reduceByKey

源码
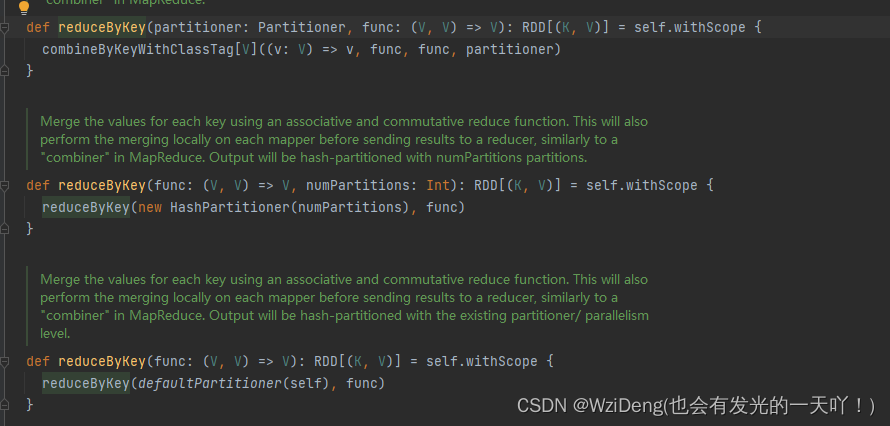
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce. Output will be hash-partitioned with numPartitions partitions.
*/
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] = self.withScope {
reduceByKey(new HashPartitioner(numPartitions), func)
}
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
实例演示
package spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object Spark15_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - (Key - Value类型)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
// reduceByKey : 相同的key的数据进行value数据的聚合操作
// scala语言中一般的聚合操作都是两两聚合,spark基于scala开发的,所以它的聚合也是两两聚合
// 【1,2,3】
// 【3,3】
// 【6】
// reduceByKey中如果key的数据只有一个,是不会参与运算的。
val reduceRDD: RDD[(String, Int)] = rdd.reduceByKey( (x:Int, y:Int) => {
println(s"x = ${x}, y = ${y}")
x + y
} )
reduceRDD.collect().foreach(println)
sc.stop()
}
}
总结
reduceByKey是一个RDD的转换操作,用于按键对RDD中的值进行聚合。它将具有相同键的值使用指定的聚合函数进行合并,返回一个新的RDD,其中每个键对应一个聚合结果。
reduceByKey的语法如下:
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
其中,func是一个接受两个相同类型的值并返回一个合并结果的聚合函数。它被应用于具有相同键的所有值。K表示键的类型,V表示值的类型。
使用reduceByKey的示例:
val rdd = sparkContext.parallelize(Seq(("a", 1), ("b", 2), ("a", 3), ("b", 4)))
val reducedRDD = rdd.reduceByKey((x, y) => x + y)
reducedRDD.foreach(println)
输出结果为:
(a, 4)
(b, 6)
在上述示例中,初始RDD rdd 包含了键值对的序列。通过应用reduceByKey操作,使用加法函数将具有相同键的值进行合并。最终得到的reducedRDD 包含了每个键对应的聚合结果。
需要注意的是,reduceByKey操作是按照键进行本地聚合,并且可以利用Spark的并行处理能力。它在进行全局聚合之前先在各个分区内进行本地聚合,从而减少了数据传输和Shuffle操作的开销。聚合函数应该满足结合律,以确保最终结果的准确性。
此外,还有一些其他的聚合操作可以用于键值对的RDD,如groupByKey、aggregateByKey和foldByKey,每个操作都有不同的特点和适用场景。根据具体的需求,选择合适的聚合操作可以提高代码的效率和性能。
groupByKey

源码
/**
* Group the values for each key in the RDD into a single sequence. Allows controlling the
* partitioning of the resulting key-value pair RDD by passing a Partitioner.
* The ordering of elements within each group is not guaranteed, and may even differ
* each time the resulting RDD is evaluated.
*
* @note This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using `PairRDDFunctions.aggregateByKey`
* or `PairRDDFunctions.reduceByKey` will provide much better performance.
*
* @note As currently implemented, groupByKey must be able to hold all the key-value pairs for any
* key in memory. If a key has too many values, it can result in an `OutOfMemoryError`.
*/
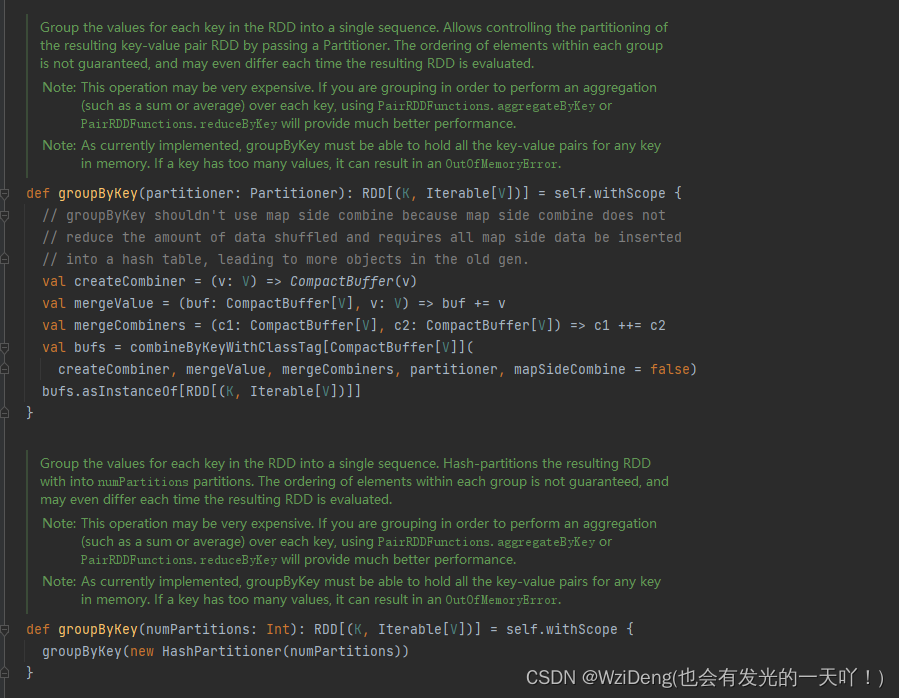
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
/**
* Group the values for each key in the RDD into a single sequence. Hash-partitions the
* resulting RDD with into `numPartitions` partitions. The ordering of elements within
* each group is not guaranteed, and may even differ each time the resulting RDD is evaluated.
