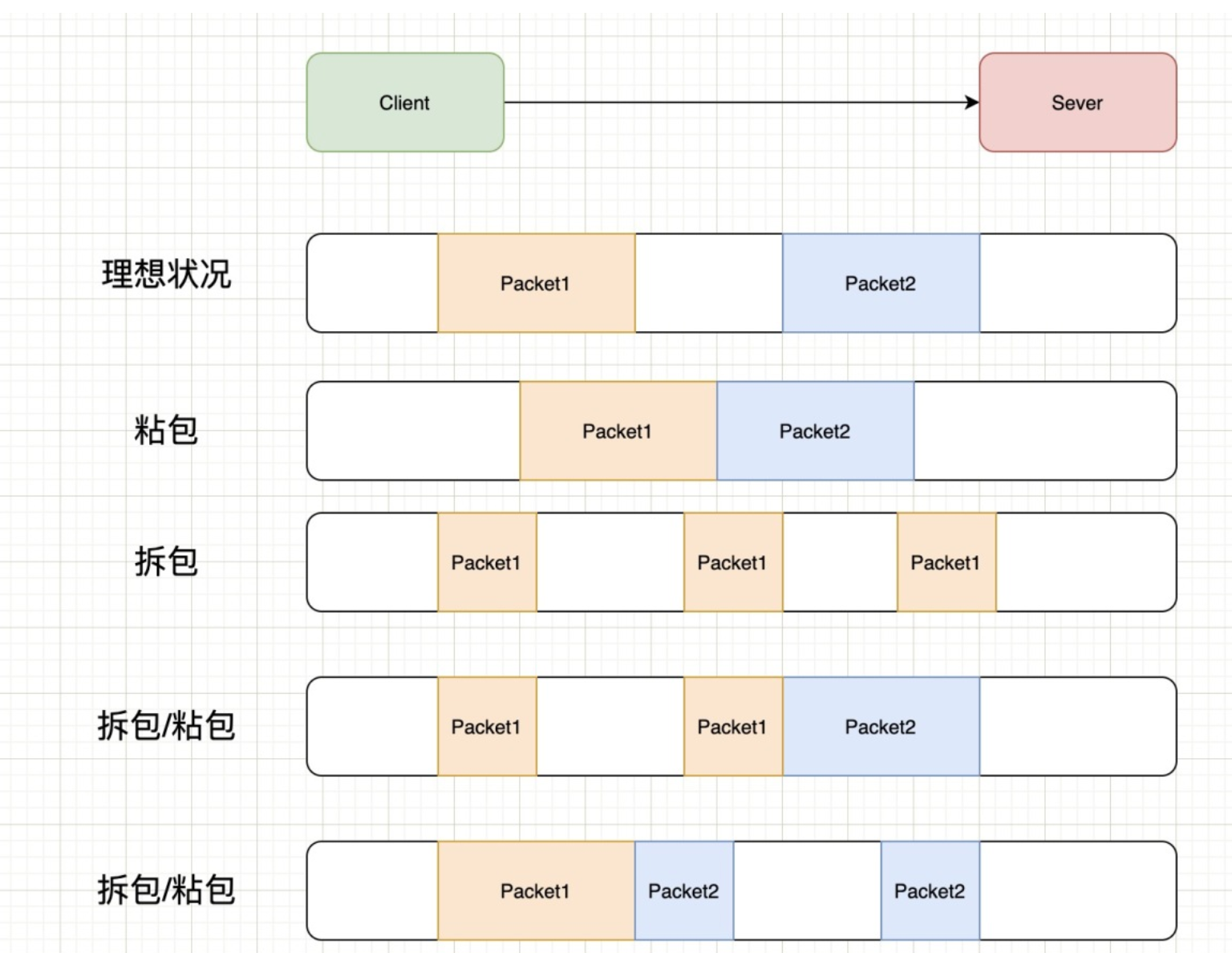
为进一步帮助开发者学习使用 Flink,Apache Flink 中文社区近期发起 Flink-Learning 实战营项目。本次实战营通过真实有趣的实战场景帮助开发者实操体验 Flink,课程包括实时数据接入、实时数据分析、实时数据应用的场景实。并结合小松鼠助教模式,全方位帮助入营开发者轻松玩转 Flink,点击下方图片扫码即刻入营。
Tips:点击「阅读原文」即刻入营~

本期将继续详细介绍 Flink- Learning 实战营。
实验简介
随着“全面二孩”政策落地、居民可支配收入稳步增加等因素的刺激,中国的母婴消费市场持续增长。与此同时,随着国民消费升级 90 后宝爸、宝妈人数剧增,消费需求与消费理念都发生了巨大的变化。据罗兰贝格最新公布的报告预计,已经经过了 16 个年头发展的母婴行业,到 2020 年,整体规模将达到 3.6 万亿元,2016-2020 年复合增速高达 17%,行业前景看起来一片光明。如此大好形势下,母婴人群在母婴消费上有什么特点?消费最高的项目是什么?
本场景中订单和婴儿信息存储在 MySQL 中,对于订单表,为了方便进行分析,我们让它关联上其对应的婴儿信息,构成一张宽表,使用 Flink 实时把它写到 Elasticsearch 中;另一方面数据经过分组聚合后,计算出订单数量和婴儿出生的关系,实时把它写到 Elasticsearch 中并展示到 Kibana 大屏中。
■ 为回馈广大开源开发者对社区的支持,阿里云实时计算 Flink 版提供云原生免费试用资源
实验资源
实验所开通的云产品因数据连通性要求,需使用同一 Region 可用区,建议都选取北京 Region 的同一可用区。涉及的云产品包括阿里云实时计算 Flink 版、检索分析服务 Elasticsearch 版、阿里云数据库 RDS。
体验目标
本场景将以 阿里云实时计算 Flink 版为基础,使用 Flink 自带的 MySQL Connector 连接 RDS 云数据库实例、Elasticsearch Connector 连接 Elasticsearch 检索分析服务实例,并以一个淘宝母婴订单实时查询的例子尝试上手 Connector 的数据捕获、数据写入等功能。
按步骤完成本次实验后,您将掌握的知识有:
使用 Flink 实时计算平台创建并提交作业的方法;
编写基于 Flink Table API SQL 语句的能力;
使用 MySQL Connector 对数据库进行读取的方法;
使用 Elasticsearch Connector 对数据库进行写入的方法。
步骤一:创建资源
开始实验之前,您需要先创建相关实验资源,确保 RDS 实例、Elasticsearch 实例、Flink 实例在同一个 VPC 网络下,并配置完成 RDS 白名单、Elasticsearch 白名单使网络打通。
步骤二:创建数据库表
在这个例子中,我们将创建三张数据表,其中一张 orders_dataset_tmp 是导入数据的临时表,其他两张作为源表,体验淘宝母婴订单实时查询。
1. 点击云数据库 RDS 控制台「实例列表」,切换到上面创建实例所在的 region,点击自己的实例名称进入详情页,首次使用分别点击「账号管理」和「数据库管理」,创建账号和数据库并使账号绑定到指定数据库。
