转载请注明出处:https://blog.csdn.net/nocml/article/details/125711025
本系列传送门:
Transformer(一)–论文翻译:Attention Is All You Need 中文版
Transformer(二)–论文理解:transformer 结构详解
Transformer(三)–论文实现:transformer pytorch 代码实现
Transformer(四)–实现验证:transformer 机器翻译实践
文章目录
- 1 文章说明
- 2. 模型训练
- 2.1 训练数据
- 2.2 训练设备
- 2.3 训练参数
- 2.4 训练过程
- 2.5 模型结果
- 2.6 结果分析
1 文章说明
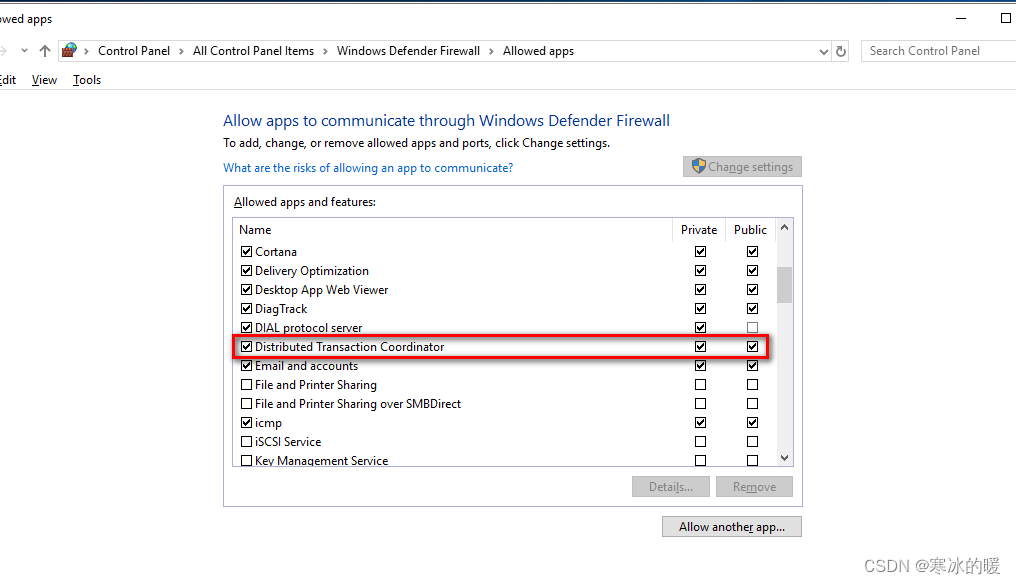
此篇文章是衔接上一篇的后续,在这篇blog中,我们会使用之前实现的代码,在真实的大规模语料上来训练一个机器翻译模型,用实际效果来检验我们实现的代码。
这个实验是我很早之前,也就是刚写完代码时做的,只不过模型结果没有经过系统评估,连blue分也没计算,所以当时就没有整理成blog。最近想了想,还是把结果粘上来,大家看一下。然后transformer这块就结束了。最近一直在搞chatgpt相关的事情,有时间了也会整理下。
2. 模型训练
2.1 训练数据
训练数据使用中英平行语料,共1000W。
2.2 训练设备
服务器型号:T7920 塔式机
gpu: 2080ti 11G 单卡 (由于只是验证模型的正确性,所以只使用了一块卡)
cpu: 至强 5218N * 2
内存:128G
2.3 训练参数
- l r : 6.26 × 1 0 − 5 lr :{6.26} ×10^{-5} lr:6.26×10−5
- b a t c h s i z e : 16 batch size: 16 batchsize:16
- s e n t e n c e m a x l e n g t h : 128 sentence \ max \ length: 128 sentence max length:128 (语料中的最大长度)
- w a r m s t e p : 10000 warm\ step : 10000 warm step:10000
- t o k e n n u m : 45000 token\ num:45000 token num:45000
- e p o c h : 5 epoch: 5 epoch:5
2.4 训练过程
- 训练时长:7d(一个epoch 大概需要一天多)
- 训练损失:从百分位降到千分位,具体见下图
- 训练初始:
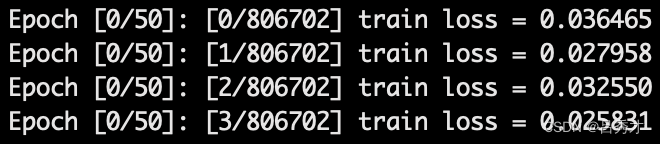
- 训练结束:

- 训练初始:
2.5 模型结果
结果展示:
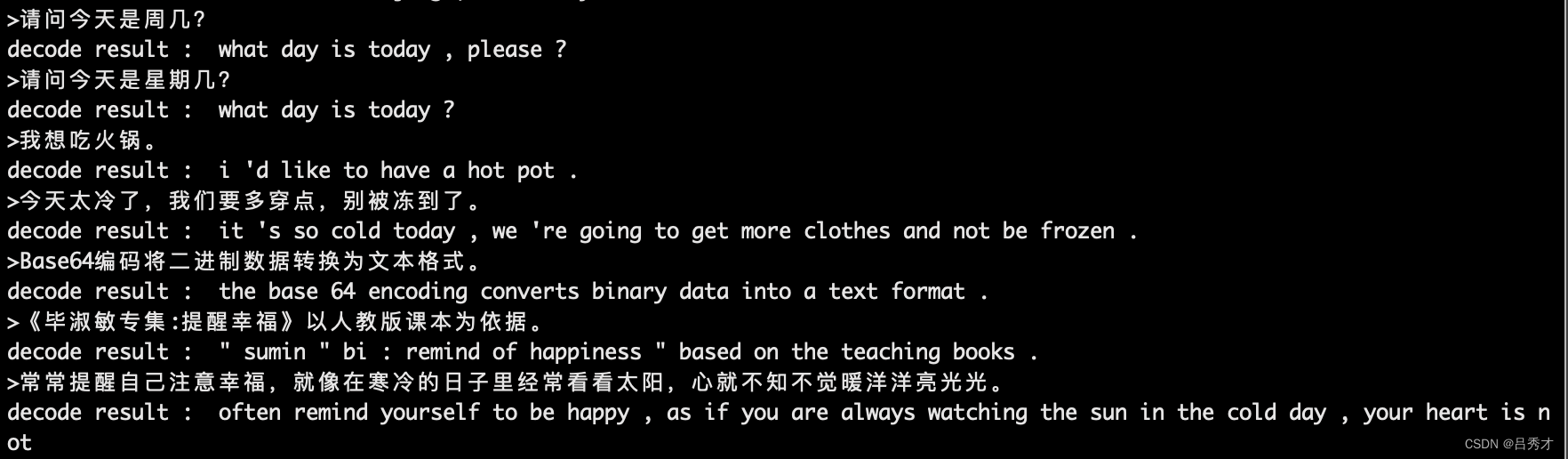
注:最后一个例子超过我设置的解码长度了,没有翻译完。
2.6 结果分析
没有计算具体的评估指标,主要是当时忙着做其它项目,没有过多的时间,且当时训练的目的也只是为了通过实验来看看代码是否有致命缺陷。从结果来看,已经有一定的翻译效果了。