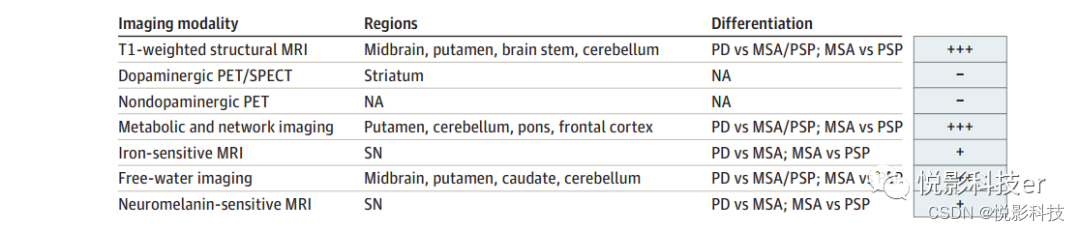
官网描述
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable,
partitioned collection of elements that can be operated on in parallel
RDD 是三个单词的首字母缩写,它表示弹性分布式数据集,是 spark 最基本的数据抽像,代表一个不可变、可分区、里面元素可以被并行操作的集合。
- DataSet 表示它是一个集合,里面存储了很多数据。
- Distributed 说明数据是分布式存储,数据拆分成小块存储在不同的物理机上,后方便后期进行分布式并行计算。
- Resilient (弹性)表示RDD 的数据可以保存在内存中或者是磁盘中。自己可以设置,默认保存在内存。
RDD 五大特性
(1) - A list of partitions
(2) - A function for computing each split
(3) - A list of dependencies on other RDDs
(4) - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
(5) - Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
-
一组分区列表的集合,即一个 RDD 中包含多个(数据)分区。后期 spark 任务执行RDD时,将一个分区划分为一个 task ,多个 task 并行执行。
-
作用在每一个分片(分区)上的函数。代码中开发者只写了一行操作语句,等真正执行时,该函数会在 RDD 的每个分区上都执行一遍。
-
一个 RDD 会依赖其他多个 RDD,上下 RDD 的依赖关系形成血统(lineage)。spark 任务的容错机制就是根据这个特性而来的。
-
(可选项)针对 kv 类型的 RDD 才有分区函数(必须产生 shuffle),如果不是 kv 类型的 rdd,它的分区函数是 None,表示没有。
在 spark 中有两种分区函数:
第一种:HashPartitioner 函数,对 key 去 hashcode 值,然后对分区数取余获取分区号。【默认使用这种】
第二种:RangePartitioner 函数,它是按照一定的范围进行分区,相同范围的 key 会进入到同一个分区中。
-
(可选项)一组最优的数据块位置列表,数据的本地性,数据的位置最优。spark 任务计算会优先考虑存有数据的节点来开启计算任务,即数据在哪里,计算任务就放在那里,这样就减少了网络传输,提升性能。
RDD 的算子分类
RDD 算子主要分为两种类型:
- transformation(转换)
- 它可以实现把一个 RDD 转换成另一个 RDD,程序在执行到这种类型的 RDD 代码时只是构建依赖(血统)关系,不会触发真正的运算操作。(这跟面向硬件编程、tensorflw 的风格有点像,先画“图”再触发执行)
- 比如:flatMap、map、reduceByKey。
- action(动作)
- 它会出发真正的执行,按照前面画的“图”执行。
- 比如:collect、saveAsTextFile
RDD之间的依赖关系
两种依赖关系:宽依赖和窄依赖。
窄依赖:父 RDD 的 partition 最多只被子 RDD 的一个 partition 所使用(一对一,多对一)。比如 map、filter、flatMap 等算子操作。
宽依赖:子 RDD 多个 partition 数据会依赖于父 RDD 的同一个 partition 分区数据(一对多)。比如:reduceByKey、groupByKey、sortByKey等算子。