2. 点击云数据库 RDS 实例详情页上方「登录数据库」,会自动跳转到 DMS 数据管理平台,输入用户名和密码登录刚刚创建的实例,点击左侧「数据库实例」-「已登录实例」列表,双击要编辑的数据库名,然后在右侧 SQL Console 命令区输入以下建表指令并执行:
create table orders_dataset_tmp(
user_id bigint comment '用户身份信息',
auction_id bigint comment '购买行为编号',
cat_id bigint comment '商品种类序列号',
cat1 bigint comment '商品序列号(根类别)',
property TEXT comment '商品属性',
buy_mount int comment '购买数量',
day TEXT comment '购买时间'
);
create table orders_dataset(
order_id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY comment '订单id',
user_id bigint comment '用户身份信息',
auction_id bigint comment '购买行为编号',
cat_id bigint comment '商品种类序列号',
cat1 bigint comment '商品序列号(根类别)',
property TEXT comment '商品属性',
buy_mount int comment '购买数量',
day TEXT comment '购买时间'
);
--
create table baby_dataset(
user_id bigint NOT NULL PRIMARY KEY,
birthday text comment '婴儿生日',
gender int comment '0 denotes female, 1 denotes male, 2 denotes unknown'
);3. 在 DMS 数据管理平台,点击左侧「常用功能」-「数据导入」,配置如下信息后点击提交申请,将 (sample)sam_tianchi_mum_baby_trade_history.csv 导入 orders_dataset_tmp 表,(sample)sam_tianchi_mum_baby.csv 导入 baby_dataset 表。
配置项 | 说明 |
数据库 | 模糊搜索数据库名后点击对应的 MySQL 实例 |
文件编码 | 自动识别 |
导入模式 | 极速模式 |
文件类型 | CSV 格式 |
目标表 | 模糊搜索要导入的表名后点击选中 |
数据位置 | 选择第1行为属性 |
写入方式 | INSERT |
附件 | 点击上传按钮上传要导入到表的对应文件 |
导入完成之后执行以下 SQL 将订单数据导入到订单源表 orders_dataset 中。
insert into orders_dataset(user_id,auction_id,cat_id,cat1,property,buy_mount,day)
select * from orders_dataset_tmp;步骤三:配置 Elasticsearch
自动创建索引
