Alibi:Attention With Linear Biases Enables Input Length Extrapolation
- Introduction
- Method
- Result
- 参考
Introduction
假设一个模型在512token上做训练,在推理的时候,模型在更长的序列上表现叫做模型的外推性。作者表明以前的位置编码如Sin、Rotary、T5 Bias 的外推性都随着推理长度的增加变得越来越差。基于此,坐着的提出了Alibi,如下图:
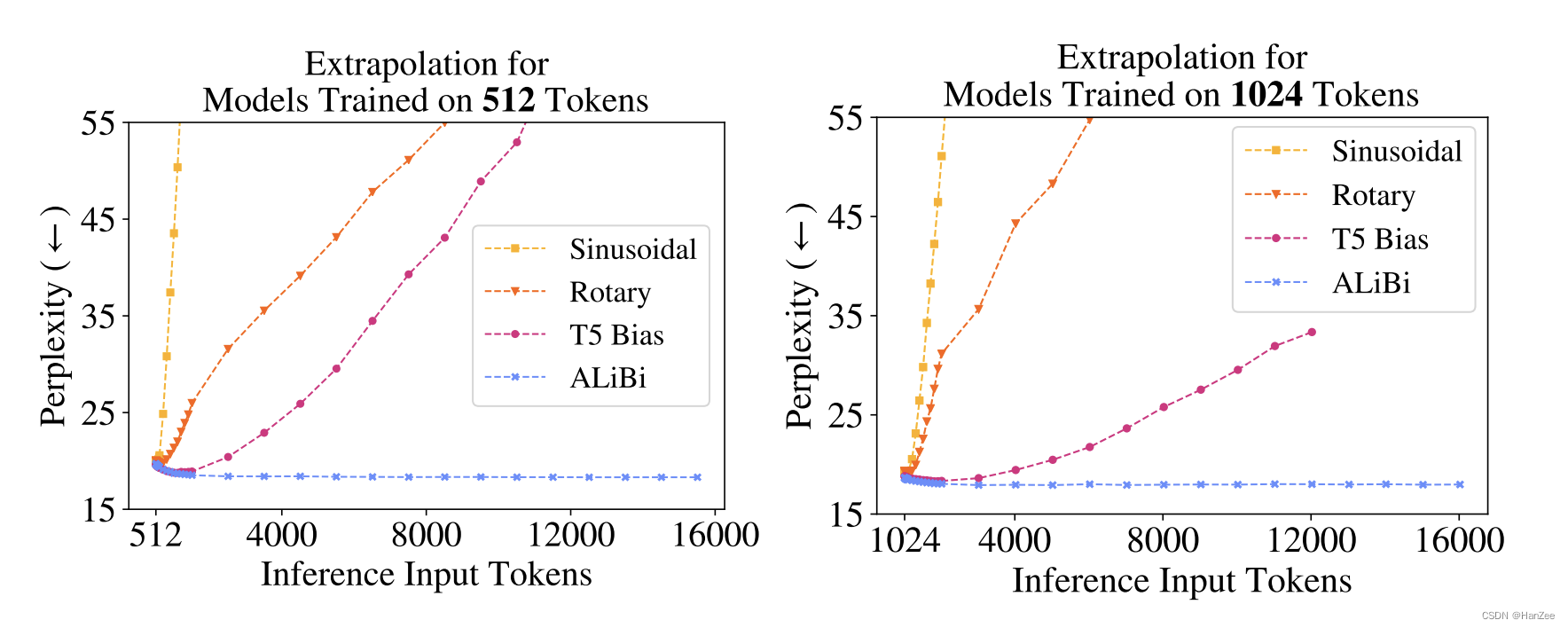
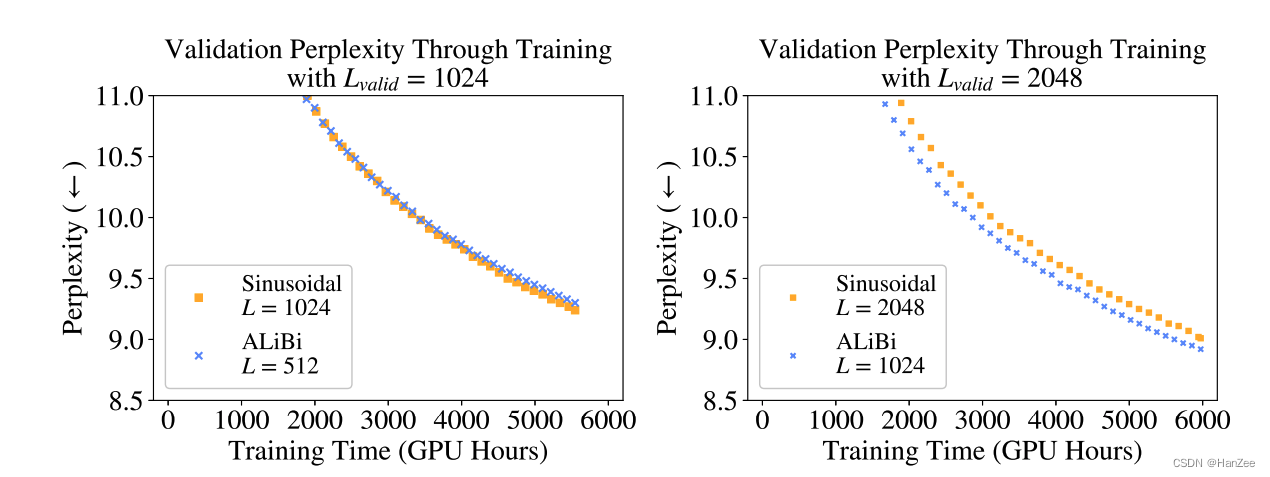
Alibi与其他位置编码相比,随着推理token长度的增加模型对token的困惑度基本不变。
同时,Ailibi在训练速度与推理速度上都比T5与Rotary要快,与Sin相当,内存占用上也要比前者少11%。

Method
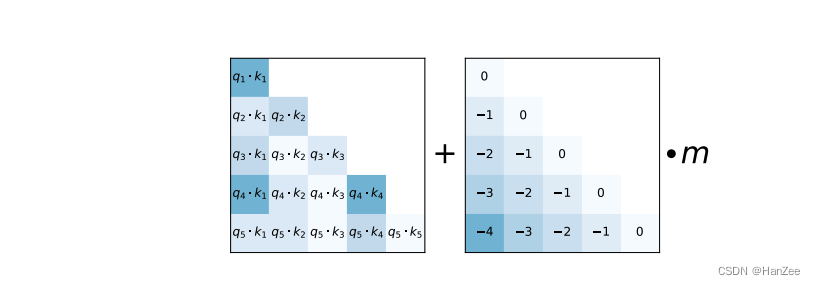
Alibi的方法十分简单,如上图,在计算 attention score的时候,会对以前的分数按照与当前的位置差距进行不同程度的惩罚。假设在计算q3与k3的attention时,q3还会考虑 k1,k2的attention,其中对q3k1就-2,对q3k2就-1。然后在乘上坡度m,其中作者发现m不需要根据不同数据选择不同的值,在使用的时候不变即可,m在不同的head上设置方法如下:

Result
参考
https://arxiv.org/pdf/2108.12409.pdf