窄依赖不会产生 shuffle,宽依赖会。
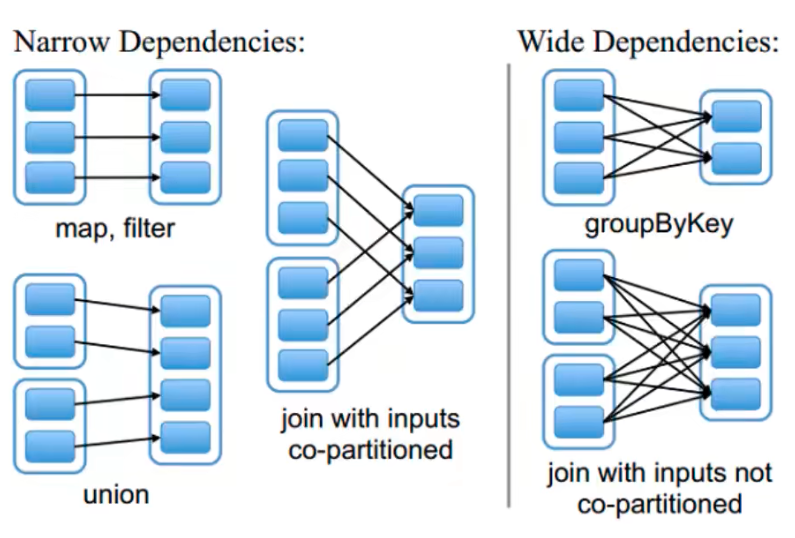
代码中 rdd 之间的依赖关系形成了血统(lineage)。如果某个 RDD 的分区数据丢失后,可以通过血统关系重新计算来恢复得到丢失部分的分区数据。
什么是 shuffle
简单来说,shuflle 过程就是将分布在集群多个节点上的同一个 key 拉取到同一个节点上,进行聚合活 join 等操作。比如 reduceByKey、join 等算子,都会触发shuffle 操作。在 shuffle 过程中,各节点上的相同 key 都会先写入本地磁盘中,然后其他节点需要通过网络传输拉取各个节点上磁盘文件中相同的 key。而且相同 key 拉取到同一个节点上执行聚合操作时,还有可能因为一个节点上处理的 key 过多,导致内存不够存放,进而溢出写到磁盘上。因此在 shuffle 过程中会发生大量的磁盘 IO 和 网络 IO,这也是 shuffle 性能交差的主要原因。
RDD 的缓存机制
RDD 缓存是什么?
把 RDD 的数据保存在内存或者是磁盘中,后续需要使用该数据时可以直接从缓存中读取,避免了重复计算。
如何设置 RDD 缓存?
参考该链接的原则三
cache 和 persist 的区别?
cache 其本质是调用了 pesist 方法,它是把数据放入缓存中。persist 可以把数据存放在内存或者磁盘中,该方法可以传入不同的缓存级别,这些缓存级别都定义在 StorageLevel 中。
RDD 缓存怎么清除
方式一:系统自动清楚,当应用程序执行完成之后,缓存数据也就消失了。
方式二:手动清除,调用unpersist(true) 方法。
DAG 有向无环图的划分
Directed Acyclic Graph 它是按照程序中的 RDD 之间的依赖关系生成的一张有方向但无环的图。
1、为什么要划分 stage?
一个 job 任务中可能有大量的宽窄依赖,宽依赖会产生 shuffle 而窄依赖不会。划分完 stage 后,在同一个 stage 中只有窄依赖没有宽依赖,这些窄依赖是可以独立并行的。
2、如何划分 stage?
从最后一个 RDD 往前推,先创建一个 stage,它实际上是最后一个 stage。如果遇到窄依赖,就将该 RDD 加入 stage 中,如果遇到宽依赖就切开,重新创建新的 stage,继续往前推,直到最开始的 RDD。整个划分stage 的过程就结束了。
3、stage 如何执行?
stage 内部会根据数据分区划分成多个 task,spark 任务执行时,stage 之间按照前后关系依次执行,stage 内部的每个 task 执行自己分区上的数据,这些 task 并行执行相同的运算。
参考链接
https://www.bilibili.com/video/BV1AJ411R7rb/?p=11&spm_id_from=pageDriver&vd_source=8a9f7d97e5a2fbdbe8a4a83a47d251b9
https://tech.meituan.com/2016/04/29/spark-tuning-basic.html
![[Linux打怪升级之路]-文件操作](https://img-blog.csdnimg.cn/2290b3384ca74ebc8ba101f64ac3cde8.png)

![Matplotlib入门[06]——figures,subplots,axes和ticks对象](https://img-blog.csdnimg.cn/c352f158f3604891a5d527e574047cd7.png)