进入检索分析服务控制台,Elasticsearch 实例列表找到自己的实例,然后点击实例名进入详情界面,点击「配置与管理」-「ES 集群配置」,点击「修改配置」,选择「允许自动创建索引」,点击「确定」。

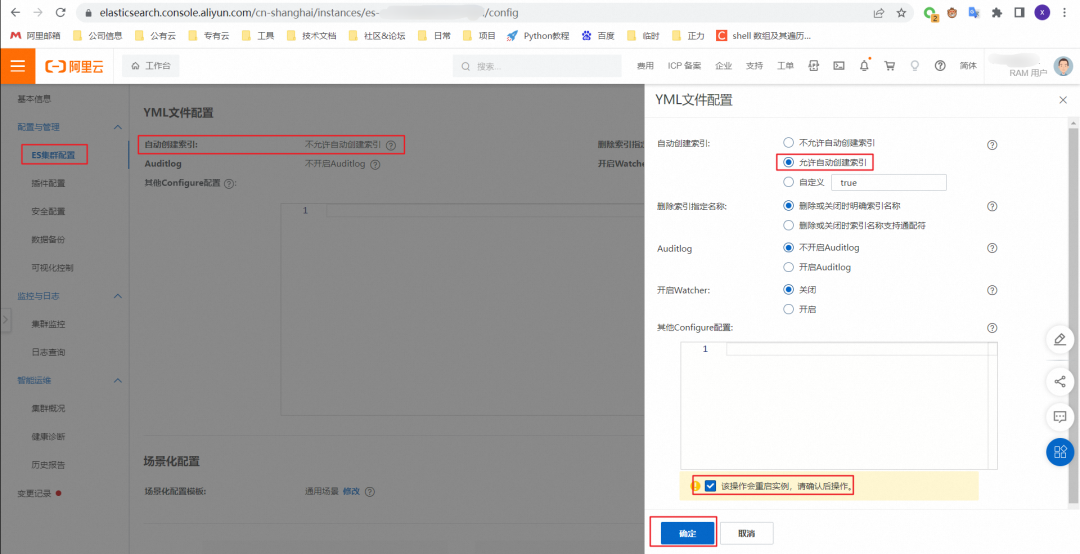
修改配置需要等待十几分钟,请耐心等待配置变更完成后再继续使用 Elasticsearch。
步骤四:创建实时查询 SQL 作业
1. 进入实时计算 Flink 平台,点击左侧边栏中的「应用」—「作业开发」菜单,并点击顶部工具栏的「新建」按钮新建一个作业。作业名字任意,类型选择「流作业 / SQL」,其余设置保持默认。如下所示:
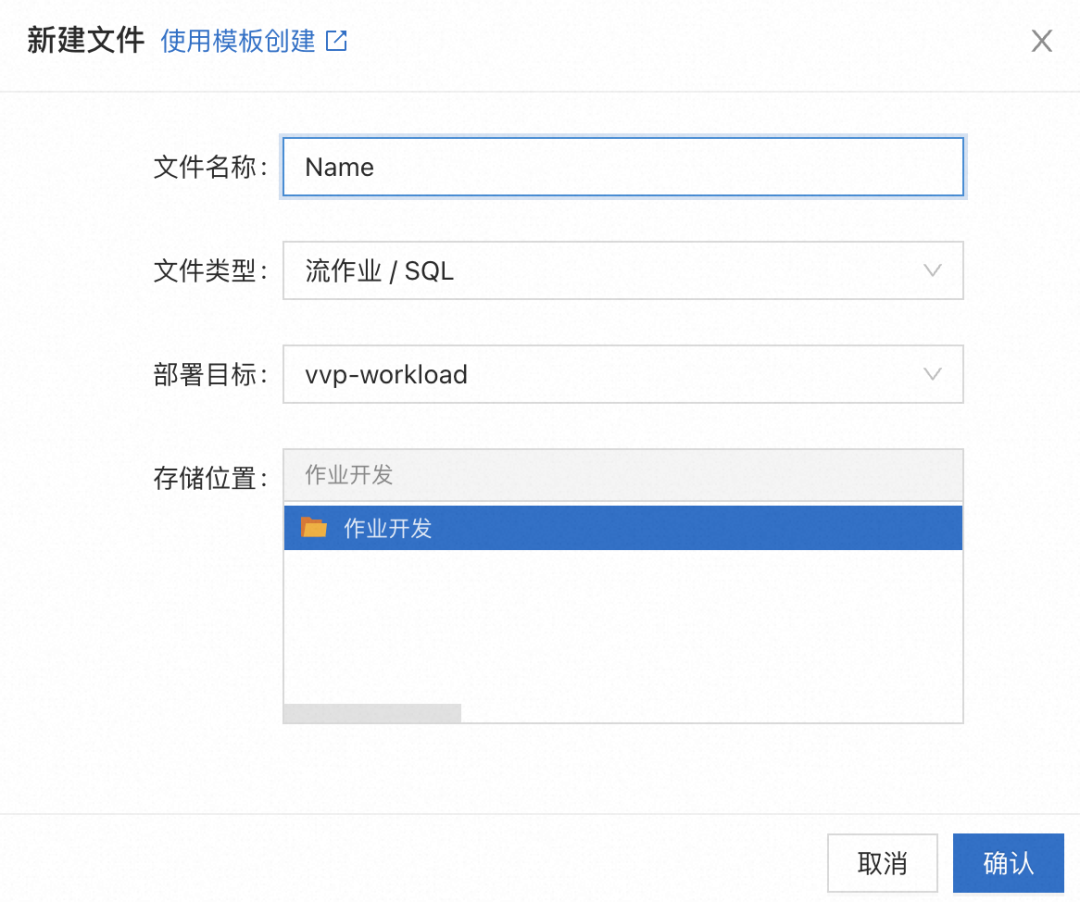
2. 成功创建作业后,右侧编辑窗格应该显示新作业的内容:

3. 接下来,我们在右侧编辑窗格中输入以下语句来创建二张临时表,并使用 MySQL CDC 连接器实时捕获 orders_dataset和 baby_dataset的变化:
CREATE TEMPORARY TABLE orders_dataset (
order_id BIGINT,
`user_id` bigint,
auction_id bigint,
cat_id bigint,
cat1 bigint,
property varchar,
buy_mount int,
`day` varchar ,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '******************.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = '***********',
'password' = '***********',
'database-name' = '***********',
'table-name' = 'orders_dataset'
);
CREATE TEMPORARY TABLE baby_dataset (
`user_id` bigint,
birthday varchar,
gender int,
PRIMARY KEY(user_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '******************.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = '***********',
'password' = '***********',
'database-name' = '***********',
'table-name' = 'baby_dataset'
);需要将 hostname 参数替换为早些时候创建资源的域名、将 username 和 password 参数替换为数据库登录用户名及密码、将 database-name参数替换为之前在 RDS 后台中创建的数据库名称。
其中,'connector' = 'mysql'指定了使用 MySQL CDC 连接器来捕获变化数据。您需要使用准备步骤中申请的 RDS MySQL URL、用户名、密码,以及之前创建的数据库名替换对应部分。