*
* @note This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using `PairRDDFunctions.aggregateByKey`
* or `PairRDDFunctions.reduceByKey` will provide much better performance.
*
* @note As currently implemented, groupByKey must be able to hold all the key-value pairs for any
* key in memory. If a key has too many values, it can result in an `OutOfMemoryError`.
*/
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] = self.withScope {
groupByKey(new HashPartitioner(numPartitions))
}
实例演示
package spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark16_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - (Key - Value类型)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
// groupByKey : 将数据源中的数据,相同key的数据分在一个组中,形成一个对偶元组
// 元组中的第一个元素就是key,
// 元组中的第二个元素就是相同key的value的集合
val groupRDD: RDD[(String, Iterable[Int])] = rdd.groupByKey()
groupRDD.collect().foreach(println)
val groupRDD1: RDD[(String, Iterable[(String, Int)])] = rdd.groupBy(_._1)
sc.stop()
}
}
总结
groupByKey是一个RDD的转换操作,用于按键对RDD中的值进行分组。它将具有相同键的所有值放置在同一个分区,并将它们作为一个键值对序列返回,每个键对应于一个由该键的所有值组成的迭代器。
groupByKey的语法如下:
def groupByKey(): RDD[(K, Iterable[V])]
其中,K表示键的类型,V表示值的类型。
使用groupByKey的示例:
val rdd = sparkContext.parallelize(Seq(("a", 1), ("b", 2), ("a", 3), ("b", 4)))
val groupedRDD = rdd.groupByKey()
groupedRDD.foreach(println)
输出结果为:
(a, CompactBuffer(1, 3))
(b, CompactBuffer(2, 4))
在上述示例中,初始RDD rdd 包含了键值对的序列。通过应用groupByKey操作,将具有相同键的值进行分组,并返回一个新的RDD groupedRDD。groupedRDD中的每个键对应一个迭代器,包含了该键的所有值。
需要注意的是,groupByKey操作会导致Shuffle操作,因为它需要将具有相同键的值放置在同一个分区中。在处理大规模数据时,Shuffle操作可能成为性能瓶颈,因此需要谨慎使用。如果只是需要对具有相同键的值进行聚合操作,通常更推荐使用reduceByKey操作,因为它可以在分区内进行本地聚合,减少Shuffle操作的开销。
此外,groupByKey返回的值是一个键值对的RDD,其中每个键对应于一个迭代器。在对迭代器中的值进行处理时,需要谨慎处理内存使用,特别是当每个键的值很大时。可以使用mapValues等方法进一步处理每个键的值。
reduceByKey 和 groupByKey 的区别
当涉及到键值对RDD的聚合操作时,reduceByKey和groupByKey之间的区别如下所示:
-
数据传输和Shuffle操作的开销:
reduceByKey:在进行聚合操作之前,reduceByKey会在各个分区内先进行本地聚合,然后再进行全局聚合。它会将具有相同键的值进行合并,并通过并行化地在每个分区内进行本地聚合,从而减少数据传输和Shuffle操作的开销。groupByKey:groupByKey会将具有相同键的所有值都放置在同一个分区中,并将它们作为迭代器返回。这意味着所有具有相同键的数据都会经过Shuffle操作,不进行本地聚合。这可能导致大量的数据传输和高昂的Shuffle开销。
-
内存使用和性能:
reduceByKey:由于reduceByKey在每个分区内进行本地聚合,因此它可以更有效地利用内存,尤其是当数据集很大时。它通过将每个键的值进行迭代并应用聚合函数,产生一个最终的结果,因此输出的RDD的每个键都对应一个聚合后的值。这可以减少内存占用并提高性能,尤其在处理大规模数据时。groupByKey:groupByKey将具有相同键的所有值放入内存中的迭代器中,并将它们作为一个键值对序列返回。由于它不进行本地聚合,因此可能会占用大量内存。此外,如果每个键的值非常大,将所有值放入内存中可能导致OutOfMemoryError。此外,由于groupByKey返回的值是迭代器,因此需要遍历整个迭代器才能访问每个键的所有值。
3. 结果类型:
reduceByKey:reduceByKey的输出是一个具有唯一键和聚合值的键值对RDD,其中每个键对应于一个聚合结果。groupByKey:groupByKey的输出是一个键值对RDD,其中每个键对应于一个由该键的所有值组成的迭代器。因此,对于具有相同键的所有值,可能需要进一步操作才能得到聚合结果。
综上所述,如果目标是对键值对进行聚合操作,并且数据集很大,通常建议使用reduceByKey。它可以在分区内进行本地聚合,减少Shuffle操作的开销和内存使用。而groupByKey适用于需要获取具有相同键的所有值的场景,但要注意它可能占用大量内存并导致性能问题。
4.从 shuffle 的角度:
- reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而 groupByKey只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较高。
5.从功能的角度:
- reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用 groupByKey