任何时候您都可以点击顶部工具栏中的「验证」按钮,来确认作业 Flink SQL 语句中是否存在语法错误。
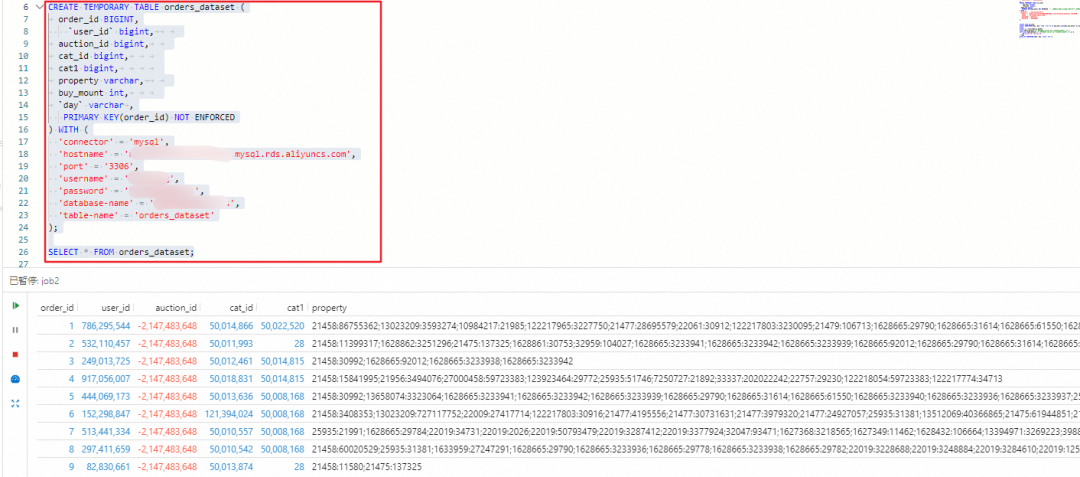
4. 为了测试是否成功地捕获了源表数据,紧接着在下面写一行 SELECT * FROM source_table;语句,选中临时表和 select 语句,并点击工具栏中的「执行」按钮。如果控制台中打印了相应的数据行,则说明捕获成功,如下图所示:
5. 我们在右侧编辑窗格中输入以下语句来创建一张临时表,并使用 Elasticsearch 连接器连接到 Elasticsearch 实例:
CREATE TEMPORARY TABLE es_sink(
order_id BIGINT,
`user_id` bigint,
auction_id bigint,
cat_id bigint,
cat1 bigint,
property varchar,
buy_mount int,
`day` varchar ,
birthday varchar,
gender int,
PRIMARY KEY(order_id) NOT ENFORCED -- 主键可选,如果定义了主键,则作为文档ID,否则文档ID将为随机值。
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://**********:9200',
'index' = 'enriched_orders',
'username' ='elastic',
'password' ='*******'--创建ES实例时自定义的密码
);需要将 hosts参数替换为早些时候创建资源的域名、将 password参数替换为登录 Kibana 密码。
其中,'connector' = 'elasticsearch-7'指定了使用 Elasticsearch 连接器来连接 Elasticsearch 实例写入数据。您需要使用准备步骤中申请的 Elasticsearch URL、用户名、密码。
6. 接下来,我们希望对原始数据按照 user_id 进行 JOIN,构成一张宽表。并把宽表数据写入到 Elasticsearch 的 enriched_orders 索引中。我们在 Flink 作业编辑窗格中输入如下代码:
INSERT INTO es_sink
SELECT o.*,
b.birthday,
b.gender
FROM orders_dataset /*+ OPTIONS('server-id'='123450-123452') */ o
LEFT JOIN baby_dataset /*+ OPTIONS('server-id'='123453-123455') */ as b
ON o.user_id = b.user_id;在保证源表中有数据的情况下,再次执行 Flink 作业,观察控制台的输出结果:
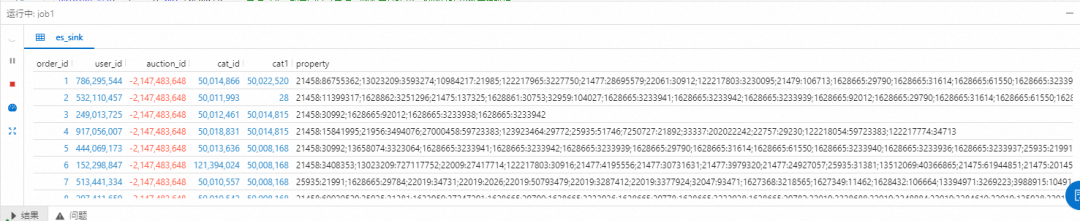
现在,点击控制台上的「上线」按钮,即可将我们编写的 Flink SQL 作业部署上线执行。您可以登录 Kibana 点击「Stack Management」-「Index Management」搜索 enriched_orders 查看 enriched_orders索引是否成功创建。
阿里云实时计算控制台在使用「执行」功能调试时,不会写入任何数据到下游中。因此为了测试使用 SQL Connector 写入汇表,您必须使用「上线」功能。
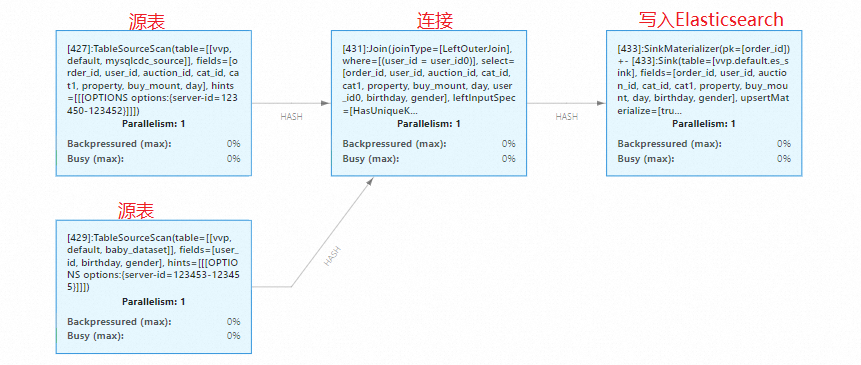
您也可以进入 Flink UI 控制台观察流数据处理图。
7. Elasticsearch 的 enriched_orders 索引创建成功后,点击「Discover」 -「create index pattern」 ,输入enriched_orders,点击「Next step」 - 「create index pattern」,创建完成后就可以在「Kibana」-「Discover」看到写入的数据了。
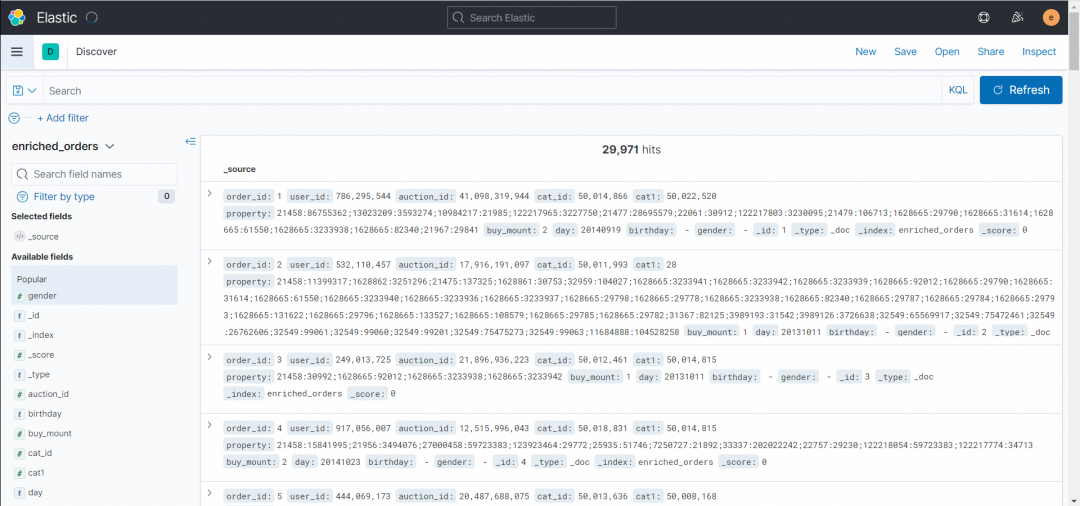
8. 接下来,我们通过对 MySQL 中源表的数据进行增改删操作,每执行一步就刷新一下「Kibana」-「Discover」界面,观察数据的变化。
8.1 order_dataset 表添加一条数据
insert into orders_dataset values ( DEFAULT ,2222222,2222222,50018855,38,'21458:33304;6933666:4421827;21475:137319;12121566:3861755',1,'20130915');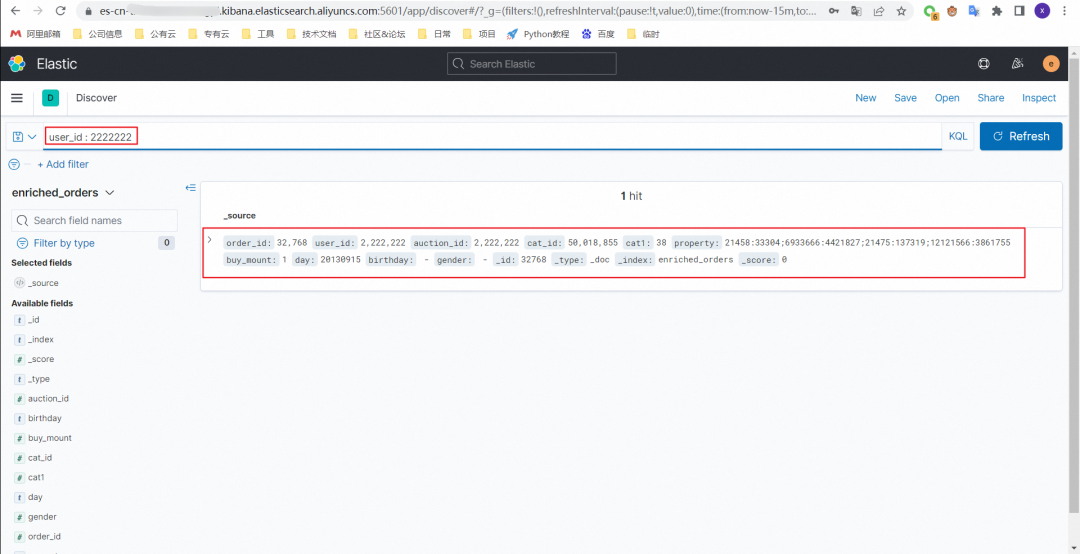
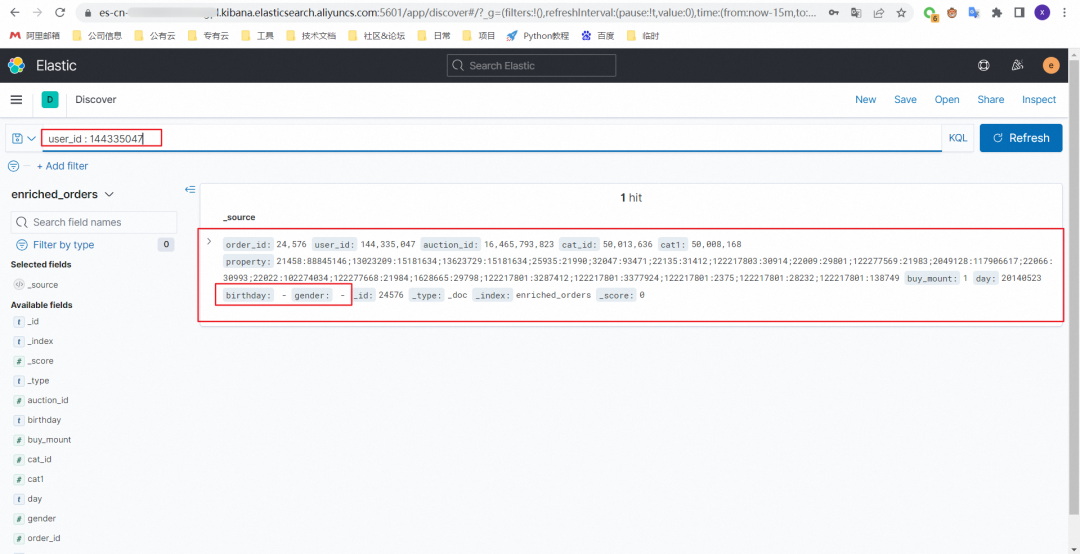
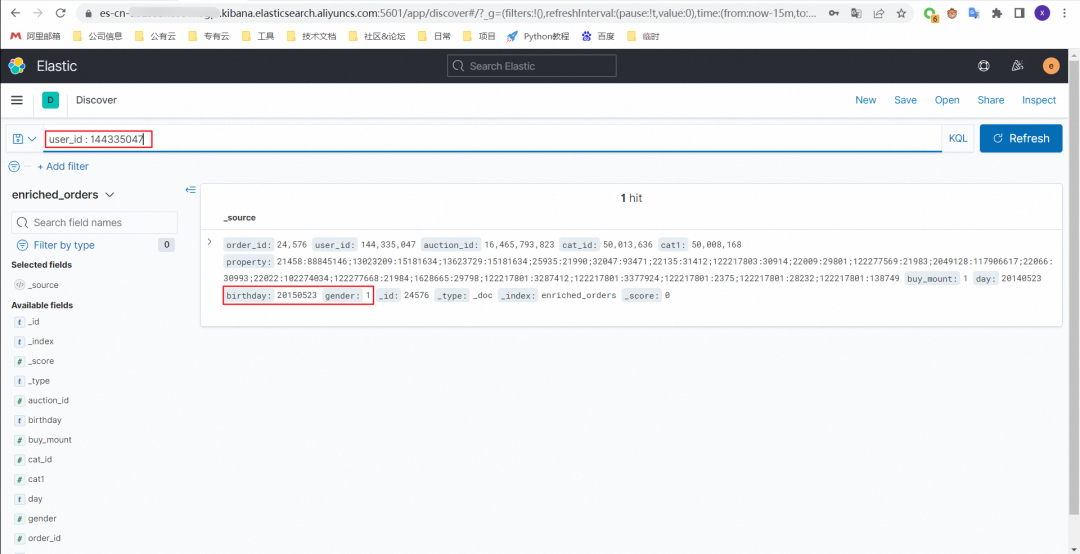
8.2 baby_dataset 表中添加一条数据
insert into baby_dataset values(144335047,'20150523',1);写入前
写入后
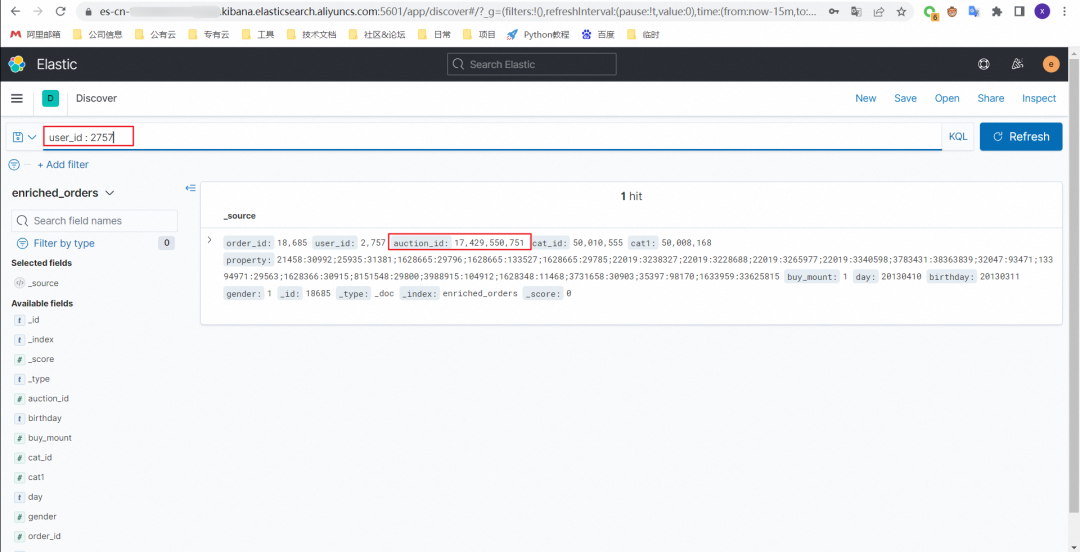
8.3 order_dataset 表更新一条数据
select order_id from orders_dataset where user_id = 2757;
--根据查到的order_id更新数据
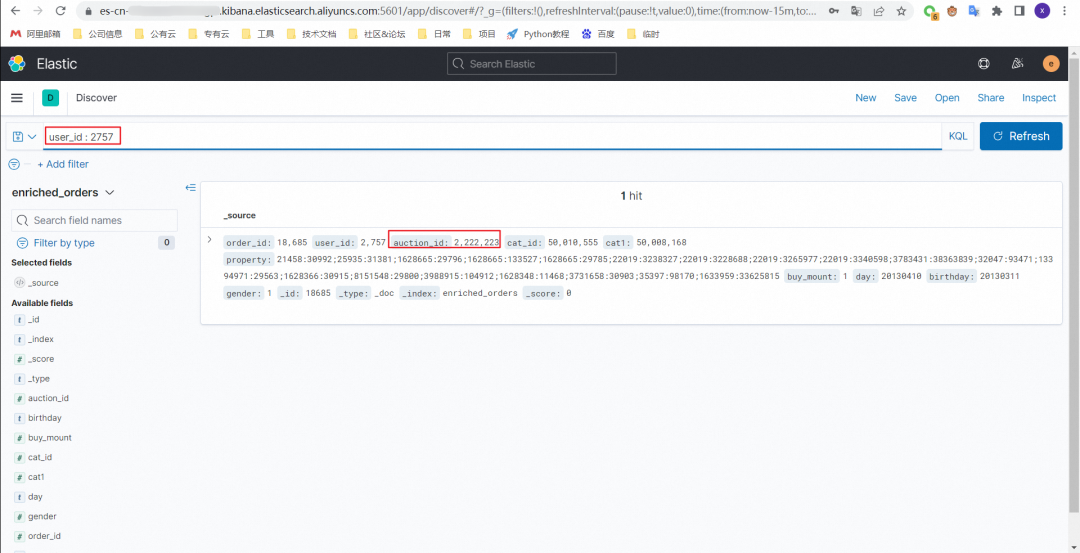
UPDATE orders_dataset SET auction_id = 2222223 WHERE order_id = ;更新前
更新后
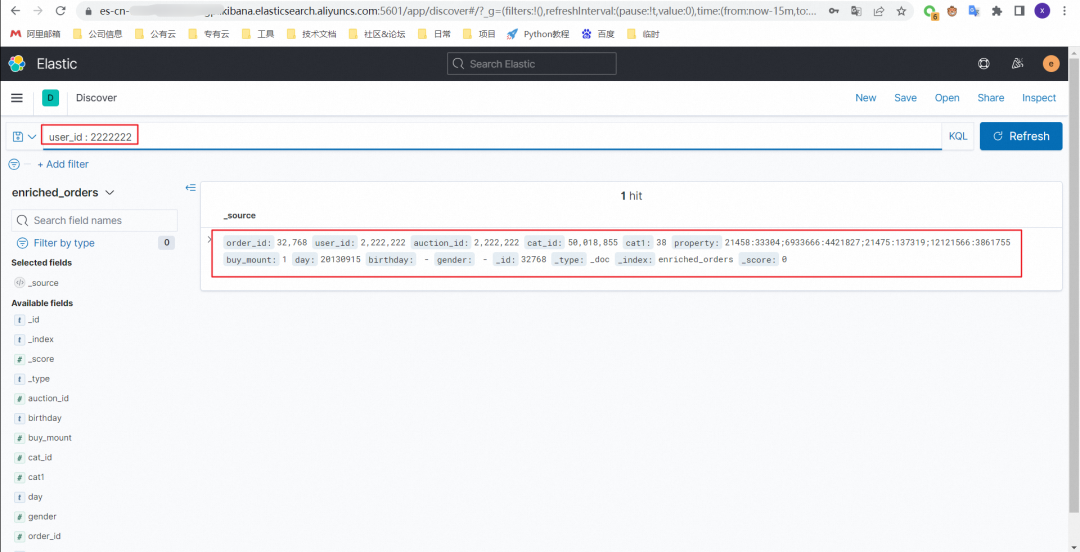
8.4 order_dataset 表中删除一条数据
select order_id from orders_dataset where user_id = 2222222;
DELETE FROM orders_dataset WHERE order_id = ;删除前
删除后

步骤五:创建实时大屏 SQL 作业
前面四步和步骤四的前面四步相同,区别在于后面步骤作业的处理逻辑 SQL 不同,要统计的指标不同,所以 Elasticsearch 的 Schema 与之前不同。
1. 进入实时计算 Flink 平台,点击左侧边栏中的「应用」—「作业开发」菜单,并点击顶部工具栏的「新建」按钮新建一个作业。作业名字任意,类型选择「流作业 / SQL」,其余设置保持默认。如下所示:
2. 成功创建作业后,右侧编辑窗格应该显示新作业的内容:

3. 接下来,我们在右侧编辑窗格中输入以下语句来创建二张临时表,并使用 MySQL CDC 连接器实时捕获 orders_dataset 和 baby_dataset 的变化:
CREATE TEMPORARY TABLE orders_dataset (
order_id BIGINT,
`user_id` bigint,
auction_id bigint,
cat_id bigint,
cat1 bigint,
property varchar,
buy_mount int,
`day` varchar ,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '******************.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = '***********',
'password' = '***********',
'database-name' = '***********',
'table-name' = 'orders_dataset'
);
CREATE TEMPORARY TABLE baby_dataset (
`user_id` bigint,
birthday varchar,
gender int,
PRIMARY KEY(user_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '******************.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = '***********',
'password' = '***********',
'database-name' = '***********',
'table-name' = 'baby_dataset'
);需要将 hostname 参数替换为早些时候创建资源的域名、将 username 和 password参数替换为数据库登录用户名及密码、将 database-name 参数替换为之前在 RDS 后台中创建的数据库名称。
其中,'connector' = 'mysql'指定了使用 MySQL CDC 连接器来捕获变化数据。您需要使用准备步骤中申请的 RDS MySQL URL、用户名、密码,以及之前创建的数据库名替换对应部分。
任何时候您都可以点击顶部工具栏中的「验证」按钮,来确认作业 Flink SQL 语句中是否存在语法错误。
4. 为了测试是否成功地捕获了源表数据,紧接着在下面写一行 SELECT * FROM source_table;语句,选中临时表和 select 语句,并点击工具栏中的「执行」按钮。如果控制台中打印了相应的数据行,则说明捕获成功,如下图所示:
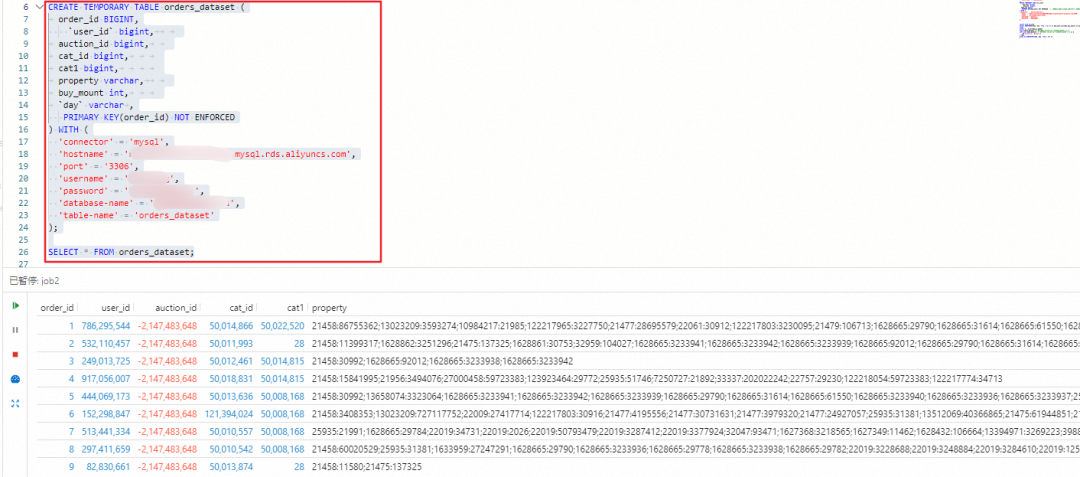
5. 我们在右侧编辑窗格中输入以下语句来创建一张临时表,并使用 Elasticsearch 连接器连接到 Elasticsearch 实例:
CREATE TEMPORARY TABLE es_sink(
day_year varchar,
`buy_num` bigint,
baby_num bigint,
PRIMARY KEY(day_year) NOT ENFORCED -- 主键可选,如果定义了主键,则作为文档ID,否则文档ID将为随机值。
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://**********:9200',
'index' = 'enriched_orders_view',
'username' ='elastic',
'password' ='*******'--创建ES实例时自定义的密码
);需要将 hosts 参数替换为早些时候创建资源的域名、将 password 参数替换为登录Kibana 密码。
其中,'connector' = 'elasticsearch-7'指定了使用 Elasticsearch 连接器来连接 Elasticsearch 实例写入数据。您需要使用准备步骤中申请的 Elasticsearch URL、用户名、密码。
6. 接下来,我们希望对原始数据按照 user_id 进行 JOIN,构成一张宽表。然后对宽表数据的订单时间取到月份进行分组 GROUP BY,并统计每个分组中订单的购买数量 SUM 和出生婴儿的数量 COUNT,并将结果数据写入到 Elasticsearch 的 enriched_orders_view 索引中。我们在 Flink 作业编辑窗格中输入如下代码:
INSERT INTO es_sink
SELECT
SUBSTRING(tmp1.`day` FROM 1 FOR 6) as day_year,
SUM(tmp1.buy_mount) as buy_num,
COUNT(birthday) as baby_num
FROM(
SELECT o.*,
b.birthday,
b.gender
FROM orders_dataset /*+ OPTIONS('server-id'='123456-123457') */ o
LEFT JOIN baby_dataset /*+ OPTIONS('server-id'='123458-123459') */ as b
ON o.user_id = b.user_id
) tmp1
GROUP BY SUBSTRING(tmp1.`day` FROM 1 FOR 6)在保证源表中有数据的情况下,再次执行 Flink 作业,观察控制台的输出结果:
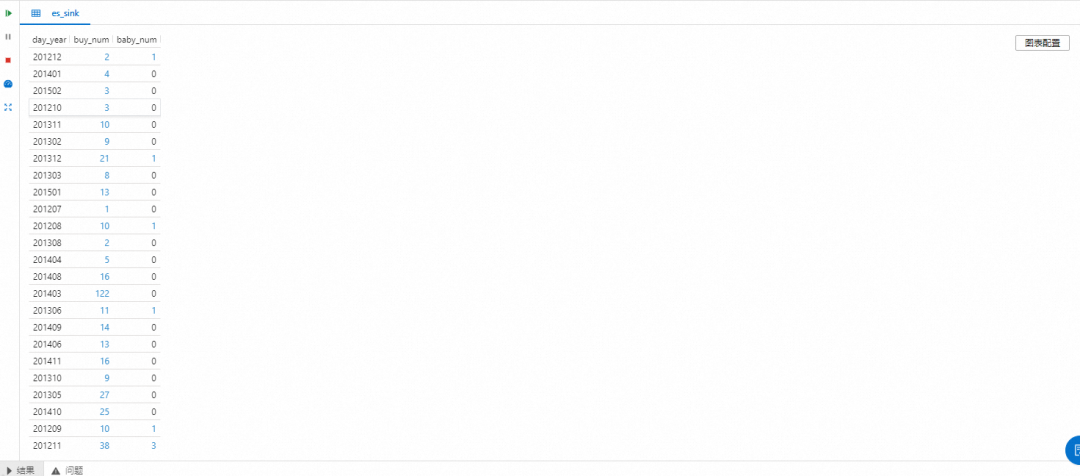
现在,点击控制台上的「上线」按钮,即可将我们编写的 Flink SQL 作业部署上线执行。您可以登录 Kibana 点击「Stack Management」-「Index Management」搜索 enriched_orders_view 查看 enriched_orders_view 索引是否成功创建。
阿里云实时计算控制台在使用「执行」功能调试时,不会写入任何数据到下游中。因此为了测试使用 SQL Connector 写入汇表,您必须使用「上线」功能。
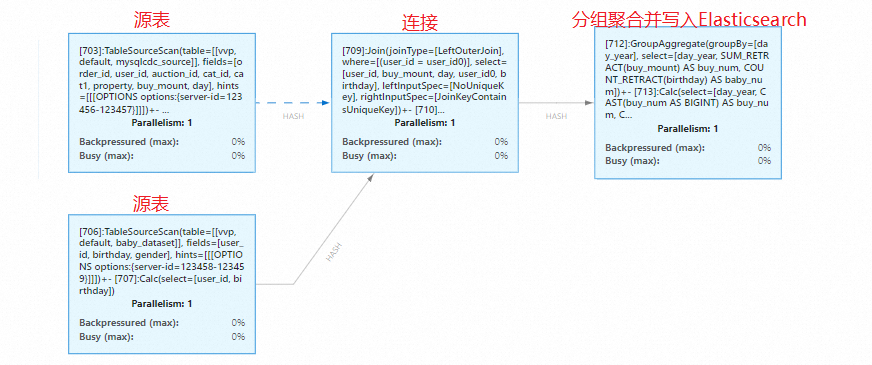
您也可以进入 Flink UI 控制台观察流数据处理图。
7. Elasticsearch 的 enriched_orders_view 索引创建成功后,点击「Discover」 -「create index pattern」 ,输入 enriched_orders_view,点击「Next step」 - 「create index pattern」,创建完成后就可以在「Kibana」-「Discover」看到写入的数据了。
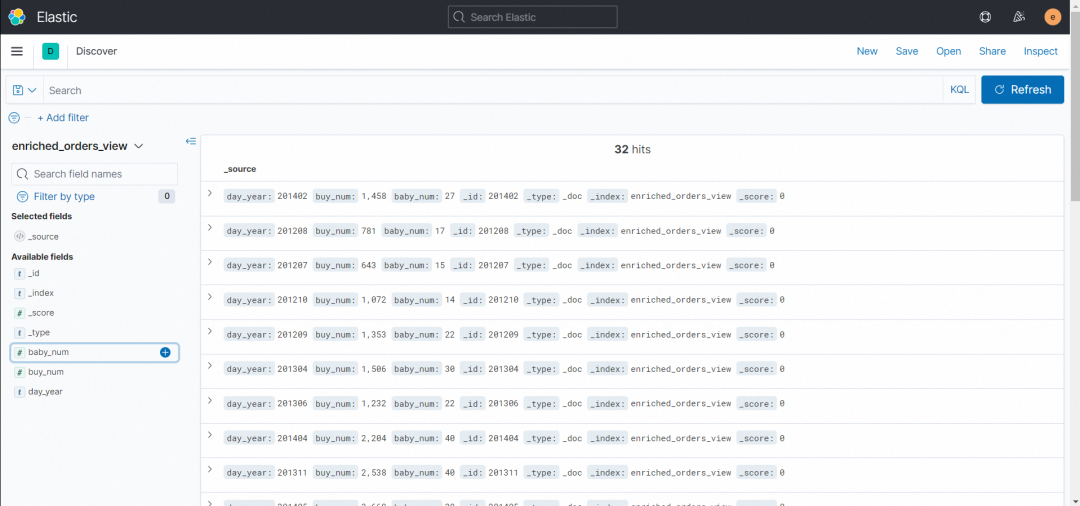
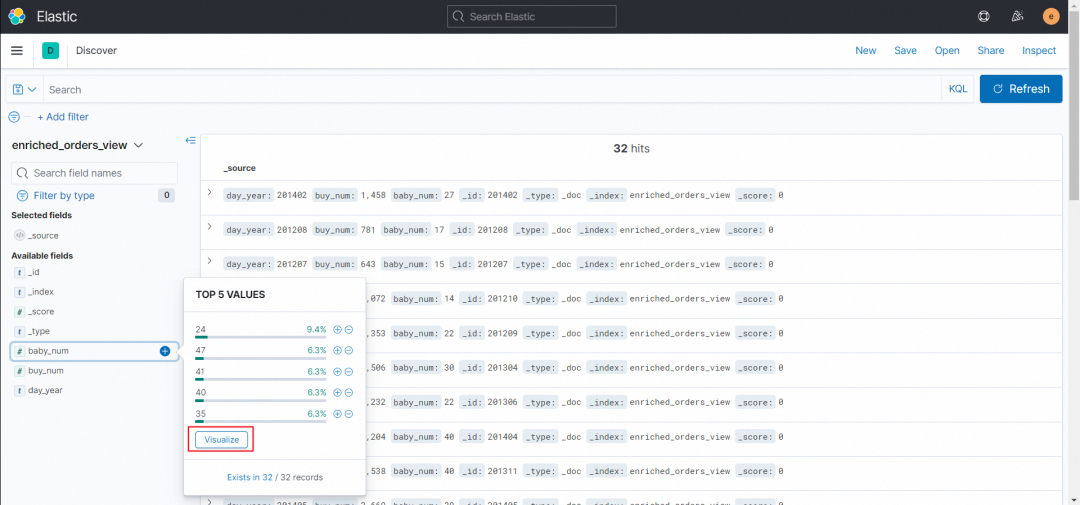
8. 在「Discover」界面点击左下角「Available fields」-「baby_num」,点击后会展示「TOP 5 VALUES」小窗口,点击窗口下方的「Visualize」,即可跳转到可视化图表界面。
跳转界面后切换图形格式为柱状图 Bar。
配置右侧 X-axis、Y-axis
X-axis 配置 Select a field为day_year.keyword,Number of values 选择到最大 100,order by 选择 alphabetical ,order direction 选择 ascending,Display name 自定义横轴名称,此处定义为 day_year_month ,然后点击 Close。
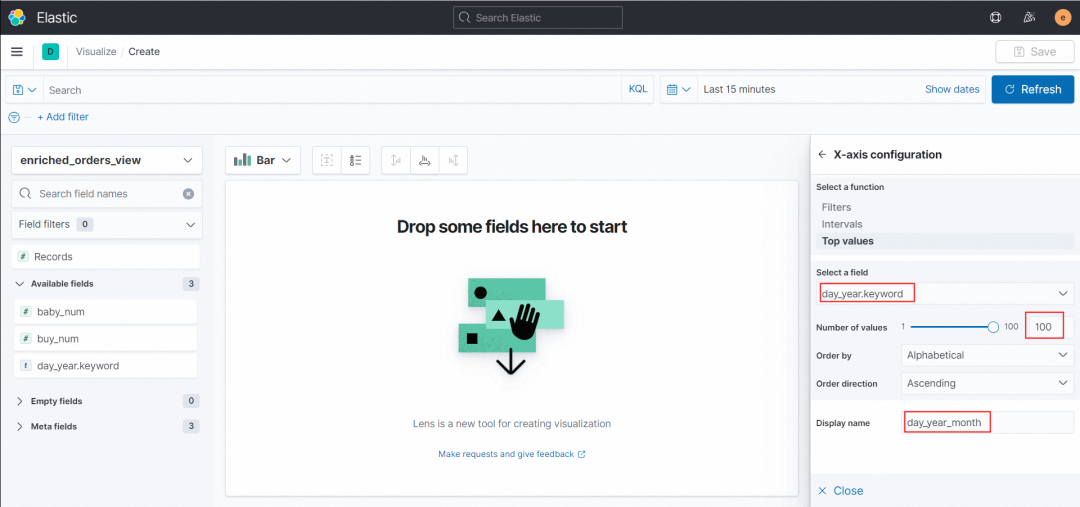
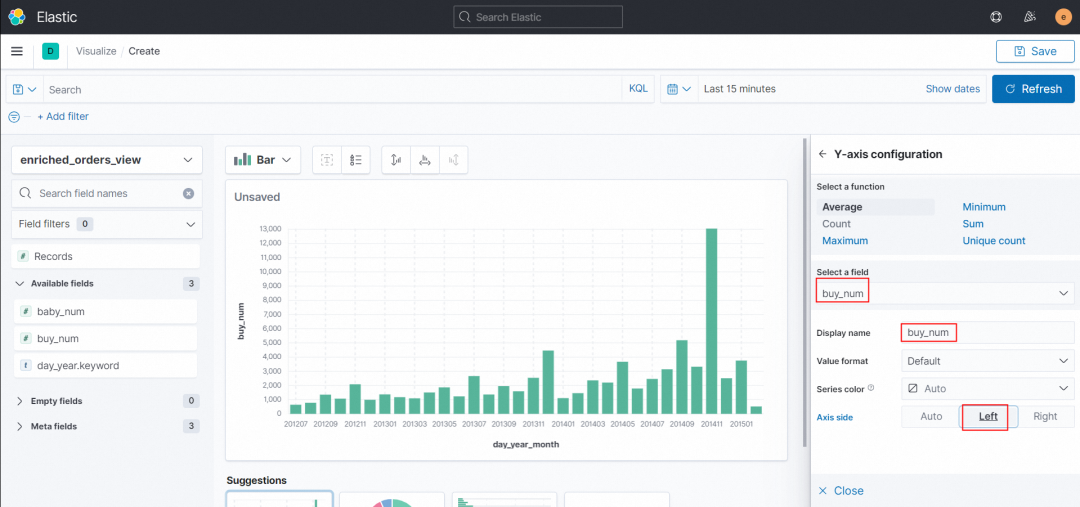
Y-axis 配置 Select a field 为 buy_num,Display name 自定义纵轴名称,此处定义为 buy_num ,Axis side 选择 Left ,然后点击 Close。界面中间即生成了对应的折线图。
9. 点击右下角的+,新建一个 layer,切换新建的 layer 的图格式为折线图 Line
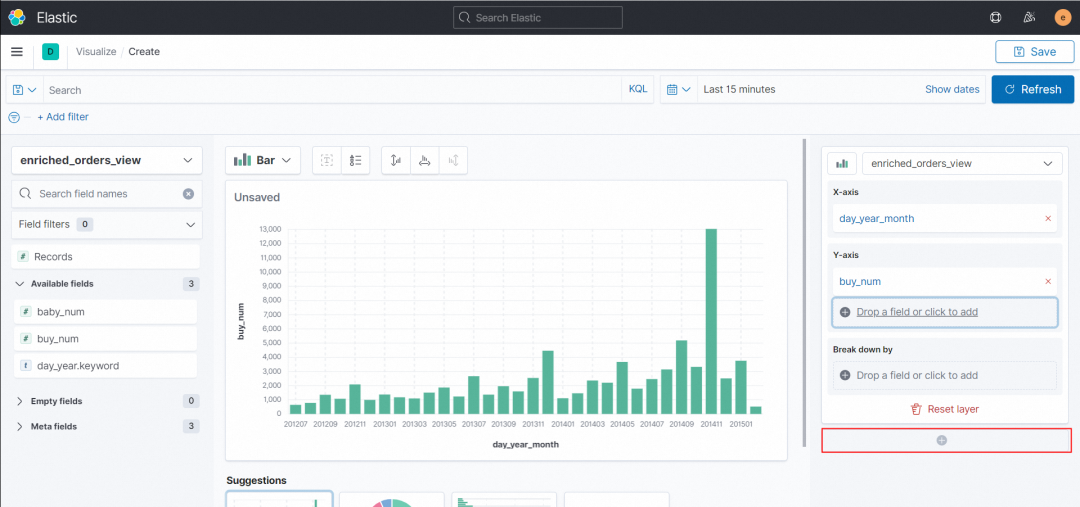
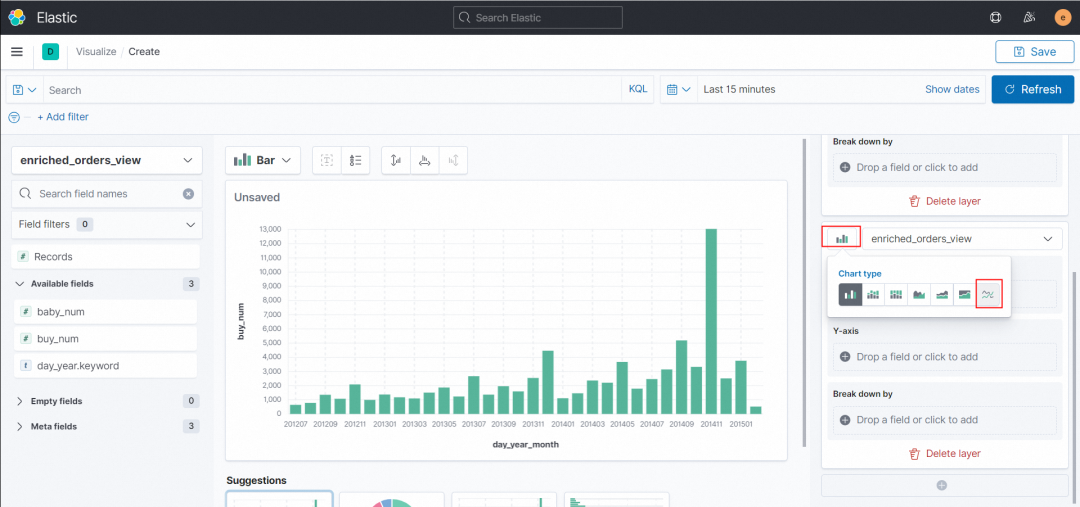
配置右侧 X-axis、Y-axis
X-axis 配置 Select a field 为 day_year.keyword,Number of values 选择到最大100,order by 选择 alphabetical ,order direction 选择 ascending,Display name自定义横轴名称,此处定义为 day_year_month ,然后点击 Close。
与上一个 X-axis 配置完全相同。
Y-axis 配置 Select a field 为 baby_num,Display name 自定义纵轴名称,此处定义为 baby_num ,Value format 选择 Pecent,Axis side 选择 Right ,然后点击Close。界面中间即生成了对应的折线图与柱状图的复合图。
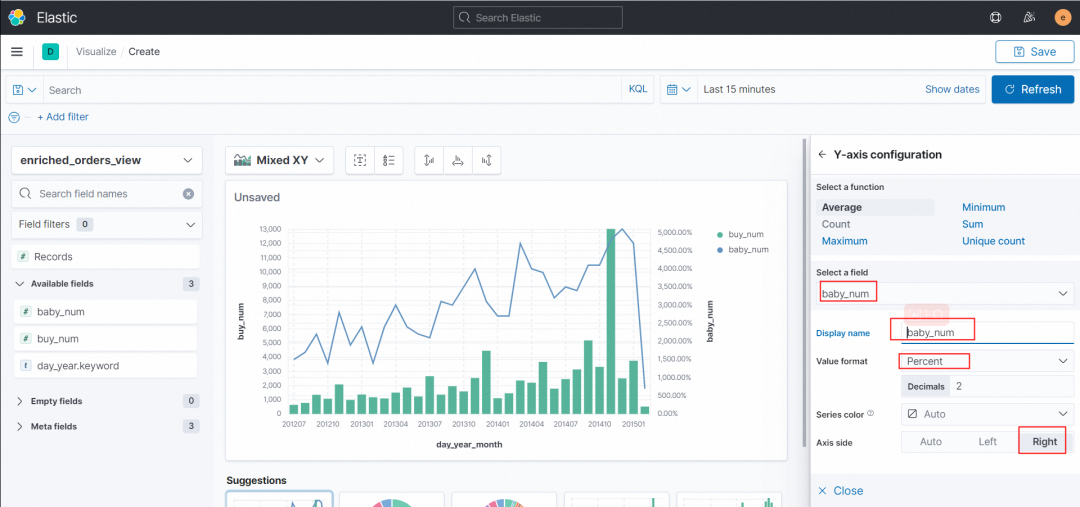
10. 最后点击右上角的 Save,定义此图表的名称即可保存。
想要了解更多商品销售额实时统计的实验信息吗?快来尝试一下吧!

往期精选





▼ 活动推荐▼

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,即刻入营
点击「阅读原文」,即刻入营